【综述】Pre-train, Prompt and Recommendation: A Comprehensive Survey of Language Modelling Paradigm
论文链接:https://arxiv.org/pdf/2302.03735.pdf
目录
摘要
1. Introduction
2. Generic Architecture of LMRS
3. Data Types
4. LMRS Training Strategies
摘要
预训练模型和学习到的表示有助于一系列下游任务,本文系统调研了如何从不同PLM(Pre-trained Language Models)相关的训练范式学习到的预训练模型中提取和迁移知识,从而提升推荐性能(泛化性、稀疏性、效率和有效性等)。
1. Introduction
目前,数据稀疏性问题成为当前深度推荐模型的一个主要性能瓶颈。而在大规模无监督语料库上训练进行预训练(pre-training),然后在不同的下游监督任务中进行微调(fine-tuning)取得了很好地效果。pre-training&fine-tuning范式的优点是:能够通过无监督任务从无标签数据中提取富含信息和可迁移的知识,这将有助于下游任务,尤其是这些任务的无标签数据缺乏时,从而避免了模型无从训练。
最近提出的prompt learning通过一种简单而灵活的方式进一步统一了在不同任务上PLMs的使用。 prompt learning依赖一系列适当的提示(hard text template/soft continuous embeddings),将下游任务重新定义为预训练任务。这种训练范式的优点有:(1)弥合了预训练和下游目标之间的差距,允许更好地利用预训练模型中丰富的知识,当下游数据非常少时,该优势尤其明显;(2)只需要调整一小部分参数即可,改方法更加高效。
Knowledge transfer via pre-training for recommendation: A review and prospect 总结了一些关于推荐模型预训练的研究,并且讨论了不同领域间的知识迁移方法,但未深入研究预训练推荐模型的训练细节。Self-Supervised Learning for Recommender Systems: A Survey 简要概述了RSs中自监督推荐进展,这意味着用于模型训练的监督信号是由原始数据半自动生成的。本文则不再严格关注自监督训练策略,也探索监督信号和数据增强技术用于pre-training&fine-tuning和prompting中。
2. Generic Architecture of LMRS
LMRS( Language Modelling Paradigm Adaptations for Recommender Systems)通过从预训练模型(PTMs)进行知识迁移来克服数据稀疏性问题。Fig1从data input、pre-training、fine-tuning/prompting和对不同推荐任务的推荐角度给出了 LMRS的高度概述。首先将数据预处理为所需形式(如图、有序序列、对齐的文本-图像对等),然后执行“pre-train, fine-tune”或“pre-train, prompt”,如果inference仅基于预训练模型,那么可将其视为一种端到端的训练方式,但利用了基于LM的学习目标,训练得到的模型可用于推断不同的推荐任务。
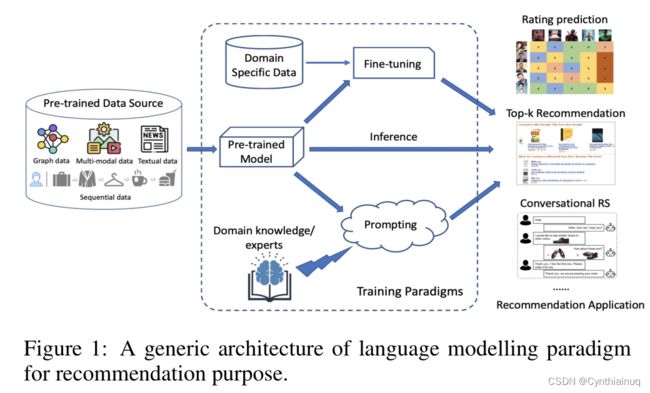
3. Data Types
将输入数据编码为嵌入通常是推荐过程的第一步,推荐系统的输入比大多数NLP任务更加多样化。
因此,编码技术和编码过程可以根据不同的输入类型进行区分。本节将概述几种输入数据类型,然后再深入讨论推荐的训练技术。
- 文本数据
文本数据是推荐中最常用的输入之一,文本数据主要包括:reviews,comments, summaries, news, conversations和codes等。
- 序列数据
本文将按时间顺序或按特定序列排序的用户交互认为序列输入,这种输入通常作为序列推荐或会话推荐的输入。
- 图
在PLMRS训练的不同阶段,图构造和图学习为提升推荐性能产生着不同的作用,其类型通常有:用户-用户社交图、用户-物品交互图、异质知识图谱等。
- 多模态数据
同“图”。
4. LMRS Training Strategies
目前,主要有两类不同的训练模式:pre-train&fine-tune paradigm 和 prompt learning paradigm。根据不同的推荐目的,以上分类又可以进一步分为不同的子类,下图展示了LMRSs的分类及相应的代表性LMRS工作。表1更详尽地展示了一些代表新LMRSs工作。

表1:代表性LMRS方法
| 训练策略 | 论文 | 学习目标 | 推荐任务 | 数据类型 | 开源代码 |
| Pre-training & Fine-tuning | |||||
| Pre-training w/o Fine-tuning | Bert4rec: Sequential recommendation with bidirectional encoder representations from transformer, 2019, CIKM | Pre-train:MLM | Sequential RS | Sequential data | GitHub - FeiSun/BERT4Rec: BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer |
