分布式技术
分布式没有权威的技术,只有实践经验和积累的组件。常见的分布式技术有发号机制、分布式数据库、分布式数据库事物、基于Redis的分布式缓存、分布式会话、分布式安全认证。
1、发号机制
在数据库(关系数据库)中,主键往往是一条记录的唯一标识,它具备唯一性。在单机的时候,只需要考虑单个数据库的问题,相对简单,但在分布式和微服务系统里,就相对困难了,因为它涉及多台机器之间的协作。那么如何保证在分布式或者微服务的多个节点下生成唯一的ID,如何让ID具备一定的可读性呢?这就需要一个发号机制来控制了。
1.1、常见的生成ID的方法
生成ID的机制需要从以下几方面进行评价:
- 机制的可靠性:有些算法可能有一定的概率出现重复的ID,也可以利用缓存机制来实现,但缓存工具也不一定完全可靠,可能也需要重启或者出现故障,如果遇到类似这样的问题,是否会对ID的唯一性造成影响。
- 实现复杂度:有些算法可以实现ID的唯一性和可读性,但是实现起来十分复杂,后续也难以改造。
- 可扩展性:有时候,发号机制不单单是一个节点的工作,可能是多个节点的工作,节点能否伸缩是一个考量点。
- ID的可读性:有些ID只是为了唯一性,如UUID机制,它是不可读的,没有业务含义。不过,生成一个可读的带有业务含义的ID,将有助于业务人员和开发人员定位业务和问题所在。
- 性能:分布式系统往往也需要面对高并发的情况,在这种情况下,性能也会列入评价ID机制的范畴。
1.1.1、使用UUID
UUID是Universally Unique Identifier(通用唯一识别码)的缩写,它是一种软件构建的标准,亦为开放软件基金会组织在分布式计算环境领域的一部分。在Java中,也提供了UUID(java.util.UUID)类,因此我们可以很方便地使用UUID。
/**
* 随机生成UUID
* @return 返回UUID的字符串
*/
public static String generateId() {
UUID uid = UUID.randomUUID();
return uid.toString();
}
/**
* 测试生成一百万个UUID的耗时
*/
public static void performanceTest() {
// 开始时间
long start =System.currentTimeMillis();
for (int i=1; i<=1000000; i++) {
generateId();
}
// 结束时间
long end = System.currentTimeMillis();
// 打印耗时
System.out.println("生成一百万个UUID耗时:" + (end - start) + "毫秒");
}
这里的generateId方法比较简单,它生成一个随机的UUID,然后返回该字符串。performanceTest方法则是对generateId方法进行测试,在我的本机测试中,生成一百万个UUID的耗时在1000ms左右,所以性能是相当优异的。
UUID只有一定的格式,没有规则,比较难以识别,也不具备业务含义。但是它也有一些好处,它简单方便,性能十分好,即使是做数据迁徙,也不会有太大的问题,毕竟没有相应的特殊规则。但是对于开发者和业务人员来说,这种UUID难以识别,通过它不好定位问题。
- 为什么不用UUID
当前很多企业已经摒弃了UUID作为主键的发号算法。除了业务不可读外,从数据库的角度来说,它还有许多缺陷。首先,使用UUID作为主键,存储会占据较大的空间,网络传输内容也多,不利于优化。其次,从性能来说,使用UUID这样无序的主键,会降低数据库主键算法(一般是B+树)的性能,尤其是在数据量庞大的情况下,例如,MySQL单表超过5000万笔数据时,采用它作为主键,检索数据的性能就比较堪忧了。因此在很多时候,预计数据量庞大的企业也不会考虑使用UUID机制来生成主键。它们往往希望使用一个大整数型(BIGINTEGER)作为主键,这样主键就将是数字,在计算机系统里可以快速计算和定位,即使在数据量很大的时候,也能保持很好的性能。
1.1.2、数据库自增长
如果采用单一数据库,并且对性能要求较低,那么使用数据库的自增长会是一个不错的选择。相对来说,在分布式系统中使用MySQL的概率要比Oracle大,所以这里采用MySQL进行讲述。对于Oracle数据库,可以考虑使用其序列(SEQUENCE)机制。
在MySQL中可以经常看到类似代码清单如下所示的建表语句。
create table foo(
id int(12) auto_increment, /**id自动增长**/
content varchar(256) null,
primary key(id) /**设置为主键**/
);
这里的auto_increment代表让字段id进行自增长,而primary key则是将id字段设置为主键,这样MySQL就可以自增长了。然后我们执行下面的SQL语句。
insert into foo (content) values('content-1');
insert into foo (content) values('content-2');
insert into foo (content) values('content-3');
insert into foo (content) values('content-4');
select * from foo;
就能够看到下图所示的结果:
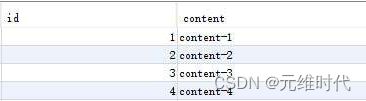
上面只是讨论一个数据库的情况,但是在一些数据量特别大的场景下,企业往往还会考虑分表分库的问题。如果出现分表分库的情况,那么又如何保证数据库ID自动增长呢?

