C++ 常见问题的回答【看懂理解--自己说2遍--总结成自己的话--写下来背】【常见问题就那几个挨个来,我觉得3天就够了】
1. 介绍一下内核态、用户态
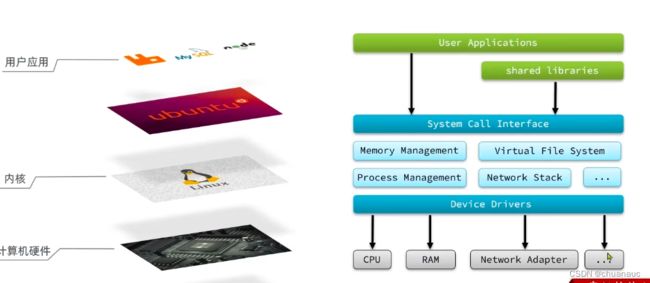
用户应用通过发行版(Ubuntu、CentOS)操作Linux内核,Linux内核与计算机硬件相交互
Linux内核通过各种管理系统例如 virtual file system 来使用计算机硬件的驱动,来控制计算机硬件。并且给上层的应用暴露出可供使用的接口
因为系统说白了也是一个应用,上层的MySQL啥的也是一个应用,是应用在运行过程中就会消耗内存空间,需要占用一定的CPU资源。如果不加区分,上层的应用如MySQL啥的抢占了内核的内存空间,就会导致我们系统崩溃了。
为了避免这种情况,于是将进程的地址空间划分为了2个区域:用户态和内核态
因为无论内核进程还是具体上层应用进程,都无法直接访问物理内存。是给这些进程分配虚拟的内存空间,映射到真实的内存空间。
应用或内核在访问虚拟内存空间时,就需要对应的虚拟地址,这个地址是一个无符号的整数。最大值取决于CPU地址总线和寄存器带宽。例如32位的系统,带宽是32,因此,他的地址最大值就是2^32。因此,虚拟地址的寻址空间就是0-2^32。
内存地址的每一个值代表一个存储单元,也就是一个字节。因此,虚拟寻址空间大小2^32字节就是4GB
操作系统是给每一个字节1Byte分配一个地址,一个字节有8bit
现在有2^32个地址,对应2^32Byte :
由于 1KB=2^10Byte 1MB=2^10KB 1GB=2^10MB (1 GB=2^30 B)
==》因此,2^32 B = 2^2 * 2^30 B = 4GB
我们把虚拟地址这4G的空间划分:用户空间占3G,内核空间占1G。
同时,也把操作划分为不同的等级:R0最高,R3最低
用户空间只能执行R3级别的命令,不能直接调用系统资源,必须使用内核提供的接口才能访问系统资源。内核空间中可以执行各种
用户应用需要执行普通的命令,在用户空间中执行,也需要调用系统资源,进程就需要调用内核接口,执行内核中的指令,当进程涉及的操作指令在内核运行时,就称之为内核态,在执行用户空间中的指令,就called用户态。一段程序很有可能就会出现进程在用户空间和内核空间中切换。
以IO访问为例(无论是访问的磁盘,还是访问的是网卡,都是与物理设备与内存间的交换数据):
用户区的缓冲区主要起到一个IO流的缓冲:不然来一个数据就写一个数据到内核去操作复杂效率低。
内核空间的缓存:作用是若一次用户的请求在内核缓存区中,那么可以直接读过来。
以数据写入到磁盘为例:数据准备好了房子用户态的缓冲区中,接着吧用户空间的缓冲区中数据拷贝到内核态空间中。然后再讲内核缓冲区等数据写入到磁盘中。
以数据从磁盘中读取数据为例:用户空间发起读请求,调用内核中的接口,调用在内核空间执行的指令,内核的指令等待磁盘中数据的到来,当数据到来后,将数据从磁盘读到内核区的缓冲区中,然后将数据从内核的缓冲区拷贝回用户的缓冲区。这些数据在用户的缓冲区中被处理。

