机器学习(六) 卷积神经网络
机器学习(六) 卷积神经网络
参考及部分图片来源:
https://zhuanlan.zhihu.com/p/27908027
https://zhuanlan.zhihu.com/p/42559190
数据集来源:
kaggle:Stanford Dogs Dataset,
kaggle:Flowers Recognition
一、卷积神经网络
1.1 引子————边界检测
我们来看一个最简单的例子:“边界检测(edge detection)”,假设我们有这样的一张图片,大小8×8:
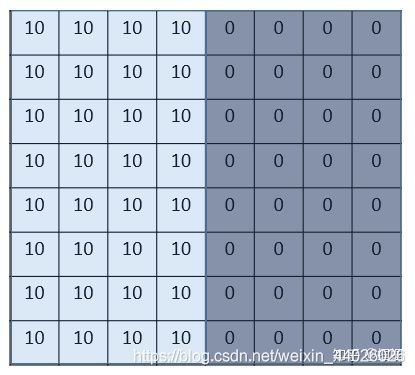
图片中的数字代表该位置的像素值,我们知道,像素值越大,颜色越亮,所以为了示意,我们把右边小像素的地方画成深色。图的中间两个颜色的分界线就是我们要检测的边界。
怎么检测这个边界呢?我们可以设计这样的一个 滤波器(filter,也称为kernel),大小3×3:

然后,我们用这个filter,往我们的图片上“盖”,覆盖一块跟filter一样大的区域之后,对应元素相乘,然后求和。计算一个区域之后,就向其他区域挪动,接着计算,直到把原图片的每一个角落都覆盖到了为止。这个过程就是 “卷积”。 (我们不用管卷积在数学上到底是指什么运算,我们只用知道在CNN中是怎么计算的。) 这里的“挪动”,就涉及到一个步长了,假如我们的步长是1,那么覆盖了一个地方之后,就挪一格,容易知道,总共可以覆盖6×6个不同的区域。
那么,我们将这6×6个区域的卷积结果,拼成一个矩阵:

发现了什么? 这个图片,中间颜色浅,两边颜色深,这说明咱们的原图片中间的边界,在这里被反映出来了!
从上面这个例子中,我们发现,我们可以通过设计特定的filter,让它去跟图片做卷积,就可以识别出图片中的某些特征,比如边界。 上面的例子是检测竖直边界,我们也可以设计出检测水平边界的,只用把刚刚的filter旋转90°即可。对于其他的特征,理论上只要我们经过精细的设计,总是可以设计出合适的filter的。
我们的CNN(convolutional neural network),主要就是通过一个个的filter,不断地提取特征,从局部的特征到总体的特征,从而进行图像识别等等功能。
那么问题来了,我们怎么可能去设计这么多各种各样的filter呀?首先,我们都不一定清楚对于一大推图片,我们需要识别哪些特征,其次,就算知道了有哪些特征,想真的去设计出对应的filter,恐怕也并非易事,要知道,特征的数量可能是成千上万的。
其实学过神经网络之后,我们就知道,这些filter,根本就不用我们去设计,每个filter中的各个数字,不就是参数吗,我们可以通过大量的数据,来 让机器自己去“学习”这些参数嘛。这,就是CNN的原理。
1.2 CNN基本概念
1.padding 填白
从上面的引子中,我们可以知道,原图像在经过filter卷积之后,变小了,从(8,8)变成了(6,6)。假设我们再卷一次,那大小就变成了(4,4)了。
这样有啥问题呢? 主要有两个问题: - 每次卷积,图像都缩小,这样卷不了几次就没了; - 相比于图片中间的点,图片边缘的点在卷积中被计算的次数很少。这样的话,边缘的信息就易于丢失。
为了解决这个问题,我们可以采用padding的方法。我们每次卷积前,先给图片周围都补一圈空白,让卷积之后图片跟原来一样大,同时,原来的边缘也被计算了更多次。

