论文:http://www.read.seas.harvard.edu/~kohler/class/cs239-w08/decandia07dynamo.pdf
翻译版:https://www.jianshu.com/p/215289fe88ea
ABSTRACT
Amazon.com 是世界上最大的电商之一,Amazon.com 所遇到的最大挑战之一,就是超大规模下的稳定性问题(reliability at massive scale)。即使是最微小的故障,也会造成巨大的经济损失,而且会降低客户对我们的信任。Amazon.com 作为一个为全球提供 web 服务的平台, 其底层的基础设施是由分布在全球的数据中心中成千上万的服务器和网络设备组成的。在如此庞大的规模下,大大小小的组件故障是不断在发生的,要正确应对这些故障,以满足软件系统的可靠性和可扩展性。
本文介绍 Dynamo的设计和实现。Amazon 的一些核心服务就是基于 Dynamo 提供不间断服务的(always-on experience)。为了达到这种等级的可用性,Dynamo牺牲了几种特定故障场景下的一致性。另外,Dynamo 大量使用了对象版本化(object versioning)和应用协助的冲突解决(application-assisted conflict resolution)机制,给开发者提供了一种新颖的接口。
1. Introduction
Amazon 是一个全球电商平台,峰值用户达到几千万。由分布在全球的数据中心中成千上万的server支撑服务。Amazon 平台对性能、可靠性和效率等指标有着很高的要求 。而且,为了支撑持续增长,平台需要有高度的可扩展性。可靠性是我们最重要的需求之一,因为即使是最微小的故障也会造成巨大的经济损失,而且会降低客户对我们的信任。
我们从打造 Amazon 平台的切身实践中总结出的一条经验是:一个系统的可靠性和可扩展性取决于如何管理它的应用状态(how its application state is managed)。
Amazon 使用的是高度去中心化的、松耦合的、面向服务的架构,由几百个服务组成。因此,这对永远可用(always available)的存储技术有着强烈的需求。例如,即使磁盘挂掉、路由抖动、甚至数据中心被飓风摧毁,用户应该仍然能向他们的购物车添加和查看商品。要实现这样的目标,管理购物车的系统就必须永远能读写它的data store,而且数据还要跨多个数据中心可用。
对于由几百万台设备组成的基础设施,故障是家常便饭;在任何时刻都会有比例小 但数量不少(small but significant number)的服务器和网络设备发生故障。因此, Amazon 的软件系统要将故障视为normal case,不因设备故障而影响可用性和性能。
为了满足可靠性和可扩展性的需求,Amazon 开发了一些存储技术,S3 (Simple Storage Service)可能是最广为人知的一种。本文介绍 Amazon 的另一个存储产品: Dynamo 的设计和实现。
Dynamo 主要用于管理这些服务的状态:
· 对可靠性要求非常高的服务
·对可靠性、一致性、成本-效率(cost-effectiveness)和性能有很强的控制能力的服务
Amazon 平台有很多类型的应用,不同的类型对存储的需求差异很大。例如,其中一类应用希望能data store的配置足够灵活,以便在成本最经济的方式下,由开发者来决定如何在可用性和性能之间取得折中。
Amazon 上的一些服务只需以主键(primary key)的方式访问数据仓库,如销量榜、购物车、客户喜好偏向、session 管理、销售排名、商品目录等等。如果使用常见的关系型数据库会非常低效,而且限制了规模的扩展性和可用性。Dynamo 提供了primary key only的访问接口来满足这类应用的需求。
Dynamo 基于一些众所周知的技术实现了可扩展性和高可用性:
数据通过一致性哈希分散和复制(partitioned and replicated)
通过对象版本化(object versioning)实现一致性
写入期间,副本之间的一致性由一种类似仲裁的技术(quorum-like technique)和一个去中心化的副本同步协议(decentralized replica synchronization protocol)保证
gossip-based 分布式故障检测和成员检测(membership)协议
Dynamo 是一个不需要人工介入管理的、完全去中心化的系统。
向 Dynamo 添加或移除存储节点不需要人工 partition 或 redistribution
Dynamo 在过去的几年已经成为 Amazon 很多核心服务的底层存储技术。在节假日购物高峰 ,它能实现不停服扩容以支持极高的峰值负载。例如,单日购物车能扛几千万请求,300 万次的付款动作,并且能处理几千万的并发活跃用户管理 session 状态的服务
本文对该领域的主要贡献:
评估了如何通过组合不同技术实现一个高可用的系统;
证明了最终一致性存储系统可以用于生产环境,满足应用的高要求;
深入探索了若干优化技术,以满足生产环境的非常严格的性能要求;
本文章节结构介绍(略,见下面全文)。
2. BACKBROUD
Amazon 的电商平台由几百个服务组成,它们协同工作,提供的服务包罗万象,从推荐系统到订单处理到欺诈检测等等。每个服务对外提供定义良好的 API,被其他服务通过网络的方式访问。这些服务运行在分布在全球的数据中心中,成千上万的服务器组成的基础设施之上 。有些服务是无状态的(例如,聚合其他服务的响应的服务),有些是有状态的(例如,根据存储在数据仓库里的状态,执行业务逻辑并产生响应的服务)。
