数据结构之哈希算法
1:什么是哈希算法?
将一个任意长度的二进制串映射为固定长度的二进制串的算法,我们叫做是哈希算法,其中固定长度的二进制串结果叫做哈希值。
比如md5算法就是一种哈希算法,md5算法将任意长度的二进制串映射为长度128bit的二进制串。
2:一个合格的哈希算法需要满足哪些条件?
1:哈希冲突概率极低
2:差别很小的原始串哈希的结果差别也要很大
3:哈希计算速度快(如md5算法加密4000个字左右的汉字只需要1ms左右)
4:无法反向从哈希值推到出原始值
3:哈希算法都有哪些应用?
A:加密(密码存储)
B:唯一标示(数据库主键,文件存储)
C:数据校验(接口请求数据有效性)
D:散列函数(散列表生成散列值)
E:负载均衡
F:数据分片
G:分布式存储
4:为什么哈希算法无法做到无冲突?
借鉴鸽巢原理(抽屉原理),假设有10个鸽巢,11只鸽子,每个鸽子下一个鸽子蛋,则至少有一个鸽巢鸽子蛋的数量不少于2,在1:什么是哈希算法?部分我们分析了哈希算法的定义,从中可以看出哈希值是一个定长的结果,因此哈希值结果个数必定存在上限,比如md5算法,哈希值长度为128bit,也就是哈希值一共有2^128次方个可能的值,则根据鸽巢原理,当有2^128+1个原始串时,必定会出现冲突,但是出现冲突的概率极低。
5:哈希算法在分布式的应用实例
为了提高系统的查询性能,我们现在需要构建一个分布式的缓存系统,前端系统通过分布式缓存系统来获取数据,可以达到减少数据库查询的目的,架构如下图:
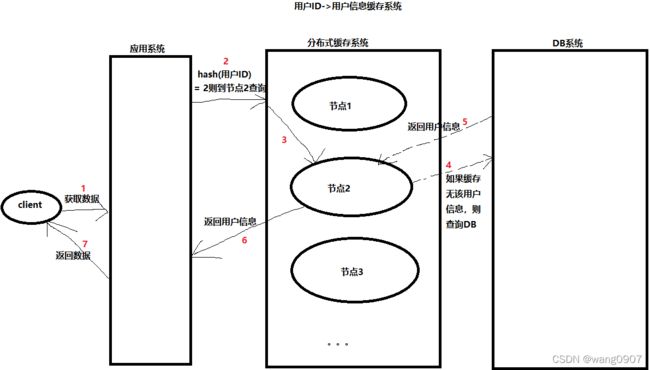
这样子,一个简单的分布式缓存系统就构建完毕了,注意图中的步骤2,假设我们使用的是md5算法执行哈希,则可能的代码如下:
class FakeCls {
int hash(String userId) {
// 分布式缓存系统中一共有10个节点
int cacheSystemNodeNum = 10;
return Md5(userId) % cacheSystemNodeNum;
}
}
需要注意,哈希值的计算严重依赖于了分布式缓存系统中节点的个数,当节点个数发生变更时,该函数的结果必定发生比较大的变化,从而造成将请求分配到了无对应缓存数据的节点,此时大量的请求都会打到DB,从而造成缓存雪崩的发生。
延伸知识:缓存雪崩,缓存击穿,缓存穿透。
缓存雪崩:当突然大规模的出现无法从缓存中获取数据的情况时,请求全部打到了DB,从而造成DB的宕机,这是缓存雪崩。
缓存击穿:当某个热点key失效,导致获取该热点key的请求打到DB,这是缓存击穿。
缓存穿透:当查询的key在缓存中不可能存在,此时一定会将请求打到DB,这是缓存穿透。
想要解决这个问题就不能使用普通的哈希函数,而需要考虑使用一致性哈希了,关于一致性哈希具体参考6:一致性哈希,使用一致性hash后,步骤2的伪代码如下:
class FakeCls {
int hash(String userId) {
return someConsistencyHash(userId);
}
}
这样,当节点发生变更,影响的也只是部分键哈希的结果,不会造成特别严重的后果,经过一段时间的自动预热(即将缓存中不存在key查询之后放到缓存中)之后,就能恢复正常了。
6:一致性哈希
一致性哈希依赖于哈希环,哈希环是一个具有一定范围的环,机器节点和数据都会被映射到环上的某个位置,如下是一个范围是[1,10000]的环:

比如我们现在有三个节点,哈希值分别如下:
节点1:508
节点2:6010
节点3:2056
则我们将这三个节点映射到哈希环上之后,如下图:

接下来数据查找过程是这样子的,首先经过哈希函数获取[1,10000]内的一个数字,按照如下两种情况处理:
1:如果是当前哈希值对应的位置恰好有映射的节点,则使用该节点查询数据
2:如果是当前哈希值没有映射的节点,则顺时针旋转,使用第一个遇到的节点,作为目标节点来查询数据
比如我们现在要查询用户ID=20201303-1对应的用户信息,假设hash(20201303-1)=5632,则会使用节点2,来作为目标节点查找数据,这个过程如下图:

但是此时还是有一个问题,那就是,节点映射是失衡的,如下的映射关系:
[509,2056]映射到node3,可映射的哈希值个数为1548。
[2057,6010]映射到node2,可映射哈希值个数为3954。
[6011,10000],[1,508]映射到node1,可映射的哈希值个数是4498。
则映射到各个节点的比例为node1:node2:node3=4498:3954:1548,可以看到这个比例并不是接近1:1:1的,为了解决这个问题,我们可以将这3个节点都克隆若干份,然后再映射到哈希环上,这个克隆的副本我们叫做是虚拟机节点,增加虚拟节点后哈希环可能如下:

这样子就能解决映射不均匀的问题了。回过头看,在5:哈希算法在分布式的应用实例我们提到可以使用一致性哈希来解决机器节点个数发生改变导致的雪崩问题,这是为什么呢?接上图,假设我们现在增加了节点4,哈希环变为下图:

此时受影响的哈希范围是[2057,2789],原来是映射到node1,现在映射到node4,[6529,7923]原来映射到node3,现在映射到node4,可以看到影响的范围还是比较小的,基于此来解决缓存雪崩问题。
以上使用虚拟节点的算法其实是
ketama一致性哈希算法。