2023.08.20 学习周报
文章目录
- 摘要
- 文献阅读
-
- 1.题目
- 2.现有问题
- 3.解决方案
- 4.本文贡献
- 5.方法
-
- 5.1 利用长短期记忆网络学习时空演化特征
- 5.2 构建用于气象辅助信息编码的堆叠自编码器
- 5.3 使用多任务学习发现全市通用模式
- 5.4 模型
- 6. 实验
-
- 6.1 数据集
- 6.2 实验设置
- 6.3 实验结果
- 7.结论
- 8.展望
- 大气污染物传输
- 总结
摘要
This week, I read a computer science that predicted the time series of PM2.5 in multiple locations in Beijing. Existing data-driven methods ignore the dynamic relationship between multiple sites in urban areas, resulting in unsatisfactory prediction accuracy. To solve this problem, a long short-term memory-Autoencoder multitask learning model (LSTM-Autoencoder) is proposed to predict PM2.5 time series at multiple locations across the city. The multi-layer LSTM network can simulate the spatiotemporal characteristics of urban air pollution particles, the autoencoder can encode the key evolution model of urban meteorological system, and the multi-task learning can automatically discover the dynamic relationship between multiple key pollution time series. The simulation results of PM2.5 in Beijing show the effectiveness of the proposed method. In addition, I learn the basic knowledge of air pollutant transmission.
本周,阅读了一篇预测北京市多个地点的PM2.5时间序列的文章。现有的数据驱动方法会忽略城市地区多个站点之间的动态关系,导致预测精度不理想。针对这个问题,提出了一种长短期记忆-自编码器多任务学习模型(LSTM-Autoencoder)来预测全市多个地点的PM2.5时间序列。展开来说,多层LSTM网络可以模拟城市空气污染颗粒物的时空特征,自编码器可以对城市气象系统关键演化模式进行编码,多任务学习可以自动发现多个关键污染时间序列之间的动态关系。对北京市PM2.5进行模拟,实验结果表明了该方法的有效性。此外,我学习了大气污染物传输的基础知识。
