上一篇文章 Pytorch 实现自定义卷积:以 2.5 维卷积(2.5D Convolution)为例 已经简要的讲解了使用 Pytorch 来自定义卷积层,但略有不足的是没有提供将它直接应用于实际数据集的训练案例,因此会有一种空中楼阁的美中不足之感。本文继续讲解利用 Pytorch 自定义卷积运算,并将它立即应用到 Deep Image Matting 抠图模型,进一步说明掌握自定义卷积运算是必要和有意义的。(Deep Image Matting 论文的实现见文章 Pytorch 抠图算法 Deep Image Matting 模型实现,本文代码的运行方式也见该文章的第三部分)
本文主要关注两个点:1. 使用 Pytorch 来自定义卷积;2. 将自定义的卷积应用于 Deep Image Matting 抠图模型。本文重点在介绍利用 Pytorch 来自定义卷积层,而应用到 Deep Image Matting 只是为了提供一个可训练的案例(当然效果也不差),借此验证自定义卷积层的方法是正确的和有效的。
本文所有代码见 GitHub: deep_image_matting_variant。支持 Pytorch 1.1.0 及以上版本。
一、Deep Image Matting 回顾
抠图是一个比较传统和应用广泛的技术,目前已经提出了一大批的算法,见 AlphaMatting,虽然以传统图像处理的方式居多,但随着深度学习技术的突飞猛进,当前抠图效果排行榜前几名已经被基于深度学习的算法占据。抠图问题可以用如下的方程来描述:
其中 表示给定的的要被抠的图像, 分别表示前景、背景, 表示透明度的 alpha 通道。抠图算法要求解的是上述方程右边的 ,但是因为图像有三个通道,因此方程右边有 7 个未知数,而左边只有 3 个已知值,因此是一个不定方程(未知数的个数比约束条件的个数多)。为了求出方程的确定解,通常的做法是添加一些额外的约束,或者事先给定一个三分图 trimap,或者给定一个草图 scribble。比如,给定一张要被抠的图像:

那么对应的三分图则类似于:

其中,白色部分表示一定是前景的区域(像素值 255),而黑色则一定是背景(像素值 0),剩下的灰色是不确定区域(像素值 128),需要抠图算法来求解;而草图则比较随意:

可以将它看成是三分图的极其简易版本。
Deep Image Matting 使用卷积神经网络来从给定的原图和三分图中预测 alpha 通道,具体为:将原图(RGB 三通道)和三分图(单通道)拼接成一个 4 通道图像,然后输入卷积神经网络,首先借助卷积网络从图像中提取特征(编码器,图像分辨率下降),然后利用反池化提升分辨率并预测与输入一样大小的 alpha 通道(解码器),整个编码-解码的过程组成网络的第一阶段(编码器-解码器阶段);因为网络只关心三分图的不确定区域(灰色区域,对于确定区域由 trimap 提供 alpha 通道值),显然有理由相信网络的预测值要比输入的 trimap 更准确,如果用这个预测的 alpha 通道替换原来的 trimap,和原图再次合并重新进行编码-解码过程,那么新的预测值将更加准确,不过缺点也很明显,就是网络太大了,为了兼顾利用预测的更准确的 alpha 通道,又不至于使网络结构太复杂,论文作者将原图和预测的 alpha 通道合并之后,进行了 4 次卷积运算,输出最终的 alpha 通道的预测值,这个过程称为网络的细化阶段。整个过程如下:
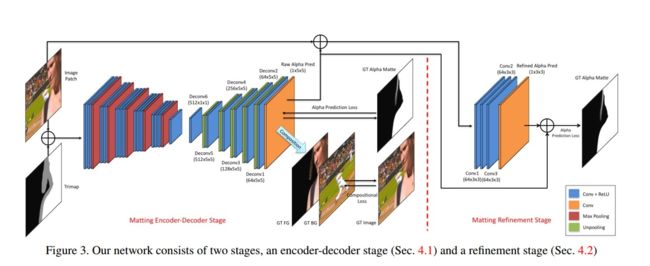