在上图的分布式数据库系统中,因为使用了非单一的数据库系统,所以需要采用特别的策略来保证主键的唯一性和自增长。
在两个数据库里建表(如果是单机模拟,可以创建2个数据库实例来模拟),然后在数据库1中执行下列SQL。
/** 第一个主键的开始值*/
set session auto_increment_offset=1;
/** 主键步长 **/
set session auto_increment_increment=2;
insert into foo (content) values('content-1');
insert into foo (content) values('content-2');
insert into foo (content) values('content-3');
insert into foo (content) values('content-4');
select * from foo;
注意这段SQL代码的前两句,这两句里都有关键字session,意思是只在某个会话中有效,而非全局有效。其中,第一条SQL语句设置了主键开始的数值,第二条SQL语句定义了主键增长的步长。执行完之后,可以看到下图所示的结果:
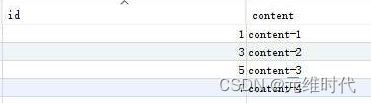
由上图可见,奇数ID保存在数据库1中了。
接下来,数据库2要执行下列SQL。
/** 第一个主键的开始值*/
set session auto_increment_offset=2;
/** 主键步长 **/
set session auto_increment_increment=2;
insert into foo (content) values('content-1');
insert into foo (content) values('content-2');
insert into foo (content) values('content-3');
insert into foo (content) values('content-4');
select * from foo;
这里的SQL和上述的基本相同,只是第一个主键值设置为了2,因此可以看到下图所示的结果。
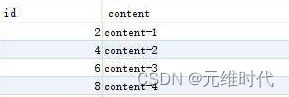
这样做就能够保证两个数据库的主键不重复,并且按照一定的规则递增了。
不过这样做会带来以下的问题:
- 如果需要增加数据库节点,就要改变自增长规则,显然,这样做不利于扩展。
- 如果出现高并发场景,数据库的性能可能就无法满足需要了,这时优化数据库会变得十分复杂,优化的空间也相对有限。
- 如果数据需要迁徙或合并,还需要考虑现有规则和新规则的适应性。
1.1.3、使用Redis生成ID
上述谈了使用数据库的不足,在分布式系统中,还可能使用流水号来追踪某一请求,以满足多个节点的协作。在这种情况下,并不需要插入数据,采用数据库机制就有点不合适了。为此,我们可以考虑使用Redis来满足这个要求。
从性能上来说,Redis的性能要比数据库好得多。从扩展性来说,使用多个Redis服务器就能实现扩展。因此,无论是性能,还是可扩展性,Redis都要比数据库好很多。并且Redis可以在不插入数据的时候生成ID,为分布式协作提供流水号。
使用Redis的方式,比数据库的方式快速。但是因为Redis服务可能出现故障,所以一般会考虑使用哨兵和集群等方式来降低故障的发生,从而保证系统能够持续提供服务。但是这样会依赖Redis服务,且算法也比较复杂,这会增加开发者实现的复杂度,造成性能的下降。
1.1.4、时钟算法
在时间表达上,Java的java.util.Date类使用了长整型数字进行表示,该数字代表距离格林尼治时间1970年1月1日整点的毫秒数。因此很多开发者提出利用这点,采用时钟算法来获取唯一的ID。使用时钟算法的好处有这么几点。
- 相对简单,可以获取一个整数型,有利于数据库的性能。
- 可以知道业务发生的时间点,通过时间来追踪业务。
- 如果在原有时间信息的基础上加入数据存储机器编号,就能快速定位业务。
在介绍时钟算法前,我们需要对Java中的时间有一定的认知,为此,这里先介绍一些简单的知识。在Java的System类中有下列两个静态(static)方法。
// 返回当前时间,精确到毫秒
System.currentTimeMillis();
// 返回当前时间,精确到纳秒
System.nanoTime();
这便是获取当前时间长整型数字的方法,此外还需要大家记住的下面的单位换算规则:
1s=1000ms;
1ms=1000μs=1000000ns;
使用时钟生成ID:
// 同步锁
private static final Class<Chapter13Application> LOCK
= Chapter13Application.class;
public static long timeKey() {
// 线程同步锁,防止多线程错误
synchronized (LOCK) { // ①
// 获取当前时间的纳秒值
long result = System.nanoTime();
// 死循环
while(true) {
long current = System.nanoTime();
// 超过1 ns后才返回,这样便可保证当前时间肯定和返回的不同,
// 从而达到排重的效果
if (current - result > 1) { // ②
// 返回结果