以前生产系统会使用关系型数据库来存储状态(state)。但对于大多数这类系统, 关系型数据库其实并不是一种理想的方式。因为大多数服务只用主键去检索,并不需要 RDBMS 提供的复杂查询和管理功能。这些额外的功能需要昂贵的硬件和专门的技能,而实际上服务根本用不到,最终的结果就是使用关系型数据库非常不经济。另外,这类数据库的复制功能很受限,而且通常是靠牺牲可用性来换一致性。虽然,近年有了一些改进,但水平扩展以及使用智能partitioning 来做负载均衡还是很不方便的。
本文介绍 Dynamo 是如何解决以上需求的。Dynamo 有易用的 key/value 接口,高度可用 ,有定义清晰的一致性窗口(clearly defined consistency window),资源使用效率很高 ,并且有易用的水平扩展方案以解决请求量或数据增长带来的挑战。每个使用 Dynamo 的服务,使用的都是独立的一套 Dynamo 系统。
2.1 系统假设与需求
Dynamo 对使用它的服务有如下几点假设和需求:
查询模型(Query Model)
通过唯一的 key 对数据进行读写。以唯一的 key 作为id,状态(其实就是Value)以二进制的形式存储。
任何操作都不会跨多个 data items,没有关系型 schema 需求。
存储的都是相对较小的文件(一般小于 1 MB)。
ACID 特性(Atomicity, Consistency, Isolation, Durability)
ACID是一组保证数据库事务可靠执行的特性。在数据库领域,对数据的单次逻辑操作(single logical operation) 称为一次事务(transaction)。 实践表明,让数据仓库支持 ACID 会使得它的可用性非常差,工业界和学术界也已经就这一点达成了广泛共识 [5]。
Dynamo 的目标应用具有这样的特点:如果能给可用性(ACID 里面的 A)带来很大提升 ,那牺牲一些一致性(C)也是允许的。
Dynamo 不提供任何隔离(isolation)保证,并且只允许单个 key 的更新操作(permit only single key updates)。
效率(Efficiency)
系统需要运行在家用硬件之上。Amazon 的服务对延迟有着严格的要求,通常用百分位值(percentile)P99.9 衡量。
鉴于访问数据是服务的核心操作之一,我们的存储系统必须满足那些严格的SLA (见 Section 2.2)。另外,服务要有配置 Dynamo 的能力,以便能满足服务的延迟和吞吐需求。其实就是在性能、成本效率、可用性和持久性之间取得折中。
Other
Dynamo 定位是 Amazon 内部使用,因此我们假设环境是安全的,不需要考虑认证和鉴权等安全方面的问题。
由于每个服务都使用各自的一套 Dynamo,因此 Dynamo 的初始设计规模是几百个存储节点。后面会讨论扩展的限制,以及可能的解决方式。
2.2 SLA (Service Level Agreements)
要保证一个应用完成请求所花的时间有一个上限(bounded time),它所依赖的那些服务就要有一个更低的上限。Client和Server会对某些系统特性,定义一个 SLA(服务级别协议)来作为契约。在这些系统特性中,最为主要有Client期望的某个API的请求率分布(request rate distribution)或Client期望的请求时延等。
举个简单例子:某个Server向Client保证,在 500 QPS 的负载下,它处理 99.9% 的请求所花的时间都在能 300ms 以内。
在 Amazon 的去中心化的、面向服务的基础设施中,SLA 扮演着重要角色。例如,对购物页面的一次请求,在典型情况下会使渲染引擎(render engine)向多达 150 个服务发送子请求,而这些子服务又都有自己的依赖,最终形成一张多层的调用图。为了保证渲染引擎能在一个上限时间内返回一个页面,调用链中的所有服务就都必须遵循各自的性能契约(contract)。
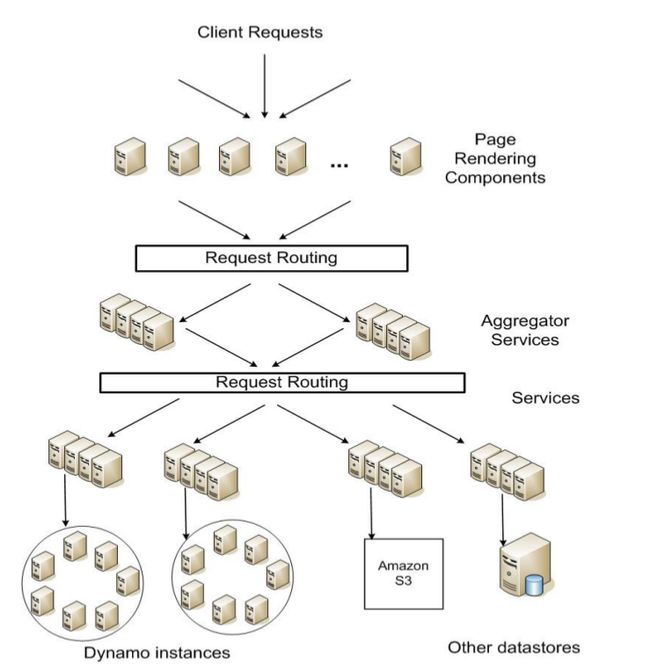
上是一张简化之后的 Amazon 平台架构图。可以看到,动态 web 内容由页面渲染组件(Page Rendering Components)提供,而它是通过调用其他的一些服务来完成这项工作的。
每个服务可以选择不同类型的数据仓库来管理(存储)它们的状态数据, 这些数据仓库只能在各自的服务边界(service boundaries)内访问。一些服务会通过聚合其他服务的数据来组合产生一个响应(composite response)。聚合服务( aggregator service)是无状态的,虽然它们大量使用缓存技术。
对于面向性能的 SLA,业内一般习惯使用平均值、中位数和方差来描述。但在 Amazon 我们发现,要打造一个让所有用户——而不是大部分用户——都有良好体验的系统,以上 SLA 并不合适。例如,如果使用了个性化推荐技术,那用户的访问历史越多,他的请求被处理的时间就越长,最终落到了性能分布的长尾区。基于平均值或中位数的 SLA 并不能反映这种情况。因此为了解决这个问题,我们使用了 P99.9 分布。99.9% 这个精度是经过大量实验分析,权衡了成本和性能之后得到的。 我们在生产环境的实验显示,这比基于均值或中位数的SLA 有更好的用户体验。
本文多处都将引用 P99.9 分布,这也显示了 Amazon 的工程师对提高用户体验所做的持续不断的努力。一些基于均值的论文,我们会在它真正有意义的场景才拿出来作为比较,但我们自己的工程和优化都不是focus在均值上的。某些技术,例如 write coordinator(写操作协调者)的负载均衡选择策略,是完全面向 P99.9 来控制性能的。
