(论文总结)Temporal Pyramid Network for Action Recognition

一、大致介绍
本文提取出了一个关注视频中动作快慢的网络,与SlowFast类似,但是SlowFast是将一个流分为两个帧率不同的分支最后再融合。而本文是结合了特征金字塔的思想来特征融合。二者有一定的区别,效果也再文中作出了对比。
论文地址:2004.03548.pdf (arxiv.org)
二、本文的结构
2.1 背景

文中举了一个例子:walking,jogging and running,三种行走的速率不同,如果统一处理的话会加大运算量,所以本文旨在研究如何更好的将不同动作速率的行为进行高效的特征提取。上图也举了例子,对比了剪羊毛和翻跟斗的变化快慢。
2.2传统方法的问题
用多个特征金字塔结构来分别用不同的网络提取不同速率的特征,计算量非常大,而且重复性工作很多,如果说能够只用一个网络对输入的帧提取一次,然后对其进行T维度的上采样或下采样,并将他们结合起来,效果会不会更好?
2.3本文的TPN
先放结构

文中认为,一个深度网络本身已经具备了不同深度的visual tempos(视觉速度,帧率)的特征,比如T维度,那么这样直接可以再网络本身进行融合。不同速率的特征提取不再需要增加分支,而是只需要在网络本身不同的深度之间进行提取。类似如果要在在图像本身提取深层次特征的话,用深度网络结合金字塔将高层和低层信息进行融合。
对于融合这些单网络内不同速率(维度或各层的信息)的特征,本文提出了两个方式:
(1)Single-depth pyramid:
在某一层采样M个不同速率的特征
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xiAfe04w-1622472125729)(C:\Users\张plus\AppData\Roaming\Typora\typora-user-images\image-20210531210650712.png)]](http://img.e-com-net.com/image/info8/621c7c43e2eb47e291e6d91367a32a0b.jpg)
采样到的特征为下图

每个特征的尺寸如下:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ic6PVjhZ-1622472125731)(C:\Users\张plus\AppData\Roaming\Typora\typora-user-images\image-20210531210811542.png)]](http://img.e-com-net.com/image/info8/3f9b75eccfe04cfca69b3b132d24ee85.jpg)
这样简单暴力,但是会限制有效性,因为他们都是单个粒度(每个特征都是固定的速率,不同速率之间没有进行融合)上表示的视频信息。
(2)Multi-depth pyramid:
直接采用不同层的特征,且满足下面CWH的大小关系

这样又得到了更丰富的空间维度信息,融合的时候应该更认真处理。
这里要注意一点:第二种方式的不同层之间空间维度和时间维度不同,融合的时候要关注。
他们是怎么融合呢?首先看空间的处理方式
Spatial Semantic Modulation
用不同水平的卷积来处理空间维度的通道数;还提到了损失函数,采用交叉熵损失,然后融合多个损失,这样可以让梯度更新的时候来源更加广泛,接受更强的分类效果监督,从而增强语义信息。

然后是时间的处理方式
Temporal Rate Modulation
之前在输入帧上用金字塔,能够动态调整速率以增强适用性。但TRN运行于一个主干网络上,所以只用原始网络深度来决定。
用超参数
跟在空间语义模块后做下采样。

之后就是融合
Information Flow of TPN

+是 element-wise addition(对应元素相加),g是上采样或下采样运算。还有两个方式Cascade Flow and Parallel Flow.如下图

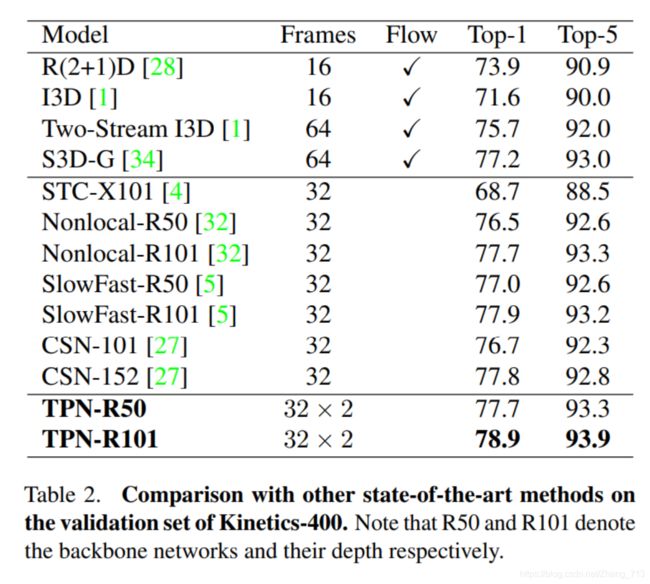
三、实验

用ResNet的res2, res3, res4, res5建立TPN,空间下采样的时候用4,8,16,32的倍速。每个层的空间语义的变化由卷积决定,特征维度不管是增加还是减少都到1024。时间速率的变化由卷积和max pooling之后来获得。最后用全连接层作预测。


四、总结
TPN的金字塔机制可以作为插件用于视频任务中2D和3D网络中来捕捉视觉速度( visual tempos)。