论文《TALLRec: An Effective and Efficient Tuning Framework to Aligh LLM with Recommendation》阅读
论文《TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation》
- 论文概况
- Background and Introduction
- Preliminary
- 问题形式化
- 方法论
-
- TALLRec Tuning形式化
- 基于LoRA的轻量化更新策略
- 大模型选择
- Experiments
- Some Questions
论文概况
今天给大家带来的是来自中科大 何向南 老师团队,由一作 Keqin Bao等人完成的论文《TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation》,论文主要聚焦于将大模型应用于推荐场景,并提出了 TALLRec 模型,目前还是arXiv预印版,论文具体发表情况暂时未知。
论文地址:https://arxiv.org/abs/2305.00447
代码地址:https://anonymous.4open.science/r/LLM4Rec-Recsys
由于本人刚开始对大预言模型(Large Language Model, LLM)进行探索,因此在介绍本文的过程中产生的理解误差和错误,希望大家能够理解并在评论区指出。
本文的主要贡献在于提出了一个行之有效的应用LLM并使用推荐数据进行参数更新的轻量化LLM训练procedure。下面进行详细介绍:
Background and Introduction
本文旨在完成大模型在推荐系统场景下的应用。通过下图可以看到,作者直接利用ChatGPT去判断物品是否值得推荐并在数据集上进行实验统计,得到的结果以AUC作为统计指标,得到的结果如下图最右部分所示。分别在Alpaca、Davinci-002、Davinci-003、ChatGPT上进行了实验,得到的结果都在0.5左右,也即和瞎猜的差不多(50%的概率)。以此作为motivation,完成了本文。
作者指出,现存的关于LLM for recommendation模型主要集中在使用别人训练好的公开模型API作为工具,对现有推荐模型完成的结果(如MF/LightGCN)进行结果重排序,完成上下文学习(In-Context Learning, ICL)。如上所示,这样简单粗暴地直接对一个序列输入大模型,判断结果并不好,与瞎猜无异。
作者认为造成直接进行ICL失败的原因主要如下:(1)LLM与推荐模型训练有差距,造成了在推荐上的性能损失;(2)ICL的表现很大程度取决于前面的推荐模型,从而限制了LLM的表现。基于此,作者提出构造推荐语言大模型(Large Recommendation Language Model, IRLM)来提高大模型在推荐上的表现。
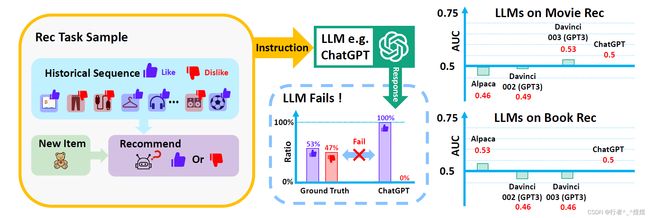
具体来说,作者设计完成了一个对训练好的大模型进行针对推荐任务的定制化的轻量化tuning过程——TALLRec。大模型选用LLaMA-7B,轻量化设计是指应用了tuning框架LoRA,使得 tuning 过程能够在3090上完成(显存容量:24GB)。
模型的突出亮点在于:(1)少量样本(few-shot)就可以有效提高模型性能;(2)模型具备很好的泛化能力(体现在跨域推荐CDR上)。
Preliminary

这里首先展示Instruction Tuning (指令微调)整体过程,作者概括为4个阶段。
- 构造 任务指令Task Instruction;
- 指定 任务输入 Task Input 和 任务输出 Task Output;
- 构造 指令输入 Instruction Input ( Task Instruction + Task Input ) 和 指令输出 Instruction Output( 也即 Task Output );
- 根据 <指令输入,指令输出> 对,完成对LLM模型的精调。
问题形式化
针对任意用户,历史交互数据表示为 [ i 1 , i 2 , ⋯ , i n ] [i_1, i_2, \cdots, i_n] [i1,i2,⋯,in],用户给物品列表对应的交互评分表示为 [ r 1 , r 2 , ⋯ , r n ] [r_1, r_2, \cdots, r_n] [r1,r2,⋯,rn],对于任意评分 r i ∈ { 0 , 1 } r_i \in \{0,1\} ri∈{0,1} (implicit feedback),其中 i ∈ [ 1 , n ] i\in [1, n] i∈[1,n] 表示物品标号。
LLM 模型表示为 M \mathcal{M} M,作者使用 M \mathcal{M} M 建造得到 LRLM 模型 M r e c \mathcal{M}_{rec} Mrec,用于预测 i n + 1 i_{n+1} in+1 的得分。微调具体步骤分配如下(可参考Architecture图):
Task Input: [ i 1 , i 2 , ⋯ , i n ] , i n + 1 ,以及 [ r 1 , r 2 , ⋯ , r n ] Task Instruction: r n + 1 是否等于 0 ? Task Output: r n + 1 \begin{aligned} \text{Task Input:} &\ \ \ [i_1, i_2, \cdots, i_n] \text{,} i_{n+1} \text{,以及} [r_1, r_2, \cdots, r_n] \\ \text{Task Instruction:} &\ \ \ r_{n+1} \text{是否等于} 0?\\ \text{Task Output:} &\ \ \ r_{n+1} \\ \end{aligned} Task Input:Task Instruction:Task Output: [i1,i2,⋯,in],in+1,以及[r1,r2,⋯,rn] rn+1是否等于0? rn+1

