diffusion model (七) diffusion model是一个zero-shot 分类器
Paper: Your Diffusion Model is Secretly a Zero-Shot Classifier
Website: diffusion-classifier.github.io/
文章目录
-
- 相关阅读
- 背景
- 方法大意
-
- diffusion model的背景知识
- 如何将diffusion model应用到zero-shot classification
-
- 如何求解
- 实验
- 参考文献
相关阅读
- diffusion model(一)DDPM技术小结 (denoising diffusion probabilistic)
- diffusion model(二)—— DDIM技术小结
- diffusion model(三)—— classifier guided diffusion model
- diffusion model(四)文生图diffusion model(classifier-free guided)
- diffusion model(五)stable diffusion底层原理(latent diffusion model, LDM
背景
最近,出现了一系列大规模的文生图模型,它们极大地增强了我们通过文字生成图片的能力。这些模型可以根据各种提示生成逼真的图片,展现出惊人的综合创作能力。到目前为止,几乎所有的应用都只关注了模型的生成功能,但实际上,这些模型还能提供条件密度估计,这对于处理图像生成之外的任务也很有用。
本篇文章指出类似stable diffusion这样的大规模文本转图像模型所计算出的密度估计,可以被用来进行“零样本分类” (zero-shot classification),而不需要额外的训练。
方法大意
diffusion model的背景知识
从前面diffusions系列文章中我们知道,diffuison model的去噪过程是一个马尔可夫过程
p θ ( x 0 ) = ∫ p θ ( x 0 : T ) d x 1 : T 其中: p θ ( x 0 : T ) : = p θ ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , σ t I ) (1) p_\theta(x_{0})= \int p_\theta(x_{0:T})dx_{1:T} \\ \text{其中:} \space p_\theta(x_{0:T}) := p_\theta(x_T)\prod_{t=1}^{T} p_\theta (x_{t-1}|x_t) \\ p_\theta (x_{t-1}|x_t) = \mathcal{N}(x_{t-1}; \mu_\theta(x_t, t) , \sigma_t \textbf{I}) \tag{1} pθ(x0)=∫pθ(x0:T)dx1:T其中: pθ(x0:T):=pθ(xT)t=1∏Tpθ(xt−1∣xt)pθ(xt−1∣xt)=N(xt−1;μθ(xt,t),σtI)(1)
即:
p θ ( x 0 ) = ∫ p θ ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t ) d x 1 : T p θ ( x t − 1 ∣ x t ) = N ( x t − 1 ; μ θ ( x t , t ) , σ t I ) (2) p_\theta(x_{0})= \int p_\theta(x_T)\prod_{t=1}^{T} p_\theta (x_{t-1}|x_t) dx_{1:T} \\ p_\theta (x_{t-1}|x_t) = \mathcal{N}(x_{t-1}; \mu_\theta(x_t, t) , \sigma_t \textbf{I}) \tag{2} pθ(x0)=∫pθ(xT)t=1∏Tpθ(xt−1∣xt)dx1:Tpθ(xt−1∣xt)=N(xt−1;μθ(xt,t),σtI)(2)
p θ ( x T ) p_\theta(x_T) pθ(xT)服从正态分布 N ( x T ; 0 , I ) \mathcal{N}(x_T; 0, \mathrm{I}) N(xT;0,I), 其与 θ \theta θ无关,可记作 p ( x T ) p(x_T) p(xT)
当给定条件 c c c时,采样过程可以表述为
p θ ( x 0 ∣ c ) = ∫ p ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t , c ) d x 1 : T (3) p_\theta(x_{0} | c)= \int p(x_T)\prod_{t=1}^{T} p_\theta (x_{t-1}|x_t, c) dx_{1:T} \\ \tag{3} pθ(x0∣c)=∫p(xT)t=1∏Tpθ(xt−1∣xt,c)dx1:T(3)
