吃下 GuanceDB 狗粮后,观测云查询性能提升超 30 倍
2023 年 4 月 23 日,观测云正式发布自研时序数据库 GuanceDB,并在当天应用到了观测云所有 SaaS 节点的底座。此次升级性能提升的效果立竿见影,对比之前使用 InfluxDB 的环境资源占用大幅降低、查询性能显著提升,我们成功地吃上了自己的狗粮。
我们也深知 talk is cheap show me the benchmark 的道理,这里发布我们在近期完成的 GuanceDB 性能压测报告。
压测方案说明
本次测试的目标是对比 GuanceDB、InfluxDB 和某知名开源时序数据库(简称 xxDB)在相同的写入负载和查询条件下的性能表现及资源占用情况。
关于测试工具:
我们对比 tsbs、prometheus-benchmark 两种时序数据库的压测方案。
其中 prometheus-benchmark 构造了更偏真实环境的持续写入负载,指标数值的变化也更真实,所以我们主要参考 prometheus-benchmark 来构造本次测试。
原 prometheus-benchmark 方案中使用了 vmagent 来抓取和写入指标,但我们今天测试的 3 种数据库对 Prometheus 写入协议支持力度不一,没法一起比较。所以我们对 vmagent 进行了一些改造,让其支持了 InfluxDB 的行写入协议。
本次测试的最终方案如下:
-
部署的一个单机的 node-exporter ,其暴露宿主机的 1383 个真实指标
-
部署 Nginx 反代并缓存 node-exporter 结果 1s,降低频繁请求的压力
-
调整 agent 的抓取配置,模拟生成不同的 node-exporter 实例数以生成不同的写入负载
-
agent 以相同的请求大小、频率将数据同时以 influx 协议 http 接口写入三种时序数据库
软件版本:
-
GuanceDB: v1.0.0
-
InfluxDB: v1.8.10
-
xxDB
主机配置:
-
压测机:1 台阿里云 ecs.g7.16xlarge 云主机:64 core,128 GB RAM
-
存储集群:3 台阿里云 ecs.g7.4xlarge 云主机:16 core,64 GB RAM,200 GB PL1 类型 ESSD
阿里云资源说明页
实例规格族_云服务器 ECS-阿里云帮助中心
云盘概述_云服务器 ECS-阿里云帮助中心
部署方式:
因为 InfluxDB 的开源版本不支持集群模式,所以我们也将分两组进行测试。一组是 InfluxDB 与 GuanceDB、xxDB 的单机版本对比,另一组是 GuanceDB 与 xxDB 的集群模式进行对比,集群模式都使用 3 个存储节点。
参数优化:
GuanceDB 对大部分场景都做了自动调优,所以我们不用手动调整配置。
InfluxDB 默认对高基数场景做了一些保护,我们调整 max-series-per-database = 0 放开了限制,cache-max-memory-size 增大到了 10g,并且开启 tsi1 索引。
xxDB 我们也参考文档进行了针对性的调优。
至此完成所有配置,开始测试。
写入测试
单机组
本组测试进行的测试轮次比较多,这里我们挑选某一轮展示详细监控截图。
在此轮测试中,我们虚拟了 344 个 node-exporter 实例,生成大约 50w 条活跃时间线,5s 抓取一次,时序点写入 QPS 10w。
GuanceDB 资源开销:CPU 占用率 2%,内存占用约 3 GB。
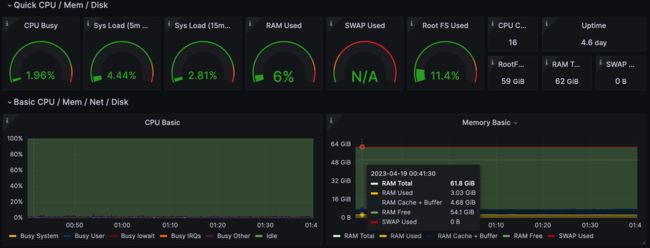

InfluxDB 资源开销:CPU 占用率 16%,内存占用约 7.4 GB。
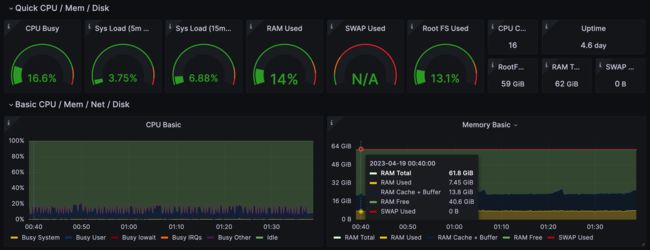
xxDB 资源开销:CPU 占用率 61%,内存占用 9 GB。
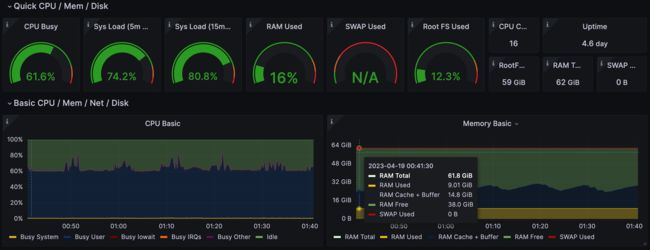
汇总结果表格如下:
| 测试用例:344 个 node-exporter 实例,50w 条活跃时间线,10w 时序点写入 QPS |
||
| CPU 占用率 |
内存占用 |
|
| GuanceDB |
2% |
3 GB |
| InfluxDB |
16% |
7.4 GB |
| xxDB |
61% |
9 GB |