return result;
}
}
}
}
先看一下代码①处,这里启用了同步锁机制,保证在多线程中不会出现差错,并且在同步代码块中获取了当前时间的纳秒值。为防止调用产生同样的时间纳秒值,代码②处退出死循环,让程序循环到下一个纳秒才返回,这样就能够保证其返回ID的唯一性了。
从上述代码可以看到,使用时钟算法相对来说比较简单。实际测试时,使用上述代码可以每秒产生数百万个ID,显然在性能上是十分优越的,甚至只需要使用单机就能够满足分布式系统发号的需求。但是如果在多个分布式节点上使用这样简易的时钟算法,就有可能发出重复的号,所以这种简单的时钟算法并不能应用在多个分布式节点上。另外,有些企业希望ID能够放入更多的业务逻辑,以便在后续出现问题时定位具体出现问题的机器和数据库,于是就出现了一些变种的时钟发号算法,其中最出名、使用最广泛的当属SnowFlake算法。
1.1.5、变异时钟算法——SnowFlake算法
SnowFlake(雪花)算法是Twitter提出的一种算法,我们之前在阐述时钟算法的时候谈到过,如果MySQL的主键采用BIGINT(大整数)类型,那么它的取值范围是−2^63 到 2^63−1,从计算机原理的角度来说,存储一个BIGINT类型就需要64位二进制位。基于这个事实,SnowFlake算法对这64位二进制位做了下图所示的约定:
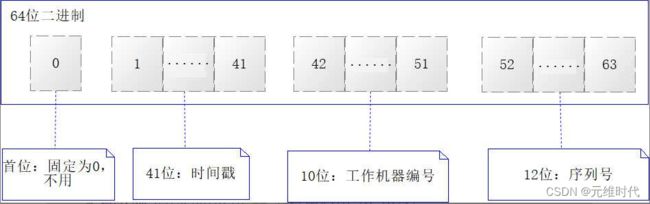
关于SnowFlake算法对于64位二进制的约定,这里结合上图做更为详细的阐述。
- 第1位二进制值固定为0,没有业务含义,在计算机原理中,它是一个符号位,0代表正数,1代表负数,这里恒定为0。
- 第2~42位,共41位二进制,为时间戳位,用于存入精确到毫秒数的时间。
- 第43~52位,共10位二进制,为工作机器id位,其中工作机器又分为5位数据中心编号和5位受理机器编号,而5位二进制表达整数时取值区间为[0, 31]。
- 第53~64位,共12位二进制,代表1ms内可以产生的序列号,当它表示整数时,取值区间为[0, 4095]。
通过上述讲解,我们可以看到,这样的一个算法可以保证在1ms内生成4096个编号,实际就是1秒至多产生4096000个ID,这样的性能显然可以满足分布式系统的需要,而更加好的是,存在10位工作机器位,这样出现问题可以定位到机器,有助于业务和开发者定位问题。但是这里需要特别指出的是,由于当前分布式和微服务系统都开始了去中心化,也就是业务数据不再和具体的机器绑定,因此受理机器编号当前使用已经不多了。
SnowFlake算法实现:
package com.spring.cloud.chapter13.main;
public class SnowFlakeWorker {
// 开始时间(这里使用2019年4月1日整点)
private final static long START_TIME = 1554048000000L;
// 数据中心编号所占位数
private final static long DATA_CENTER_BITS = 10L;
// 最大数据中心编号
private final static long MAX_DATA_CENTER_ID = 1023;
// 序列编号占位位数
private final static long SEQUENCE_BIT = 12L;
// 数据中心编号向左移12位
private final static long DATA_CENTER_SHIFT = SEQUENCE_BIT ;
/** 时间戳向左移22位(10+12) */
private final static long TIMESTAMP_SHIFT
= DATA_CENTER_BITS + DATA_CENTER_SHIFT;
// 最大生成序列号,这里为4095
private final static long MAX_SEQUENCE = 4095;
// 数据中心ID(0~1023)
private long dataCenterId;
// 毫秒内序列(0~4095)
private long sequence = 0L;
// 上次生成ID的时间戳
private long lastTimestamp = -1L;
/**
* 因为当前微服务和分布式趋向于去中心化,所以不存在受理机器编号,
* 10位二进制全部用于数据中心
* @param dataCenterId -- 数据中心ID [0~1023]
*/
public SnowFlakeWorker(long dataCenterId) { // ①
// 验证数据中心编号的合法性
if (dataCenterId > MAX_DATA_CENTER_ID) {
String msg = "数据中心编号[" + dataCenterId
+"]超过最大允许值【" + MAX_DATA_CENTER_ID + "】";
throw new RuntimeException(msg);
}
if (dataCenterId < 0) {
String msg = "数据中心编号[" + dataCenterId + "]不允许小于0";
throw new RuntimeException(msg);
}
this.dataCenterId = dataCenterId;
}
/**
* 获得下一个ID (为了避免多线程环境产生的错误,这里方法是线程安全的)
* @return SnowflakeId