可以看出,进程执行过程中,两个地方耗时比较多:一个是内核指令等待从磁盘或网卡中响应的数据到来,第二就是数据从内核到用户区的拷贝
2. C++的内存管理:
【C++初阶】第七篇——C/C++的内存管理(C/C++动态内存分布+new和delete的用法和实现原理)_c 动态内存 new_呆呆兽学编程的博客-CSDN博客
(一)select、poll、epoll 和区别:
1.介绍下select :
select是最早的IO多路复用的实现方案。通过对3个数组对文件描述符上可能发生的三种事件:读事件、写事件、异常事件进行监听。源码中,这三个数组中的每个bit位来标记一个文件描述符,且固定了数组大小:1024位,因此,select最多监听的文件描述符只有1024个;同时select中还有一个用于记录阻塞时间的变量,可以用于控制select的阻塞时长是一直等待阻塞还是完全不阻塞或者等候多少秒后未收到事件就不继续阻塞。
那么,select的IO多路复用流程是:首先将想要监听的文件描述符记录在fd_set中,对应的fd置为1,接着,执行select()函数,此时fd_set还处于用户空间,select()函数会将其拷贝至内核空间。在内核空间,操作系统通过轮训去查看是否有文件描述符出现了相应的事件。若出现,则将出现事件的个数返回,同时,将fd_set中发生事件的文件描述符置为1,并拷贝回用户空间。
通过这个过程,可以看出,select()虽然实现了IO多路复用,但是存在着以下的缺点:
首先是:fd_set需要从用户空间拷贝到内核空间,并从内核空间再次拷贝回去。这个拷贝的动作因涉及内核态与用户态的切换,因此相当耗时。其次,当select监听到时事件发生,他只会将有几个事件发生这个数值回传,至于具体是哪几个文件描述符发生了事件,还要将循环查找fd_set看哪个bit位被置为1。同时,由于fd_set从内核态获得到了事件信息,拷贝回用户态,就会将之前的用户态内fd_set覆盖,然而我们需要一次次调用select()来监听各个文件操作符的事件状态,因此,这相当于每次调用前我们都需要重新初始化一遍fd_set定义好哪些事件要被监听,操作复杂。最后,就是由于当时的源码实现,只能令select()监听1024个文件描述符,这个对于当下的高并发有些不够,因此也需要改进。

2. 介绍下poll :
poll 同样是IO多路复用的一种实现,他针对select()的几个不足做出了调整:他将select方法中的fd_set数据结构改变为结构体类型的数组,数组中的每个结构体用于标识一个文件描述符,包含的信息有该文件描述符的fd,要监听的事件信息,以及要被内核写入的真正监听到的事件。
poll的IO流程同样是:创建poll的数组fd_set,存放要监听的文件描述符信息,调用poll函数,将fd_set数组传入内核态,在内核态也是以链表的方式存放这些结构体。当内核轮训发现有事件发生,将发生事件的个数返回,并将fd_set从内核态拷贝回用户态。由于返回的依旧是发生事件的个数,因此,还是需要代码实现遍历fd_set才可以知道到底是哪个文件描述符发生了什么时间。
总结一下,与select相比,fd_set能监听的文件描述符个数不局限于1024了,但是,由于采用链表作文文件描述符的存放的数据结构,这导致当监听的内容过多时,会导致轮询链表时间越来越长,导致性能变差。同时,由于指定监听什么事件和真实监听到的事件用两个数组存储,因此,不会再有需要每次调用前重新初始化监听fd_set的操作了。然鹅,关键的fd_set从用户态到内核态的拷贝移动、返回值只告诉使用者发生事件的文件描述符个数,而不告诉具体哪些事件发生变化 这些导致的性能问题依旧没有解决。