完成了限定性能的测试场景后,我们很好奇要多大的压力才能将各台数据库主机的资源打满,尤其对 GuanceDB,响应 10w 写入 QPS 仅仅花费了 2% 的 CPU 开销,它的性能上限在哪里?随即我们开始加大 QPS,当各台主机的 CPU,内存和磁盘若有一项被打满时,即被认为到达瓶颈。
实际测试结果都是主机的 CPU 先被打满,此时内存占用和磁盘写入带宽都还有余量,所以我们就以 CPU 利用率为瓶颈指标画出以下对比图:

在单机场景下,当 CPU 达到满载时,xxDB 的写入 QPS 约 15w,InfluxDB 约 90w,GuanceDB 约 270w。本轮 GuanceDB 获得第一,写入性能是 InfluxDB 的 3 倍。也可以看到在 CPU 利用率超过 20% 后,性能不再呈线性增长,都有一定程度衰退。
集群组
我们按照之前的方法继续测试 3 节点集群:

在集群场景下,仍然是 CPU 利用率先达到瓶颈。同样在 CPU 满载情况下,GuanceDB 此时的写入 QPS 约为 860w,xxDB 约为 45w。
对比之前 GuanceDB 和 xxDB 的单机写入性能测试,理想情况下 N 个节点的集群版的写入性能应该是单机版的 N 倍,呈线性增长,实测 3 节点集群符合性能预期。
查询测试
查询测试将混合单机 InfluxDB、集群版 GuanceDB、集群版 xxDB 一起进行。集群一般可以将数据和查询分摊并可以在节点之间并行查询,理论上这个测试方式对 InfluxDB 不太公平,但条件受限,暂且这么设计。
我们虚拟 688 个 node-exporter 实例,生成大约 100w 个活跃时间线,5s 抓取一次,时序点写入 QPS 20w。在持续写入 24 小时后,我们再测试一些常见语句的查询性能和对比存储空间占用。
GuanceDB 同时支持 DQL 和 PromQL 两种查询语法。DQL 是观测云自研的多模数据查询语言,同时支持指标、日志、对象等多种类型负载数据的查询和分析,语法表达非常简洁。语法设计上跟 SQL 接近,但更加适应时序分析场景,学习曲线平滑。
这里我们一共对比了四种查询语法在相同语义的 1h、8h、24h 不同时间范围下的响应时间:
| 查询 |
GuanceDB With DQL |
GuanceDB With PromQL |
InfluxDB With InfluxQL |
xxDB With xxQL |
| host-249 的 5 分钟负载 |
M::node_exporter:(max(node_load5)) {instance = 'host-249'} [{start_ms}:{end_ms}:{step}s] |
max_over_time(node_exporter:node_load5{instance="host-249"}) URL Query String: start={start_ms}&end={end_ms}&step={step}s |
SELECT max(node_load5) from node_exporter where (instance = 'host-249') and "time" >= '{start}' AND "time" < '{end}' group by time({step}s) |
SELECT _wstart as ts, max(node_load5), last(instance) FROM node_exporter WHERE instance = 'host-249' AND _ts >= {start_nano} AND _ts < {end_nano} INTERVAL({step}s) |
| 所有机器最高 5 分钟负载 |
M::node_exporter:(max(node_load5)) [{start_ms}:{end_ms}:{step}s] |
max(max_over_time(node_exporter:node_load5})) URL Query String: start={start_ms}&end={end_ms}&step={step}s |
SELECT max(node_load5) from node_exporter where "time" >= '{start}' AND "time" < '{end}' group by time({step}s) |
