零售商品销售预测
调整 代码下载的C币已设置为 0 (以前误设置)
研究、设计内容:
在电子商务业务蓬勃发展的同时,零售业遭遇了寒潮。电子商务的冲击、瞬息万变的经济环境、难以捉摸的销售情况和日益冷清的大型卖场,都给零售业带来了重重困难。
进入数字时代后,数据的有效使用成为零售企业颠覆传统的动力,也势必将改变零售业的格局。沃尔玛等大型零售商都积极第将数据分析与商业结合,创造了额外的经济收益。
某大型零售商的数据科学家收集了不同城市10家商店1539种商品在2013年的销售数据,还定义了每个产品和商店的某些属性。本课题将的目的是建立一个销售预测模型,使得公司可以预测每个产品在特定商店的销售情况,从而可以提前调整物流、完善备货渠道,以较高的效率完成销售流程。在此模型的基础上,分析在增加销售额中起到关键作用的商品和商店的属性,从而对商店和所售商品进行优化,以期增加公司整体销售额。
需要熟练掌握Python语言或其他编程语言,熟悉机器学习算法。结果需要可视化展示。
提交:代码、数据、课题报告
环境配置
python3
python 库
matplotlib
numpy
pandas
scikit-learn
xgboost
seaborn
可以使用命令安装 一键安装
pip install scikit-learn matplotlib numpy pandas xgboost seaborn
Code
目录结构

为了便于同学们理解编码思路和过程,代码中进行了详细的注释,一定要看着注释进行理解~
代码下载
代码下载 https://download.csdn.net/download/q506610466/19987298?spm=1001.2014.3001.5503
运行时,先运行 data.py 进行数据处理,随后再运行 ML_model.py
数据清洗
data.py
# -*- encoding: utf-8 -*-
# @File: data.py
# @mail: [email protected]
# @Author: LiuYu
"""
数据清洗模块
"""
import pandas as pd
import warnings
from sklearn.preprocessing import LabelEncoder
warnings.filterwarnings("ignore")
def load_data():
# 读取数据
train_df = pd.read_csv("./data/train.csv")
test_df = pd.read_csv("./data/test.csv")
print('train.csv ', train_df.shape)
print("test.csv", test_df.shape)
# Y = train_df["Item_Outlet_Sales"]
# 排除 ["Item_Outlet_Sales"]这一列
# X = train_df.drop(["Item_Outlet_Sales"], axis=1)
X = train_df
print("原始样本数:", X.shape[0])
# TODO 查看存在 NAN的特征 可知 Item_Weight:商品重量 Outlet_Size:商店营业面积 存在缺失值
print(X.isnull().any())
# ------------------------修正或删除异常数据 start---------------------
# 排除 Outlet_Size 因为存在大量的空值 影响 模型训练
X = X.drop(["Outlet_Size"], axis=1)
# 用平均值填充 Nan
X["Item_Weight"] = X["Item_Weight"].fillna(X["Item_Weight"].mean())
print("-" * 100)
print("用平均值填充后:")
print(X.isnull().any())
print("-" * 100)
total = X.isnull().sum().sort_values(ascending=False)
percent = (X.isnull().sum() / X.isnull().count()).sort_values(ascending=False)
Missing_Value = pd.concat([total, percent], axis=1, keys=["Total", "Percent"])
print("缺失值所占比例:")
print(Missing_Value)
# X_noNan = X.drop(["Item_Weight"], axis=1)
# print(X_noNan.shape)
# 删除缺失值
X.dropna(inplace=True)
# 输出中间 数据
# X.to_csv("data01.csv")
print("删除缺失值后的样本数:", X.shape[0])
# 修正异常值 0 把Item_Visibility 特征中大量的0 修正为 平均数
visibility_avg = X.pivot_table(values='Item_Visibility', index='Item_Identifier')
miss_bool = (X['Item_Visibility'] == 0)
print('Number of 0 values initially: %d' % sum(miss_bool))
X.loc[miss_bool, 'Item_Visibility'] = X.loc[miss_bool, 'Item_Identifier'].apply(lambda x: visibility_avg.loc[x])
# ------------------------修正或删除异常数据 end---------------------
# TODO 对非数字型属性 进行 转化
# Item_Fat_Content 1 Item_Type 1 Outlet_Identifier 1
# Item_Identifier 1 Outlet_Location_Type 1 Outlet_Type 1
# TODO 数据中的类型变量一般为字符串的形式, 这不利于特征之间关系的计算, 因此将字符串转化为数值
print("-" * 100)