*/
public synchronized long nextId() {
// 获取当前时间
long timestamp = System.currentTimeMillis();
// 如果是同一个毫秒时间戳的处理
if (timestamp == lastTimestamp) {
sequence += 1; // 序号+1
// 是否超过允许的最大序列
if (sequence > MAX_SEQUENCE) {
sequence = 0;
// 等待到下一毫秒
timestamp = tilNextMillis(timestamp); // ②
}
} else {
// 修改时间戳
lastTimestamp = timestamp;
// 序号重新开始
sequence = 0;
}
// 二进制的位运算,其中“<<”代表二进制左移,“|”代表或运算
long result = ((timestamp - START_TIME) << TIMESTAMP_SHIFT)
| (this.dataCenterId << DATA_CENTER_SHIFT)
| sequence; // ③
return result;
}
/**
* 阻塞到下一毫秒,直到获得新的时间戳
* @param lastTimestamp -- 上次生成ID的时间戳
* @return 当前时间戳
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp;
do {
timestamp = System.currentTimeMillis();
} while(timestamp > lastTimestamp);
return timestamp;
}
}
这个算法的难点在于二进制的位运算。代码①处的构造方法,主要是验证和绑定数据中心编号(dataCenterId)。核心是nextId方法,它通过获取当前时间毫秒数,判断上次生成的ID是否在同一个时间戳内,于是,计算序号就存在两种可能。第一种可能是在同一个时间戳内,这个时候通过序号加一的方法来处理。而代码②处的序号已经超过最大限制,这时候通过tilNextMillis方法阻塞到下一毫秒,就可以获得下一毫秒的时间戳,避免产生重复的ID。第二种可能是不在同一个时间戳内,这个时候让序号从0重新开始,且重新记录上次生成ID的时间戳即可。接下来看代码③处,这里的运算为二进制位运算,其中,通过左移运算符“<<”将对应的二进制数字移动到对应的位上,然后通过“|”将数字拼凑在一起,最终生成ID。通过循环测试nextId方法可以看到生成的ID,代码如下:
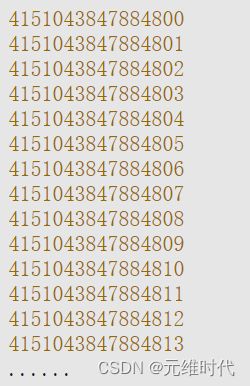
由以上ID可见,存在16位数字,按照给出的算法保证了ID的唯一性。SnowFlake算法是一种高效的算法,每秒可以产生数十万的ID,它包含了数据中心(旧算法在不去中心化的情况下还可以包含受理机器编号)、时间戳和序号3种业务逻辑,可以在一定的程度上帮助我们定位业务。由于性能好且带有一定的业务数据,因此受到了许多互联网企业的青睐,使用得也比较广泛。
但是这个算法也有一些缺陷:
- 因为时间戳只存在41位二进制,所以只能使用69年,69年后就可能产生重复的ID了,不过这个时间已经比较长了,相信大部分的系统和主要的算法早已更替。
- 从SnowFlake算法上来看,如果机器性能足够好,每秒可以产生超过400万个ID,但是对于大部分企业来说,只需要每秒满足数万个ID即可,并不需要这么高的性能。这种高性能浪费的主要是序号的二进制位,实际上,二进制位达到9位,就可以产生512个序号,如果机器性能足够,就可以每秒产生超过50万的ID,这就已经能满足大部分企业的需要了。
- 从机器位来说,因为去中心化是分布式和微服务的趋势,所以我在实现的时候,并未考虑受理机器编号,这样就会造成机器位数有10位二进制,可以表达区间[0, 1023]的整数。如果数据中心预估总共只有几十台机器,显然也会造成二进制位的浪费。
1.2、自定义发号机制
实际上,我们并不需要严格按照常见发号算法来做,只要我们规划得当,使用自己的算法也是可行的。本节就让我们来实现一个自定义的发号机制。在前面介绍SnowFlake算法的时候,我谈到了它的诸多缺点,例如,产生的序号和机器位可能浪费了太多的二进制。为了克服这些问题,我们会改造SnowFlake算法,编写自定义发号机制。
在改造前,需要先明确自己的系统的实际情况,这是第一步。这里做如下假设。
- 预估数据中心不会超过100个,这就意味着数据中心使用8位二进制即可,原来的10位就能够节省出2位了。
- 系统不会超过每秒10万次的请求(这符合大部分企业的需求),如果超过可以使用限流算法进行处理,所以序号使用8位二进制即可,这样原来的12位就能够节省出4位了。
由此来看,一共可以节省6位二进制,可以用于表示发号机器编号,这样就可以同时在多个节点上使用发号算法了。但是需要进行约定,为了更好地讲述约定,先看一下图:

在上图中,约定如下:
- 第1位二进制固定为0。
- 第2~42位,共41位二进制,存储时间戳。
- 第43~48位,共6位二进制,存储发号机器号。
- 第49~56位,共8位二进制,存储数据中心编号。
- 第57~64位,共8位二进制,存储序号。
有了这些约定,就可以实现算法了,代码示例:
package com.spring.cloud.chapter13.main;
public class CustomWorker {