由于涉及到积分,直接最大化 p θ ( x 0 ∣ c ) p_\theta(x_0|c) pθ(x0∣c)很难求解,因此diffusion model的训练采用了最小化对数似然的证据下界(Evidence Lower Bound, ELBO)。通过推导得出:最大化 p θ ( x 0 ∣ c ) p_\theta(x_0|c) pθ(x0∣c)相当于优化下界【预测噪声和实际添加噪声差异的期望越小越好】。详细过程可参考文献[1]中的式32-45, 86-92
log p θ ( x 0 ∣ c ) ≥ E q [ log p θ ( x 0 : T ∣ c ) q ( x 1 : T ∣ x 0 ) ] = E q [ log p ( x T ) ∏ t = 1 T p θ ( x t − 1 ∣ x t , c ) ∏ t = 1 T q ( x t ∣ x t − 1 ) ] = E q [ log p ( x T ) p θ ( x 0 ∣ x 1 , c ) ∏ t = 2 T p θ ( x t − 1 ∣ x t , c ) q ( x T ∣ x T − 1 ) ∏ t = 1 T − 1 q ( x t ∣ x t − 1 ) ] ⋯ = − E ϵ [ ∑ t = 2 T w t ⏟ 当训练时以均匀分布采样时间步时 w t = 1 ∥ ϵ − ϵ θ ( x t , c ) ∥ 2 − log p θ ( x 0 ∣ x 1 , c ) ⏟ 当T足够大时,该项 → 0 ] + C ⏟ 常数与c无关 ≈ 去除无关项 − E ϵ , t [ ∥ ϵ − ϵ θ ( x t , c ) ∥ 2 ] (4) \begin{aligned} \log p _ { \theta } ( x _ { 0 } \vert c ) &\ge \mathbb{E} _ { q } [ \log \frac { p _ { \theta } ( x _ { 0 : T } | c ) } { q ( x _ { 1 : T } \vert x _ { 0 } ) } ] \\ &= \mathbb{E} _ { q } [ \log \frac { p(x_T)\prod_{t=1}^{T} p_\theta (x_{t-1}|x_t, c)} { \prod _ { t = 1 } ^ { T } q ( x _ { t } \vert x _ { t - 1 } ) } ] \\ & = \mathbb{ E } _ { q } [ \log \frac { p ( x _ { T } ) p _ { \theta } ( x _ { 0 } \vert x _ { 1 } , c) \prod _ { t = 2 } ^ { T } p _ { \theta } ( x _ { t - 1 } \vert x _ { t } , c ) } { q ( x _ { T } \vert x _ { T - 1 } ) \prod _ { t = 1 } ^ { T - 1 } q ( x _ { t } \vert x _ { t - 1 } ) } ] \\ & \cdots \\ &= - \mathbb{E} _ { \epsilon } [ \sum _ { t = 2 } ^ { T } \underbrace{w _ { t }}_{\text{当训练时以均匀分布采样时间步时}w_t=1} \Vert \epsilon - \epsilon _ { \theta } ( x _ { t } , c ) \Vert ^ { 2 } - \underbrace {\log p _ { \theta } ( x _ { 0 } \vert x _ { 1 } , c )}_{\text{当T足够大时,该项} \rightarrow 0} ] + \underbrace{C}_{\text{常数与c无关}} \\ & \stackrel{去除无关项} \approx - \mathbb{E} _ { \epsilon, t} \left[ \Vert \epsilon - \epsilon _ { \theta } ( x _ { t } , c ) \Vert ^ { 2 } \right]\\ \end{aligned}\tag{4} logpθ(x0∣c)≥Eq[logq(x1:T∣x0)pθ(x0:T∣c)]=Eq[log∏t=1Tq(xt∣xt−1)p(xT)∏t=1Tpθ(xt−1∣xt,c)]=Eq[logq(xT∣xT−1)∏t=1T−1q(xt∣xt−1)p(xT)pθ(x0∣x1,c)∏t=2Tpθ(xt−1∣xt,c)]⋯=−Eϵ[t=2∑T当训练时以均匀分布采样时间步时wt=1 wt∥ϵ−ϵθ(xt,c)∥2−当T足够大时,该项→0 logpθ(x0∣x1,c)]+常数与c无关 C≈去除无关项−Eϵ,t[∥ϵ−ϵθ(xt,c)∥2](4)