存储系统在构建一个服务的 SLA 中经常扮演着重要角色,尤其是业务逻辑相对轻量的场景,Amazon 的许多服务就属于这一类。因此,状态管理就成了服务的SLA 的主要部分。Dynamo 的设计目标之一就是:允许服务自己控制自己的系统特性——例如持久性和一致性——让服务自己决定如何在功能、性能和成本效率之间取得折中。
2.3 设计考虑
商业系统中数据复制算法一般都是同步的,以提供一个强一致性的数据访问接口。 为了达到这种级别的一致性,这些算法被迫牺牲了某些故障场景下的数据可用性。例如, 如果数据有冲突,它们会禁止访问这个数据,直到数据的不一致完全得到了解决。在早期,这种复制式数据库(replicated database)是可以工作的。但众所周知,分布式系统是无法同时满足强一致性、高可用性和正确处理网络故障这几个特性的 [2, 11]。因此,系统和应用都需要知道,在什么场景下选择满足什么特性。
对于Server和网络故障较高的场景,可以通过乐观复制(optimistic replication )技术提高可用性,在后台将数据变动同步到其他节点,并发更新和失联也是可以容忍的。这种方式的问题是会导致数据冲突,需要检测并解决冲突。而解决数据冲突又会带来两个额外问题:【何时解决】以及【谁来解决】。Dynamo 设计为最终一致数据仓库(eventually consistent data store),即:最终所有的更新会应用到所有的副本。
何时解决冲突:是读的时候还是写的时候?1.一些传统的数据仓库是在写的时候解决冲突,这样可以保证读的复杂度很低。 但在这种系统中,任何时候,如果数据仓库不能写入所有或者大多数副本,写就会被拒绝。2. Dynamo 的设计与此相反,它的目标是提供一个“永远可写”(always writable)的数据仓库(例如,一个对写操作高度可用的数据仓库)。对很多 Amazon 服务来说,拒绝写入会造成很差的用户体验。比如即使发生服务器或网络故障,也应该允许用户往购物车添加或删除商品。这个需求使我们将解决冲突的复杂度放到了读操作,以保证写永远不会被拒绝。
谁来解决冲突:是数据仓库还是app?1.如果由数据仓库来做,那选择会相当受限。数据仓库只能使用一些非常简单的策略,例如 "last write wins" ,来解决更新冲突。2.如果由app来做,由于app理解数据描述的是什么,它可以自主选择对用户体验最好的冲突解决算法。例如,购物车可以选择“合并”冲突的版本,返回一个合并后的购物车。但是,尽管这样可以带来很大的灵活性 ,但一些app开发者并不想自己实现一套冲突解决机制,因此在这种情况下,解决冲突的问题就下放给了数据仓库,由后者来选择一些简单的策略,例如 “last write wins”。
其他设计原则:
增量扩展性(Incremental scalability):应当支持逐机器(节点)扩容,而且对系统及运维人员带来的影响尽量小;
对称性(Symmetry):每个节点的职责应该是相同的,不应当出现某些节点承担特殊职责或特殊角色的情况。以我们的实践经验,对称性简化了系统的配置和运维;
去中心化(Decentralization):“去中心化”是“对称性”的进一步扩展,系统应该是去中心化的、点对点的,而不应该是集中式控制的。在过去,集中式控制导致了很多服务故障,我们应当极力避免它。去中心化会使得系统更简单、更具扩展性和可用性;
异构性(Heterogeneity):系统要能够利用到基础设施的异构性。例如,负载的分布要和存储节点的能力成比例。对于逐步加入能力更强的新节点,而不是一次升级所有节点来说,这种异构支持能力是不可或缺的;
3. 相关工作
3.1 点对点系统(Peer to Peer Systems)
一些点对点P2P系统关注了数据存储和分布的问题。
第一代 P2P 系统
如 Freenet 和 Gnutella,在文件共享系统领域使用广泛。它们都是非结构化 P2P 网络(节点之间的 overlay 链路都是随机建立的)的代表。在这种网络中,一次查询请求通常是泛洪(flood)到整张网络,找到尽量多的共享这个数据的节点。
结构化 P2P 系统
P2P 网络到下一代,就是有名的结构化 P2P 网络。这种网络使用了全局一致性协议,保证任何一个节点可高效地将查询请求路由到存储这个数据的节点。
Pastry 和 Chord 这样的系统利用路由机制可以保证查询在有限跳之内收到应答。
为了减少多跳路由带来的额外延迟,一些 P2P 系统使用了O(1)路由机制,在这种机制中,每个节点维护了足够多的路由信息,因此它可以将(访问数据的)请求在常量跳数内路由到合适的对端节点 。
包括 Oceanstore 和 PAST 在内的很多存储系统都是构建在这种路由 overlay 之上的。Oceanstore 提供全球分布的、事务型的、持久的存储服务,支持分布在很大地理范围内的副本的串行化更新 。为了支持并发更新,同时避免广域锁(wide-are locking)内在的一些问题,它使用了一 种基于冲突解决(conflict resolution)的更新模型。conflict resolution 在 [21] 中提出,用于减少事务异常中止(transaction abort)的数量。Oceanstore 处理冲突的方式是 :对并发更新进行排序(order),将排好序的若干个更新作为原子操作应用到所有副本。 Oceanstore 是为在不受信的基础设施上做数据复制的场景设计的。作为对比,PAST 是在Pastry 之上提供了一个简单的抽象层,以此来提供持久和不可变对象。它假设应用可以在它之上构建自己需要的存储语义(例如可变文件)。
3.2 分布式文件系统与数据库
