【C语言督学训练营 第二十一天】汇编语言零基础入门
文章目录
- 前言
- 1.C语言源文件转汇编
- 2.汇编指令格式
- 3.汇编常用指令
-
- 3.1 相关寄存器
- 3.2 常用指令
- 3.3 数据传送指令
- 3.4 算术/逻辑运算指令
- 3.5 控制流指令
- 3.6 条件码
- 4.如何定义汇编中的变量
- 5.选择循环汇编实战
- 6.函数调用汇编实战
- 7.C语言源文件转机器指令
前言
汇编语言是一种功能很强的程序设计语言,也是利用计算机所有硬件特性并能直接控制硬件的语言。学好以后可以做单片机、做操作系统、编译器,反正底层开发肯定是需要的。
汇编语言(assembly language)是一种用于电子计算机、微处理器、微控制器或其他可编程器件的低级语言,亦称为符号语言。在汇编语言中,用助记符代替机器指令的操作码,用地址符号或标号代替指令或操作数的地址。
在不同的设备中,汇编语言对应着不同的机器语言指令集,通过汇编过程转换成机器指令。特定的汇编语言和特定的机器语言指令集是一一对应的,不同平台之间不可直接移植。
从上面可以看出汇编语言的强大之处,尔强任尔强,我们要做的是能够读懂汇编语言代码,能够了解到汇编语言中的基础知识,先看一道408专业课真题,代码部分给出了C语言代码与汇编代码的核心部分,我们要能从中看出这是干嘛的,然后解出题目即可!

1.C语言源文件转汇编
在进行C语言源文件转汇编之前,需要先配置环境变量,将我们之前安装的mingw64里面的bin目录配置到path变量中,这样就可以直接在黑窗口使用gcc命令了!配置环境变量教程网上一堆我就不啰嗦了,下面我说说如何生成汇编文件以C语言代码编译生成可执行文件的过程(这个过程在考纲之内,但是考试概率比较低)。
编译过程(了解即可,是大纲范围,考的概率不高)
- 第一步: main.c–>编译器–》main.s文件(.s文件就是汇编文件,文件内是汇编代码)
- 第二步:我们的main.s汇编文件—》汇编器—》main.obj
- 第三步: main.obj文件–》链接器–》可执行文件exe
接下来让我们使用Clion生成汇编代码吧!
首先进入源文件所在目录(这里指的是mytest目录):

执行以下命令生成汇编文件(这种方式生成的与intel的汇编代码有一定的区别!):
gcc -S -fverbose-asm main.c
下面是生成与考研格式一样的汇编代码intel 32:
gcc -m32 -masm=intel -S -fverbose-asm main.c

2.汇编指令格式
在去看汇编指令前,我们来看下CPU是如何执行我们的程序的,如下图所示,我们编译后的可执行程序,也就是main.exe是放在代码段的,PC指针寄存器存储了一个指针,始终指向要执行的指令,读取了代码段的某一条指令后,会交给译码器来解析,这时候译码器就知道要做什么事情了,CPU 中的计算单元加法器不能直接对栈上的某个变量a,直接做加1操作的,需要首先将栈,也就是内存上的数据,加载到寄存器中,然后再用加法器做加1操作,再从寄存器搬到内存上去。

一条机器指令分为以下两部分:
操作码字段:表征指令的操作特性与功能(指令的唯一标识)︰不同的指令操作码不能相同。
地址码字段:指定参与操作的操作数的地址码。
指令中指定操作数存储位置的字段称为地址码,地址码中可以包含存储器地址。也可包含寄存器编号。指令中可以有一个、两个或者三个操作数,也可没有操作数, 根据一条指令有几个操作数地址,可将指令分为零地址指令。一地址指令、二地址指令、三地址指令。4个地址码的指令很少被使用(考研考不到,这里不列了)


二地址指令格式中,从操作数的物理位置来说有可归为三种类型
- 寄存器-寄存器(RR)型指令:需要多个通用寄存器或个别专用寄存器,从寄存器中取操作数,把操作结果放入另一个寄存器,机器执行寄存器-寄存器型的指令非常快,不需要访存.
- 寄存器-存储器(RS)型指令:执行此类指令时,既要访问内存单元,又要访问寄存器.
- 存储器-存储器(SS)型指令:操作时都是涉及内存单元,参与操作的数都是放在内存里,从内存某单元中取操作数,操作结果存放至内存另一单元中,因此机器执行指令需要多次访问内存。
寄存器英文: register
存储器英文: storage
| 名称 | 特征 | 常见系统 | 简称 | 英文名 |
|---|---|---|---|---|
| 复杂指令集 | 变长 | x86 | CISC | Complex lnstruction Set Computer |
| 精简指令集 | 等长 | arm | RISC | Reduced lnstruction Set Computin |
3.汇编常用指令
3.1 相关寄存器