文献阅读
1.题目
文献链接:Multitask Air-Quality Prediction Based on LSTM-Autoencoder Model
2.现有问题
现有的基于人工神经网络的PM2.5时间序列预测方法,主要是选择一个地点进行建模,容易造成信息丢失。
3.解决方案
1)采用多位置PM2.5时间序列,利用LSTM学习时空演化特征。
2)考虑到深度学习模型的有效性,提出了带气象信息编码器的多任务LSTM模型,用于PM2.5时间序列的建模。
3)采用多LSTM层提取PM2.5时间序列的时空特征,提出叠置式自编码器对多个地点的气象信息进行编码,使用级联并行架构进行多任务学习。
4.本文贡献
1)考虑到空气污染物的复杂时空动态,通过多层LSTM网络的时空学习,探索城市多个地点颗粒物的时空特征。
2)利用气象信息,采用稀疏约束叠加自编码器对进化信息进行编码。
3)PM2.5时间序列在多个地点之间具有很强的相关性,于是利用多任务学习自动探索重点污染监测站之间的联系,并通过深度学习模型隐式描述各地点之间的关系。
4)对北京市多站PM2.5时间序列和气象观测资料的建模与仿真表明,该方法考虑了多站间的相互关系,取得了满意的效果。
5.方法
5.1 利用长短期记忆网络学习时空演化特征
LSTM网络图:
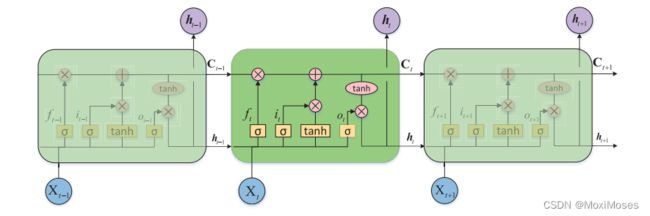
5.2 构建用于气象辅助信息编码的堆叠自编码器
1)定义了一个特征学习函数h = fθ (X),其中fθ(·)称为编码器函数。然后,解码函数X = gθ (h)学习重构原始信号。特征向量h是原始输入的压缩表示。
2)目标是构建气象信息的向量表示,并将其用于PM2.5时间序列的建模。气象自编码器的目标函数可表示为:

其中:XMeteo,i为第i个监测点位置的气象信息,R(θ)是自编码器权值的约束项。
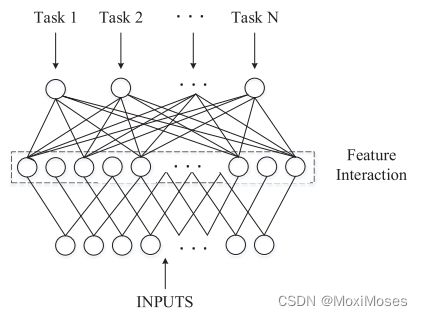
5.3 使用多任务学习发现全市通用模式
1)在硬参数共享中,学习神经网络基础层的公共特征子空间。在基础层中参数是完全相同的,可以防止过拟合问题,有更好的泛化效果。
2)在软参数共享中,任务的模型参数可以是不同的、受规则约束的特征子空间。
3)多任务学习的参数学习图:
4)多任务学习的目标函数:
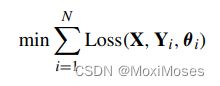
其中:X为多任务输入,Yi为各自的多任务学习目标,θi是第i个任务对应的学习参数,N是任务数。
5.4 模型
1)模型架构图:
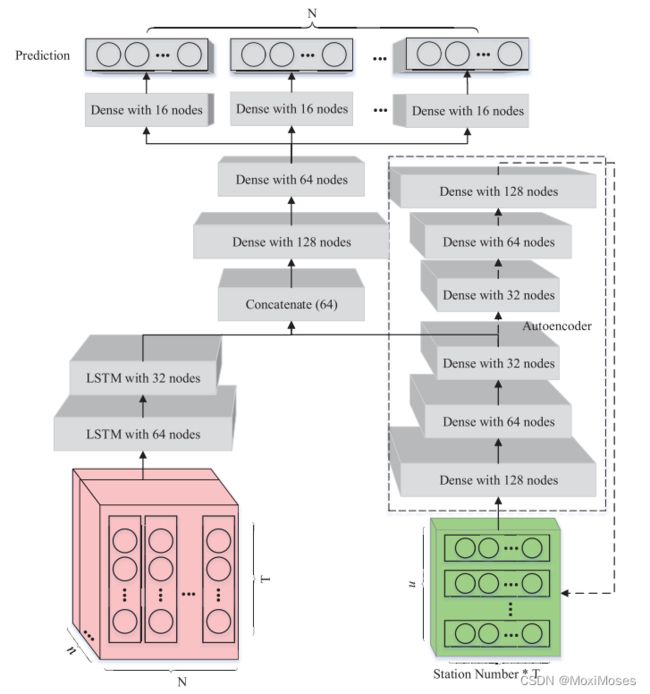
多层LSTM网络对PM2.5时空序列特征进行学习,层叠式自编码器可以逐层压缩有用信息,提高性能。
2)在更高层次的特征学习上,使用两层密集网络学习PM2.5综合演化信息和气象辅助。基于深度特征,利用多个亚密集层对全市范围内多个地点的PM2.5时间序列进行建模,并输出预测值。整个模型的目标函数为:
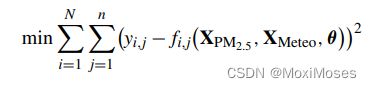
其中:yi,j为PM2.5时间序列实值,N为空气质量监测站的个数,n是时间序列的个数。XPM2.5为所有空气质量监测站的记录值,XMeteo是辅助气象信息的输入,θ为所提模型的所有参数。
6. 实验
6.1 数据集
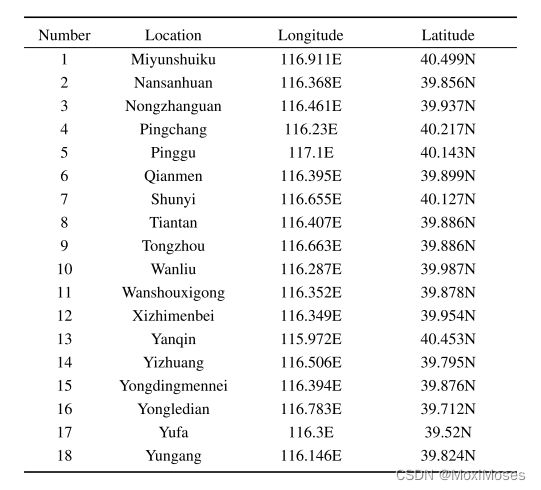
1)主要包括几种空气污染物的浓度:PM2.5(μg/m3)、PM10(μg/m3)、NO2(μg/m3)、CO(mg/m3)、O3(mg/m3)和SO2(μg/m3)。共有18个监测站,站点名称、经纬度如下所示:
2)时间序列从2017年1月30日下午4点到2018年1月31日下午3点每小时采样一次,共8784个样本。
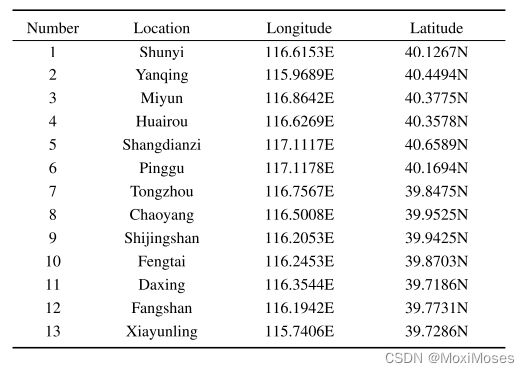
3)利用气象信息作为辅助信息,包括温度、压力、湿度、风向、风速和天气情况。共有13个气象站,位置如下所示:
6.2 实验设置
优化方法是最常用的ADAM优化器,使用三个评价指标来比较所提出模型的性能:均方根误差(RMSE)、平均绝对误差(MAE)和对称平均绝对百分比误差(SMAPE)。
6.3 实验结果
1)该模型在北京市多个气象监测站的预报结果:
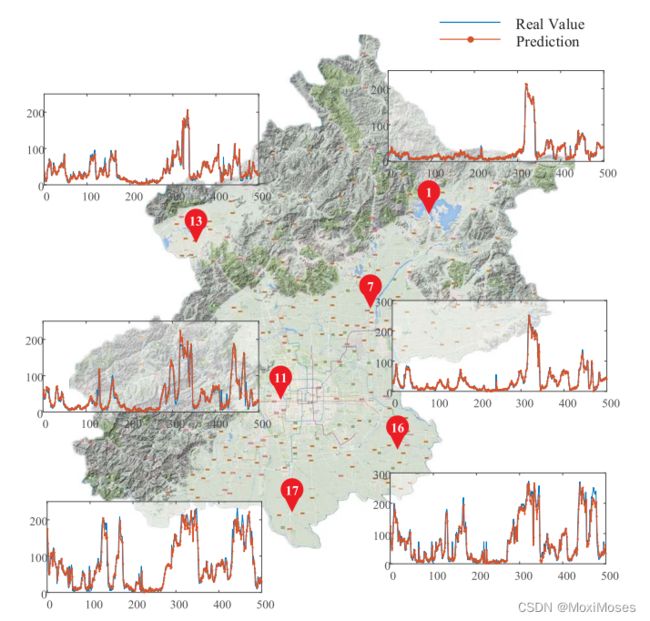
从图中可以看出,多个地点的PM2.5时间序列趋势是一致的,但地点之间的细节差异很明显。
2)该方法对PM2.5时间序列的一步前预测结果和三步前预测结果:
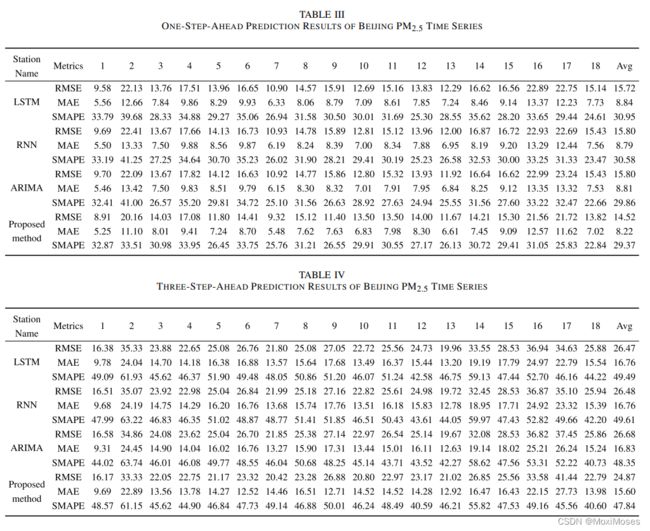
从表中可以看出,提出的方法在各个指标(RMSE、MAE、SMAPE)上都有更好的表现,每个指标的预测误差都比对比方法好10%左右。
3)LSTM-Autoencoder模型和传统LSTM模型的预测结果
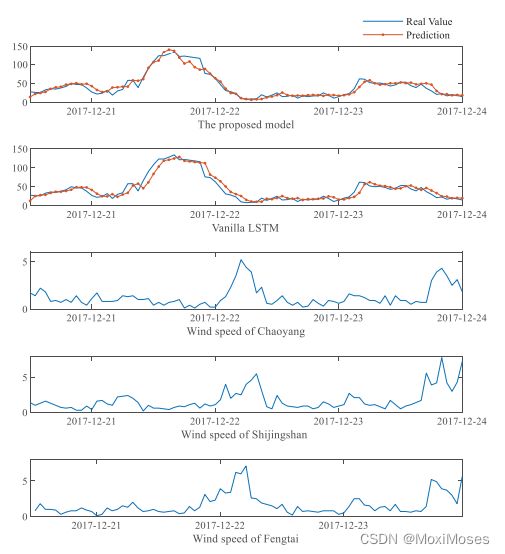
两者之间预测结果相差很大,LSTM-Autoencoder模型在12月21日的预测结果优于传统的LSTM模型。预测曲线增长快,能有效地预测空气质量。相比之下,传统LSTM无法跟踪PM2.5时间序列的趋势。
7.结论
1)提出了一种新的多任务深度学习模型,该模型具有自动编码的辅助信息,用于空气质量时间序列预测。
2)模型可以利用历史PM2.5时间序列和全市多地点的气象时间序列,而多任务学习范式可以隐式捕捉跨任务演化模式,用于时间序列建模。
3)克服了数据驱动的PM2.5预测方法的局限性,模拟结果证实了模型的有效性。
4)模型可以跟踪PM2.5时间序列发生剧烈变化时的演变模式,并且可以隐式学习多个站点的多个PM2.5时间序列的共同模式。
8.展望
在PM2.5时间序列建模中加入更多的辅助信息,如经济因素、气体排放等,即传统PM2.5预测模型从未考虑过的确定性过程。
大气污染物传输