| Path language modeling over knowledge graphsfor ex-plainable recommendation, 2022, WWW | Pre-train: AM | Explainable RS | Graph | N/A | |
| Bridging the gap between nlp andsequential/session-based recommendation, 2021, RecSys | Pre-train: AM + MLM + PLM + RTD | Session-based RS | Textual + Sequential data |
GitHub - NVIDIA-Merlin/Transformers4Rec: Transformers4Rec is a flexible and efficient library for sequential and session-based recommendation and works with PyTorch | |
| Fine-tuning Holistic(整体) Model | Apirecx: Cross-library api recommendation via pre-trained languagemodel, 2021, EMNLP | Pre-train: cross-entropy Fine-tune: cross-entropy |
Cross-library API RS | Textual data(code) | GitHub - yuningkang/APIRecX |
| Recindial: Aunifiedframework for conversational recommendation with pre-trained language models, 2022, AACL-IJCNLP | Pre-train: AM Fine-tune: AM + cross-entropy |
Conversational RS | Textual data + Graph |
GitHub - Lingzhi-WANG/PLM-BasedCRS | |
| Training large-scale news recommenders with pretrained language models in the loop, 2022, KDD | Pre-train: AM + MLM Fine-tune: AM |
News RS | Textual + Sequential data |
GitHub - microsoft/SpeedyRec | |
| Twhin-bert: A socially-enriched pretrained language model for multilingual tweet representations, 2022, arXiv | Pre-train: MLM + NT-Xent Fine-tune: Negative Sampling Loss |
Social RS | Textual data | GitHub - xinyangz/TwHIN-BERT: Code and data release for the paper "TwHIN-BERT: A Socially-Enriched Pre-trained Language Model for Multilingual Tweet Representations" | |
| Curriculum pre-training heterogeneous subgraph transformer for top-n recommendation, 2023, TOIS | Pre-train: MNP + MEP + cross-entropy + Contrastive Loss; Fine-tune: cross-entropy |
Top-N RS | Graph | N/A | |
| Fine-tuning Partial Model | Towards universal sequence representation learning for recommender systems, 2022, TOIS | Pre-train: Contrastive Loss Fine-tune: cross-entropy |
Cross-domain RS Sequential RS |
Textual + Sequential data |
GitHub - RUCAIBox/UniSRec: [KDD'22] Official PyTorch implementation for "Towards Universal Sequence Representation Learning for Recommender Systems" |
| Tiny-newsrec: Effective and efficient plm-based news recommendation, 2022, EMNLP | Pre-train: MLM + AM Fine-tune: cross-entropy + MSE + InfoNCE |
News RS | Textual + Sequential data |
GitHub - yflyl613/Tiny-NewsRec: [EMNLP 2022] Official Pytorch implementation for "Tiny-NewsRec: Efficient and Effective PLM-based News Recommendation" | |