为了更好的理解,我们先来仔细的推敲一下网络结构。网络的编码器阶段用的是 VGG-16 的前 13 个卷积层和其后的 1 个全连接层(看成是 1x1 的卷积层),穿插在这 14 个卷积层中间的是 5 个 2x2 的最大池化层,因此编码器阶段图像的分辨率下降了 32 倍,对于 320x320 的输入,此时特征映射的分别率为 10x10。解码器阶段几乎是编码器阶段的逆过程,先接 1 个 1x1 的卷积层,之后接 5 个 5x5 的卷积层,这 5 卷积层之前都使用了 2x2 的反池化层来提升图像的分辨率,因此特征映射的分辨率又恢复到了 320x320,最后再接 1 个 5x5 的单通道卷积预测,作用 Sigmoid 激活函数之后,即是 alpha 通道的预测值。论文作者为了最求极致效果,在以上网络的基础上,再接了一个小型的网络,即整个抠图模型的细化阶段。细化阶段只接了包含预测层在内的 4 个 3x3 的卷积层。
实际抠图的时候,先将 RGB 3 通道待抠图像(由前景、背景与真实 alpha 通道合成),和预先给定的 trimap 1 通道图像拼接成一个 4 通道图像,然后经过编码器-解码器阶段的预测得到一个粗略的 alpha 通道值,再将 RGB 3 通道待抠图像和这个预测的 alpha 1 通道拼接成 4 通道图像输入细化阶段,得到最终的 alpha 通道预测值。图像的预处理的方式为:RGB 3 通道待抠图像采用 VGG-16 的处理方式,即减去均值再除以标准差,trimap 通道则直接除以 255 压缩到 0~1 之间即可。
网络的损失由三部分通过加权和的方式组成:
- 编码器-解码器阶段预测的 alpha 与真实 alpha 通道之间的损失;
- 前景、背景与预测的 alpha 和真实 alpha 通道合成图像之间的损失
- 细化阶段预测的最终 alpha 与真实 alpha 通道之间的损失;
所有损失都是逐点像素之间的平方和误差:
其中, 是为了损失函数可微而引进的常数值。实际计算时只计算未知区域部分的损失值。
训练的时候,论文作者们采用了分阶段训练的策略:
- 首先单独训练第一阶段(编码器-解码器阶段);
- 然后固定第一阶段的参数,只训练第二阶段(细化阶段);
- 最后联合微调两个阶段的参数
训练时的数据增强如下:
- trimap 由真实的 alpha 通过随机大小的腐蚀膨胀而来;
- 随机的从图像中裁剪 [320x320, 480x480, 640x640] 大小的图块,然后缩放到 320x320 输入大小;
- 随机的水平翻转;
- 每训练一轮之后,随机的由前景、背景和真实 alpha 通道合成待抠图像(前景:背景=1:100)
训练数据请到此 链接 联系作者获取。网络参数的初始化方式为:编码器阶段因为直接来源于 VGG-16,所以直接导入预训练参数即可,其它层则随机初始化。这里需要注意的一点是:因为模型结构已将第一个卷积层的输入通道由 3 变成 4,所以导入预训练参数时,只赋值给前 3 个通道的参数,第 4 个通道的参数则直接零初始化。
如果完全按照论文作者的网络结构构建模型的话,那么因为第 14 层是一个全连接层(看成是 1x1 的卷积层),因此参数量巨大,一方面很容易造成网络的过拟合,另一方面也很难令网络快速的收敛(是否是这个原因让论文作者采用分阶段训练的策略?)。因此,实际实现时,一般要去掉第 14 个卷积层,而只用前 13 个卷积层(从而只用 4 个最大池化层),另外实践显示,加入批标准化(Batch Normalization)既有助于加快网络收敛,又有益于提升抠图效果。因此实现模型时,通常都做如下修改:
- 只用 VGG-16 的前 13 个卷积层(和前 4 个最大池化层);
- 所有卷积层之后都加入批标准化层;
另外,做以下简化:
- 去掉细化阶段,损失简化成只求 alpha 通道之间的损失
也不会特别大的影响的抠图效果。因此,本文实现的 Deep Image Matting 模型做了以上 3 点修改或简化。