// 开始时间(这里使用2019年4月1日整点)
private final static long START_TIME = 1554048000000L;
// 当前发号节点编号(最大值63)
private static long MACHINE_ID = 21L;
// 最大数据中心编号
private final static long MAX_DATA_CENTER_ID = 127L;
// 最大序列号
private final static long MAX_SEQUENCE = 255L;
// 数据中心位数
private final static long DATA_CENTER_BIT=8L;
// 机器中心位数
private final static long MACHINE_BIT= 6L;
// 序列编号占位位数
private final static long SEQUENCE_BIT = 8L;
// 数据中心移位(8位)
private final static long DATA_CENTER_SHIFT = SEQUENCE_BIT;
// 当前发号节点移位(8+8=16位)
private final static long MACHINE_SHIFT
= SEQUENCE_BIT + DATA_CENTER_BIT;
// 时间戳移位(8+8+6=22位)
private final static long TIMESTAMP_SHIFT
= SEQUENCE_BIT + DATA_CENTER_BIT + MACHINE_BIT;
// 数据中心编号
private long dataCenterId;
// 序号
private long sequence = 0;
// 上次时间戳
private long lastTimestamp;
public CustomWorker(long dataCenterId) {
// 验证数据中心编号的合法性
if (dataCenterId > MAX_DATA_CENTER_ID) {
String msg = "数据中心编号[" + dataCenterId
+ "]超过最大允许值【" + MAX_DATA_CENTER_ID + "】";
throw new RuntimeException(msg);
}
if (dataCenterId < 0) {
String msg = "数据中心编号[" + dataCenterId + "]不允许小于0";
throw new RuntimeException(msg);
}
this.dataCenterId = dataCenterId;
}
/**
* 获得下一个ID (该方法是线程安全的)
* @return 下一个ID
*/
public synchronized long nextId() {
// 获取当前时间
long timestamp = System.currentTimeMillis();
// 如果是同一个毫秒时间戳的处理
if (timestamp == lastTimestamp) {
sequence += 1; // 序号+1
// 是否超过允许的最大序列
if (sequence > MAX_SEQUENCE) {
sequence = 0;
// 等待到下一毫秒
timestamp = tilNextMillis(timestamp);
}
} else {
// 修改时间戳
lastTimestamp = timestamp;
// 序号重新开始
sequence = 0;
}
// 二进制的位运算,其中“<<”代表二进制左移,“|”代表或运算
long result = ((timestamp-START_TIME) << TIMESTAMP_SHIFT)
| (MACHINE_ID << MACHINE_SHIFT)
| (this.dataCenterId << DATA_CENTER_SHIFT)
| sequence;
return result;
}
/**
* 阻塞到下一毫秒,直到获得新的时间戳
* @param lastTimestamp -- 上次生成ID的时间戳
* @return 当前时间戳
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp;
do {
timestamp = System.currentTimeMillis();
} while(timestamp > lastTimestamp);
return timestamp;
}
}
2、分布式数据库技术
对分布式和微服务来说,一种业务就可能有很多的数据,如交易,单数据库也很有可能无法支撑,需要多个数据库节点进行支持,这种需要将数据库拆分为多节点进行存储的技术,即分布式数据库技术。
2.1、分库、分表和分区的概念
2.1.1、分库、分表的概念
2.1.2、分区
分区是指一张表的数据分成n个区块,在逻辑上看,最终只是一张表,但底层是由n个物理区块组成的,如下图所示:
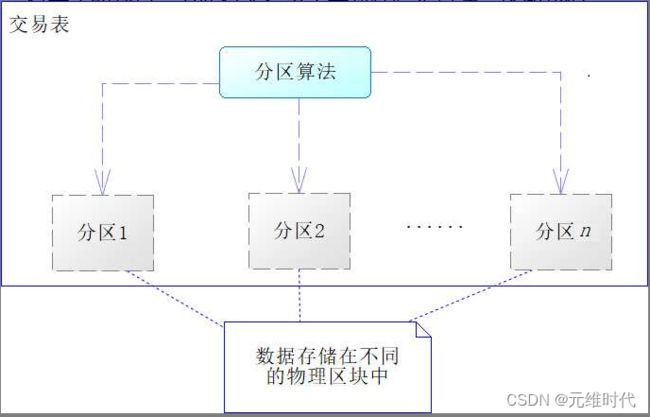
分区技术与分表技术很类似,只是分区技术属于数据库内部的技术,对于开发者来说,它逻辑上仍旧是一张表,开发时不需要改变SQL表名。将一张表切分为多个物理区块,有以下这么几个好处:
- 相对于单个文件系统或是磁盘,分区可以在不同的磁盘上存储更多的数据。