| Mm-rec: Visiolin-guistic model empowered multimodal news recommendation, 2022, SIGIR | Pre-train: MMM + MAP Fine-tune: cross-entropy |
News RS | Sequential + Multi-modal data |
GitHub - zcfinal/MM-Rec: Source codes for paper "MM-Rec: Visiolinguistic Model Empowered Multimodal News Recommendation" | |
| Fine-tuning External Part | S3-rec: Self-supervised learning for sequential recommendation with mutual information maximization, 2020, CIKM | Pre-train: MIM Fine-tune: Pairwise Ranking Loss |
Sequential RS | Textual + Sequential data |
GitHub - RUCAIBox/CIKM2020-S3Rec: Code for CIKM2020 "S3-Rec: Self-Supervised Learning for Sequential Recommendation with Mutual Information Maximization" |
| Boosting deep ctr prediction with a plug-and-play pre-trainer for news recommendation, 2022, COLING | Pre-train: MTP + cross-entropy Fine-tune: cross-entropy |
News RS | News RS | GitHub - Jyonn/PREC: COLING 2022 oral paper | |
| Pre-training of graph augmented transformers for medication recommendation, 2019, IJCAI | Pre-train: binary cross-entropy Fine-tune: cross-entropy |
Medication RS | Graph | GitHub - jshang123/G-Bert: Pre-training of Graph Augmented Transformers for Medication Recommendation | |
| Graph neural pre-training for recommendation with side information, 2022, TOIS | Pre-train: binary cross-entropy Fine-tune: BPR + binary cross-entropy |
Top-N RS | Textual data + Graph |
GitHub - pretrain/pretrain | |
| Prompting | |||||
| Fixed-PTM Prompt Tuning | Towards unified conversational recommender systems via knowledge-enhanced prompt learning, 2022, KDD | Pre-train: AM + MLM + cross-entropy Prompt-tuning: AM + cross-entropy |
Conversational RS | Textual data | GitHub - RUCAIBox/UniCRS: [KDD22] Official PyTorch implementation for "Towards Unified Conversational Recommender Systems via Knowledge-Enhanced Prompt Learning" |
| Personalized prompts for sequential recommendation, 2022, arXiv | Pre-train: Pairwise Ranking Loss Prompt-tuning: Pairwise Ranking Loss + Contrastive Loss |
Cross-domain RS Sequential RS |
Textual + Sequential data |
N/A | |
| Fixed-prompt PTM Tuning | Improving conversational recom-mendation systems’ quality with context-aware item meta-information, 2022, Findings of NAACL | Pre-train: AM + MLM PTM Fine-tune: AM + cross-entropy |
Conversational RS | Textual data | |
| A unified multi-task learning framework for multi-goal conver-sational recommender systems, 2022, TOIS | Pre-train: AM; PTM Fine-tune: AM | Conversational RS | Textual data | GitHub - dengyang17/UniMIND | |