上面已经提到过了,Deep Image Matting 模型的编码器采用的是 VGG-16 的所有卷积层,而且将第一个卷积层的通道数由 3 改成了 4,在导入预训练模型时,VGG-16 预训练模型的第一个卷积层的参数只赋值给 Deep Image Matting 模型第一个卷积层的前 3 个通道,第 4 个通道的参数全部零初始化。这是一种处理方式,另一种处理方式是:可以在网络的最前面接一个卷积层,该卷积层将 4 通道转为 3 通道,然后再接 VGG-16 的卷积层。本文作为 Pytorch 自定义卷积层的教程,再介绍一种新的处理方式:保持第一个卷积层 3 通道的输入,将 trimap 作为卷积运算的权重来处理,此时预训练模型直接无任何修改的导入即可。
二、自定义卷积层
本节的目标是:保持 Deep Image Matting 第一个卷积层 3 通道的输入(确切的说是保持 Deep Image matting 编码器结构为 VGG-16 的前 13 个卷积层,方便导入预训练模型),同时又用自定义卷积层优雅的利用 trimap 的信息而让网络能达到同等级别的抠图性能。
因为我们已经有了三分图 trimap,其上黑色区域(像素值 0)表示确定为背景的区域,白色区域(像素值 255)表示确定为前景的区域,只有灰色区域(像素值 128)是未知区域,需要抠图模型来预测每个像素是前景的概率,因此模型需要特别关心的就是这些未知区域,实际上计算损失的时候只计算未知区域的 alpha 通道(正规化到 [0, 1])的平均平方误差(而且这是模型效果好的必要条件,如果对整个 alpha 通道计算损失则效果很差),通过损失的反向传播让模型只聚焦于未知区域。
基于以上的认识,设计一种加权卷积如下:如果一个像素点落在未知区域内则将它的权重值设得略大一点,否则则适当的设小一点。比如,对于 3x3 的传统卷积:
将其修改为如下带额外权重的卷积:
其中额外权重 的定义需要满足上文提到的需求:当点落在未知区域上时,额外权重值大,否则相对较小,以此让网络更加关注未知区域。作为一个特例,记 为三分图 trimap 的二维矩阵,定义:
因为我们的目的是让 在 的时候大,而在 和 的时候小,所以可以取 ,此时 是一个开口向下的抛物线,最大值 2 在点 时取得。考虑到 的取值可能过于主观,因此让它们成为变量而不是常数更好,这样前面的取值可以作为它们的初始化,而它们确切的值则随着模型的训练而发生改变。
下面,我们来定义这种带额外权重的卷积。
先来计算 的值
Pytorch 任何需要计算梯度的运算都可以通过继承 torch.autograd.function.Function 类实现。在继承该类时,因为网络有前向传播和反向传播两个过程,因此需要重载 forward 和 backward 这两个函数。顾名思义,这两个函数分别用于前向计算和反向梯度计算。重载这两个函数时,需要将它们定义为静态函数,同时 forward 函数的参数个数(不计算 ctx,ctx 跟 self 的作用类似)和 backward 的返回值个数一致,即要对所有输入参数返回它们的梯度,如果某个输入参数不需要计算梯度,那么返回 None 即可。同理,backward 函数的输入参数数目和 forward 函数的返回值个数一致,因为反向传播是从后计算的,先计算 forward 函数的输出的梯度,然后通过这些输出的梯度根据链式法则来计算 forward 函数的各个输入的梯度。
来看具体的计算过程:
class SquareKernelFn(torch.autograd.function.Function):
"""Compute kernel for square funcion."""
@staticmethod
def forward(ctx, alpha, a, b, c, kernel_size, stride, padding, dilation):
"""Forward computation.