文件系统和数据库系统领域已经对通过分散数据(distributing data)来提高性能、可用性和持久性进行了广泛研究。和P2P 存储系统只支持 flat namespace 相比,典型的分布式文件系统都支持 hierarchical namespace。
Ficus 和 Coda 这样的系统通过文件复制来提高可用性,代价是牺牲一致性。 更新时的冲突解决一般都有各自特殊的解决方式;Farsite 是一个不使用中心式服务器(例如 NFS)的分布式文件系统,它通过复制实现高可用和高扩展;Google File System是另一个分布式文件系统,用于存储 Google 内部应用的状态数据。GFS 的设计很简单,一个master管理所有元数据,数据进行分片( chunk),存储到不同数据节点(chunkservers);Bayou 是一个分布式关系型数据库系统,允许disconnected operation,提供最终一致性;
在这些系统中,Bayou、Coda 和 Ficus 都支持disconnected operation,因此对网络分裂和宕机都有很强的弹性,它们的不同之处在于如何解决冲突。例如,Coda 和 Ficus 在系统层面解决,而 Bayou 是在应用层面。相同的是,它们都提供最终一致性。。与这些系统类似,Dynamo 允许在网络发生分裂的情况下继续执行读写操作,然后通过不同的冲突解决机制来处理更新冲突。
分布式块存储系统,例如 FAB ,将一个大块分割成很多小块并以很高的可用性的方式存储。。与此不同,我们的场景更适合使用键值存储,原因包括:1.系统定位是存储相对较小的文件( 小于1 MB)2.键值存储更容易在应用级别针对单个应用进行配置。
Antiquity 是一个广域分布式文件系统,设计用于处理多个服务器挂掉的情况。它使用安全日志(secure log)保证数据完整性,在不同服务器之间复制 secure log 来保证持久性,使用拜占庭容错协议(Byzantine fault tolerance protocols)保证数据一致性。。与此不同,Dynamo 并不将数据完整性和安全性作为主要关注点,因为我们面向的是受信环境。
Bigtable 是一个管理结构化数据的分布式文件系统,它维护了一张稀疏的多维有序映射表(sparse, multi-dimensional sorted map),允许应用通过多重属性访问它们的数据。。与此不同 ,Dynamo 面向的应用都是以 key/value 方式访问数据的,我们的主要关注点是高可用,即使在发生网络分裂或服务器宕机的情况下,写请求也是不会被拒绝的。
传统的复制型关系数据库系统(replicated relational database systems)都将关注点放在保证副本的强一致性。虽然强一致性可以给应用的写操作提供方便的编程模型, 但导致系统的扩展性和可用性非常受限,无法处理网络分裂的情况。
3.3 讨论
Dynamo 面临的需求使得它与前面提到的集中式存储系统都不相同。
首先,Dynamo 针对的主要是需要【永远可写的数据仓库】的应用, 即使发生故障或并发更新,写也不应该被拒绝。对于 Amazon 的很多应用来说,这一点是非常关键的。
第二,Dynamo 构建在受信的、单一管理域的基础设施之上。
第三,使用 Dynamo 的应用没有层级命名空间的需求(这是很多文件系统的标配),也没有复杂的关系型 schema 的需求(很多传统数据库都支持)。
第四,Dynamo 是为延迟敏感型(latency sensitive)应用设计的,至少 99.9% 的读写操作都要在几百毫秒内完成。为了到达如此严格的响应要求,在多节点之间对请求进行路由的方式(被很多分布式哈希表系统使用,例如 Chord 和 Pastry )就无法使用了。因为多跳路由会增加响应时间的抖动性,因此会增加长尾部分的延迟。 Dynamo 可以被描述为:一个零跳(zero hop)分布式哈希表,每个节点在本地维护了足够多的路由信息,能够将请求直接路由到合适节点。
4. 系统架构
生产级别的存储系统的架构是很复杂的。除了最终存储数据的组件之外,系统还要针对下列方面制定可扩展和健壮的解决方案:负载均衡、成员管理(membership)、故障检测、故障恢复、副本同步、过载处理(overload handling)、状态转移、并发和任务调度、请求 marshalling、请求路由(routing)、系统监控和告警,以及配置管理。
详细描述以上提到的每一方面显然是不可能的,因此本文将关注下面几项 Dynamo 用到的分布式系统核心技术:
partitioning(分区,经哈希决定将数据存储到哪个/些节点)
复制(replication)
版本化(versioning)
成员管理(membership)
故障处理(failure handling)
规模扩展(scaling)
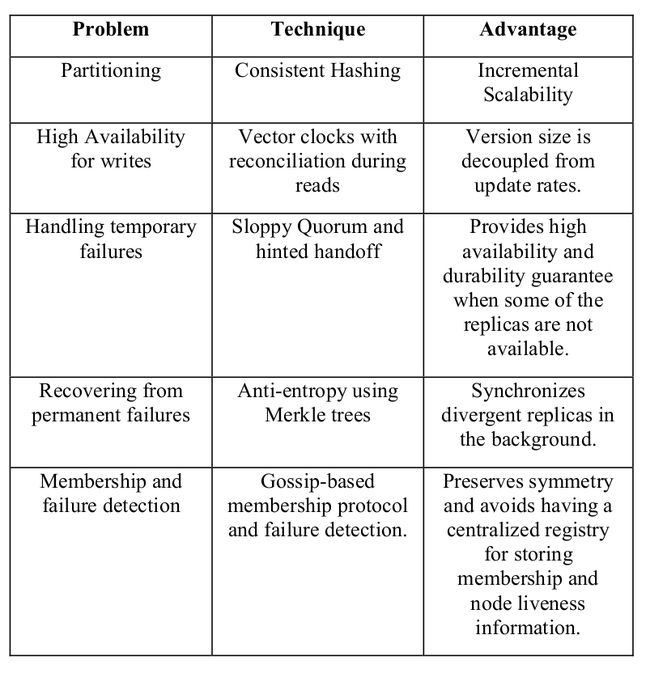
下表总结了 Dynamo 使用的这些技术及每项技术的好处:
4.1 系统接口
Dynamo 存储键值对象的接口非常简单,它提供两个操作:get() put()
get(key) 会定位到存储系统中 key 对应的所有对象副本,返回一个 context和object:可能是单个对象,也可能是一个对象列表(有冲突情况下,包括了所有版本)。
put(key,context,object) 确定对象应该存放的位置,然后写到相应的磁盘。context 包含了系统中对象的元数据,例如对象的版本,对调用方是不透明的( opaque)。context是和object存储在一起的,这样系统很容易验证 put 请求的 context 是否合法。