| Tuning-free Prompting | Zero-shot recommendation as language modeling, 2022, ECIR | Pre-train: AM | Zero-Shot RS | Textual data | https://shorturl.at/glmqA |
| Recommendation as language processing (rlp): A unified pretrain, personalizedprompt & predict paradigm (p5), 2022, RecSys | Pre-train: AM | Zero-Shot RS Cross-domain RS |
Zero-Shot RS Cross-domain RS |
GitHub - jeykigung/P5 | |
| Prompt+PTM Tuning | Personalized prompt learning for explainable recommendation, 2023, TOIS | Pre-train: AM; Prompt-tuning: NLL Prompt+PTM tuning: NLL + MSE |
Explainable RS | Textual data | GitHub - lileipisces/PEPLER: Personalized Prompt Learning for Explainable Recommendation |
| Rethinking reinforcement learning for recommendation: A prompt perspective, 2022, SIGIR | Prompt+PTM tuning: cross-entropy | Next Item RS | Sequential data | N/A | |
| 注:MLM(Masked Language Modelling);AM(Auto-regressive Modelling);RTD (Replaced Token Detection替换令牌检测);NT-Xent (Normalized Temperature-scaled Cross Entropy Loss);MNP (Masked Node Prediction);MEP (Masked Edge prediction); MMM (Masked Multi-modal Modelling);MAP (Multi-modal Alignment Prediction); MIM (Mutual Information Maximization Loss); MTP (Masked News/User Token Prediction); NLL (Negative Log-likelihood Loss) | |||||
4.1 Pre-train, fine-tune paradigm
“Pre-train, fine-tune”模式的优点:(1) 预训练能提供好的初始化模型,会对不同的下游推荐任务产生更好的泛化性,从而从各个角度提升推荐性能,并提升微调阶段的收敛速度;(2)在大型源语料库上进行预训练可以学习通用知识,从而有利于下游推荐者;(3)预训练可被视作一种正则化以避免在低资源、小数据集上过拟合。
- Pre-train
这种训练策略可以看作是传统端到端训练,不同的是,我们仅关注基于语言模型的学习目标应用到训练阶段。许多经典的LM-based推荐模型都属于这一类,比如:BERT4Rec使用双向自注意力网络建模序列用户行为;Transformers4Rec则采用基于huggingface transformer架构作为预测下一个物品的基础模型,并且进一步探索了因果LM、MLM、排列LM和替换令牌检测四种不同的LM训练任务。这两种方法为LM-based推荐奠定了基础。
- Pre-train, fine-tune holistic(整体) model
模型经过预训练,并使用不同的数据源进行微调,微调对整个模型参数进行调整。APIRecX采用分段的源API代码预训练GPT模型,然后利用来自另一个库的API代码片段对预训练的GPT模型进行微调,已实现跨库推荐。RecInDial使用领域特定的数据集微调预训练会话推荐模型DialoGPT,以此注入DBpedia中的知识以提高推荐性能。SpeedyFeed对PTM进行微调,使其与用户嵌入部分一起学习新闻嵌入,以自回归的方式进行新闻推荐。他们也探索了不同的微调策略,比如调整PTM的一部分、调整PTM的最后一层,但根据经验,通常微调整个模型会使模型性能更好,这让我们对平衡推荐精度和训练效率有了更深入的了解。
- Pre-train, fine-tune partial model
因为微调整个模型通常非常耗时且灵活性差,许多LMRSs选择对模型部分参数进行微调,已实现训练开销和推荐性能之间的平衡(UniSRec,Tiny-newsrec,Mm-rec)。例如,为了解决BERT为general texts引入非平滑各向异性语义空间,导 致来自不同领域项目的文本存在很大的语言差距的问题,UniSRec应用线性转换层对来自不同领域项目的BERT表示进行转换,然后采用自适应组合策略推导出通用项目表示来处理领域偏差问题。同时,考虑从多个领域特定的行为模式中学习可能会出现一种冲突的“跷跷板”现象,他们提出了序列-物品、序列-序列对比任务,以在预训练阶段进行多任务学习。他们发现,只要对模型参数的一小部分进行微调,就可以快速地使模型适应冷启动或新项目的未知领域。
- Pre-train, fine-tune extra part of the model