如何将diffusion model应用到zero-shot classification
对于一个分类模型,给定输入 x x x,模型输出类别的概率向量 c c c, 即 p θ ( c ∣ x ) p_\theta(c|x) pθ(c∣x),为了用diffusion model求解 p θ ( c ∣ x ) p_\theta(c|x) pθ(c∣x),需要用到贝叶斯公式
p θ ( c i ∣ x ) = p ( c i ) p θ ( x ∣ c i ) ∑ j p ( c j ) p θ ( x ∣ c j ) (5) p _ { \theta } ( c _ { i } \vert x ) = \frac { p ( c _ { i } ) \, p _ { \theta } ( x \vert c _ { i } ) } { \sum _ { j } p ( c _ { j } ) \, p _ { \theta } ( x \vert c _ { j } ) } \tag{5} pθ(ci∣x)=∑jp(cj)pθ(x∣cj)p(ci)pθ(x∣ci)(5)
不妨假设各个类别的先验概率相同,有 p ( c 1 ) = p ( c 2 ) = ⋯ = p ( c N ) = 1 N p(c_1)=p(c_2)=\cdots=p(c_N) = \frac{1}{N} p(c1)=p(c2)=⋯=p(cN)=N1
式5可写作
p θ ( c i ∣ x ) = p θ ( x ∣ c i ) ∑ j p θ ( x ∣ c j ) = exp { log ( p θ ( x ∣ c i ) ) } ∑ j exp { log ( p θ ( x ∣ c j ) ) } (6) \begin{aligned} p _ { \theta } ( c _ { i } \vert x ) &= \frac { p _ { \theta } ( x \vert c _ { i } ) } { \sum _ { j } \, p _ { \theta } ( x \vert c _ { j } ) } \\ & = \frac { \exp \{ \log {( p _ { \theta } ( x \vert c _ { i } ) } ) \} } { \sum _ { j } \, \exp \{ \log {( p _ { \theta } ( x \vert c _ { j } ))} \} } \end{aligned} \tag{6} pθ(ci∣x)=∑jpθ(x∣cj)pθ(x∣ci)=∑jexp{log(pθ(x∣cj))}exp{log(pθ(x∣ci))}(6)
根据式4,我们知道 log p θ ( x 0 ∣ c ) ≈ − E ϵ , t [ ∥ ϵ − ϵ θ ( x t , c ) ∥ 2 ] \log p _ { \theta } ( x _ { 0 } \vert c ) \approx - \mathbb{E} _ { \epsilon, t} \left[ \Vert \epsilon - \epsilon _ { \theta } ( x _ { t } , c ) \Vert ^ { 2 } \right] logpθ(x0∣c)≈−Eϵ,t[∥ϵ−ϵθ(xt,c)∥2], 带入上式得
p θ ( c i ∣ x ) ≈ exp { − E ϵ , t [ ∥ ϵ − ϵ θ ( x t , c i ) ∥ 2 ] } ∑ j exp { − E ϵ , t [ ∥ ϵ − ϵ θ ( x t , c j ) ∥ 2 ] } (7) \begin{aligned} p _ { \theta } ( c _ { i } \vert x ) & \approx \frac { \exp \{ - \mathbb{E} _ { \epsilon, t} \left[ \Vert \epsilon - \epsilon _ { \theta } ( x _ { t } , c_i ) \Vert ^ { 2 } \right]\} } { \sum _ { j } \, \exp \{ - \mathbb{E} _ { \epsilon, t} \left[ \Vert \epsilon - \epsilon _ { \theta } ( x _ { t } , c_j ) \Vert ^ { 2 } \right] \} } \end{aligned} \tag{7} pθ(ci∣x)≈∑jexp{−Eϵ,t[∥ϵ−ϵθ(xt,cj)∥2]}exp{−Eϵ,t[∥ϵ−ϵθ(xt,ci)∥2]}(7)
由此我们推导出了基于diffusion model的classifier。
如何求解