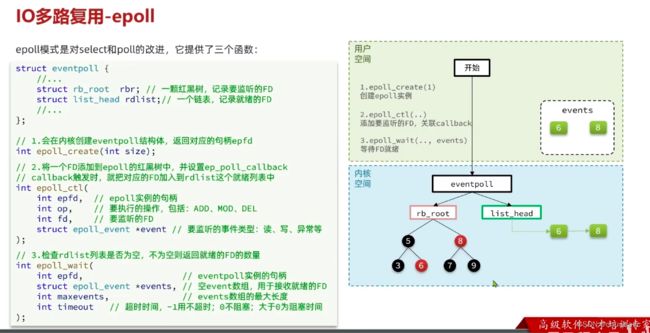
3. 介绍下epoll :
epoll 同样是IO多路复用的一种实现,但epoll解决了刚刚说到的关于select 和 poll 的问题。
这是因为它的实现方式:首先,epoll不再将监听的文件描述符存放在用户空间,而是直接通过epoll_ctl(ADD)加入到内核空间,其次,在内核空间的文件描述符也不再以链表形式存放,而是被组织为了一颗红黑树。这样的组织形式使得即使监听的文件描述符个数增长也不会对性能有太大的波动。同时,epoll还在内核态维护了一个链表,用来存放监听到发生事件的文件描述符,这样就可以明确的告知调用者那些文件描述符发生了事件,而无需调用者再次通过代码遍历一遍全部的fd_set才能知道谁发生了改变。
具体来说,使用epoll的过程是:首先通过epoll_create()在内核区开辟空间存放epoll实例,将要监听的文件描述符通过epoll_ctl(ADD)作为一个节点,加入epoll实例组织的红黑树中。而后,通过调用epoll_wait()要求内核开始轮询监听红黑树上的文件描述符上是否有事件发生,若有事件发生,那么,会调用回调函数,将该事件(以epoll_event结构体形式)加入到epoll实例的rdlist链表中。当调用epoll_wait()时,只会访问这个rblist链表,若链表为空则按照epoll的参数阻塞等待,或者不阻塞等等。当有事件发生,epoll_wait()检测到rblist链表非空,则将该链表内容从内核态拷贝回用户态,供用户态的程序处理。
总结一下:相较于select\poll,epoll相当于把select/poll的功能拆分,通过epoll_ctl()函数对插入要监听的文件描述符,这个从用户态到内核态的过程只有一次;同时,通过调用epoll_wait()直接将已经被监听到事件的从内核态拷贝回用户态,相较于select\poll会将全部的文件描述符集合拷贝回用户态,一来减少了拷贝的内容,二来由于直接将那些文件描述符发生事件返回给调用者,也避免了用户态代码遍历fdset一遍才能知道到底谁发生了事件。
@@同时,调用epoll_wait()会有两种通知用户事件发生的方式:LT和ET
LT:只要FD中有数据可读,且调用了epoll_wait(),那就会发出信号告知有事件有数据,会重复通知,直到FD中的数据被读光
ET:FD中有数据可读,且调用了epoll_wait(),那就会发出信号告知有事件有数据,只会通知一次,直到有新数据到来
实现的方法就是,将发生时间的FD从rblist中截取下来,查看是ET还是LT模式,若是LT,那么会查看数据有没有读光,没有读光就会把这两个FD重新加回到rblist,若是ET模式,无论是否数据读完都不会将FD添加回去。因此采用ET模式应选择非阻塞读,把所有到达的数据一次行全读走。(注意,一定要用非阻塞,阻塞的话会导致没数据就在那里等待,出问题了嘛这不)
LT模式可能会出现惊群现象,由于数据存在而不断发出通知,多进程或多线程情况下,然而只会有一个进线程能获取到内容去处理,这种频繁的选取一个进线程会导致CPU繁忙,效率不高
ET模式 可以结合非阻塞IO,一次性读走处理FD上的全部内容
Linux惊群效应详解(最详细的了吧)_戴着眼镜看不清的博客-CSDN博客 【有时间好好看一下】
同时,也想补充一下,为什么要用红黑树来组织监听的文件描述符?
1.为他妈的要用红黑树不用哈希表:
哈希表VS红黑树_51CTO博客_哈希表和红黑树
红黑树与哈希树的介绍_51CTO博客_avl树和红黑树
为什么epoll使用红黑树来管理文件描述符,而不是哈希表? - 知乎
哎,红黑树和哈希表,面试问三次了! - 知乎
4. 总结下 select\poll\epoll 三者的区别:

1.为他妈的要用红黑树不用哈希表:
哈希表VS红黑树_51CTO博客_哈希表和红黑树
红黑树与哈希树的介绍_51CTO博客_avl树和红黑树
为什么epoll使用红黑树来管理文件描述符,而不是哈希表? - 知乎
哎,红黑树和哈希表,面试问三次了! - 知乎
1. Ubuntu 和 centOS 和 Linux 关系:

1. 五种IO模型:

IO的读写主要就分为两个阶段:一是等待数据从硬件(如磁盘、网卡)上就绪,写入到内核缓冲区,二是将数据从内核缓冲区拷贝回用户缓冲区
不同的IO模型就是在这两个阶段上处理的差别:分别是 阻塞IO、非阻塞IO、IO多路复用、信号IO和异步IO。我们分别来说下
(1)阻塞IO:阻塞IO就是在这两个阶段都一直阻塞等待:用户态发出读数据请求,通过系统调用要求内核读取数据,但是数据没有到达内核缓冲区,于是就一直阻塞等待。终于数据到达了磁盘,数据从磁盘中拷贝回内核态,内核态拷贝回用户空间。在这一整个过程直到数据拷贝回用户空间,用户态的函数一直在阻塞等待。

(2)非阻塞等IO:
与阻塞等待不同的是,当用户态请求发出要调用内核态的函数接口,发现数据不在内核态的缓冲区中,那么,此时用户态的函数不等待,直接返回无数据。
之后不断向内核发出请求,如果内核态依旧缓冲区无数据,那就同样不阻塞等待直接返回用户态。直到数据从磁盘拷贝回内核态,当新一次的请求到来,内核态缓冲区中有数据,于是数据被读走,即,从内核态拷贝回用户态。

(3)IO多路复用:
IO多路复用则是用一个线程去同时监听多个这种读写操作,即同时监听多个文件描述符FD。当出现某个FD可读或可写的时候,就会收到通知,然后调用read()或write()来对这个发生事件的FD读或写。这样,就可以避免之前对每一个FD调用recv()时,若当前recv()的FD没有就绪,其他FD就绪也没有办法被处理到的情况。而当select等收到信号,此时去读取发生事件的FD一定无需阻塞,直接可以将数据从磁盘读取到内核缓冲区了。
一般实现IO多路复用有三种实现select poll epoll : select poll只能通知用户态有几个FD发生事件,但是不嫩准确告知是哪几个FD;epoll则是不仅可以返回有几个FD发生事件,还可以将发生事件的FD写回到用户态,方便用户态继续处理。