3.2 常用指令

3.3 数据传送指令


3.4 算术/逻辑运算指令


3.5 控制流指令


3.6 条件码
编译器通过条件码(标志位)设置指令和各类转移指令来实现程序中的选择结构语句。
条件码(标志位)
除了整数寄存器,CPU还维护着一组条件码(标志位)寄存器,它们描述了最近的算术或逻辑运算操作的属性。可以检测这些寄存器来执行条件分支指令,最常用的条件码有:
- CF:进(借)位标志。最近无符号整数加(减)运算后的进(借)位情况。有进(借)位,CF=1;否则CF=0。如(unsigned) t <(unsigned) a,因为判断大小是相减。
- ZF:零标志。最近的操作的运算结算是否为0。若结果为0,ZF=1;否则ZF=0。如( t ==O) 。
- SF:符号标志。最近的带符号数运算结果的符号。负数时,SF=1;
否则SF=O。 - OF:溢出标志。最近带符号数运算的结果是否溢出,若溢出,OF=1;否则OF=0。
可见,OF和SF对无符号数运算来说没有意义,而CF对带符号数运算来说没有意义。

常见的算术逻辑运算指令(add、sub、imul、 or、 and、shl、inc、dec、not、sal等)会设置条件码。但有两类指令只设置条件码而不改变任何其他寄存器,即cmp和test 指令, cmp指令和 sub指令的行为一样,test 指令与and指令的行为一样,但它们只设置条件码,而不更新目的寄存器。
注意:乘法溢出后,可以跳转到“溢出自陷指令”,例如 int 0x2e就是一条自陷指令,但是考研只需要掌握溢出,可以跳转到“溢出自陷指令”即可,不需要记自陷指令有哪些。
4.如何定义汇编中的变量
我们针对整型,整型数组,整型指针变量的赋值(浮点与字符等价的),对应的汇编进行解析,首先我们编写下面C代码:
#include 将其转换为汇编语言代码(考研出该类题目的话是以intel为基准,如果我们是windows系统,那么我们可以使用以下命令生成):
gcc -m32 -masm=intel -S -fverbose-asm main.c
- 接下来我们来分析转换后的汇编代码,首先**#号代表注释**,我们从main标签位置开看即可。我们的C代码在让CPU去运行时,其
实所有的变量名都已经消失了,实际是数据从一个空间,拿到另一个空间的过程。 - 栈内变量先定义在低地址还是高地址,取决于操作系统与CPU的组合,你的可能和我的不一样,因此不用去研究,没有意义(也不属于考研大纲范围)。
- 我们访问所有变量的空间都是通过栈指针(esp时刻都存着栈指针,也可以称为栈顶指针)的偏移,来获取对应变量内存空间的数据的)。
.file "main.c"
.intel_syntax noprefix
.text
.def ___main; .scl 2; .type 32; .endef
.section .rdata,"dr"
LC0:
.ascii "i=%d\12\0"
.text
.globl _main
.def _main; .scl 2; .type 32; .endef
_main:
push ebp #
mov ebp, esp #,
and esp, -16 #,
sub esp, 48 #,
# main.c:2: int main() {
call ___main # #调用main函数
# main.c:3: int arr[3] = {1, 2, 3};
mov DWORD PTR [esp+24], 1 # arr,# 把常量1放入栈指针(esp寄存器存的栈指针)偏移量24个字节
mov DWORD PTR [esp+28], 2 # arr,
mov DWORD PTR [esp+32], 3 # arr,
# main.c:5: int i = 5;
mov DWORD PTR [esp+44], 5 # i,
# main.c:6: int j = 10;
mov DWORD PTR [esp+40], 10 # j,# 把常量40放入栈指针(esp寄存器存的栈指针)偏移44个字节,这个位置属于变量j。
# main.c:7: i = arr[2];
mov eax, DWORD PTR [esp+32] # tmp89, arr #把后面地址指向的的数据拿到eax寄存器内。
mov DWORD PTR [esp+44], eax # i, tmp89
# main.c:8: p = arr;
lea eax, [esp+24] # tmp90,# 把后面的地址拿到eax寄存器内。
mov DWORD PTR [esp+36], eax # p, tmp90
# main.c:9: printf("i=%d\n", i);
mov eax, DWORD PTR [esp+44] # tmp91, i
mov DWORD PTR [esp+4], eax #, tmp91
mov DWORD PTR [esp], OFFSET FLAT:LC0 #, #把LC0的地址放到寄存器栈指针指向的位置!
call _printf #
# main.c:10: return 0;
mov eax, 0 # _10,
# main.c:11: }
leave
ret