比如,我们把(8,8)的图片给补成(10,10),那么经过(3,3)的filter之后,就是(8,8),没有变。
我们把上面这种“让卷积之后的大小不变”的padding方式,称为 “Same”方式, 把不经过任何填白的,称为 “Valid”方式。这个是我们在使用一些框架的时候,需要设置的超参数。
2.stride 步长
前面我们所介绍的卷积,都是默认步长是1,但实际上,我们可以设置步长为其他的值。 比如,对于(8,8)的输入,我们用(3,3)的filter, 如果stride=1,则输出为(6,6); 如果stride=2,则输出为(3,3);(这里例子举得不大好,除不断就向下取整)
3.pooling 池化
这个pooling,是为了提取一定区域的主要特征,并减少参数数量,防止模型过拟合。 比如下面的MaxPooling,采用了一个2×2的窗口,并取stride=2:
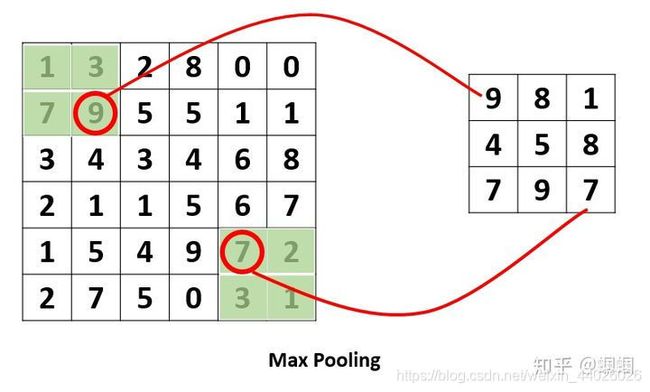
除了MaxPooling,还有AveragePooling,顾名思义就是取那个区域的平均值。
4.对多通道(channels)图片的卷积
这个需要单独提一下。彩色图像,一般都是RGB三个通道(channel)的,因此输入数据的维度一般有三个:(长,宽,通道)。 比如一个28×28的RGB图片,维度就是(28,28,3)。
前面的引子中,输入图片是2维的(8,8),filter是(3,3),输出也是2维的(6,6)。
如果输入图片是三维的呢(即增多了一个channels),比如是(8,8,3),这个时候,我们的filter的维度就要变成(3,3,3)了,它的 最后一维要跟输入的channel维度一致。 这个时候的卷积,是三个channel的所有元素对应相乘后求和,也就是之前是9个乘积的和,现在是27个乘积的和。因此,输出的维度并不会变化。还是(6,6)。
但是,一般情况下,我们会 使用多了filters同时卷积,比如,如果我们同时使用4个filter的话,那么 输出的维度则会变为(6,6,4)。
画了下面这个图,来展示上面的过程:

图中的输入图像是(8,8,3),filter有4个,大小均为(3,3,3),得到的输出为(6,6,4)。 我觉得这个图已经画的很清晰了,而且给出了3和4这个两个关键数字是怎么来的,所以我就不啰嗦了(这个图画了我起码40分钟)。
其实,如果套用我们前面学过的神经网络的符号来看待CNN的话,
- 我们的输入图片就是X,shape=(8,8,3);
- 4个filters其实就是第一层神金网络的参数W1,,shape=(3,3,3,4),这个4是指有4个filters;
- 我们的输出,就是Z1,shape=(6,6,4);
- 后面其实还应该有一个激活函数,比如relu,经过激活后,Z1变为A1,shape=(6,6,4);
所以,在前面的图中,我加一个激活函数,给对应的部分标上符号,就是这样的:

1.3 CNN的结构组成
上面我们已经知道了卷积(convolution)、池化(pooling)以及填白(padding)是怎么进行的,接下来我们就来看看CNN的整体结构,它包含了3种层(layer):
- Convolutional layer(卷积层–CONV)
由滤波器filters和激活函数构成。 一般要设置的超参数包括filters的数量、大小、步长,以及padding是“valid”还是“same”。当然,还包括选择什么激活函数。
- Pooling layer (池化层–POOL)
这里里面没有参数需要我们学习,因为这里里面的参数都是我们设置好了,要么是Maxpooling,要么是Averagepooling。 需要指定的超参数,包括是Max还是average,窗口大小以及步长。 通常,我们使用的比较多的是Maxpooling,而且一般取大小为(2,2)步长为2的filter,这样,经过pooling之后,输入的长宽都会缩小2倍,channels不变。
- Fully Connected layer(全连接层–FC)
这个前面没有讲,是因为这个就是我们最熟悉的家伙,就是我们之前学的神经网络中的那种最普通的层,就是一排神经元。因为这一层是每一个单元都和前一层的每一个单元相连接,所以称之为“全连接”。 这里要指定的超参数,无非就是神经元的数量,以及激活函数。
接下来,我们随便看一个CNN的模样,来获取对CNN的一些感性认识:

上面这个CNN是我随便拍脑门想的一个。它的结构可以用: X–>CONV(relu)–>MAXPOOL–>CONV(relu)–>FC(relu)–>FC(softmax)–>Y 来表示。
这里需要说明的是,在经过数次卷积和池化之后,我们 最后会先将多维的数据进行“扁平化”,也就是把 (height,width,channel)的数据压缩成长度为 height × width × channel 的一维数组,然后再与 FC层连接,这之后就跟普通的神经网络无异了。
可以从图中看到,随着网络的深入,我们的图像(严格来说中间的那些不能叫图像了,但是为了方便,还是这样说吧)越来越小,但是channels却越来越大了。在图中的表示就是长方体面对我们的面积越来越小,但是长度却越来越长了。
二、CNN应用1:Stanford Dogs
1.数据读入
import numpy as np # 导入Numpy
import pandas as pd # 导入Pandas
import os # 导入os工具
print(os.listdir("../input/stanford-dogs-dataset/images/Images"))
只处理10个目录:
# 本示例咱只处理这10种狗吧
dir = '../input/stanford-dogs-dataset/images/Images/'
chihuahua_dir = dir+'n02085620-Chihuahua' #吉娃娃
japanese_spaniel_dir = dir+'n02085782-Japanese_spaniel' #日本狆
maltese_dir = dir+'n02085936-Maltese_dog' #马尔济斯犬
pekinese_dir = dir+'n02086079-Pekinese' #北京狮子狗
shitzu_dir = dir+'n02086240-Shih-Tzu' #西施犬
blenheim_spaniel_dir = dir+'n02086646-Blenheim_spaniel' #英国可卡犬
papillon_dir = dir+'n02086910-papillon' #蝴蝶犬
toy_terrier_dir = dir+'n02087046-toy_terrier' #玩具猎狐梗
afghan_hound_dir = dir+'n02088094-Afghan_hound' #阿富汗猎犬
basset_dir = dir+'n02088238-basset' #巴吉度猎犬
将10个子目录中的图像和标签值读入X,y数据集:
import cv2 # 导入Open CV工具箱
X = []
y_label = []
imgsize = 150
# 定义一个函数读入狗狗图片
def training_data(label,data_dir):
print ("正在读入:", data_dir)
for img in os.listdir(data_dir):
path = os.path.join(data_dir,img)
img = cv2.imread(path,cv2.IMREAD_COLOR)
img = cv2.resize(img,(imgsize,imgsize))
X.append(np.array(img))
y_label.append(str(label))
# 读入10个目录中的狗狗图片
training_data('chihuahua',chihuahua_dir)
training_data('japanese_spaniel',japanese_spaniel_dir)
training_data('maltese',maltese_dir)
training_data('pekinese',pekinese_dir)
training_data('shitzu',shitzu_dir)
training_data('blenheim_spaniel',blenheim_spaniel_dir)
training_data('papillon',papillon_dir)
training_data('toy_terrier',toy_terrier_dir)
training_data('afghan_hound',afghan_hound_dir)
training_data('basset',basset_dir)
2.构建X,y张量
构建X,y张量,并将标签从文本转换为one-hot格式的分类编码
X=X/255:相当于手工将图像的像素值进行简单的压缩,也就是将X张量归一化,以利于神经网络处理
from sklearn.preprocessing import LabelEncoder # 导入标签编码工具
from keras.utils.np_utils import to_categorical # 导入One-hot编码工具
label_encoder = LabelEncoder()
y = label_encoder.fit_transform(y_label) # 标签编码
y = to_categorical(y,10) # 将标签转换为One-hot编码
X = np.array(X) # 将X从列表转换为张量数组
X = X/255 # 将X张量归一化
3.拆分数据集
from sklearn.model_selection import train_test_split # 导入拆分工具
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,
random_state=0)
4.构建简单的卷积网络
- Conv2D,2D卷积层,对平面图像进行卷积卷积层参数32,(3,3)中,32是深度,即该层卷积核个数,也就是通道数。(3,3)代表卷积窗口大小。input_shape指定了输入特征图的形状。全部卷积层都通过ReLU函数激活
- MaxPooling2D,最大池化层,一般紧随卷积层出现,通常采用2*2窗口,默认步幅为2,这是将特征图进行2倍采样,也就是高宽特征减半。卷积+池化结构一般需要重复几次,同时逐渐增加特征的深度。
- Flatten,展平层,将卷积操作后的特征图展平后,才输入全连接层进一步处理
- 最后两个Dense,是全连接层。第一个是普通的层,用于计算权重,确定分类,用ReLU函数激活。第二个则只负责输出分类结果,用Softmax激活
