Desnet模型详解
模型介绍
DenseNet的主要思想是密集连接,它在卷积神经网络(CNN)中引入了密集块(Dense Block),在这些块中,每个层都与前面所有层直接连接。这种设计可以让信息更快速地传播,有助于解决梯度消失的问题,同时也能够增加网络的参数共享,减少参数量,提高模型的效率和性能。
Desnet原理
DenseNet 的原理可以总结为以下几个关键点:
-
密集连接的块: DenseNet 将网络分成多个密集块(Dense Block)。在每个密集块内,每一层都连接到前面所有的层,不仅仅是前一层。这种连接方式使得信息能够更加快速地传播,允许网络在更早的阶段融合不同层的特征。
-
跳跃连接: 每一层都从前面所有的层接收特征作为输入。这些输入通过堆叠而来,从而构成了一个密集的特征图。这种跳跃连接有助于解决梯度消失问题,因为每一层都可以直接访问之前层的梯度信息,使得训练更加稳定。
-
特征重用性: 由于每一层都与前面所有层连接,网络可以自动地学习到更加丰富和复杂的特征表示。这样的特征重用性有助于提高网络的性能,同时减少了需要训练的参数数量。
-
过渡层: 在密集块之间,通常会使用过渡层(Transition Layer)来控制特征图的大小。过渡层包括一个卷积层和一个池化层,用于减小特征图的尺寸,从而减少计算量。
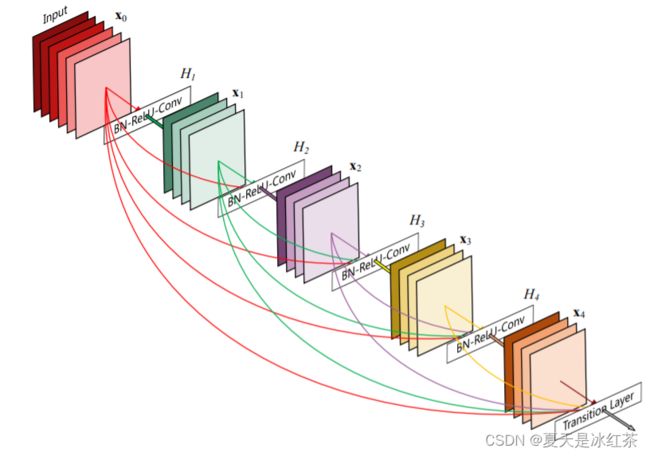
Desnet的结构
关于 DenseNet 的结构时,我们主要关注网络中的三个主要组成部分:密集块(Dense Block)、过渡层(Transition Layer)以及全局平均池化层。
密集块
密集块是 DenseNet 最核心的部分,由若干层组成。在密集块中,每一层都与前面所有层直接连接。这种密集连接的方式使得信息可以更充分地传递和重用。每一层的输出都是前面所有层输出的连结,这也意味着每一层的输入包括了前面所有层的特征。这种连接方式通过堆叠层的方式,构建了一个密集的特征图。
过渡层
在密集块之间,可以使用过渡层来控制特征图的大小,从而减少计算成本。过渡层由一个卷积层和一个池化层组成。卷积层用于减小通道数,从而降低特征图的维度。池化层(通常是平均池化)用于减小特征图的尺寸。这些操作有助于在保持网络性能的同时降低计算需求。
全局平均池化层
在整个 DenseNet 结构的末尾,通常会添加一个全局平均池化层。这一层的作用是将最终的特征图转换为全局汇总的特征,这对于分类任务是非常有用的。全局平均池化层计算每个通道上的平均值,将每个通道转换为一个标量,从而形成最终的预测。
DenseNet 结构的特点不仅在每个密集块内进行特征的密集连接,还在不同密集块之间使用过渡层来控制网络的尺寸和复杂度。这使得 DenseNet 能够在高度复杂的任务中表现出色,同时保持相对较少的参数。
这些在论文当中也有体现:

Desnet的优缺点比较
优点
-
密集连接促进信息传递和特征重用,提升了网络性能。
-
跳跃连接减少了梯度消失,有助于训练深层网络。
-
密集连接减少参数数量,提高了模型效率。
-
早期融合多尺度特征,增强了表征能力。
-
在小样本情况下表现更佳,充分利用有限数据。
缺点
-
密集连接可能导致内存需求增大。
-
连接多导致计算量增加,训练和推理时间较长。
-
可能因复杂性导致过拟合,需考虑正则化。
其实综合考虑,Desnet在图像识别和计算机视觉任务中仍然是一个好的选择。
Pytorch实现Desnet
import torch
import torchvision
import torch.nn as nn
import torchsummary
import torch.nn.functional as F
from torch.hub import load_state_dict_from_url
from collections import OrderedDict
from torchvision.utils import _log_api_usage_once
import torch.utils.checkpoint as cp
model_urls = {
"densenet121":"https://download.pytorch.org/models/densenet121-a639ec97.pth",
"densenet161":"https://download.pytorch.org/models/densenet161-8d451a50.pth",
"densenet169":"https://download.pytorch.org/models/densenet169-b2777c0a.pth",
"densenet201":"https://download.pytorch.org/models/densenet201-c1103571.pth",
}
cfgs = {
"densenet121":(6, 12, 24, 16),
"densenet161":(6, 12, 36, 24),
"densenet169":(6, 12, 32, 32),
"densenet201":(6, 12, 48, 32),
}
class DenseLayer(nn.Module):
def __init__(self, num_input_features, growth_rate, bn_size, drop_rate, memory_efficient = False):
super(DenseLayer,self).__init__()
self.norm1 = nn.BatchNorm2d(num_input_features)
self.relu1 = nn.ReLU(inplace=True)
self.conv1 = nn.Conv2d(num_input_features, bn_size * growth_rate, kernel_size=1, stride=1, bias=False)
self.norm2 = nn.BatchNorm2d(bn_size * growth_rate)
self.relu2 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(bn_size * growth_rate, growth_rate, kernel_size=3, stride=1, padding=1, bias=False)
self.drop_rate = float(drop_rate)
self.memory_efficient = memory_efficient
def bn_function(self, inputs):
concated_features = torch.cat(inputs, 1)
bottleneck_output = self.conv1(self.relu1(self.norm1(concated_features)))
return bottleneck_output
def any_requires_grad(self, input):
for tensor in input:
if tensor.requires_grad:
return True
return False
@torch.jit.unused
def call_checkpoint_bottleneck(self, input):
def closure(*inputs):
return self.bn_function(inputs)
return cp.checkpoint(closure, *input)
def forward(self, input):
if isinstance(input, torch.Tensor):
prev_features = [input]
else:
prev_features = input
if self.memory_efficient and self.any_requires_grad(prev_features):
if torch.jit.is_scripting():
raise Exception("Memory Efficient not supported in JIT")
bottleneck_output = self.call_checkpoint_bottleneck(prev_features)
else:
bottleneck_output = self.bn_function(prev_features)
new_features = self.conv2(self.relu2(self.norm2(bottleneck_output)))
if self.drop_rate > 0:
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)
return new_features
class DenseBlock(nn.ModuleDict):