4. 信号驱动IO:
信号驱动IO则对要监听的FD绑定一个信号处理函数,要求内核去监听这个FD。若内核无数据存放在缓冲区,那么用户态进程不阻塞,执行其他操作。当数据从磁盘到达内核缓冲区,内核会递交SIGIO信号通知用户态进程去调用recv()从内核把数据拷贝到用户区
缺点:
有大量信号产生的时候,会将大量的信号从内核空间拷贝到用户空间。造成性能较差。
同时,有大量信号产生时,会将信号加入到队列中,SIGIO处理函数若处理不及时会导致信号队列溢出。
5.异步IO:
用户态不再调用recv,而是调用aio_read()告知内核要监听那一个FD。内核返回一个OK,用户态就去执行其他的操作了。而后内核等待数据从磁盘就绪,拷贝到内核缓冲区,内核再将数据拷贝到用户缓冲区,再 调用信号处理函数 通知用户态数据到来
缺点:由于用户态不阻塞,当高并发时,可能会出现用户态不断要求内核监越来越多的FD,导致内核使用很多的缓冲区来存放这些FD上的数据,可能会导致超出内核内存,导致崩溃。因此,要做好限流,限制并发访问的数量。
总结下:同步还是异步:看的是第二阶段,数据从内核拷贝到用户态的拷贝过程是用户态执行还是内核态执行。因此:阻塞IO、非阻塞IO、IO多路复用、信号驱动IO都是同步的;只有异步IO是异步的。
至于阻塞非阻塞,则是看第一阶段,用户态发出请求,是否一直等待内核态的响应:

1. 校招八股:C/C++开发工程师常见笔试、面试题目汇总【基础】 - 简书 (jianshu.com)
https://blog.csdn.net/liang13664759/article/details/1771246
Makefile由浅入深--教程、干货 - 知乎 (zhihu.com)
2. 介绍下 session cookie token :
为什么会出现 session cookie token ?
因为HTTP是无状态的,第一次请求验证了身份,下一次还是这个客户请求无法识别出这是已经验证身份的人,还需要再次验证,用户体验差
解决方案就是session配合 cookie ;或者 token 配合 cookie
Session与Token的异同?
Session和Token机制原理上差不多,都是用户身份验证的一种识别手段,它们都有过期时间的限制,但两者又有一些不同的地方。
1、Session是存放在服务器端的,可以保存在:内存、数据库、NoSQL中。它采用空间换时间的策略来进行身份识别,把用户信息存放到服务器端。这会导致几个问题:(1)若Session没有持久化落地存储,一旦服务器重启,Session数据会丢失。(2)同时,若一亿个用户的session全部存储到服务器a,内存压力过大难以承受,另一方面,由nginx负载均衡时,存储在服务器a的session可能被转发到服务器b,导致session发现不了,还需要再次验证。
2、Token是放在客户端存储的,采用了时间换空间策略,它也是无状态的,所以在分布式环境中应用广泛。每次用户带着自己的token去访问请求,和服务器进行验证,速度更快,由于携带的是token信息,类似uuid,内容也更少,减轻了服务器端的存储压力。
而cookie就像是一个摆渡鸟,带着session或token 的信息来回互换穿梭于客户端和服务器,这样,就可以避免用户在请求服务过程中不断手动验证信息。例如一个场景是:你在淘宝浏览,买东西,跳转到购物车要买,这之间的验证时,不需要再次登录。这是因为cookie携带着我们的token,这样我们就不用一次次自己校验,重新登录了。
ref :session和token有什么区别? - 知乎 (zhihu.com)
Vue.js 数据双向绑定的原理及实现_哔哩哔哩_bilibili
3. 进程与线程:
进程是被加载到内存中的程序,其中包含代码和相关的数据,还有操作系统为之创建的相关的数据结构,其中有PCB(task_struct)、进程地址空间(mm_struct)和页表,我们可以通过PCB找到对应的mm_struct。
4. C++ 内存分布:
【C++初阶】第七篇——C/C++的内存管理(C/C++动态内存分布+new和delete的用法和实现原理)_c 动态内存 new_呆呆兽学编程的博客-CSDN博客
申请空间的本质是:向内存所要空间得到物理地址,然后在特定的区域申请没有被使用的虚拟地址,建立映射关系,再返回虚拟地址即可。
程序地址空间 就是 进程地址空间 就是 虚拟地址空间
5. 之后粘到这里来(C++和操作系统不分家)
【操作系统】虚拟内存相关&分段分页&页面置换算法_chuanauc的博客-CSDN博客