- 数据管理比较方便,例如,需要按日期删除交易记录时,只需要在对应的分区操作即可。
- 在使用分区的字段查询时,可以先定位到分区,然后就只需要查询分区,而不需要全表查询了,这样可以大大提高数据检索效率。
- 支持CPU多线程同时查询多个分区磁盘,提高查询的吞吐量。
- 在涉及聚合函数查询时,可以很容易地合并数据。
不过,从当前来说,分表技术已经渐渐淡出了人们的选择。因为分表会导致表名变化,产生逻辑不一致,继而加大后续开发的工作量和统计上的困难。当前采用更多的是分库技术,分库技术的伸缩性更好,可以增加节点,也可以减少节点,比较灵活。但是由于分布在多个节点中,因此需要其他的技术将它们整合成为一个整体。分区则是数据库内部的技术,当前Oracle和MySQL 5.1后的版本都能够支持分区技术,只是分区并不是分布式技术。
2.2、Spring多数据源支持
为了更好地进行论述,这里假设我们系统中有3个数据库,在这些数据库中有一张交易表,该表建表语句如下:
create table t_transaction (
id bigint not null comment '主键,采用SnowFlake算法生成',
user_id bigint not null comment '用户编号',
product_id bigint not null comment '商品编号',
payment_channel tinyint not null
comment '交易渠道,字典:1-银行卡交易,2-微信支付,3-支付宝支付,4-其他支付',
amout decimal(10, 2) not null comment '交易金额',
quantity int not null default 1 comment '交易商品数量',
discount decimal(10, 2) not null default 0 comment '优惠金额',
trans_date timestamp not null comment '交易日期',
note varchar(512) null comment '备注',
primary key (id)
);
在学习的过程中,在单机的情况下也可以创建3个数据库实例进行模拟,我也是如此,为此分别创建了3个库:sc_chapter14_1、sc_chapter14_2和sc_chapter14_3。

然后我们引入依赖包spring-boot-starter-jdbc,这样就能加载Spring关于JDBC的类库进来了。当中有一个抽象类——AbstractRoutingDataSource,英文的翻译是抽象路由数据源。为了更好地使用它,我们进行一定的源码分析:
package org.springframework.jdbc.datasource.lookup;
/**** imports ****/
public abstract class AbstractRoutingDataSource
extends AbstractDataSource implements InitializingBean { // ①
// 目标数据源,Map类型,可支持多个数据源,通过Key决定
@Nullable
private Map<Object, Object> targetDataSources;
// 默认数据源
@Nullable
private Object defaultTargetDataSource;
// 是否支持降级
private boolean lenientFallback = true;
// 通过JNDI查找数据源
private DataSourceLookup dataSourceLookup = new JndiDataSourceLookup();
// 通过解析后的数据源(包含原始数据源和JNDI数据源)
@Nullable
private Map<Object, DataSource> resolvedDataSources;
// 默认解析后的数据源
@Nullable
private DataSource resolvedDefaultDataSource;
.......
// Spring属性初始化后调用方法
@Override
public void afterPropertiesSet() {
// 没有目标数据源设置
if (this.targetDataSources == null) {
throw new IllegalArgumentException(
"Property 'targetDataSources' is required");
}
// 解析数据源存放到resolvedDataSources 中
this.resolvedDataSources
= new HashMap<>(this.targetDataSources.size());
this.targetDataSources.forEach((key, value) -> { // ②
Object lookupKey = resolveSpecifiedLookupKey(key);
DataSource dataSource = resolveSpecifiedDataSource(value);
this.resolvedDataSources.put(lookupKey, dataSource);
});
// 如果默认的数据源为空,则进行设置
if (this.defaultTargetDataSource != null) {
