5.从头跑一个pipeline
1.安装torch
pip install torchvision torchPyTorch的torchvision.models模块中自带的很多预定义模型。torchvision 是PyTorch的一个官方库,专门用于处理计算机视觉任务。在这个库中,可以找到许多常用的卷积神经网络模型,包括ResNet、VGG、AlexNet等,以及它们的不同变体,如resnet50、vgg16等
2.准备模型
1.导出resnet50模型
import torch
import torchvision.models as models
resnet50 = models.resnet50(pretrained=True)
resnet50.eval()
image = torch.randn(1, 3, 244, 244)
resnet50_traced = torch.jit.trace(resnet50, image)
resnet50(image)
resnet50_traced.save('model.pt')
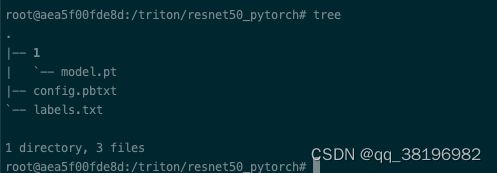
创建resnet50_pytorch目录,目录下创建目录1(1表示版本号),然后将model.pt模型放到resnet50_pytorch/1目录下
执行该Python文件的时候会从https://download.pytorch.org/models/resnet50-0676ba61.pth下载模型文件,保存到本地的.cache/torch/hub/checkoutpoints
如我是在容器中执行的,保存路径为/root/.cache/torch/hub/checkpoints/resnet50-0676ba61.pth
2.准备模型配置
name: "resnet50_pytorch"
platform: "pytorch_libtorch"
max_batch_size: 128
input [
{
name: "INPUT__0"
data_type: TYPE_FP32
dims: [ 3, -1, -1 ]
}
]
output [
{
name: "OUTPUT__0"
data_type: TYPE_FP32
dims: [ 1000 ]
label_filename: "labels.txt"
}
]
instance_group [
{
count: 1
kind: KIND_GPU
}
]
此时目录结构为

模型目录的名称必须与config.pbtxt中指定的模型名称完全匹配。这是为了确保 Triton 能够正确地识别和加载模型
3.加载模型
此时已经可以通过triton加载模型,需要注意的model-repository指出resnet50_pytorch的上一级目录即可(否则会报错),Triton会加载model-repo路径下的所有模型
/opt/tritonserver/bin/tritonserver --model-repository=/triton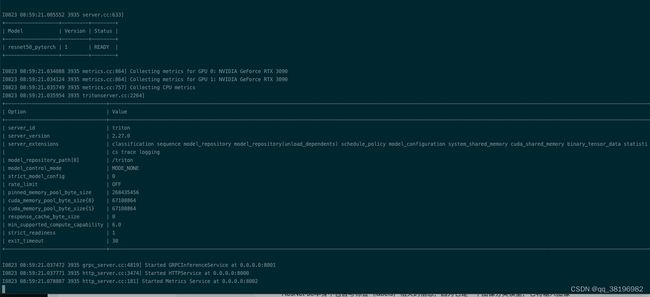
4.发送请求
想要获取分类的结果,可以设置 class_count=k,表示获取 TopK 分类预测结果。如果没有设置这个选项,那么将会得到一个 1000 维的向量。
import numpy as np
import tritonclient.http as httpclient
import torch
from PIL import Image
if __name__ == '__main__':
#1.创建triton client
triton_client = httpclient.InferenceServerClient(url='127.0.0.1:8000')
#2.加载图片
image = Image.open('/test_triton/24poJOgl7m_small.jpg')
#3.对图片进行预处理,以满足resnet50的input要求
image = image.resize((224, 224), Image.ANTIALIAS)
image = np.asarray(image)
image = image / 255
image = np.expand_dims(image, axis=0)
image = np.transpose(image, axes=[0, 3, 1, 2])
image = image.astype(np.float32)
#4.创建inputs
inputs = []
inputs.append(httpclient.InferInput('INPUT__0', image.shape, "FP32"))
inputs[0].set_data_from_numpy(image, binary_data=False)
#5.创建outputs
outputs = []
outputs.append(httpclient.InferRequestedOutput('OUTPUT__0', binary_data=False, class_count=1))
#6.向triton server发送请求
results = triton_client.infer('resnet50_pytorch', inputs=inputs, outputs=outputs)
output_data0 = results.as_numpy('OUTPUT__0')
print(output_data0.shape)
print(output_data0)AttributeError: module 'PIL.Image' has no attribute 'ANTIALIAS'
则降低PIL版本
pip uninstall Pillow
pip install Pillow==9.5.0结果如下:
test_triton.py:12: DeprecationWarning: ANTIALIAS is deprecated and will be removed in Pillow 10 (2023-07-01). Use LANCZOS or Resampling.LANCZOS instead.