# LabelEncoder可以将字符串形式 变为 1 2 3 4 .... 类似的数字 格式
le = LabelEncoder()
X['Outlet_Identifier'] = le.fit_transform(X['Outlet_Identifier'])
var_mod = ['Item_Fat_Content', 'Outlet_Location_Type', 'Outlet_Type', "Item_Type", "Item_Identifier"]
le = LabelEncoder()
for i in var_mod:
X[i] = le.fit_transform(X[i])
# One Hot Coding:
# X = pd.get_dummies(X, columns=['Item_Fat_Content', 'Outlet_Location_Type', 'Outlet_Type', 'Outlet', "Item_Type",
# "Item_Identifier"])
X.to_csv('./data/data01.csv', sep=",", index=False)
print("数据处理完成,其维度为", X.shape)
return X
if __name__ == '__main__':
load_data()
模型构建
ML_model.py
# -*- encoding: utf-8 -*-
# @File: model.py
# @mail: [email protected]
# @Author: LiuYu
from data import load_data
from sklearn.linear_model import LinearRegression, SGDRegressor, Ridge
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from xgboost import XGBRegressor
import pandas as pd
from sklearn import metrics
import numpy as np
# 画图工具
import matplotlib.pyplot as plt
import seaborn as sns
"""
机器学习模型---回归
"""
def mae(y_true, y_pred):
"""平均绝对误差"""
return np.mean(abs(y_true - y_pred))
# TODO 1. 读取数据
# data_df = load_data()
data_df = pd.read_csv("data/data01.csv")
print(data_df.head())
# TODO 2. 划分 训练 X 和 标签 Y
Y = data_df["Item_Outlet_Sales"]
# 排除特征Item_Outlet_Sales
X = data_df.drop(["Item_Outlet_Sales"], axis=1)
# TODO 3. 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(X, Y, random_state=2021)
# TODO 4. 标准化
# 标准化可以使数据 区间变得 规整 有利于计算
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# TODO 5. 创建预估器
# 预估计就是我们所说的模型 这里我们尝试了几种 发现XGBRegressor效果最好 就注释掉其他的
# estimator = SGDRegressor(learning_rate="constant", eta0=0.01, max_iter=100000, penalty="l1")
# estimator = Ridge()
estimator = XGBRegressor(learning_rate=0.03, reg_lambda=1e-3)
# estimator = LinearRegression()
estimator.fit(x_train, y_train)
# TODO 6. 模型评估
y_predict = estimator.predict(x_test)
print("预测销售额:\n", y_predict)
error = mae(y_test, y_predict)
print("平均绝对误差为:\n", error)
print("均方根误差 : %.4g" % np.sqrt(metrics.mean_squared_error(y_test, y_predict)))
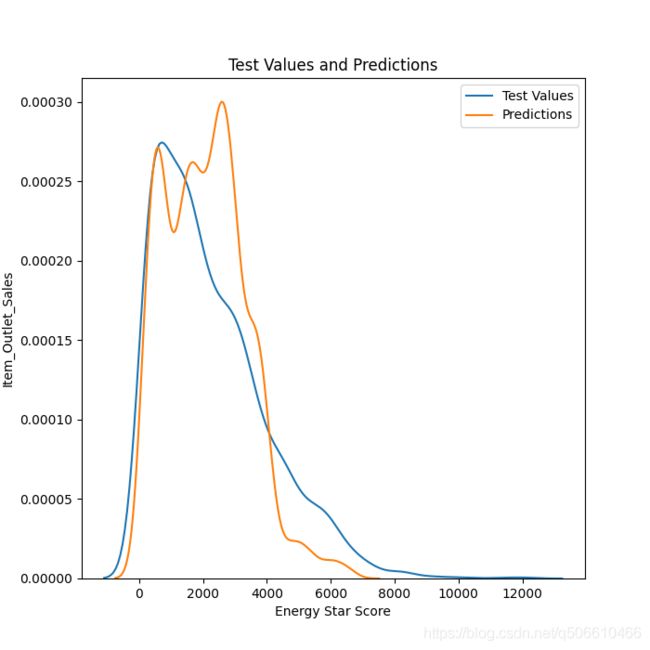
# TODO 7. 预测和真实之间的差异图
# Density plot of the final predictions and the test values
plt.figure(figsize=(7, 7))
sns.kdeplot(y_test, label="Test Values")
sns.kdeplot(y_predict, label='Predictions')
plt.legend(loc='best')
# Label the plot
plt.xlabel('Energy Star Score')
plt.ylabel('Item_Outlet_Sales')
plt.title('Test Values and Predictions')
plt.savefig("预测和真实之间的差异图.png")
# TODO 8.特征重要性挑选
plt.figure(figsize=(7, 7))
importances = pd.Series(estimator.feature_importances_, index=X.columns).sort_values(ascending=True)
importances.plot(kind='barh', figsize=(10, 6))
plt.savefig("特征重要性.png")
可视化评估

望各位老板
关注 点赞 收藏
分享给需要的人。