1.大气污染物传输的本质是空气中污染物的扩散和迁移过程,而大气污染物传输的主要因素包括风、大气稳定度、地形、气象条件等。
1)风:风的方向和速度决定了污染物的扩散方向和速率。强风能够将污染物快速地从污染源地带到其他地区,而相对较弱的风可能导致污染物在源地积累。
2)大气稳定度:大气稳定度指的是大气中垂直气流的强弱。在稳定的大气条件下,污染物容易积聚在较低的空气层中,形成雾霾等现象。而在不稳定的大气条件下,污染物可能会被较强的垂直气流带到较高的空气层,减少地表的浓度。
3)地形:山脉、山谷等地形特征能够影响风的流动,并且可能导致污染物在某些地区的积聚或稀释。
4)气象条件:温度的变化可以影响空气密度,从而影响污染物的上升和下沉。湿度可以影响污染物的溶解和反应。
2.利用高维数学方法来建立模型预测大气污染物传输
1)偏微分方程:大气污染物传输通常涉及多个自变量,如时间、空间坐标等。偏微分方程是用来描述多个自变量之间关系的数学方程。
2)扩散方程:扩散方程是描述物质传输和扩散过程的数学模型。在高维数学中,可以使用偏微分方程来表示扩散方程。这些方程可以考虑污染物浓度随时间和空间的变化,同时考虑风速、大气稳定度等因素。
3)数值模拟方法:由于复杂的大气流动和扩散过程难以解析地求解,数值模拟方法成为了预测大气污染物传输的重要工具。通过将扩散方程离散化,可以在计算机上模拟大气污染物的传输过程。
4)数据同化:将观测数据与模型预测结果进行融合,从而提高预测的准确性。数据同化技术可以将实际观测数据与模型预测进行比较,通过优化算法来调整模型参数,使模型的输出与实际观测数据更加一致。
5)随机过程:大气传输过程中存在不确定性因素,如风速和方向的随机变化。随机过程理论可以用来建立随机扩散模型,考虑这些不确定性因素对污染物传输的影响。
3.大气污染物传输过程需要遵循的物理规律
1)质量守恒:在任何给定的空间区域内,污染物的质量不能凭空产生或消失,只能通过传输和转化来改变。这意味着传输过程中,污染物的流入流出量必须相等。
2)扩散:它描述了污染物在浓度梯度驱动下在空气中的随机运动。扩散过程可以使用菲克定律来描述,该定律表明扩散通量与浓度梯度成正比。
3)对流:对流可以通过空气的运动来将污染物从一个地区传输到另一个地区,其中风的方向和速度决定了污染物的传输路径。
4)沉降:大气中的颗粒物和气溶胶等污染物会因重力作用而沉降到地面,这被称为沉降过程。沉降速率取决于颗粒物的大小、密度以及空气的粘度和密度。
5)化学反应:大气中的污染物可能会发生化学反应,导致浓度的变化。其中化学反应可以影响污染物的浓度分布和组成。
6)辐射传输:辐射传输是指太阳辐射或其他电磁辐射对污染物传输的影响。一些污染物可能吸收或散射辐射,从而影响大气的温度和辐射平衡。
总结
本周,我阅读了一篇预测北京市多个地点的PM2.5时间序列的文章,它是一个基于神经网络的预测模型,该模型使用神经网络来模拟气候污染物的运输过程。 此外,我学习了大气污染物传输的基础知识,其中包含了大气污染物传输的影响因素以及需要遵循的物理规律。下周,我会学习一些数学方法或者模型能够有效地分析大气污染的变化规律,预测大气污染物未来的走势,理解其中的优势点。