【JVM基础】JVM入门基础
目录
-
- JVM的位置
- 三种 JVM
- JVM体系结构
- 类加载器
-
- 双亲委派机制
-
- 概念
- 例子
- 作用
- 沙箱安全机制
-
- 组成沙箱的基本组件
- Native
-
- JNI:Java Native Interface(本地方法接口)
- Native Method Stack(本地方法栈)
- PC寄存器(Program Counter Register)
- 方法区(Method Area)
- 栈(Java Stack)
-
- 栈 + 堆 + 方法区:交互关系
- 堆(Heap)
-
- 新生区 (伊甸园+幸存者区*2)
- 老年区
- 永久区
- 堆内存调优
-
- 报OOM怎么办?
- GC(垃圾回收)
-
- 引用计数法
- 复制算法
- 标记清除
- 标记压缩(标记整理):再优化
- 标记清除压缩:再优化
- 分代收集算法
- 总结
JVM的位置
应用程序(Java应用程序)在JRE上运行(JRE包含JVM),JRE在操作系统(Windows、Mac)上运行,操作系统在硬件体系(Intel、Spac…)上运行。
三种 JVM
- Sun公司:HotSpot 用的最多(我们使用)
- BEA:JRockit
- IBM:J9VM
JVM体系结构
JVM 调优:99%都是在方法区和堆,大部分时间调堆。 JNI(Java Native Interface):本地方法接口


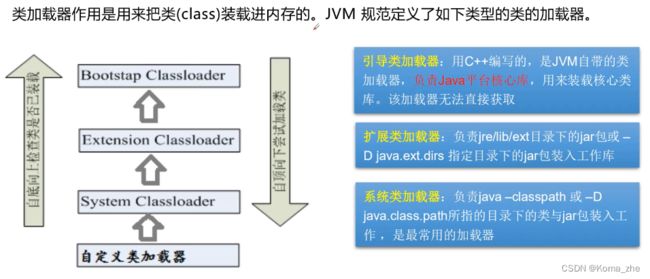
类加载器
作用:加载class文件
例如:new Student();(具体实例在堆里,引用变量名放栈里)
- 虚拟机自带的加载器
- 启动类(根)加载器
- 扩展类加载器
- 应用程序加载器

双亲委派机制
概念
当某个类加载器需要加载某个.class文件时,它首先把这个任务委托给他的上级类加载器,递归这个操作,如果上级的类加载器没有加载,自己才会去加载这个类。
例子
当一个 Hello.class 这样的文件要被加载时。
不考虑我们自定义类加载器,首先会在 AppClassLoader 中检查是否加载过,如果有那就无需再加载了。如果没有,那么会拿到父加载器,然后调用父加载器的 loadClass 方法。
父类中同理也会先检查自己是否已经加载过,如果没有再往上。注意这个类似递归的过程,直到到达 Bootstrap classLoader 之前,都是在检查是否加载过,并不会选择自己去加载。
直到 BootstrapClassLoader,已经没有父加载器了,这时候开始考虑自己是否能加载了,如果自己无法加载,会下沉到子加载器去加载,一直到最底层,如果没有任何加载器能加载,就会抛出ClassNotFoundException。

作用
- 1、防止重复加载同一个.class。通过委托去向上面问一问,加载过了,就不用再加载一遍。保证数据安全。
- 2、保证核心.class不能被篡改。通过委托方式,不会去篡改核心.class,即使篡改也不会去加载,即使加载也不会是同一个.class对象了。不同的加载器加载同一个.class也不是同一个Class对象。这样保证了Class执行安全。
比如:如果有人想替换系统级别的类:String.java。
篡改它的实现,在这种机制下这些系统的类已经被 Bootstrap classLoader 加载过了(为什么?因为当一个类需要加载的时候,最先去尝试加载的就是 BootstrapClassLoader ),所以其他类加载器并没有机会再去加载,从一定程度上防止了危险代码的植入。
沙箱安全机制