Dynamo将调用方提供的 key 和object都视为不透明的字节序列 。它对 key 应用 MD5 哈希得到一个 128bit 的 ID,并根据这个 ID 计算应该存储到哪些节点。
4.2 Partitioning算法
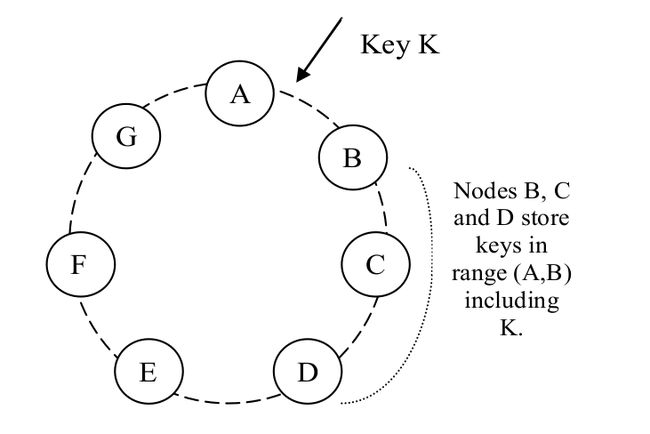
Dynamo 的核心需求之一是:系统必须支持增量扩展。 这就要求有一种机制能够将数据分散到系统中的不同的节点上。Dynamo 的分散方案基于一致性哈希。在一致性哈希中,哈希函数的输出是一个固定的范围,通常作为一个循环空间,或称环(ring)。每个节点都会随机分配一个在这个循环空间内的值(position或者token),这个值代表了节点在这个环上的位置position。
用如下方式找到一个数据项对应的存储节点:
1.首先对它的 key 做哈希得到一个哈希值
2.在环上沿着顺时针方向找到第一个position比这个哈希值更大的节点
即,每个节点要负责环上从它自己到它的下一个节点之间的区域。一致性哈希的主要好处是 :添加或删除节点只会影响相邻的节点,其他节点不受影响。
但是,初级的一致性哈希算法有一些问题。 首先,给每个节点随机分配一个position(token)会导致数据和负载的非均匀分布。 其次,初级的一致性哈希算法没有考虑到节点的异构因素,导致性能不理想。
为了解决这些问题,Dynamo 使用了一致性哈希的一个变种:每节点并不是映射到环上的一个position,而是多个position。为了实现这种设计,Dynamo 使用了虚拟节点的概念。一个虚拟节点看上去和一个普通节点一样,但一个普通节点实际上可能管理不止一台虚拟节点。具体来说,当一个新节点添加到系统后,它会在环上被分配多个位置(对应多个 token)。 我们会在 Section 6 介绍 Dynamo partitioning策略的调优 。
虚拟节点可以代来如下好处:
当一个节点不可用时(故障或例行维护),这个节点的负载会均匀分散到其他可用节点上;
当一个节点重新可用时,或新加入一个节点时,这个节点会获得与其他节点大致相同的负载;
一个节点负责的虚拟节点的数量可用根据节点容量来决定,这样可用充分利用物理基础设施中的异构性。
4.3 Replication
为了实现高可用性和持久性,Dynamo 将数据复制到多台机器上。每个数据会被复制到 N 台机器,这里的 N 是每套 Dynamo 系统可以自己配置的。
上节讲过了,每个 key k,会被分配一个节点(注意 是虚拟节点),我们把它称为 coordinator节点吧。 coordinator负责落到它管理的范围内的数据的复制。它除了自己存储一份之外,还会在环上顺时针方向的其他 N-1 个节点存储一份副本。因此在系统中,每个节点要负责从它自己往后的一共 N 个节点。
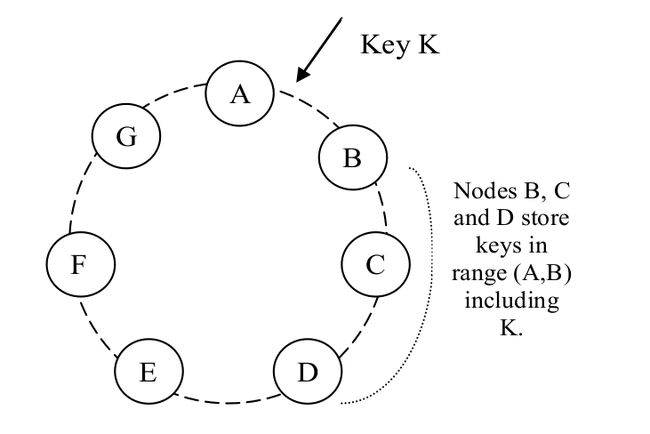
比如下图中,B 除了自己存储一份之外,还会将其复制到 C 和 D 节点。因此,D 实际存储的数据,其 key 的范围包括 (A, B]、(B, C] 和 (C, D]。例如,落在 (A, B] 范围内的 key 会沿顺时针方向找到第一个值比它大的节点,因此找到的是 B,而 B 会将自己存储的数据复制到 C 和 D,因此 D 会包含 key 在 (A, B] 范围内的对象。其他几个范围也是类似的。译者注。
存储某个特定 key 的所有节点组成一个列表,称为preference list(优先列表)。 我们在 4.8 节会看到,Dynamo 的设计是,对于给定的 key,每个节点都能决定哪些节点可以进入这个列表。为了应对节点失败的情况,preference list 会包含 N个以上的节点。(所以这里说的和上一段不一样,从上一段推断出来,对于给定的key,应该是N个节点存储它,但是这里preference list 是大于N的)
另外注意,由于我们引入了虚拟节点,存储一个 key 的 N 个positions,实际上对应的物理节点可能少于 N 个(一个节点可能会占用不止一个position)。为了避免这个问题 ,preference list 在选择节点的时候会跳过一些position,以保证 list 里面的节点都在不同的物理节点上。
4.4 Data Versioning
Dynamo 提供最终一致性,所有更新操作会异步地传递给所有的副本。put() 操作返回时,数据(更新)可能还没有应用到所有副本,因此紧接着的 get() 操作可能获取不到最新数据。在没有故障的情况下,更新操作的传递时间是可控制的;但在特定故障场景下(例如服务器宕机或网络分裂),在有限的时间内,更新操作可能会无法传递到所有副本。
Amazon 有些应用是可以容忍这种不一致性的,应用在这种情况下能继续运行。例如,购物车要求“添加到购物车”的请求永远不能被丢失或拒绝。如果购物车的最新状态不可用, 而用户对一个稍老版本的购物车状态做了修改,那这种修改也是有意义的,需要保留;但它不能直接覆盖最新的状态,因为最新的状态中可能也有一些修改需要保留。这里要注意,不管是“添加到购物车”还是“从购物车删除”,在系统中转换成的都是 Dynamo的put() 操作 。如果最新的状态不可用,而用户又基于稍的大版本做了修改,那这两个版本都需要保留, 由随后的步骤来处理更新冲突。
为了满足以上需求,Dynamo将每次修改结果都作为一个新的、不可变的版本。即,允许系统中同时存在多个不同版本。在大部分情况下,新版本都包含老版本的数据,而且系统自己可以判断哪个是权威版本(syntactic reconciliation)。但是,在发生故障并且存在并发更新的场景下,版本会生出branch, 导致版本冲突。系统本身无法处理这种情况,需要客户端介入,将多个分支合并成一个(semantic reconciliation)。比如:合并多个不同版本的购物车。 有了这种调和机制,“添加到购物车”操作就永远不会失败 ;但是,这种情况会导致已经删除的商品偶尔又在购物车中冒出来(resurface)。