.ident "GCC: (x86_64-posix-sjlj-rev0, Built by MinGW-W64 project) 8.1.0"
.def _printf; .scl 2; .type 32; .endef
大家转的汇编的偏移值可能和我这里有一些差异,这个没关系,大家理解变量赋值的汇编指令及原理即可,主要掌握的指令是 mov,还有lea,还有PTR。下面是ptr介绍
- ptr – pointer(既指针)得缩写。
汇编里面ptr是规定的字(既保留字),是用来临时指定类型的。(可以理解为, ptr是临时的类型转换,相当于C语言中的强制类型转换)
如mov ax,bx;是把BX寄存器“里”的值赋予AX,由于二者都是寄存器,长度已定(word型),所以没有必要加“WORD”
mov ax,word ptr [bx];是把内存地址等于“BX寄存器的值”的地方所存放的数据,赋予ax。由于只是给出一个内存地址,不知道希望赋予ax 的,是byte还是 word,所以可以用word明确指出;如果不用,既(mov ax, [bx];)则在8086中是默认传递一个字,既两个字节给ax。
intel 中的关键字:
- dword ptr长字(4字节)
- word ptr是双字节
- byte ptr是一字节
5.选择循环汇编实战
先写一段源代码!
#include 生成汇编代码:
.file "main.c"
.intel_syntax noprefix
.text #这里是文字常量区,存放了我们的字符串常量!LC0 LC1是我们要打印字符串的起始地址!
.def ___main; .scl 2; .type 32; .endef
.section .rdata,"dr"
LC0:
.ascii "i is small\0"
LC1:
.ascii "this is loop\0"
.text
.globl _main
.def _main; .scl 2; .type 32; .endef
_main:
push ebp #
mov ebp, esp #,
and esp, -16 #,
sub esp, 32 #,
# main.c:3: {
call ___main #
# main.c:4: int i=5;
mov DWORD PTR [esp+28], 5 # i,
# main.c:5: int j=10;
mov DWORD PTR [esp+24], 10 # j,
# main.c:6: if (i< j)
mov eax, DWORD PTR [esp+28] # tmp89, i
cmp eax, DWORD PTR [esp+24] # tmp89, j #前者减去后者,然后设置条件码
jge L2 #, #判断条件码L2 如果符合jge就跳转到L2标签,否则往下执行,jge是根据条件码ZF和SF来判断的。
# main.c:8: printf("i is small\n");
mov DWORD PTR [esp], OFFSET FLAT:LC0 #,
call _puts #
L2:
# main.c:10: for(i=0;i<5;i++)
mov DWORD PTR [esp+28], 0 # i,
# main.c:10: for(i=0;i<5;i++)
jmp L3 # # 无条件跳转到L3
L4:
# main.c:11: printf( "this is loop\n");
mov DWORD PTR [esp], OFFSET FLAT:LC1 #,
call _puts #
# main.c:10: for(i=0;i<5;i++)
add DWORD PTR [esp+28], 1 # i,
L3:
# main.c:10: for(i=0;i<5;i++)
cmp DWORD PTR [esp+28], 4 # i,比较变量i的值与4的大小,并设置条件码,如果小于等于则直接跳转到L4
jle L4 #,
# main.c:12: return 0;
mov eax, 0 # _11,
# main.c:13: }
leave
ret
.ident "GCC: (x86_64-posix-sjlj-rev0, Built by MinGW-W64 project) 8.1.0"
.def _puts; .scl 2; .type 32; .endef
这一块大家理解选择,循环的汇编指令及原理即可,主要掌握的指令是cmp,ige,jmp,jle等。以及了解一下字符串常量是存在文字常量区。
6.函数调用汇编实战
函数调用的汇编原理解析
先必须明确的一点是,函数栈是向下生长的。所谓向下生长,是指从内存高地址向低地址的路径延伸。于是,栈就有栈底和栈顶,栈顶的地址要比栈底的低。
对x86体系的CPU而言,寄存器ebp可称为帧指针或基址指针(base pointer),寄存器esp可称为栈指针(stack pointer) .
这里需要说明的几点如下。
(1) ebp在未改变之前始终指向栈帧的开始(也就是栈底),所以ebp的用途是在堆栈中寻址(寻址的作用会在下面详细介绍)。
(2) esp会随着数据的入栈和出栈而移动,即esp始终指向栈顶。