Implementation of computation: ax^2 + bx + c.
Args:
alpha: A tensor with shape [batch, 1, height, width] representing
a batch of depth maps.
a, b, c: Scalars.
Returns:
A tensor with shape [batch, 1, k, k, N, N], where
k = kernel_size and N = number of slide windows.
"""
ctx.kernel_size = torch.nn.modules.utils._pair(kernel_size)
ctx.stride = torch.nn.modules.utils._pair(stride)
ctx.padding = torch.nn.modules.utils._pair(padding)
ctx.dilation = torch.nn.modules.utils._pair(dilation)
ctx.scalars = (a, b, c)
needs_grad = ctx.needs_input_grad
needs_grad = needs_grad[0] or needs_grad[1] or needs_grad[2]
ctx.save_for_backward(alpha if needs_grad else None)
ctx._backend = torch._thnn.type2backend[alpha.type()]
batch_size, channels, in_height, in_width = alpha.shape
out_height = (in_height + 2 * ctx.padding[0] -
ctx.dilation[0] * (ctx.kernel_size[0] - 1)
-1) // ctx.stride[0] + 1
out_width = (in_width + 2 * ctx.padding[1] -
ctx.dilation[1] * (ctx.kernel_size[1] - 1)
-1) // ctx.stride[1] + 1
alpha_wins = torch.nn.functional.unfold(alpha, ctx.kernel_size,
ctx.dilation, ctx.padding,
ctx.stride)
alpha_wins = alpha_wins.view(batch_size, channels, ctx.kernel_size[0],
ctx.kernel_size[1], out_height,
out_width)
square_alpha_wins = (a * alpha_wins + b) * alpha_wins + c
return square_alpha_wins
@staticmethod
@torch.autograd.function.once_differentiable
def backward(ctx, grad_outputs):
grad_alpha = grad_a = grad_b = grad_c = None
batch_size, out_channels = grad_outputs.shape[:2]
output_size = grad_outputs.shape[-2:]
# Compute gradients
a, b, c = ctx.scalars
alpha = ctx.saved_tensors[0]
_, in_channels, in_height, in_width = alpha.shape
needs_input_grad = ctx.needs_input_grad
if needs_input_grad[0] or needs_input_grad[1] or needs_input_grad[2]:
grad_alpha = grad_outputs.new()
alpha_wins = torch.nn.functional.unfold(alpha, ctx.kernel_size,
ctx.dilation, ctx.padding,
ctx.stride)
alpha_wins = alpha_wins.view(batch_size,
in_channels,
ctx.kernel_size[0],
ctx.kernel_size[1],
output_size[0],
output_size[1])
if needs_input_grad[0]:
grad_alpha_wins = (2 * a * alpha_wins + b) * grad_outputs
grad_alpha_wins = grad_alpha_wins.view(
batch_size, -1, output_size[0] * output_size[1])
grad_alpha = torch.nn.functional.fold(grad_alpha_wins,
(in_height, in_width),
ctx.kernel_size,
ctx.dilation,
ctx.padding,
ctx.stride)
if ctx.needs_input_grad[1]:
grad_a = alpha_wins * alpha_wins * grad_outputs
grad_a = torch.einsum('ijklmn->', (grad_a,))
if ctx.needs_input_grad[2]:
grad_b = alpha_wins * grad_outputs
grad_b = torch.einsum('ijklmn->', (grad_b,))
if ctx.needs_input_grad[3]:
grad_c = torch.einsum('ijklmn->', (grad_outputs,))
return grad_alpha, grad_a, grad_b, grad_c, None, None, None, None