方法论
TALLRec Tuning形式化
具体到TALLRec的训练过程,作者经过两轮tuning:
第一轮: Instruction Tuning,使用了 Alpaca 提供的数据进行模型精调(这里不是太清楚Alpaca的使用)。
第二轮:Rec Tuning,即针对推荐的fine-tuning。具体就是把历史数据分别分成 Like 和 Dislike, 结合预测目标物体构成 Rec Input;“用户是否会 Like i n + 1 i_{n+1} in+1” 作为 Rec Instruction;对应到 r n + 1 r_{n+1} rn+1 的 “Yes/No” 构成 Rec Output。
整体精调过程形式化表达如下:
max Φ ∑ ( x , y ) ∈ Z ∑ t = 1 ∣ y ∣ log ( P Φ ( y t ∣ x , y < t ) ) (1) \max _{\Phi} \sum_{(x, y) \in \mathcal{Z}} \sum_{t=1}^{|y|} \log \left(P_{\Phi}\left(y_{t} \mid x, y_{
其中, Φ \Phi Φ 表示模型 M \mathcal{M} M 中的模型参数,模型针对所有训练对 ( x , y ) (x, y) (x,y),通过 1 到 t − 1 t-1 t−1 序列预测第 t t t 个token。具体到rec tuning同理。
基于LoRA的轻量化更新策略
这里作者employ了 LoRA 作为Tuning 轻量化框架,大概思想就是大模型参数众多,但是好多是用不到的,在fine-tune过程中只需要更新一部分数据就可以了,没有必要全更新。LoRA将LLM模型参数freeze掉,然后引入了一个可训练的秩分解矩阵用于更新参数,实现只需要更新一部分参数就能达到fine-tune的目的(据介绍达到了只需要更新千分之几的地步)。(这里关于LoRA的工作还没有进行了解,后续读过论文之后再进行详细分享,论文引用附在后面1)
上述过程形式化表示如下:
max Θ ∑ ( x , y ) ∈ Z ∑ t = 1 ∣ y ∣ log ( P Φ + Θ ( y t ∣ x , y < t ) ) (2) \max _{\Theta} \sum_{(x, y) \in \mathcal{Z}} \sum_{t=1}^{|y|} \log \left(P_{\Phi+\Theta}\left(y_{t} \mid x, y_{
这里的 Φ \Phi Φ 就是大模型 M \mathcal{M} M 的参数, Θ \Theta Θ 表示 LoRA 引入的参数。可以看到 Φ \Phi Φ 没再更新,更新的只有 Θ \Theta Θ。
大模型选择
备选项包括GPT系列、PaLM、ChinChilla、LLaMA。作者基于安全考虑和开源问题,最终选择了LLaMA。
Experiments
baseline选择:包含传统模型和LLMs。传统模型包括GRU4Rec、Caser、SASRec、DROS,以及加入BERT训练过的语料feature的改进版模型GRU-BERT、DROS-BERT。(使用BERT训练文本语料feature,进行连接后输入原模型)。
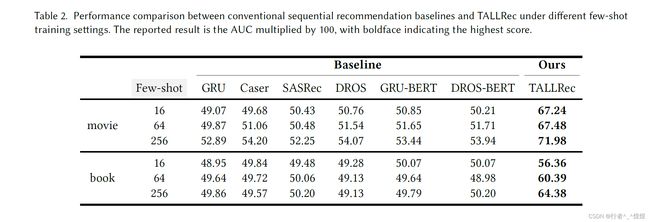
LLM模型包括Alpaca、Text-Davinci-002、Text-Davinci-003、ChatGPT。

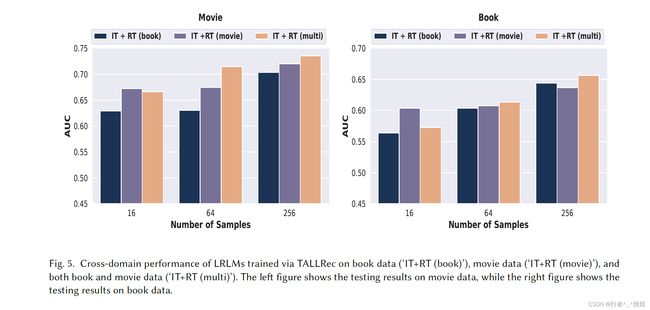
消融实验:
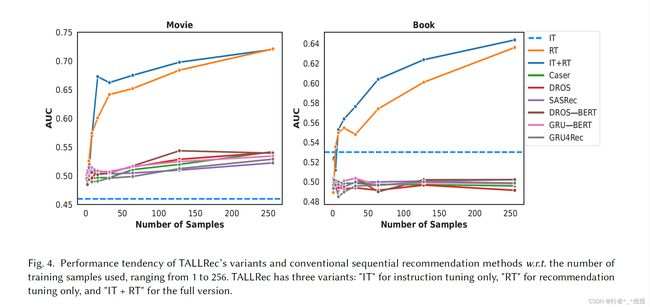
K-shot 分析实验结果:
Some Questions
为什么baseline模型只使用GPT-3.5进行,不能使用LLaMA吗?如果加入使用LLaMA这样不是会更有说服力吗?(当然作者在intro中指出GPT3.5比LLaMA-7B强很多,这个我不太清楚,求解释。)
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-Rank Adaptation of Large Language Models. In The Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net. https://openreview.net/forum?id=nZeVKeeFYf9 ↩︎