网络编译时的超参数:
- ‘categorical_crossentropy’,即分类交叉熵,适用于多元分类,以衡量两个概率分布之间的距离,使之最小化,让输出结果尽可能接近真实值
- 评价指标是准确率acc,即accucary
from keras import layers # 导入所有层
from keras import models # 导入所有模型
cnn = models.Sequential() # 贯序模型
cnn.add(layers.Conv2D(32, (3, 3), activation='relu', # 卷积
input_shape=(150, 150, 3)))
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化
cnn.add(layers.Conv2D(64, (3, 3), activation='relu')) # 卷积
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化
cnn.add(layers.Conv2D(128, (3, 3), activation='relu')) # 卷积
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化
cnn.add(layers.Conv2D(128, (3, 3), activation='relu')) # 卷积
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化
cnn.add(layers.Flatten()) # 展平
cnn.add(layers.Dense(512, activation='relu')) # 全连接
cnn.add(layers.Dense(10, activation='softmax')) # 分类输出
cnn.compile(loss='categorical_crossentropy', # 损失函数
optimizer='RMSprop', # 优化器
metrics=['acc']) # 评估指标
训练网络:
history = cnn.fit(X_train,y_train, # 指定训练集
epochs=50, # 指定轮次
batch_size=256, # 指定批量大小
validation_data=(X_test,y_test)) # 指定验证集
绘制损失曲线与准确率曲线:
# 这段代码参考《Python深度学习》一书中的学习曲线的实现
def show_history(history): # 显示训练过程中的学习曲线
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss) + 1)
plt.figure(figsize=(12,4))
plt.subplot(1, 2, 1)
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
acc = history.history['acc']
val_acc = history.history['val_acc']
plt.subplot(1, 2, 2)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
show_history(history) # 调用这个函数,并将神经网络训练历史数据作为参数输入
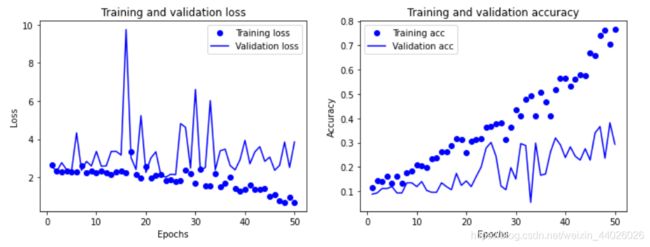
验证集的准确率在20%左右,效果很差。
5.添加dropout层
from keras import optimizers # 导入优化器
cnn = models.Sequential() # 序贯模型
cnn.add(layers.Conv2D(32, (3, 3), activation='relu', # 卷积
input_shape=(150, 150, 3)))
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化
cnn.add(layers.Conv2D(64, (3, 3), activation='relu')) # 卷积
cnn.add(layers.Dropout(0.5)) # Dropout
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化
cnn.add(layers.Conv2D(128, (3, 3), activation='relu')) # 卷积
cnn.add(layers.Dropout(0.5)) # Dropout
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化
cnn.add(layers.Conv2D(256, (3, 3), activation='relu')) # 卷积
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化
cnn.add(layers.Flatten()) # 展平
cnn.add(layers.Dropout(0.5)) # Dropout
cnn.add(layers.Dense(512, activation='relu')) # 全连接
cnn.add(layers.Dense(10, activation='sigmoid')) # 分类输出
cnn.compile(loss='categorical_crossentropy', # 损失函数
optimizer=optimizers.Adam(lr=1e-4), # 更新优化器并设定学习速率
metrics=['acc']) # 评估指标
history = cnn.fit(X_train,y_train, # 指定训练集
epochs=50, # 指定轮次
batch_size=256, # 指定批量大小
validation_data=(X_test,y_test)) # 指定验证集
show_history(history) # 调用这个函数,并将神经网络训练历史数据作为参数输入