image = image.resize((224, 224), Image.ANTIALIAS)
(1, 1)
[['10.245845:283']]输出的几个数字的含义如下:
-
(1, 1):这是输出数据的形状。这个元组表示输出数据的维度,第一个数字表示批处理大小(batch size),第二个数字表示每个样本的输出数目。在这个结果中,批处理大小是1,每个样本有1个输出。 -
['10.245845:283']:这是模型的输出值。它是一个字符串数组,通常包含了一个或多个浮点数值,以字符串形式表示。在这个结果中,字符串'10.245845:283'可以分为两部分:10.245845:这是模型对输入图像的分类概率得分。它表示模型认为输入图像属于某个特定类别的概率得分。通常,这个值越高,模型越确信输入图像属于这个类别。283:这通常是与类别标签相关的索引或标识符。这个索引可以用来查找与模型输出的概率得分对应的类别名称。具体来说,索引283对应于 ImageNet 数据集中的一个类别。您可以使用相应的labels.txt文件来查找该索引对应的类别名称。
5.准备标签
在第4步无论是使用class_count与否,都没有直接返回分类结果。这是因为ResNet-50本身不包含与标签(labels)相关的信息,因为它是一个图像分类模型,它将输入图像分为一组预定义的类别,但它并不知道这些类别的名称。标签信息通常是根据您的具体任务和数据集来定义的。
不同的labels.txt会导致最终的分类结果不一样
wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt下载之后重命名为labels.txt,
将config.pbtxt的内容改为如下:
name: "resnet50_pytorch"
platform: "pytorch_libtorch"
max_batch_size: 128
input [
{
name: "INPUT__0"
data_type: TYPE_FP32
dims: [ 3, -1, -1 ]
}
]
output [
{
name: "OUTPUT__0"
data_type: TYPE_FP32
dims: [ 1000 ]
label_filename: "labels.txt"
}
]
instance_group [
{
count: 1
kind: KIND_GPU
}
]重新启动服务,重新发送请求,结果为
(1, 1)
[['10.245845:283:Persian cat']]查询labels.txt,283对应的类别是Persian cat(索引从0开始)
3.使用ensemble
第2部分的client.py里可以看到进行了数据处理,现在我们专门使用一个模型来进行数据处理
首先创建resnet50_ensemble目录,并把resnet50_pytorch拷贝到resnet50_ensemble目录下
1.python script model
使用Python Script Model来完成image的数据处理,以符合input需求(正式叫法是前处理),该类型的model通过python backend来进行execute。编写Python script model,需要实现如下接口供triton server调用
-
initialize:加载model config;创建image预处理所需要的对象 -
execute:有两种模式:-
Default model:execute输入为batch request,返回的结果也应该是相同order和number的batch response
-
Decoupled model:这里对返回的order和number都没有限制,主要应用在Automated Speech Recognition (ASR)
-
-
finalize:是可选的。该函数允许在从Triton服务器卸载模型之前进行任何必要的清理。
看不懂不要紧,先跑就行
创建一个model.py文件,内容如下
import numpy as np
import sys
import json
import io
import triton_python_backend_utils as pb_utils
from PIL import Image
import torchvision.transforms as transforms
import os
class TritonPythonModel:
def initialize(self, args):
# You must parse model_config. JSON string is not parsed here
self.model_config = model_config = json.loads(args['model_config'])
# Get OUTPUT0 configuration
output0_config = pb_utils.get_output_config_by_name(
model_config, "OUTPUT_0")
# Convert Triton types to numpy types
self.output0_dtype = pb_utils.triton_string_to_numpy(
output0_config['data_type'])
self.normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
self.loader = transforms.Compose([
transforms.Resize([224, 224]),
transforms.CenterCrop(224),
transforms.ToTensor(), self.normalize
])
def _image_preprocess(self, image_name):
image = self.loader(image_name)
#expand the dimension to nchw
image = image.unsqueeze(0)
return image
def execute(self, requests):
output0_dtype = self.output0_dtype
responses = []