我们知道,卷积运算是根据滑动窗口分块进行计算的,因此首先通过 torch.nn.functional.unfold 函数将 alpha(理解成三分图 trimap)分成一个一个的滑动窗口小分块,对于批量 、通道数、分辨率 的输入 ,形状为: ,如果卷积核大小(kernel size)、填充大小(padding)、步幅(stride)、空洞率(dilation)分别为 ,那么该函数的输出大小为:,是一个 3 维张量,其中:
为了便于理解和计算,通过 view 函数将它变成形状为 的 6 维张量(对于这里的 alpha 来说,)。最后直接计算二次方程即结束了 forward 函数的定义。
对于反向传播求梯度,即 backward 函数的内容,首先要清楚的一点是 grad_outputs 表示的是 forward 函数的输出 square_alpha_wins 的梯度,因此根据链式法则,alpha 的梯度计算如下:
grad_alpha_wins = (2 * a * alpha_wins + b) * grad_outputs
grad_alpha_wins = grad_alpha_wins.view(
batch_size, -1, output_size[0] * output_size[1])
grad_alpha = torch.nn.functional.fold(grad_alpha_wins,
(in_height, in_width),
ctx.kernel_size,
ctx.dilation,
ctx.padding,
ctx.stride)
这里需要注意的是 alpha 梯度张量的形状与 alpha 的形状是一样的,但 grad_alpha_wins 的形状是 6 维的:,因此要通过函数 torch.nn.functional.fold 把所有的滑动窗口小分块折叠回去(fold 和 unfold 互为反函数),这个函数的第 1 个参数的形状是 3 维张量(即 unfold 函数的输出张量的形状),第 2 个参数是这个函数输出的目标分辨率(也就是 unfold 函数的输入的张量的分辨率),其它参数顾名思义,不再赘述。关于 的梯度的计算也是直接的,略过。
额外补充的几个点是:
-
torch.nn.modules.utils._pair()函数将输入变成成对的元组,如果输入本身是成对的元组,则输出不变。比如:_pair(3), _pair((3, 3))的结果都是 (3, 3); - ctx.needs_input_grad 记录的是
forward函数的每个参数(不计 ctx)是否需要求梯度的信息,比如 ctx.needs_input_grad[0] 记录是否对参数 alpha 求梯度,如果是 True,则需要对 alpha 求梯度,否则不需要,返回 None 即可。 -
forward函数中的张量(Tensor)可通过ctx.save_for_backward()函数传递给backward函数,通过ctx.saved_tensors取出。比如,ctx.save_for_backward(t1, t2, ..., tn) 将 tk 传递给backward,然后通过 t1, t2, ..., tn = ctx.saved_tensors 等方式取出来。 -
forward函数中的非张量变量、常量可通过类属性的方式传值,比如 ctx.a = a。
再来计算自定义卷积
理解和清楚了 k 的计算过程之后,很容易的,你可以直接写出带额外权重的卷积运算:
class KernelConvFn(torch.autograd.function.Function):
"""2D convolution with kernel.
Copy from: https://github.com/NVlabs/pacnet/blob/master/pac.py/PacConv2dFn
"""
@staticmethod
def forward(ctx, inputs, kernel, weight, bias=None, stride=1, padding=0,
dilation=1):
"""Forward computation.
Args:
inputs: A tensor with shape [batch, channels, height, width]
representing a batch of images.
kernel: A tensor with shape [batch, channels, k, k, N, N],
where k = kernel_size and N = number of slide windows.
weight: A tensor with shape [out_channels, in_channels,
kernel_size, kernel_size].
bias: None or a tenor with shape [out_channels].
Returns:
outputs: A tensor with shape [batch, out_channels, height, width].
"""
(batch_size, channels), input_size = inputs.shape[:2], inputs.shape[2:]
ctx.in_channels = channels
ctx.input_size = input_size
ctx.kernel_size = tuple(weight.shape[-2:])
ctx.dilation = torch.nn.modules.utils._pair(dilation)
ctx.padding = torch.nn.modules.utils._pair(padding)
ctx.stride = torch.nn.modules.utils._pair(stride)
needs_input_grad = ctx.needs_input_grad
ctx.save_for_backward(
inputs if (needs_input_grad[1] or needs_input_grad[2]) else None,
kernel if (needs_input_grad[0] or needs_input_grad[2]) else None,
weight if (needs_input_grad[0] or needs_input_grad[1]) else None)
ctx._backend = torch._thnn.type2backend[inputs.type()]