我们看到求式7的关键是不同类别下,预测的噪声和实际噪声差异的期望。这里面有两个随机变量,分别是 ϵ , t \epsilon, t ϵ,t,其中 ϵ ∼ N ( 0 , I ) \epsilon \sim \mathcal{N}(0, \mathrm{I}) ϵ∼N(0,I), t ∼ u n i f o r m ( 0 , T ) t \sim \mathrm{uniform}(0, T) t∼uniform(0,T)。可以用蒙特卡诺采样对上述期望进行估计,假定依概率对上述两个随机变量采样 K K K次,得到 { ( ϵ i , t i ) ∣ i = 0 , 1 , ⋯ K } \{ (\epsilon_i, t_i)|i = 0, 1, \cdots K \} {(ϵi,ti)∣i=0,1,⋯K},可将式7转化为
E ϵ , t [ ∥ ϵ − ϵ θ ( x t , c j ) ∥ 2 ] = 1 K ∑ i = 1 K ∥ ϵ i − ϵ θ ( x t i , c j ) ∥ 2 (8) \mathbb{E} _ { \epsilon, t} \left[ \Vert \epsilon - \epsilon _ { \theta } ( x _ { t } , c_j ) \Vert ^ { 2 } \right] = \frac { 1 } { K } \sum _ { i = 1 } ^ { K } \Vert \epsilon _ { i } - \epsilon _ { \theta } (x_{t_i}, c _ { j } ) \Vert ^ { 2 } \tag{8} Eϵ,t[∥ϵ−ϵθ(xt,cj)∥2]=K1i=1∑K∥ϵi−ϵθ(xti,cj)∥2(8)
当我们求出每一个类别 j j j下的 p θ ( c j ∣ x ) p _ { \theta } ( c _ { j } \vert x ) pθ(cj∣x),值最大的就是预测出来的类别。
细心的同学发现了,为了准确的估计期望,需要用蒙特卡诺方法采样较多的样本,一个样本意味着需要用diffusion model推理一次得到预测的噪声,当样本量较大时,推理时间会非常大。总的推理次数为 K ∗ # c K * \# c K∗#c, K K K为蒙特卡诺的采样的样本数目, # c \# c #c为类别数目, # c = N \#c=N #c=N。
在实践中为了减少推理速度,作者修改了对 t i , ϵ i t_i, \epsilon_i ti,ϵi这两个随机变量的采样逻辑,也将上面的one-stage分类的范式转化为two-stage。感兴趣的读者可以阅读原文。本文简单介绍核心思路:
对于第一个提速方案:修改采样逻辑。主要基于实验观测,如下图。
(注:横轴表示 ϵ i \epsilon_i ϵi的采样数目。Uniform: t = [ 0 , 1 , 2 , . . , 1000 ] t = [0,1, 2, .., 1000] t=[0,1,2,..,1000], 0, 500, 1000: t = [ 0 , 500 , 1000 ] t=[0, 500, 1000] t=[0,500,1000], even 10: t = [ 0 , 10 , 20 , . . . , 1000 ] t = [0, 10, 20, ..., 1000] t=[0,10,20,...,1000])

对于第二个提速方案:作者将 N = { ( ϵ i , t i ) ∣ i = 0 , 1 , ⋯ K } N= \{ (\epsilon_i, t_i)|i = 0, 1, \cdots K \} N={(ϵi,ti)∣i=0,1,⋯K}划分了成两个集合 K 1 , K 2 K_1, K_2 K1,K2, 首先在 K 1 K_1 K1中根据式7估计 x x x的类别。保留概率最高的 M M M个类别。随后在集合 K 2 K_2 K2上对前 M M M个可能的类别继续用式7计算概率。此时的计算量从 K ∗ # c K * \#c K∗#c变为 K 1 ∗ # c + ( K 2 ) ∗ M K_1 * \#c + (K_2) * M K1∗#c+(K2)∗M。
实验
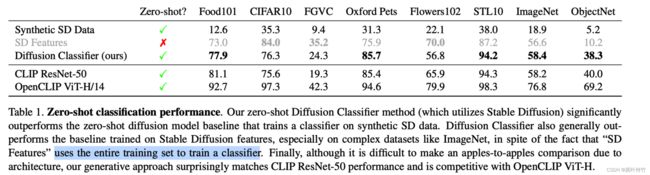
作者对比同为zero-shot classifier的CLIP,结果如下。zero-shot的能力以及接近了基于renset50的CLIP。但与openCLIP ViT-H/14还有较大差距。其它更多的实验对比请见原始论文。
参考文献
[1]: Luo, Calvin. “Understanding diffusion models: A unified perspective.” arXiv preprint arXiv:2208.11970 (2022).
[2]: Li, Alexander C., et al. “Your diffusion model is secretly a zero-shot classifier.” arXiv preprint arXiv:2303.16203 (2023).