【无标题】
Spark是用来计算的
计算就需要资源
所以,谁提供资源,就叫什么模式
LOCAL:本机的Spark(JVM)
Standalonde:()集群Spark(JVM) ,国内不常用,因为出现晚
YARN: Spark使用HADOOP的YARN资源调度(HADOOP出现的比较早),
yarn来提供调度资源,YARN集群(JVM)
Mesos:yarn模仿Mesos, Mesos集群
bin binary 存放二进制或者命令
conf configuration 配置文件 但是SPARK的不怎么起作用,因为后面带template
examples 例子
jar jar包存放地址(一般也可以是lib library)
sbin 以s开头的脚本命令 start stop

加\ 是连接符,表示还是第一行的
sparl-submit --class 全限定类名 --master local/local[n] 包路径
注意路径是与执行命令的位置有关
master local是本机提供资源
如果是用local[n] 是用一个进程中的多个线程来模仿分布式操作
不加[n]是默认一个线程
local[*] 利用当前环境最大核计算
最后是运行次数
cd change directory
pwd print work dir
chmod change mode
因为是yarn提供资源,所以得先启动yarn

默认1个机器8个核,虚拟核
部署模式
client和cluster
client 可以在客户端看到结果
集群无法在客户端看到结果,结果在YARN


什么是端口号
通过将数据包的目标端口号与发送方和接收方的 IP 地址一起,网络中的路由器和交换机可以将数据包传递到正确的目标应用程序或服务。
IP找到机器,端口对应服务
端口号有默认.但是不固定,可以改
mysql 默认服务3306
81
域名解析器
1.本机解析 2.网络解析
本机用HOSTS解析 ,解析不出来用网络解析
Spark-Core
RDD:Spark中用于分布式计算的模型
1.RDD是一个对象
2.内部封装了和分布式计算相关的操作(1.分流,也是分区 2.计算 3.网络传输 )
RDD: 类似于数据传输的管道
什么是模型?
数据结构:数组 链表 等
hashmap 一个节点放8个, 链表长度为8,不操作,但是第9个时,就开始数据倾斜,开始修正,hashmap的数组默认长度为16,这时候开始扩容2倍,当放第10个时,数组再扩容2倍,64, 再放11个时,修改链表数据结构变成红黑二叉树
ArrayList,LinkedList, 是底层在存,而不是他存,这两个只是将底层结构封装起来,所以 ArrayList LinkedList也是工具
JAVA中,模型是一个对象(东西都封装好了,拿来用)
注意
trim去掉的是半角空格(老外的),并不能去掉全角空格(亚洲)
1.RDD对象是如何构建的?
new,反射,反序列化,克隆(.clone内存中直接复制)
new: 调用类构造方法
反射: 使用 Class.forName() 反射方式创建对象时,会通过类加载器加载类字节码,然后调用默认的无参构造方法初始化对象。
反序列化: 根据对象的字节流重新转化为对象.
装饰者设计模式:将多个功能组合起来
工厂模式:造出来的都有共同特性
RDD的对象是不能自己构建的,需要由框架进行构建.
2.RDD对象的关系
RDD其中封装的计算逻辑称之为最小计算单元(基本运算±*/)
计算时,将多个RDD功能组合在一起实现复杂功能
parallelize是个啥意思? 并行

3个分区,numSlices 分区数,
如果不传分区数,就默认使用当前环境中的最大虚拟核数(local的后面那个数)
对接磁盘文件时用textFile
项目路径以当前项目的根路径为基准的

直接读取多个文件,逗号隔开,
或者也可以直接传目录,
想读多个文件可以用通配符

用逗号隔开的数据的文件一般叫csv
用tab隔开的数据的文件叫tsv
textFile也能传2个参数,第二个参数是文件的最小分区数
为啥是最小?
默认为2
Spark是基于MapReduce开发的
Spark是无法读取文件的,底层读文件采用的是Hadoop方式,所以文件分区不是Spark决定的,是Hadoop决定的,Hadoop读取文件的切片就是Spark的分区.

每个分区放2个,余1 超过了半个,所以必须额外创建
切片时,大于1.1就需要额外创建
Hadoop最大分区为128
先比较切片的最小值,找到最小值,按最小值切

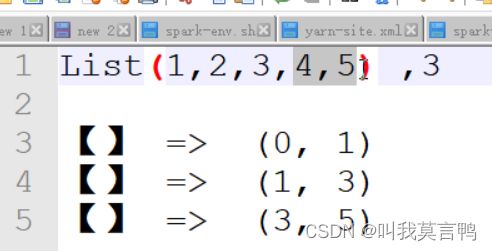
分区数据

使用paralize 分3各区,他是能咋分
1.zhangsan 2. lisi 3.wangwu zhaoliu
1.zhangsan 2. lisi tianqi 3.wangwu zhaoliu