随着PTMs深度的增加,他们捕获的表示使得下游推荐任务更加容易。除了上面提到的两种微调策略,还有一些方法利用PTMs之外的任务特定层来进行推荐任务,通过优化特定任务层的参数,微调几乎不涉及PTMs的其他部分。G-BERT首先预训练了GPT和BERT模型来学习访问患者历史记录的嵌入,然后将其作为输入对额外的预测层进行微调,以进行药物推荐。另一种方式是在微调阶段使用PTM初始化一个有相似架构的新模型,并使用调优后的模型进行推荐。S3-Rec首先以自监督的方式在四个不同的学习目标上(关联属性预测、遮盖物品预测、遮盖属性预测和段预测)预训练一个双向transformer-based模型,以学习物品嵌入。然后,利用学习到的模型参数初始化一个单向transformer-based模型,使用pairwise rank loss进行微调。
4.2 Prompting paradigm
与其通过设计特定的目标函数使PLMs适应不同的下游推荐任务,“pre-train, prompt and inference” 通过hard/soft prompt 重新定义下游推荐任务,这一趋势逐渐开始取代“pre-train, fine-tune and inference” 并成为多个推荐任务的重要训练范式。该范式中,可以通过特定与领域的训练目标来避免微调。预训练的模型本身可以直接用于预测下一个物品,产生推荐解释、进行对话、在编码时为程序员推荐相似的数学问题或库、甚至输出与推荐目标相关的子任务(如解释【Personalized Prompt Learning for Explainable Recommendation】)
prompt learning打破了数据约束的问题,弥补了预训练和微调之间客观形式的差距。prompts可以分为hard/discrete prompts或soft continuous prompts,前者通常使用人工设计的人类可读的文本模板,而后者由几个连续可学习的嵌入组成。
- Fixed-PTM prompt tuning
提示调优只需要为提示和标签参数调优一小部分参数,这对few-shot推荐任务非常有效。尽管在不显著改变PTM结构和参数的情况下构建提示信息可以获得很好的结果,但也需要选择合适的prompt template和verbalizer(语言器),这可能会极大地影响推荐性能。prompt tuning可以是更易读的离散文本模板(BERT for CR),也可以是软连续向量(UniCRS、PPR),例如,BERT for CR手动设计了几个提示模板,在预先训练的BERT模型上测试电影/书籍推荐的性能。PPR则提出了一种个性化提示生成器,用于生成软提示作为用户行为序列之前的前缀,用于序列推荐。
- Fixed-prompt PTM tuning
固定提示PTM调优对PTMs的参数进行调优,类似于“pre-train, fine-tune”策略,但会额外使用带有固定参数的prompts来指导推荐任务。提示可以是一个或多个tokens,指示不同的任务,包括推荐UniMIND从不同的统一目标,如闲聊、对话推荐和问答,到相同的sequence-to-sequence模型,并设计了提示令牌以无缝地从各种问题转移/引导对话。该模型采用多任务学习模式进行训练,并在相同的目标下进行参数优化。MESE设计了一个[REC]令牌作为提示,以指示推荐过程的开始,并总结对话推荐的对话上下文。
- Tuning-free prompting
这种训练策略可以被称为zero-shot推荐,可以在不改变PTMs的参数的情况下,只基于输入提示直接生成推荐任务或相关子任务结果。一些研究工作已经验证了zero-shot推荐在单域或跨域场景中处理新用户/物品的能力(zero-shot RS、RLP)。其中,RLP在预训练中使用相同的负对数似然(Negative Log-likelihood, NLL)训练,统一学习了多项任务(如顺序推荐、评分预测、解释生成、综述总结和直接推荐等)。在推理阶段,将一系列精心设计的离散文本模板提示作为输入,包括询问新领域中推荐物品(未出现在预训练阶段),经过训练的模型输出较好的结果,无需进行微调。zero-shot推荐之所以具有这种能力,是因为训练数据和预训练任务能够从不同的模式中提炼出丰富的语义和相关性知识,并将其转化为能够理解用户偏好行为的用户和物品tokens
- Prompt+PTM tuning
在这个类别中,参数包括两部分:prompt-relevant参数和模型参数,微调阶段通过优化特定推荐任务的所有参数来执行。与“pre-train,fine-tune the holistic model”不同,Prompt+PTM tuning能够在模型训练开始时提供额外的bootstrapping(引导)。比如,PPL提出了一种连续提示学习方法,首先固定PTM,微调prompt以弥合连续提示与加载PTM之间的差距,然后对prompt和PTM进行微调,从而获得更高的BLUE分数。他们结合discrete prompts(三个用户、物品特征关键词,如健身房、早餐和WiFi)和 soft prompts(用户、物品嵌入)来生成推荐解释。研究表明,所提出的prompts在生成解释的可读性和流畅性方面得到了改进。注意,Prompt+PTM tuning阶段并不一定是指微调阶段,可以是针对特定数据输入从双方调优参数的任何可能的阶段。PRL通过学习奖励状态对作为soft prompts来编码训练期间观察到的动作,将强化学习框架作为Prompt+PTM tuning策略。在推理阶段,经过训练的prompt生成器可以直接为推荐模型生成软提示嵌入,以生成动作(物品)。
尽管“pre-train, fine-tune”和“pre-train, prompt”训练策略在推荐领域已经取得了一些进步,但研究仍处于起步阶段,在同一平台上比较不同训练策略在推荐任务上的表现还需要做更多的工作。
待续......