如图2所示,假设函数A调用函数B,称函数A为调用者,称函数B为被调用者,则函数调用过程可以描述如下:
(1)首先将调用者(A)的堆栈的基址(ebp)入栈,以保存之前任务的信息。
(2)然后将调用者(A)的栈顶指针(esp)的值赋给ebp,作为新的基址(即被调用者B的栈底)。原有函数的栈顶,是新函数的栈底。
(3)再后在这个基址(被调用者B的栈底)上开辟(一般用sub指令)相应的空间用作被调用者B的栈空间。
(4))函数B返回后,当前栈帧的ebp恢复为调用者A的栈顶(esp),使栈顶恢复函数B被调用前的位置;然后调用者A从恢复后的栈顶弹出之前的ebp值(因为这个值在函数调用前一步被压入堆栈)。
这样,ebp和 esp就都恢复了调用函数B前的位置,即栈恢复函数B调用前的状态。相当于(ret指令做了什么)

可以理解为以下一个过程!
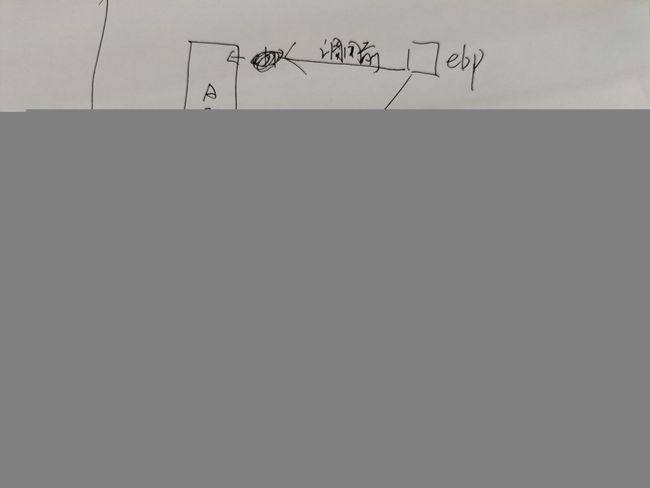
先来写一段C语言有关函数的代码:
#include 生成汇编语言代码:
.file "main.c"
.intel_syntax noprefix
.text
.globl _add
.def _add; .scl 2; .type 32; .endef
# add函数的入口
_add:
#把原有函数的栈基指针压栈
push ebp #
#修改栈基指针的指向(原栈顶将作为被调函数的栈基)
mov ebp, esp #,
# 栈顶向下移16个单位
sub esp, 16 #,
# main.c:4: ret = a + b;
mov edx, DWORD PTR [ebp+8] # tmp93, a
mov eax, DWORD PTR [ebp+12] # tmp94, b
add eax, edx # tmp92, tmp93
mov DWORD PTR [ebp-4], eax # ret, tmp92
# main.c:5: return ret;
mov eax, DWORD PTR [ebp-4] # _4, ret
# main.c:6: }
leave
ret #函数返回,弹出压栈的指令返回地址回到main函数执行!
.def ___main; .scl 2; .type 32; .endef
.section .rdata,"dr"
LC0:
.ascii "add result=%d\12\0"
.text
.globl _main
.def _main; .scl 2; .type 32; .endef
# 当调用main函数时按照下面大小初始化栈空间
_main:
push ebp #
mov ebp, esp #,
and esp, -16 #,
sub esp, 32 #,
# main.c:7: int main() {
call ___main #
# main.c:10: a= 5;
mov DWORD PTR [esp+16], 5 # a,
# main.c:11: p = &a;
#把a变量的地址拿到eax寄存器内
lea eax, [esp+16] # tmp91,
# 把eax寄存器内存放的值放进地址为esp+28的空间内。
mov DWORD PTR [esp+28], eax # p, tmp91
# main.c:12: b = *p + 2;
# 先找到指针变量p指向的地址,将其放进寄存器
mov eax, DWORD PTR [esp+28] # tmp92, p
# 将寄存器指向地址里面的内容拿到寄存器内。
mov eax, DWORD PTR [eax] # _1, *p_5
# main.c:12: b = *p + 2;
# eax寄存器内的值增加2
add eax, 2 # tmp93,
#将计算结果放进[esp+24]空间内。
mov DWORD PTR [esp+24], eax # b, tmp93
# 下面是函数调用实参传递的经典动作,从而理解值传递是如何实现的!
# main.c:13: ret = add(a, b);
mov eax, DWORD PTR [esp+16] # a.0_2, a
mov edx, DWORD PTR [esp+24] # tmp94, b
mov DWORD PTR [esp+4], edx #, tmp94
mov DWORD PTR [esp], eax #, a.0_2
call _add #
# 将计算结果赋值进ret变量内。
mov DWORD PTR [esp+20], eax # ret, tmp95
# main.c:14: printf("add result=%d\n",ret);
mov eax, DWORD PTR [esp+20] # tmp96, ret
mov DWORD PTR [esp+4], eax #, tmp96
mov DWORD PTR [esp], OFFSET FLAT:LC0 #,
call _printf #
# main.c:15: return 0;
mov eax, 0 # _10,
# main.c:16: }
leave
ret
.ident "GCC: (x86_64-posix-sjlj-rev0, Built by MinGW-W64 project) 8.1.0"
.def _printf; .scl 2; .type 32; .endef
下图为main函数调用add函数的原理图!