SELECT _wstart as ts, max(node_load5) FROM node_exporter WHERE _ts >= {start_nano} AND _ts < {end_nano} INTERVAL({step}s) |
| 所有机器全部 5 分钟负载 |
M::node_exporter:(avg(node_load5)) [{start_ms}:{end_ms}:{step}s] by instance |
avg_over_time(node_exporter:node_load5}) URL Query String: start={start_ms}&end={end_ms}&step={step}s |
SELECT avg(node_load5), instance from node_exporter where "time" >= '{start}' AND "time" < '{end}' group by time({step}s), instance |
SELECT _wstart as ts, tbname, avg(node_load5), last(instance) FROM node_exporter WHERE _ts >= {start_nano} AND _ts < {end_nano} PARTITION BY tbname INTERVAL({step}s) |
查询 1 响应时间:
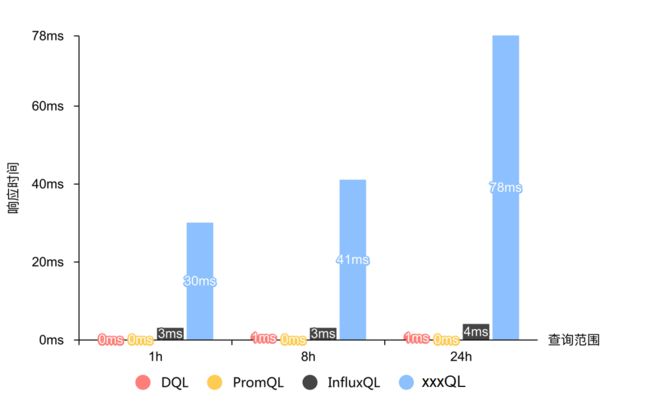
注:图示中 0ms 表示响应时间不到 1ms。
| 单位:ms |
1h |
8h |
24h |
| GuanceDB With DQL |
0 |
1 |
1 |
| GuanceDB With PromQL |
0 |
0 |
0 |
| InfluxDB With InfluxQL |
3 |
3 |
4 |
| xxDB With xxxQL |
30 |
41 |
78 |
查询 2 响应时间:
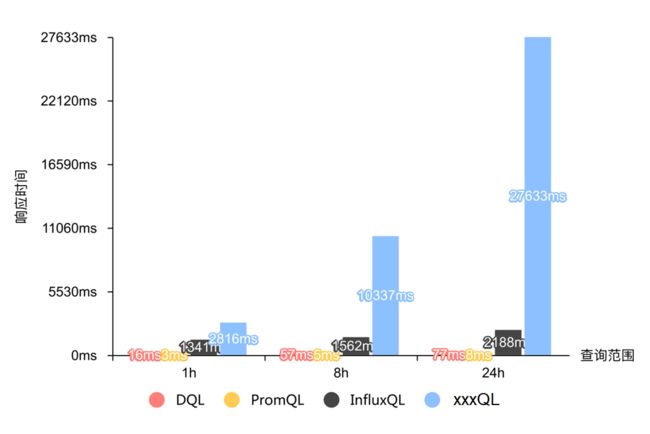
| 单位:ms |
1h |
8h |
24h |
| GuanceDB With DQL |
16 |
57 |
77 |
| GuanceDB With PromQL |
3 |
5 |
8 |
| InfluxDB With InfluxQL |
1341 |
1562 |
2188 |
| xxDB With xxxQL |
2816 |
10337 |
27633 |
查询 3 响应时间:

注:图示中 -1ms 表示请求响应时间超过了 60s 不计数。
| 单位:ms |
1h |
8h |
24h |
| GuanceDB With DQL |
71 |
112 |
135 |
| GuanceDB With PromQL |
15 |
23 |
63 |
| InfluxDB With InfluxQL |
2032 |
2282 |
2700 |
| xxDB With xxxQL |
>60000 |
>60000 |
>60000 |
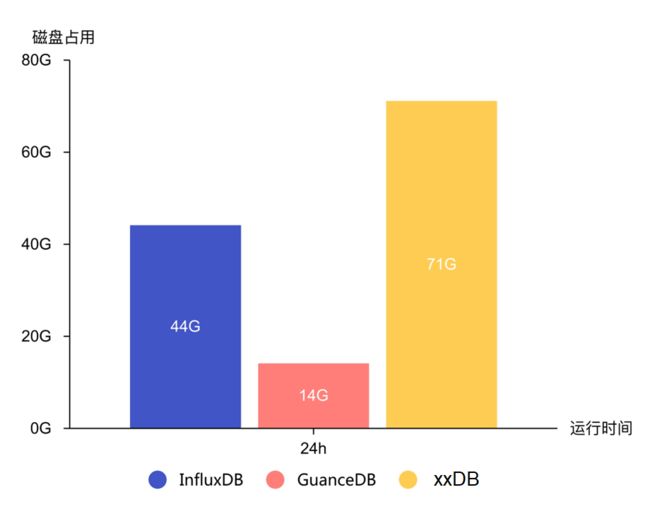
空间占用对比
在上述的查询测试构造的写入压力(活跃时间线 100w,时序点写入 QPS 20w)下,运行 24 小时后,我们对比存储空间占用。
总结
经过数轮的写入和查询性能测试,相信各位对 GuanceDB 的综合性能表现已经有了比较清晰的认识了。GuanceDB 对比 InfluxDB 写入性能提升 3 倍,存储空间占用减少 68%,查询性能提升 30 倍以上。GuanceDB 相比 xxDB 提升则更明显,背后的原因是 xxDB 虽然明面上是支持了 Schemaless 数据的写入,但是对 Schemaless 的场景明显优化不足,所以表现欠佳。
GuanceDB 的优异性能来自于我们构建的高效的火山模型查询引擎、SIMD 指令加速、对 Schemaless 数据的最优先支持等,也因为我们站在了 VictoriaMetrics 的肩膀上。非常感谢 VictoriaMetrics 开源社区对我们的支持,我们将持续贡献回报社区,共同促进可观测领域技术的发展与进步。
我们在 5 月中下旬也将发布 GuanceDB 的单机版本,欢迎大家到时关注和测试。如有同学对 GuanceDB 感兴趣,或有任何疑问,可以随时站内和我联络,或者在观测云(www.guance.com)社群里沟通。