# Every Python backend must iterate over everyone of the requests
# and create a pb_utils.InferenceResponse for each of them.
for request in requests:
# 1) 获取request中name为INPUT_0的tensor数据, 并转换为image类型
in_0 = pb_utils.get_input_tensor_by_name(request, "INPUT_0")
img = in_0.as_numpy()
image = Image.open(io.BytesIO(img.tobytes()))
# 2) 进行图片的transformer,并将结果设置为numpy类型
img_out = self._image_preprocess(image)
img_out = np.array(img_out)
# 3) 构造output tesnor
out_tensor_0 = pb_utils.Tensor("OUTPUT_0", img_out.astype(output0_dtype))
# 4) 设置resposne
inference_response = pb_utils.InferenceResponse(output_tensors=[out_tensor_0])
responses.append(inference_response)
return responses
def finalize(self):
print('Cleaning up...')该model.py的主要功能是对图像进行预处理,并生成推理响应
对应的config.pbtxt为
name: "preprocess"
backend: "python"
max_batch_size: 256
input [
{
name: "INPUT_0"
data_type: TYPE_UINT8
dims: [ -1 ]
}
]
output [
{
name: "OUTPUT_0"
data_type: TYPE_FP32
dims: [ 3, 224, 224 ]
}
]
instance_group [{ kind: KIND_CPU }]我将这个模块放在了preprocess
2.ensemble model
ensemble model是用来描述Triton server模型处理的pipeline,其中仅有一个配置文件,并不存在真实的model
config.pbtxt内容如下:
其中通过platform设置当前model的类型为ensemble
通过ensemble_scheduling来指明model间的调用关系,其中step指定了执行的前后依赖关系
name: "ensemble_python_resnet50"
platform: "ensemble"
max_batch_size: 256
input [
{
name: "INPUT"
data_type: TYPE_UINT8
dims: [ -1 ]
}
]
output [
{
name: "OUTPUT"
data_type: TYPE_FP32
dims: [ 1000 ]
}
]
ensemble_scheduling {
step [
{
model_name: "preprocess"
model_version: -1
input_map {
key: "INPUT_0"
value: "INPUT" # 指向ensemble的input
}
output_map {
key: "OUTPUT_0"
value: "preprocessed_image"
}
},
{
model_name: "resnet50_pytorch"
model_version: -1
input_map {
key: "INPUT__0" #对应resnet50_pytorch里的input名字
value: "preprocessed_image" # 指向preprocess的output
}
output_map {
key: "OUTPUT__0" #对应resnet50_pytorch里的output
value: "OUTPUT" # 指向ensemble的output
}
}
]
}此时resnet50_ensemble的目录结构为:

3.启动程序并测试
启动程序
/opt/tritonserver/bin/tritonserver --model-repository=/triton/resnet50_ensemble测试代码为
import numpy as np
import tritonclient.http as httpclient
import torch
from PIL import Image
if __name__ == '__main__':
triton_client = httpclient.InferenceServerClient(url='127.0.0.1:8000')
img_path = '/test_triton/24poJOgl7m_small.jpg'
image = np.fromfile(img_path, dtype='uint8')
image = np.expand_dims(image, axis=0)
#设置input
inputs = []
inputs.append(httpclient.InferInput('INPUT', image.shape, "UINT8"))
inputs[0].set_data_from_numpy(image)
#设置output
outputs = []
outputs.append(httpclient.InferRequestedOutput('OUTPUT', binary_data=False, class_count=1))
#发送请求
results = triton_client.infer('ensemble_python_resnet50', inputs=inputs, outputs=outputs)
output_data0 = results.as_numpy('OUTPUT')
print(output_data0.shape)
print(output_data0)运行结果为
(1, 1)
[['9.462329:434:bath towel']]4.dali model
在第3部分,把数据处理放到了triton server进行,但问题在于数据处理的操作并没有充分利用硬件资源。为了加速模型的推理速度,一般将triton server部署在GPU节点上(第3部分的数据处理是在CPU上进行的)。将数据处理转移到GPU上,可以使用nvidia提供的dali数据处理库