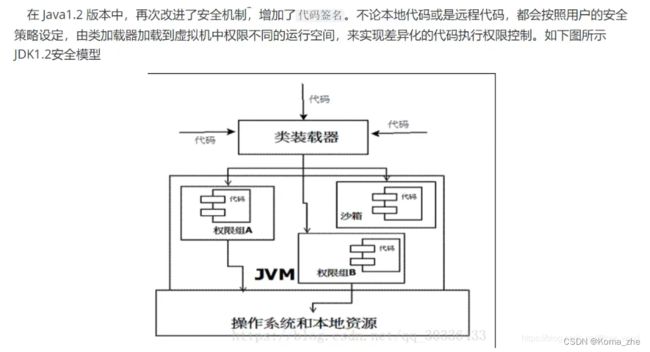

组成沙箱的基本组件
- 字节码校验器(bytecode verifier)
确保 Java 类文件 .Class 遵循 Java 语言规范。这样可以帮助 Java 程序实现内存保护。但并不是所有的类文件都会经过字节码校验,比如核心类。 - 类装载器(class loader)
其中类装载器在3个方面对 Java 沙箱起作用:- 它防止恶意代码去干涉善意的代码; //双亲委派模式
- 它守护了被信任的类库边界;
- 它将代码归入保护域,确定了代码可以进行哪些操作。
虚拟机为不同的类加载器载入的类提供不同的命名空间,命名空间由一系列唯一的名称组成,每一个被装载的类将有一个名字,这个命名空间是由 Java 虚拟机为每一个类装载器维护的,它们互相之间甚至不可见。
类装载器采用的机制是双亲委派模式。
1、从最内层 JVM 自带类加载器开始加载,外层恶意同名类得不到加载从而无法使用;
2、由于严格通过包来区分了访问域,外层恶意的类通过内置代码也无法获得权限访问到内层类,破坏代码就自然无法生效。
- 存取控制器(access controller):存取控制器可以控制核心 API 对操作系统的存取权限,而这个控制的策略设定,可以由用户指定。
- 安全管理器(security manager):是核心 API 和操作系统之间的主要接口。实现权限控制,比存取控制器优先级高。
- 安全软件包(security package):java.security 下的类和扩展包下的类,允许用户为自己的应用增加新的安全特性,包括:
- 安全提供者
- 消息摘要
- 数字签名 keytools https(需要证书)
- 加密
- 鉴别
Native
凡是带了 native 关键字的,说明 Java 的作用范围达不到了,得回去调用底层C语言的库
凡是带了 native 关键字的方法会进入本地方法栈,其它的是 Java栈
JNI:Java Native Interface(本地方法接口)
调用本地方法接口(JNI)作用:
扩展 Java 的使用,融合不同的编程语言为 Java 所用
Java 诞生的初衷是融合C/C++程序,C、C++横行,想要立足,必须要有调用C、C++的程序,它在内存区城中专门开辟了块标记区城: Native Method Stack
Native Method Stack(本地方法栈)
登记 native 方法,在执行引擎(Execution Engine)执行的时候。通过JNI (本地方法接口)加载**本地方法库(Native Libraies)**中的方法。
在企业级应用中少见,与硬件有关应用:Java程序驱动打印机,系统管理生产设备等
PC寄存器(Program Counter Register)
程序计数器: Program Counter Register
每个线程都有一个程序计数器,是线程私有的,就是一个指针, 指向方法区中的方法字节码 ( 用来存储指向下一条指令的地址, 也即将要执行的指令代码 ), 在执行引擎读取下一条指令,是一个非常小的内存空间,几乎可以忽略不计。
方法区(Method Area)
方法区是被所有线程共享,所有字段和方法字节码,以及一些特殊方法,如构造函数,接口代码也在此定义,简单说:所有定义的方法的信息都保存在该区域,此区域属于共享区间;
静态变量、常量、类信息(构造方法、接口定义)、运行时的常量池(如:static,final,,Class(类模板), 常量池)存在方法区中,但是实例变量存在堆内存中,和方法区无关。
栈(Java Stack)
为什么 main() 先执行,最后结束:(因为一开始 main() 先压入栈)
栈:栈内存,主管程序的运行,生命周期和线程同步。
线程结束,栈内存也就释放,对于栈来说,不存在垃圾回收问题。
栈存放:8大基本类型+对象引用+实例的方法。
栈运行原理:栈帧(局部变量表+操作数栈)每调用一个方法都有一个栈帧。
栈满了 main() 无法结束,会抛出错误:栈溢出 StackOverflowError

栈 + 堆 + 方法区:交互关系

堆(Heap)
一个 JVM 只有一个堆内存,堆的大小是可以调节的。
类加载器读取了类文件后,一般会把 类,方法,常量,变量,保存所有引用类型的真实对象放到堆中。
堆内存细分3个区域:
- 新生区(伊甸园区) Young / new
- 养老区 old
- 永久区 Perm ,在JDK8以后,永久存储区改了个名字 (元空间)
GC 垃圾回收,主要是在 伊甸园区 和 养老区。