# Slide windows, [batch, channels x kernel_size x kernel_size, N x N],
# where N is the number of slide windows.
inputs_wins = torch.nn.functional.unfold(inputs, ctx.kernel_size,
ctx.dilation, ctx.padding,
ctx.stride)
inputs_mul_kernel = inputs_wins.view(
batch_size, channels, *kernel.shape[2:]) * kernel
# Matrix multiplication
outputs = torch.einsum('ijklmn,ojkl->iomn', (inputs_mul_kernel, weight))
if bias is not None:
outputs += bias.view(1, -1, 1, 1)
return outputs
@staticmethod
@torch.autograd.function.once_differentiable
def backward(ctx, grad_outputs):
grad_inputs = grad_kernel = grad_weight = grad_bias = None
batch_size, out_channels = grad_outputs.shape[:2]
output_size = grad_outputs.shape[2:]
in_channels = ctx.in_channels
# Compute gradients
inputs, kernel, weight = ctx.saved_tensors
if ctx.needs_input_grad[0] or ctx.needs_input_grad[1]:
grad_inputs_mul_kernel = torch.einsum('iomn,ojkl->ijklmn',
(grad_outputs, weight))
if ctx.needs_input_grad[1] or ctx.needs_input_grad[2]:
inputs_wins = torch.nn.functional.unfold(inputs, ctx.kernel_size,
ctx.dilation, ctx.padding,
ctx.stride)
inputs_wins = inputs_wins.view(batch_size, in_channels,
ctx.kernel_size[0],
ctx.kernel_size[1],
output_size[0], output_size[1])
if ctx.needs_input_grad[0]:
grad_inputs = grad_outputs.new()
grad_inputs_wins = grad_inputs_mul_kernel * kernel
grad_inputs_wins = grad_inputs_wins.view(
batch_size, -1, output_size[0] * output_size[1])
grad_inputs = torch.nn.functional.fold(grad_inputs_wins,
ctx.input_size,
ctx.kernel_size,
ctx.dilation,
ctx.padding,
ctx.stride)
if ctx.needs_input_grad[1]:
grad_kernel = inputs_wins * grad_inputs_mul_kernel
grad_kernel = grad_kernel.sum(dim=1, keepdim=True)
if ctx.needs_input_grad[2]:
inputs_mul_kernel = inputs_wins * kernel
grad_weight = torch.einsum('iomn,ijklmn->ojkl',
(grad_outputs, inputs_mul_kernel))
if ctx.needs_input_grad[3]:
grad_bias = torch.einsum('iomn->o', (grad_outputs,))
return (grad_inputs, grad_kernel, grad_weight, grad_bias, None, None,
None)
这个类的 forward 函数执行的操作是按照滑动窗口计算 inputs x kernel x weight,因为 kernel 是纯符号化的,因此上面这个类是自定义卷积运算的通用类,凡是符合局部运算 inputs x kernel x weight 的自定义卷积都可以使用。实际上,这个类是从这个项目 pacnet
复制来的,位于 pac.py/PacConv2dFn,只有部分符号有轻微差异。
唯一需要指出的是 torch.einsum 函数表示爱因斯坦求和,根据爱因斯坦和式约定,求和号中指标相同时可以省略求和符号,比如:
举一个简单的例子:
a = torch.tensor([[-1, -2, -3], [-4, -5, -6]])
b = torch.tensor([[1, 2, 3], [4, 5, 6]])
s = torch.einsum('ij,ij->', (a, b)) # Summation of elmentwise multiply
# s = tensor(-91)
s = torch.einsum('ij,kj->ik', (a, b)) # Matrix multiply
#s = tensor([[-14, -32],
# [-32, -77]])
s = torch.einsum('ij,ik->jk', (a, b)) # Matrix multiply
# s = tensor([[-17, -22, -27],
# [-22, -29, -36],
# [-27, -36, -45]])
封装成自定义卷积层
要将我们自定义的卷积成为像 torch.nn.Conv2d 这种非常方便调用的类,还需要最后封装一下。这直接通过继承 torch.nn.Module 类实现。具体为:
- 通过
torch.nn.parameter.Parameter定义权重参数:weight、bias 等,并适当的初始化它们; - 重载
forward函数,调用自定义 SquareKernelFn 等类时,使用apply函数,参数与其forward函数相同;
如下,我们将自定义的平方额外权重卷积封装成 ConvSquare 类:
class ConvSquare(torch.nn.Module):
"""Implementation of square weighted convolution."""