首先创建resnet50_ensemble_dali目录,并把resnet50_pytorch模型拷贝到resnet50_ensemble_dali路径下
1.准备dali模型
安装依赖
curl -O https://developer.download.nvidia.com/compute/redist/nvidia-dali-cuda110/nvidia_dali_cuda110-1.28.0-8915299-py3-none-manylinux2014_x86_64.whl
pip install nvidia_dali_cuda110-1.28.0-8915299-py3-none-manylinux2014_x86_64.whl在Releases · NVIDIA/DALI · GitHub下载与自己系统适配的whl
Python文件如下
import nvidia.dali as dali
import nvidia.dali.fn as fn
@dali.pipeline_def(batch_size=128, num_threads=4, device_id=0)
def pipeline():
images = fn.external_source(device='cpu', name='DALI_INPUT_0')
images = fn.resize(images, resize_x=224, resize_y=224)
images = fn.transpose(images, perm=[2, 0, 1])
images = images / 255
return images
pipeline().serialize(filename='./model.dali')
执行该Python文件将得到model.dali模型
在resnet50_ensemble_dali目录下创建resnet50_dali,把model.dali放到该目录下
对应的config.pbtxt文件为
name: "resnet50_dali"
backend: "dali"
max_batch_size: 128
input [
{
name: "DALI_INPUT_0"
data_type: TYPE_FP32
dims: [ -1, -1, 3 ]
}
]
output [
{
name: "DALI_OUTPUT_0"
data_type: TYPE_FP32
dims: [ 3, 224, 224 ]
}
]
instance_group [
{
count: 1
kind: KIND_GPU
gpus: [ 0 ]
}
]2.创建pipeline
创建ensemble_python_resnet50目录,和3.2一样,对应的config.pbtxt内容为
name: "ensemble_python_resnet50"
platform: "ensemble"
max_batch_size: 128
input [
{
name: "INPUT"
data_type: TYPE_FP32
dims: [ -1, -1, 3 ]
}
]
output [
{
name: "OUTPUT"
data_type: TYPE_FP32
dims: [ 1000 ]
}
]
ensemble_scheduling {
step [
{
model_name: "resnet50_dali"
model_version: -1
input_map {
key: "DALI_INPUT_0"
value: "INPUT" # 指向ensemble的input
}
output_map {
key: "DALI_OUTPUT_0"
value: "preprocessed_image"
}
},
{
model_name: "resnet50_pytorch"
model_version: -1
input_map {
key: "INPUT__0"
value: "preprocessed_image" # 指向resnet50_dali的output
}
output_map {
key: "OUTPUT__0"
value: "OUTPUT" # 指向ensemble的output
}
}
]
}现在整个resnet50_ensemble_dali目录结构为

3.启动并测试
启动Triton加载模型
/opt/tritonserver/bin/tritonserver --model-repository=/triton/resnet50_ensemble_dali/测试代码为
import numpy as np
import tritonclient.http as httpclient
import torch
from PIL import Image
if __name__ == '__main__':
triton_client = httpclient.InferenceServerClient(url='127.0.0.1:8000')
img_path = '/test_triton/24poJOgl7m_small.jpg'
image = Image.open(img_path)
image = np.asarray(image)
image = np.expand_dims(image, axis=0)
image = image.astype(np.float32)
inputs = []
inputs.append(httpclient.InferInput('INPUT', image.shape, "FP32"))
inputs[0].set_data_from_numpy(image, binary_data=False)
outputs = []
outputs.append(httpclient.InferRequestedOutput('OUTPUT', binary_data=False, class_count=1))
#发送请求
results = triton_client.infer('ensemble_python_resnet50', inputs=inputs, outputs=outputs)
output_data0 = results.as_numpy('OUTPUT')
print(output_data0.shape)
print(output_data0)结果为
root@aea5f00fde8d:/triton/resnet50_ensemble_dali# python3 /test_triton/dali/client.py
(1, 1)
[['10.661538:283:Persian cat']]
结束!