假设内存满了,报错 OOM:堆内存不够 OutOfMemoryError:Java heap space
//-Xms8m -Xmx8m -XX:+PrintGCDetails
public static void main(String[] args) {
String str = "javajavajavajava";
while (true){
str += str + new Random().nextInt(888888888)+ new Random().nextInt(21_0000_0000);
}
}
//OutOfMemoryError:Java heap space 堆内存满了
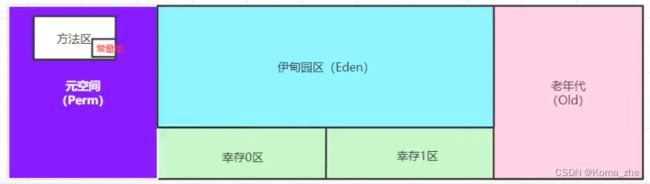
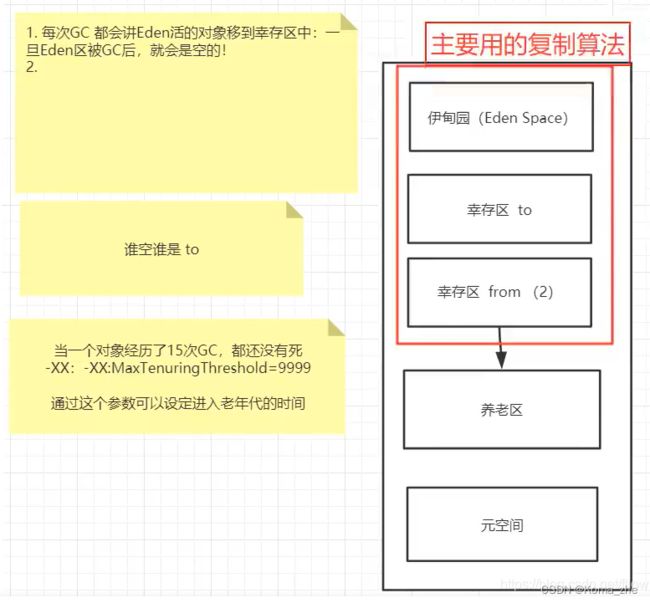
新生区 (伊甸园+幸存者区*2)
- 类诞生和成长甚至死亡的地方
- 伊甸园,所有对象都是在伊甸园区 new 出来的
- 幸存者区(from, to),轻GC定期清理伊甸园,活下来的放入幸存者区,幸存者区满了之后重GC 清理伊甸园+幸存者区,活下来的放入养老区。都满了就报 OOM。
注:经过研究,99%的对象都是临时对象!直接被清理了
老年区
新生区剩下来的,轻GC杀不死了
永久区
这个区域常驻内存,用来存放 JDK 自身携带的 Class 对象,Interface 元数据,存储的是 Java 运行时的一些环境或类信息,该区域不存在垃圾回收GC。关闭虚拟机就会释放这个内存。
- jdk1.6之前:永久代,常量池在方法区。
- jdk1.7:永久代,但是慢慢退化了(去永久代)常量池在堆中。
- jdk1.8之后:无永久代,常量池在元空间。
常量池一直在方法区,其中的字符串池 JDK1.7之后保存到了堆中。
永久区 OOM 例子:一个启动类,加载了大量的第三方jar包。Tomcat 部署了太多的应用,大量动态生成的反射类。不断的被加载。直到内存满,就会出现 OOM。
方法区又称非堆 (non-heap),本质还是堆,只是为了区分概念。
元空间逻辑上存在,物理上并不存在。
堆内存调优
public static void main(String[] args) {
//返回虚拟机试图使用的最大内存
long max = Runtime.getRuntime().maxMemory(); //字节 1024*1024
//返回jvm初始化的总内存
long total = Runtime.getRuntime().totalMemory();
System.out.println("max="+max+"字节\t"+(max/(double)1024/1024+"MB"));
System.out.println("total="+total+"字节\t"+(total/(double)1024/1024+"MB"));
/* 运行后:
max=1866465280字节 1780.0MB
total=126877696字节 121.0MB
*/
//默认情况下,分配的总内存占电脑内存1/4 初始化1/64
}
报OOM怎么办?
-
1.尝试扩大堆内存,如果还报错,说明有死循环代码 或垃圾代码
Edit Configration>add VM option> 输入:-Xms1024m -Xmx1024m -XX:+PrintGCDetails
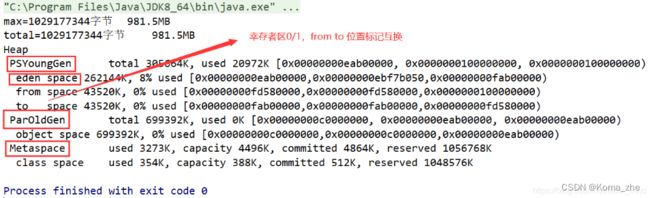
新生区+养老区:305664K+699392K=1005056K = 981.5M ,说明元空间物理并不存在。 -
2.分析内存,看一下哪个地方有问题(专业工具)
能够看到代码第几行出错:内存快照分析工具,MAT,Jprofiler
MAT,Jprofiler作用:- 分析Dump内存文件,快速定位内存泄漏;
- 获得堆中的数据
- 获得大的对象
//-Xms 设置初始化内存分配大小 默认1/64
//-Xmx 设置最大分配内存,默认1/4
//-XX:+PrintGCDetails 打印GC垃圾回收信息
//-XX:+HeapDumpOnOutOfMemoryError //oom DUMP
//-Xms1m -Xmx8m -XX:+HeapDumpOnOutOfMemoryError
public class Demo03 {
byte[] array = new byte[1*1024*1024]; //1m
public static void main(String[] args) {
ArrayList<Demo03> list = new ArrayList<>();
int count = 0;
try {
while (true){
list.add(new Demo03()); //不停地把创建对象放进列表
count = count + 1;
}
} catch (Exception e) {
System.out.println("count: "+count);
e.printStackTrace();
}
}
}