this.resolvedDefaultDataSource
= resolveSpecifiedDataSource(this.defaultTargetDataSource);
}
}
// 选择具体的数据源
protected DataSource determineTargetDataSource() {
Assert.notNull(this.resolvedDataSources,
"DataSource router not initialized");
// 获取数据库的key
Object lookupKey = determineCurrentLookupKey(); // ③
// 尝试通过key得到的数据源
DataSource dataSource = this.resolvedDataSources.get(lookupKey);
// 如果为空则使用默认
if (dataSource == null && (this.lenientFallback || lookupKey == null)) {
dataSource = this.resolvedDefaultDataSource;
}
if (dataSource == null) {
throw new IllegalStateException(
"Cannot determine target DataSource for lookup key ["
+ lookupKey + "]");
}
return dataSource;
}
// 获取key的抽象方法
@Nullable
protected abstract Object determineCurrentLookupKey(); // ④
}
这个类在代码①处实现了InitializingBean接口,这就意味着IoC容器装配为Spring Bean的时候,就会调用afterPropertiesSet方法。在afterPropertiesSet方法中,它解析了目标数据源(targetDataSources,它是一个Map结构,通过key进行访问),这里的目标数据源是提供给开发者配置的,配置的方式可能是原始的JDBC配置方式,也可能是JNDI的配置方式,所以需要进行解析,然后放入到解析后的数据源(resolvedDataSources)中,并且设置默认的数据源。再看determineTargetDataSource方法,它是一个选择具体数据源的方法,这里注意,解析后的数据源(resolvedDataSources)是一个Map结构,所以依赖key进行访问。代码③处是获取key的方法,这个方法依赖代码④定义的抽象方法determineCurrentLookupKey,通过这个key,可以到解析后的数据源(resolvedDataSources)中,找对应的数据库。
2.2.1、配置多数据源
首先在application.yml中配置多个数据源所需的属性,代码如下:
jdbc:
# 数据源1
ds1:
id: '001'
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/sc_chapter14_1?serverTimezone=UTC
username: root
password: 123456
default: true
# 数据源2
ds2:
id: '002'
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/sc_chapter14_2?serverTimezone=UTC
username: root
password: 123456
# 数据源3
ds3:
id: '003'
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/sc_chapter14_3?serverTimezone=UTC
username: root
password: 123456
# 数据库连接池配置
pool:
# 最大空闲连接数
max-idle: 10
# 最大活动连接数
max-active: 50
# 最小空闲连接数
min-idle: 5
2.3、分片算法
无论是分表、分库和分区,都是将一张表的记录分隔到不同的区域存储,每个区域如同一个片区,为了让这些分散的片区能够整合成为一个整体,就需要对应的分片算法了。常见的分片算法也有多种,大体分为范围分片、哈希(Hash)分片和热点分片。哈希分片又分为求余分片和一致性哈希算法。因为范围分片的算法比较简单,并且当前使用得不多了,所以就不再介绍了。
为了更好地讨论这些算法,我们还需要分析企业实际的问题。在互联网的实践中,数据往往被划分为两大类:一类是带有用户性质的数据;另一类是不带用户性质的数据。例如,拿本书模拟的互联网金融系统来说,交易记录是带有用户性质的,因为交易是某个用户发生的业务行为,带有用户性质的数据往往是网站中最庞大最主要的,是我们分布式数据库存储的主要内容,也是我们关注的重点;另外一部分是不带用户性质的,例如产品,它和用户无关,是平台发布的数据,相对于用户数据,这部分数据会少得多。