这一部分大家理解指针变量的间接访问原理,函数调用的原理,到这里大家对于C语言的每一部分在机器上的运行已经非常清晰。这一部分主要掌握的指令是add,sub,call,ret等.
7.C语言源文件转机器指令
下面还需要掌握函数调用时机器码的偏移值,我们前面转的都只有汇编,没有含有机器码,如何得到机器码,需要执行下面两条指令.
第一条:gcc -m32 -g -o main main.c (Mac一致)
第二条:objdump --source main.exe >main.dump (Mac去掉.exe后缀,写为main即可)
如下为部分机器码,我们在考试时考的就是机器码!!!
main.exe: file format pei-i386
Disassembly of section .text:
00401000 <___mingw_invalidParameterHandler>:
401000: f3 c3 repz ret
401002: 8d b4 26 00 00 00 00 lea 0x0(%esi,%eiz,1),%esi
401009: 8d bc 27 00 00 00 00 lea 0x0(%edi,%eiz,1),%edi
00401010 <_pre_c_init>:
401010: 83 ec 1c sub $0x1c,%esp
401013: 31 c0 xor %eax,%eax
401015: 66 81 3d 00 00 40 00 cmpw $0x5a4d,0x400000
40101c: 4d 5a
40101e: c7 05 8c 53 40 00 01 movl $0x1,0x40538c
401025: 00 00 00
401028: c7 05 88 53 40 00 01 movl $0x1,0x405388
40102f: 00 00 00
401032: c7 05 84 53 40 00 01 movl $0x1,0x405384
401039: 00 00 00
40103c: c7 05 20 50 40 00 01 movl $0x1,0x405020
401043: 00 00 00
401046: 74 49 je 401091 <_pre_c_init+0x81>
401048: a3 08 50 40 00 mov %eax,0x405008
40104d: a1 98 53 40 00 mov 0x405398,%eax
401052: 85 c0 test %eax,%eax
401054: 74 2d je 401083 <_pre_c_init+0x73>
401056: c7 04 24 02 00 00 00 movl $0x2,(%esp)
40105d: e8 4a 15 00 00 call 4025ac <___set_app_type>
401062: e8 4d 15 00 00 call 4025b4 <___p__fmode>
401067: 8b 15 a8 53 40 00 mov 0x4053a8,%edx
40106d: 89 10 mov %edx,(%eax)
40106f: e8 dc 05 00 00 call 401650 <__setargv>
401074: 83 3d 1c 30 40 00 01 cmpl $0x1,0x40301c
40107b: 74 63 je 4010e0 <_pre_c_init+0xd0>
40107d: 31 c0 xor %eax,%eax
40107f: 83 c4 1c add $0x1c,%esp
401082: c3 ret
401083: c7 04 24 01 00 00 00 movl $0x1,(%esp)
40108a: e8 1d 15 00 00 call 4025ac <___set_app_type>
40108f: eb d1 jmp 401062 <_pre_c_init+0x52>
401091: 8b 15 3c 00 40 00 mov 0x40003c,%edx
401097: 81 ba 00 00 40 00 50 cmpl $0x4550,0x400000(%edx)