需要注意:某些故障会导致存在多个冲突的版本,而不仅仅是两个。服务器故障或网络分裂会导致一个对象有多个版本,每个版本有各自的子历史(version sub-histories),随后要由系统来将它们一致化。这需要将应用设计为:显式承认多版本存在的可能性(以避免丢失任何更新)。
向量时钟(vector clock)
Dynamo 使用向量时钟来跟踪同一对象不同版本之间的因果性。 一个向量时钟就是一个 (node, counter) 列表。一个向量时钟关联了一个对象的所有版本,可以通过它来判断对象的两个版本是在并行的分支上还是有因果关系。如果对象的第一个时钟上的所有 counter 都小于它的第二个时钟上的 counter,那第一个时钟就是第二的祖先,可以安全的删除;否则,这两个修改就是有冲突的,需要 reconciliation。
在 Dynamo 中,客户端更新一个对象时,必须指明基于哪个版本进行更新。一般流程是,先执行读操作,拿到 context,其中包含了 vector clock 信息,然后写的时候带上这个 context。
在处理读请求的时候,如果 Dynamo 能够访问到多个版本,并且无法 reconcile 这些版本 ,那它就会返回所有版本,并在 context 中附带各自的 vector clock 信息。基于 context 指定版本更新的方式解决了冲突,将多个分支重新合并为一个唯一的新分支。
我们通过下图来展示 vector clock 是如何工作的:
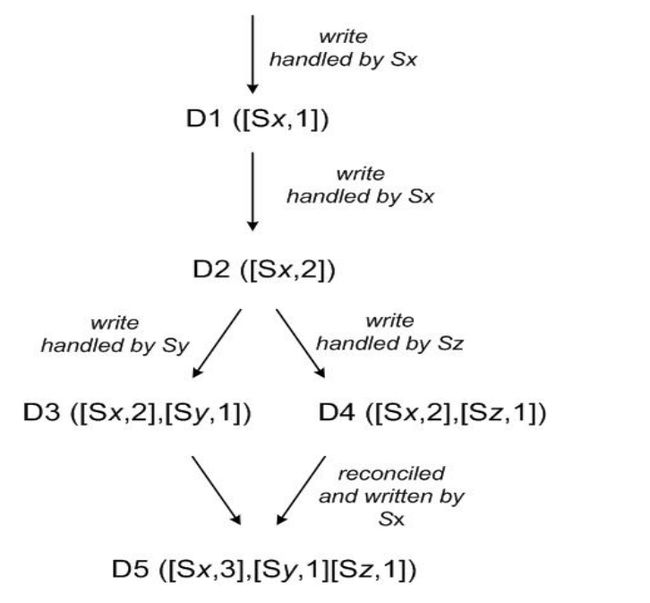
首先,客户端写入一个对象。处理这个 key 的写请求的节点 Sx 增加 key 的序列号(计数),并用这个序列号创建对象的 vector clock。至此,系统有了一个对象 D1 和它的时钟 [(Sx, 1)]。
第二步,客户端更新这个对象。假设还是 Sx 处理这个请求。此时,系统有了对象 D2 和它的时钟 [(Sx, 2)]。D2 是 D1 的后代,因此可以覆盖 D1;但是,D1 在其他节点上的副本可能还没有看到 D2 这次更新。
第三步,假设还是这个客户端,再次更新了对象,并且这次是由另外的一个节点 Sy 处理请求。此时,系统有了 D3 和它的时钟 [(Sx, 2), (Sy, 1)].
接下来,假设另一个客户端读取 D2,并尝试更新它,写请求由另一个节点 Sz 处理。 现在,系统有 D4(D2 的后代),版本 clock 是 [(Sx, 2), (Sz, 1)]。如果一个节点知道 D1 和 D2,那它收到 D4 和它的 clock 后,就可以断定 D1 和 D2被同一个新数据覆盖了,因此可以安全地删除 D1 和 D2。但如果一个节点只知道 D3,那它收到 D4 后就看不出这两个版本有何因果关系。换言之,D3 和 D4 各自的改动并没有反映在对方之中。因此这两个版本都应当被保留,然后交给客户端,由客户端(在下一次读到时候)执行 semantic reconciliation。
现在,假设一些客户端把 D3 和 D4 都读到了(context 会同时显示 D3 和 D4 )。读操作返回的 context 综合了 D3 和 D4 的 clock,即 [(Sx, 2), (Sy, 1), (Sz, 1)]。如果客户端执行 reconciliation,并且节点 Sx 执行协调写(coordinates the write),Sx 会更新自己在 clock 中的序列号。最终新生成的数据 D5 的 clock 格式如下:[(Sx, 3), (Sy, 1), (Sz, 1)]。
vector clock 的一个潜在问题是:如果有多个节点先后 coordinate 同一个对象的写操作,那这个对象的 clock vector 会变得很长。但在实际中这不太可能发生,因为 写操作 coordination 只会由 preference list 中前 N 个节点中的一个来执行。 只有在网络分裂或多台服务器挂掉的情况下,写操作才可能由非 preference list 前 N 个节点来执行,导致 vector clock 变长。在这种情况下,应该要限制 vector clock 的长度 。
Dynamo 采用了一种 clock 截断方案(clock truncation scheme): 另外保存一个和 (node, counter) 对应的时间戳,记录对应的节点最后一次更新该记录的时间。当 vector clock 里的 (node, counter) 数量达到一个阈值(例如10)时, 就删除最老的一项。
显然,这种截断方案会给 reconciliation 带来一定问题,因为截断后可能无法精确判断部分后代的因果关系。但到目前为止,我们还没有在生产环境遇到这个问题,因此没有继续深入研究下去。
4.5 get() 和 put() 的执行过程
在 Dynamo 中,任何存储节点都可以接受任何 key 的 get 和 put 操作请求。本节先介绍在无故障场景下这些操作是如何执行的,下一节介绍有故障的场景。
节点的选择
get 和 put 操作由 Amazon 基础设施相关的请求处理框架发起,使用 HTTP。 节点的选择有两种:
1.将请求路由到负载均衡器,由后者根据负载信息选择一个后端节点
2.使用能感知 partition 的客户端,直接将请求路由到某 coordinator 节点
第一种方式的好处是使用客户端的应用不需要了解任何 Dynamo 相关的代码,第二种的好处是延迟更低,因为跳过了一次潜在的转发步骤。