GC(垃圾回收)

JVM在进行GC时,并不是对新生代、幸存区、老年区,这三个区域统一回收。大部分时候回收的是新生代
GC两种:轻GC,重GC (Full GC,全局GC)
引用计数法
一般 JVM 不用,大型项目对象太多了

复制算法
-XX:MaxTenuringThreshold=15 设置进入老年代的存活次数条件。

好处:没有内存的碎片,内存效率高
坏处:浪费了内存空间(一个幸存区永远是空的);假设对象100%存活,复制成本很高。
复制算法最佳使用场景:对象存活度较低的时候,新生区。
标记清除

优点:不需要额外空间,优化了复制算法。
缺点:两次扫描,严重浪费时间,会产生内存碎片。
标记压缩(标记整理):再优化
三部曲:标记–清除–压缩
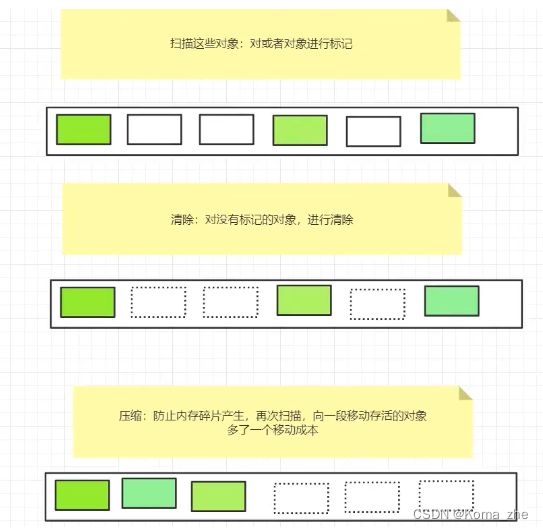
标记清除压缩:再优化
每标记清除几次就压缩一次,或者内存碎片积累到一定程度就压缩。
分代收集算法
根据内存对象的存活周期不同,将内存划分成几块,JVM一般将内存分成新生代和老生代。
在新生代中,有大量对象死去和少量对象存活,所以采用复制算法,只需要付出少量存活对象的复制成本就可以完成收集;
老年代中因为对象的存活率极高,没有额外的空间对他进行分配担保,所以采用标记清理或者标记整理算法进行回收;

总结
内存效率:复制算法 > 标记清除算法 > 标记压缩算法(时间复杂度)
内存整齐度:复制算法 = 标记压缩算法 > 标记清除算法
内存利用率:标记压缩算法 = 标记清除算法 > 复制算法
没有最好的算法,只有合适的算法(GC也被称为分代收集算法)。
- 年轻代:存活率低,用复制算法。
- 老年代:存活率高,区域大,用标记-清除-压缩。