def __init__(self,num_layers,num_input_features,bn_size,growth_rate,
drop_rate,memory_efficient = False,):
super(DenseBlock,self).__init__()
for i in range(num_layers):
layer = DenseLayer(
num_input_features + i * growth_rate,
growth_rate=growth_rate,
bn_size=bn_size,
drop_rate=drop_rate,
memory_efficient=memory_efficient,
)
self.add_module("denselayer%d" % (i + 1), layer)
def forward(self, init_features):
features = [init_features]
for name, layer in self.items():
new_features = layer(features)
features.append(new_features)
return torch.cat(features, 1)
class Transition(nn.Sequential):
"""
Densenet Transition Layer:
1 × 1 conv
2 × 2 average pool, stride 2
"""
def __init__(self, num_input_features, num_output_features):
super(Transition,self).__init__()
self.norm = nn.BatchNorm2d(num_input_features)
self.relu = nn.ReLU(inplace=True)
self.conv = nn.Conv2d(num_input_features, num_output_features, kernel_size=1, stride=1, bias=False)
self.pool = nn.AvgPool2d(kernel_size=2, stride=2)
class DenseNet(nn.Module):
def __init__(self,growth_rate = 32,num_init_features = 64,block_config = None,num_classes = 1000,
bn_size = 4,drop_rate = 0.,memory_efficient = False,):
super(DenseNet,self).__init__()
_log_api_usage_once(self)
# First convolution
self.features = nn.Sequential(
OrderedDict(
[
("conv0", nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)),
("norm0", nn.BatchNorm2d(num_init_features)),
("relu0", nn.ReLU(inplace=True)),
("pool0", nn.MaxPool2d(kernel_size=3, stride=2, padding=1)),
]
)
)
# Each denseblock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = DenseBlock(
num_layers=num_layers,
num_input_features=num_features,
bn_size=bn_size,
growth_rate=growth_rate,
drop_rate=drop_rate,
memory_efficient=memory_efficient,
)
self.features.add_module("denseblock%d" % (i + 1), block)
num_features = num_features + num_layers * growth_rate
if i != len(block_config) - 1:
trans = Transition(num_input_features=num_features, num_output_features=num_features // 2)
self.features.add_module("transition%d" % (i + 1), trans)
num_features = num_features // 2
# Final batch norm
self.features.add_module("norm5", nn.BatchNorm2d(num_features))
# Linear layer
self.classifier = nn.Linear(num_features, num_classes)
# Official init from torch repo.
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.features(x)
out = F.relu(features, inplace=True)
out = F.adaptive_avg_pool2d(out, (1, 1))
out = torch.flatten(out, 1)
out = self.classifier(out)
return out
def densenet(growth_rate=32,num_init_features=64,num_classes=1000,mode="densenet121",pretrained=False,**kwargs):
import re
pattern = re.compile(
r"^(.*denselayer\d+\.(?:norm|relu|conv))\.((?:[12])\.(?:weight|bias|running_mean|running_var))$"
)
if mode == "densenet161":
growth_rate=48
num_init_features=96
model = DenseNet(growth_rate, num_init_features, cfgs[mode],num_classes=num_classes, **kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls[mode], model_dir='./model', progress=True) # 预训练模型地址
for key in list(state_dict.keys()):
res = pattern.match(key)
if res:
new_key = res.group(1) + res.group(2)
state_dict[new_key] = state_dict[key]
del state_dict[key]
if num_classes != 1000:
num_new_classes = num_classes
weight = state_dict['classifier.weight']
bias = state_dict['classifier.bias']
weight_new = weight[:num_new_classes, :]
bias_new = bias[:num_new_classes]
state_dict['classifier.weight'] = weight_new
state_dict['classifier.bias'] = bias_new
model.load_state_dict(state_dict)
return model
from torchsummaryX import summary
if __name__ == "__main__":
in_channels = 3
num_classes = 10
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = densenet(growth_rate=32, num_init_features=64, num_classes=num_classes, mode="densenet121", pretrained=True)
model = model.to(device)
print(model)
summary(model, torch.zeros((1, in_channels, 224, 224)).to(device))