负责处理读或写请求的节点称为 coordinator。通常情况下,这是 preference list 内前N个节点中的第一个节点。如果请求是经过负载均衡器转发的,那这个请求可能会被转发到环上的任意一个节点。在这种情况下,如果收到请求的节点不是 preference list 的 前 N个节点中的一个,那它就不会处理这个请求,而是将其转发到 preference list 前 N 个节点中的第一个节点。
读或写操作需要 preference list 中前 N 个处于健康状态的节点,如果有 down 或不可访问状态的节点,要跳过。如果所有节点都是健康的,那就取 preference list 的前 N 个节点。如果发生节点故障或网络分裂,优先访问 preference list 中编号较小的节点。
读写操作仲裁算法
为了保证副本的一致性,Dynamo 使用了一种类似仲裁系统(quorum systems)的一致性协议。 这个协议有两个配置参数:
R:允许执行一次读操作所需的最少投票者
W:允许执行一次写操作所需的最少投票者
设置 R + W > N,就得到了一 个类似仲裁的系统。在这种模型下,一次 get (或 put)的延迟由 R(或 W)个副本中最慢的一个决定(木桶效应)。因此,为了降低延迟,R 和 W 通常设置的比 N 小。
写和读过程
当收到一个 put() 请求后,coordinator 会为新版本生成 vector clock,并将其保存到节点本地;然后,将新版本(及对应的新 vector clock)发送给 N 个排在最前面的、可到达的节点。只要有至少 W-1 个节点返回成功,这次写操作就认为是成功了。
类似地,对于一次 get() 请求,coordinator 会向排在最前面的 N 个(highest-ranked )可访问的节点请求这个key 对应的数据的版本,等到 R 个响应之后,就将结果返回给客户端。如果 coordinator 收集到了多个版本,它会将所有它认为没有因果关系的版本返回给客户端。客户端需要对版本进行 reconcile,合并成一个最新版本,然后将结果写回 Dynamo。
4.6 故障处理: Hinted Handoff
如果使用传统仲裁算法,Dynamo 无法在服务器宕机或网络分裂的时候仍然保持可用,而且在遇到最简单故障情况下,持久性也会降低。因此,Dynamo 采用了一种宽松的仲裁机制(sloppy quorum):所有读和写操作在 preference list 的前 N 个健康节点上执行;注意这 N 个节点不一定就是前 N 个节点, 因为遇到不健康的节点,会沿着一致性哈希环的顺时针方向顺延。
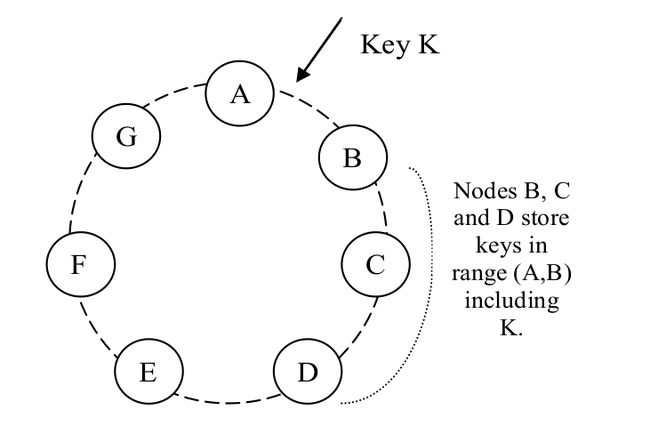
以上图为例,其中 N=3。如果 A 临时不可用,正常情况下应该到达A的写请求就会发送到 D。这样设计是为了保证期望达到的可用性和持久性。发送到 D 的副本的元数据中会提示(hint)这个副本本来应该发送给谁(这里是 A),然后这个数据会被 D 保存到本地的一个独立数据库中,并且有一个定期任务不断扫描,一旦 A 可用了,就将 这个数据发送回 A,然后 D 就可以从本地数据库中将其删除了,这样系统内的副本数还是保持不变。
使用这种 hinted handoff 的方式,Dynamo保证了在节点或网络发生短时故障时读和写操作不会失败。希望可用性最高的应用可以将 W 设为 1,这样可以保证只要一个节点完成写,这次写操作就被系统接受了。在这种情况下,除非全部节点都不可用,否则写操作就不会被拒绝。但实际上,大部分 Amazon 的应用都是把 W设置为一个比 1 大的值,以达到期望的持久性等级。我们会在第 6 节更深入地讨论 N、R 和 W 的配置。
高可用的存储系统必须能够处理整个数据中心挂掉的情况。掉电、制冷失效、网络故障以及自然灾难都会导致整个数据中心发生故障。Dynamo 可以把多个副本部署在多个数据中心,只要将 preference list 里的节点分散到不同数据中心。这些数据中心之间通过高速网络互连。这使得我们可以在整个数据中心挂掉的情况下仍然可以提供服务。
4.7 持久故障处理: 副本同步
在节点成员变动较小、节点只是短时故障的情况下,hinted handoff 方式工作良好。但也有一些场景,在 hinted 副本移交给原本应该存储这个副本的节点之前,该副本就不可用了 。为了解决这个威胁到持久性的场景,Dynamo 实现了一种逆熵副本同步协议来保证副本是同步的。
为了快速检测副本之间的不一致性,以及最小化转移的数据量,Dynamo 使用了 Merkle trees。一个 Merkle tree 就是一个哈希树,其叶子节点是key 对应的 value 的哈希值。父节点是其子节点的哈希。Merkle tree 的主要优点是:1.每个分支都可以独立查看(check),节点无需下载整棵树或者整个数据集;2.减少检查副本一致性时所需传输的数据量.例如,如果两棵树的root节点的哈希值相同,那这两棵树的叶子节点必然相同,这两台 node之间就无需任何同步;否则,就说明两台 node 之间的某些副本是不同的,这种情况下两台node 就需要交换其child节点的哈希值,直到到达叶子节点,就找到了未同步(out of sync)的 key(从root到leaf)。Merkle tree 最小化了同步时需要转移的数据量,减少了逆熵过程中读取磁盘的次数。