def __init__(self, in_channels, out_channels, kernel_size, stride=1,
padding=0, dilation=1, bias=True, a=None, b=None, c=None):
"""Constructor."""
super(ConvSquare, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = torch.nn.modules.utils._pair(kernel_size)
self.stride = torch.nn.modules.utils._pair(stride)
self.padding = torch.nn.modules.utils._pair(padding)
self.dilation = torch.nn.modules.utils._pair(dilation)
# Parameters: weight, bias
self.weight = torch.nn.parameter.Parameter(
torch.Tensor(out_channels, in_channels, kernel_size,
kernel_size))
if bias:
self.bias = torch.nn.parameter.Parameter(
torch.Tensor(out_channels))
else:
self.register_parameter('bias', None)
# Scalars
self.a = a
self.b = b
self.c = c
# Initialization
self.reset_parameters()
def forward(self, inputs, alpha):
"""Forward computation.
Args:
inputs: A tensor with shape [batch, in_channels, height, width]
representing a batch of images.
alpha: A tensor with shape [batch, 1, height, width] representing
a batch of depth maps.
Returns:
outputs: A tensor with shape [batch, out_channels, height, width].
"""
kernel = SquareKernelFn.apply(alpha, self.a, self.b, self.c,
self.kernel_size, self.stride,
self.padding, self.dilation)
outputs = KernelConvFn.apply(inputs, kernel, self.weight,
self.bias, self.stride,
self.padding, self.dilation)
return outputs
def extra_repr(self):
s = ('{in_channels}, {out_channels}, kernel_size={kernel_size}'
', stride={stride}')
if self.padding != (0,) * len(self.padding):
s += ', padding={padding}'
if self.dilation != (1,) * len(self.dilation):
s += ', dilation={dilation}'
return s.format(**self.__dict__)
def reset_parameters(self):
torch.nn.init.kaiming_uniform_(self.weight, a=math.sqrt(5))
if self.bias is not None:
fan_in, _ = torch.nn.init._calculate_fan_in_and_fan_out(self.weight)
bound = 1 / math.sqrt(fan_in)
torch.nn.init.uniform_(self.bias, -bound, bound)
if self.a is None:
self.a = torch.nn.parameter.Parameter(torch.Tensor())
self.a.data = torch.tensor(-4.)
if self.b is None:
self.b = torch.nn.parameter.Parameter(torch.Tensor())
self.b.data = torch.tensor(4.)
if self.c is None:
self.c = torch.nn.parameter.Parameter(torch.Tensor())
self.c.data = torch.tensor(1.)
因为要支持 可训练,所以当初始化 ConvSquare 类时如果没有给 赋值,则通过 torch.nn.parameter.Parameter 将它们定义成可训练的参数,否则是不可训练的常数。
三、在 DIM 数据集上训练
使用 的初始学习率,每 20 个 epoch 衰减 0.8 的衰减策略下,训练 200 个 epoch 后,执行
python3 predict_trimap.py
在 test 文件内将看到测试图片的抠图结果:
从以上抠图的效果上看不算太糟,说明我们自定义的卷积层是正确的。
【注】
本次训练之后 的值为:
三者变化都不大(初始化:)。
【说明】
本文代码的运行方式也见如下文章的第三部分: Pytorch 抠图算法 Deep Image Matting 模型实现