6.保存模型
from keras.models import load_model # 导入模型保存工具
cnn.save('../my_dog_cnn.h5') # 创建一个HDF5格式的文件'my_dog_cnn.h5'
del cnn # 删除当前模型
cnn = load_model('../my_dog_cnn.h5') # 重新载入已经保存的模型
二、CNN应用2:Flower recognition
import numpy as np # 导入Numpy
import pandas as pd # 导入Pandas
import os # 导入OS
import matplotlib.pyplot as plt # 导入matplotlib
print(os.listdir('../input/flowers-recognition/flowers'))
# 选择几种花进行分类
daisy_dir='../input/flowers-recognition/flowers/daisy'
sunflower_dir='../input/flowers-recognition/flowers/sunflower'
tulip_dir='../input/flowers-recognition/flowers/tulip'
dandelion_dir='../input/flowers-recognition/flowers/dandelion'
rose_dir='../input/flowers-recognition/flowers/rose'
import cv2 # 导入Open CV工具箱
X = []
y_label = []
imgsize = 150
# 定义一个函数读入花花图片
def training_data(label,data_dir):
print ("正在读入:", data_dir)
for img in os.listdir(data_dir):
path = os.path.join(data_dir,img)
img = cv2.imread(path,cv2.IMREAD_COLOR)
img = cv2.resize(img,(imgsize,imgsize))
X.append(np.array(img))
y_label.append(str(label))
training_data('daisy',daisy_dir)
training_data('sunflower',sunflower_dir)
training_data('tulip',tulip_dir)
training_data('dandelion',dandelion_dir)
training_data('rose',rose_dir)
from sklearn.preprocessing import LabelEncoder # 导入标签编码工具
from keras.utils.np_utils import to_categorical # 导入One-hot编码工具
label_encoder = LabelEncoder()
y = label_encoder.fit_transform(y_label) # 标签编码
y = to_categorical(y,10) # 将标签转换为One-hot编码
X = np.array(X) # 将X从列表转换为张量数组
X = X/255 # 将X张量归一化
分割数据:
from sklearn.model_selection import train_test_split # 导入拆分工具
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,
random_state=0)
构建,训练模型:
from keras import layers # 导入所有层
from keras import models # 导入所有模型
from keras import optimizers # 导入优化器
cnn = models.Sequential() # 序贯模型
cnn.add(layers.Conv2D(32, (3, 3), activation='relu', # 卷积
input_shape=(150, 150, 3)))
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化
cnn.add(layers.Conv2D(64, (3, 3), activation='relu')) # 卷积
cnn.add(layers.Dropout(0.5)) # Dropout
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化
cnn.add(layers.Conv2D(128, (3, 3), activation='relu')) # 卷积
cnn.add(layers.Dropout(0.5)) # Dropout
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化
cnn.add(layers.Conv2D(256, (3, 3), activation='relu')) # 卷积
cnn.add(layers.Dropout(0.5)) # Dropout
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化
cnn.add(layers.Conv2D(512, (3, 3), activation='relu')) # 卷积
cnn.add(layers.MaxPooling2D((2, 2))) # 最大池化
cnn.add(layers.Flatten()) # 展平
cnn.add(layers.Dropout(0.5)) # Dropout
cnn.add(layers.Dense(1024, activation='relu')) # 全连接
cnn.add(layers.Dense(10, activation='sigmoid')) # 分类输出
cnn.compile(loss='categorical_crossentropy', # 损失函数
optimizer=optimizers.Adam(lr=1e-4), # 更新优化器并设定学习速率
metrics=['acc']) # 评估指标
history = cnn.fit(X_train,y_train, # 指定训练集
epochs=50, # 指定轮次
batch_size=256, # 指定批量大小
validation_data=(X_test,y_test)) # 指定验证集
画图方式1:
# 这段代码参考《Python深度学习》一书中的学习曲线的实现
def show_history(history): # 显示训练过程中的学习曲线
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs = range(1, len(loss) + 1)
plt.figure(figsize=(12,4))
plt.subplot(1, 2, 1)
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
acc = history.history['acc']
val_acc = history.history['val_acc']
plt.subplot(1, 2, 2)
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
show_history(history) # 调用这个函数

画图方式2:
#function to get accuracy and loss from history
def get_history_data(history):
train_acc = history.history['acc']
val_acc = history.history['val_acc']
train_loss = history.history['loss']
val_loss = history.history['val_loss']
return train_acc,val_acc,train_loss,val_loss
train_acc,val_acc,train_loss,val_loss = get_history_data(history)
#plot Accuracy graph
epochs = range(len(train_acc))
plt.figure(figsize=(7,7));
plt.plot(epochs,train_acc,label ='Train accuracy');
plt.plot(epochs,val_acc,label ='Validation accuracy');
plt.ylabel('Accuracy')
plt.xlabel('Epochs')
plt.legend();
plt.title('Training Vs Validation Accuracy');

#plot validation graph
plt.figure(figsize=(7,7));
plt.plot(epochs,train_loss,label ='Train Loss');
plt.plot(epochs,val_loss,label ='Validation Loss');
plt.ylabel('Loss')
plt.xlabel('Epochs')
plt.legend();
plt.title('Training Vs Validation Loss');