Dynamo 使用 Merkle tree 实现逆熵的过程如下:每个节点为每段 key range(一台虚拟节点所覆盖的 key 的范围)维护了一棵单独的 Merkle tree。这使得节点之间可以比较 key range,确定其维护的 range 内的 key 是否是最新的。在这种方案中,两个节点会交换他们都有的 key range 所对应的 Merkle tree 的root节点。然后,根据前面提到的【找不同】的方法, node 可以判断是否有不一致,如果有就执行同步。
这种方案的缺点是:每当有节点加入或离开系统时,一些 key range 会变,因此对应的 tree 需要重新计算。我们会在 6.2 节介绍如何通过改进的 partitioning scheme 解决这个问题。
4.8 Membership和故障检测
4.8.1 Ring Membership
在 Amazon 的环境中,节点服务不可用(故障或维护导致的)通常情况下持续时间都很短, 但也存在中断比较长的情况。一个节点服务中断并不能说明这个节点永久性的离开了系统, 因此不应该让系统触发rebalance或者修复无法访问的副本。 与此类似,无意的手动操作可能导致新的节点加入到 Dynamo。(也就是说系统中可能经常出现节点的删除和加入,但我们不应该去真的让它work)
因此,为了避免以上这些问题,我们决定使用显式机制来向 Dynamo 的 Ring 增删节点。管理员通过命令行或 web 方式连接到 Dynamo 中的某一个节点,然后下发一个成员变更命令,来将 某个node 添加到 ring 或从 ring 删除。负责处理这个请求的节点 将成员变动信息和对应的时间写入持久存储。成员变动会形成历史记录,因为一个节点可能会多次从系统中添加和删除。Dynamo使用 gossip-based 协议来传递成员变动信息,维护成员的最终一致视图。每个节点每秒会随机选择另一个节点作为对端,这两个节点会高效地 reconcile 它们的成员变动历史。
每个节点到各自的 token 集合的映射关系(node-> token set)会持久存储在磁盘上。当一个节点第一次起来时,首先会选择它的 token 集合(虚拟节点),然后将映射关系load到内存中。这个map初始时只包含本 node 和它的 token set。存储在不同 Dynamo 节点上的映射关系,会在节点交换成员变动历史时被reconcile。因此,partitioning 和 placement(数据的放置信息)也会通过 gossip 协议进行扩散,最 终每个节点都能知道其他节点负责的 token 范围。这使得每个节点可以将一个 key 的读/写操作直接发送给正确的节点进行处理。
4.8.2 External Discovery
以上机制可能导致 ring 临时的逻辑分裂。例如,管理员先联系 node A,将 A 加入 ring,然后又联系 node B 加入 ring。在这种情况下,A 和 B 都会认为它们自己是 ring 的成员,但不会立即感知到对方。
为了避免逻辑分裂,我们会将一些 Dynamo 节点作为种子节点。种子节点是通过外部机制(external mechanism)发现的,所有节点都知道种子节点的存在。因为所有节点最终都会和种子节点 reconcile 成员信息,所以逻辑分裂就几乎不可能发生了????。种子节点可以在静态配置文件中设置,或者从一个配置中心获取。通常情况下,种子节点具有普通节点的全部功能。
4.8.3 故障检测
故障检测在 Dynamo 中用于如下场景下跳过不可达的节点:get() 和 put() 操作时;转移 partition 和 hinted replica 时;
要避免尝试与不可达节点通信,一个纯本地概念(pure local notion)的故障检测就足够了:节点 B 只要没有应答节点 A 的消息,A 就可以认为 B 不可达(即使 B 可以应答 C 的消息)。
在客户端持续发送请求的情况下,Dynamo ring 的节点之间就会有持续的交互;因此只要 B 无法应答消息,A 可以很快就可以发现;在这种情况下,A 可以选择(和与 B 同属一个 partition 的???我觉得这里不是这个意思)其他节点来处理请求,并定期地检查 B 是否活过来了。在没有持续的客户端请求的情况下,两个节点都不需要知道另一方是否可达。
去中心化故障检测协议使用简单的 gossip 风格协议,使得系统内的每个节点都可以感知到其他节点的加入或离开。想详细了解去中心化故障检测机制及其配置,可以参考 [8]。Dynamo 的早期设计中使用了一个去中心化的故障检测器来维护故障状态的全局一致视图。后来我们发现,我们显式的节点加入和离开机制使得这种全局一致视图变得多余了。因为节点的真正(permanent)加入和离开消息,依靠的是我们的显式添加和删除节点机制;而临时的加入和离开,由于节点之间的互相通信(转发请求时),它们自己就会发现。
4.9 添加/移除存储节点
当一个新节点 X 加入到系统后,它会获得一些随机分散在 ring 上的 token。对每个分配给 X 的 key range,当前可能已经有一些(小于等于 N 个)节点在负责处理了 。因此,将 key range 分配给 X 后,这些节点就不需要处理这些 key 对应的请求了,而 要将 keys 转给 X。考虑一个简单的情况:X 加入图 2 中 A 和 B 之间。这样,X 就负责处理落到 (F, G], (G, A] and (A, X] 之间的 key。结果,B、C 和 D 节点就不需负责相应 range 了。因此,在收到 X 的转移 key 请求之后,B、C 和 D 会向 X 转移相应的 key。当移除一个节点时,key 重新分配的顺序和刚才相反。
我们的实际运行经验显示,这种方式可以在存储节点之间保持 key 的均匀分布,这有利于保证低延迟和快速 bootstrapping。另外,在源和目的节点之间加了确认(转移),可以保证不会转移重复的 key range。