一般来说,基于数据的特性,企业会按用户数据进行区分,并且主要以用户编号为区分依据。这里有一个最基本的原则,就是尽量把同一个用户的数据存储到同一个分片中,因为这些数据往往有一定的关系,如果可以在同一个分片访问,就可以减少跨分片访问和由此带来的资源消耗,从而提高访问性能。拿我们的例子来说,如果根据交易记录ID进行分片,那么一个用户的交易记录就有可能同时有sc_chapter14_1、sc_chapter14_2和sc_chapter14_3这3个库中,如果想组织一个整体数据展示给用户看,就需要访问3个数据库,这无疑会给系统开发带来很大的困难,同时性能也不会好。
对于那些与用户无关的数据,则需要根据其自身业务进行分析了。例如,产品微服务系统,可能就需要根据产品编号进行分片了,因为产品本身可能有许多关联业务,所以拿产品编号分片就显得更为合理一些。
2.3.1、哈希分片之求余算法
常见的哈希算法有两种,一种是求余算法,另外一种是一致性哈希算法。相对来说,求余算法很简单。
有3个库,即sc_chapter14_1、sc_chapter14_2和sc_chapter14_3。我们只需要使用userId对3进行求余,就知道要存入哪个数据库了,这个算法十分简单易行,如下图所示:
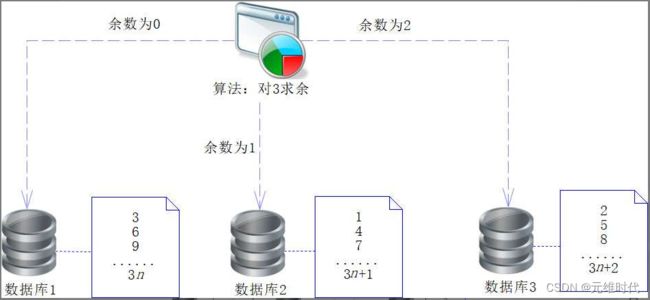
有些企业会采用这个模型,因为它简单方便,性能也很好。但是对于数据量快速增长的企业来说,采用这个模型就会有很多问题,其中最主要的就是伸缩性问题。例如,因为数据量不断膨胀,所以3个库已经不够用了,要增加1个库,从3个库变为4个库,就需要通过使用userId对4求余来决定将数据存放到哪个库。当然,这对新的用户数据没有什么影响,但是旧的用户数据就必须迁徙了。然而,所有数据库的数据都做迁徙,无疑需要大量的时间和代价,成本也较高。对于那些已经部署了数百个数据库的企业,当出现业务增长缓慢、出现资源浪费、需要为了节省成本而减少数据库的时候,也要迁徙所有的数据才能重新部署。所以这样的算法不适合那些频繁增加和减少节点的企业,为了满足业务伸缩性较大的企业的需求,有软件开发者提出了新的算法——著名的一致性哈希算法。
2.3.2、一致性哈希算法
一致性哈希算法,也称为一致性哈希算法,它是1997年麻省理工学院提出的一种算法。它首先假设一个圆由232个点构成,如下图所示:
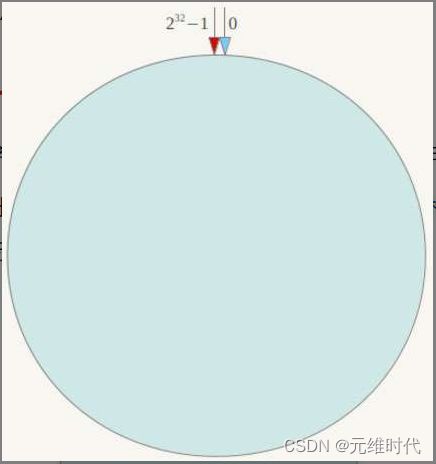
对于这个圆,我们也称为哈希环,它由232个节点组成,数值的取值范围为区间[0, 2^32 −1]。我们可以根据数据库编号或者其他标识性的属性求其哈希值(hash code),然后该值就会对应到这个哈希环上的某一点。
我们有4个库,依次编号为Node A、Node B、Node C和NodeD,它们都是我们数据库的节点。根据编号求出哈希值,就可以放到图14-5的节点中了,如下图所示:
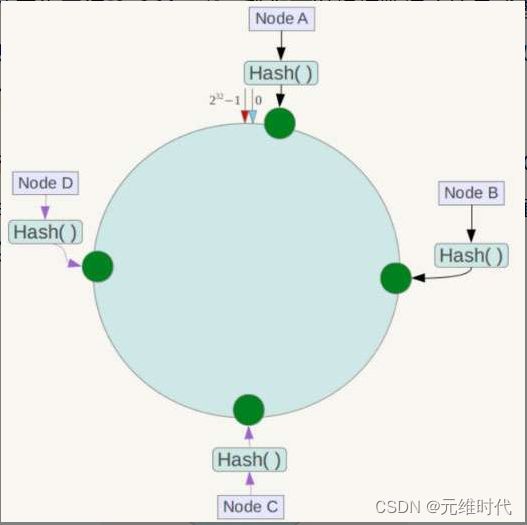
为了进行说明,这里需要进行一些假设:
- 假设Node A、Node B、Node C和NodeD这4个节点的哈希值为Hash A、Hash B、Hash C和Hash D,根据图14-6就可以得到以下5个区间:[0, Hash A]、[Hash A,Hash B]、[Hash B, Hash C]、[Hash C, Hash D]和[Hash D,
2^32−1)。 - 假设对userId也求哈希值,记为n,而n必然落入Node A、Node B、Node C和NodeD这4个节点所产生的5个区间之中。
在一致性哈希算法中,对于n,采用顺时针方向找到下一个数据库节点,用来存放该数据。为了说明这点,这里举几个例子,这些例子都紧扣上图图,所以结合该图进行阅读往往会事半功倍。例如:
Hash A < n <= Hash B
那么根据上图,按顺时针方向找到的下一个数据库节点就是Node B节点。又如:
0 <= n < Hash A
那么根据上图,按顺时针方向找到的下一个数据库节点就是Node A节点。再如:
Hash D <= n < 2^32-1
一致性哈希算法,对于伸缩性大有好处:当我们减少一个节点的时候,只需要将减少的那个节点的数据插入到顺时针的下一个节点即可;当我们新增一个节点的时候,只需要通过哈希值计算将下一个节点的部分数据分配给新增节点即可。从上述可以知道,通过一致性哈希算法,新增或者减少节点,只需要移动附近节点的数据即可,无须全局迁徙,所以一致性哈希算法非常合适那些需要经常增加和删除存储节点的应用。
2.3.3、热点数据分配法
在我们存储的数据中,80%是几乎用不到的,只有20%是常常需要访问的。对于那些常常需要访问的数据,我们称为热点数据。
假设我们采用了一致性哈希分片算法,有3个库,即库1、库2和库3。3个库的数据分配得比较平均,但是80%的热点数据在库1中。这样就会导致库1比较繁忙,库2和库3比较清闲,在高并发下,库1就可能因为超负荷工作而瘫痪。这是因为数据虽然平均分配了,但是热点数据分配不平均。为了解决这个问题,一些开发者提出了按热点分配的方法,最理想的情况是,热点数据能够比较平均地分配到各个库中,这样在负荷上分配就比较平均了,整个系统性能也会得到显著提升。
在实际中,数据是跟着用户走的,换句话说,操作越多的用户越需要我们关注,这些用户的数据往往就是热点数据,从这层关系来说,热点数据的分配也可以理解为区分热点用户。这些数据往往是无规则的,需要我们存储映射关系才能弄清它们之间的关系。为此,可以在一个公共的数据库上创建一张映射表,通过它来区分热点数据和非热点数据,并且记录哪个用户分配到了哪个数据库节点上,如下图所示:
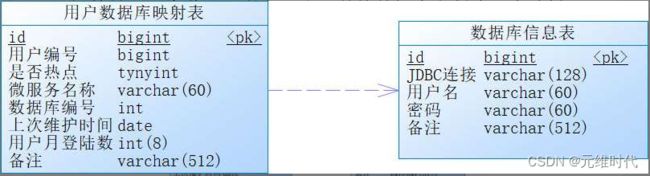
看左边的用户数据库映射表(下文简称映射表),下面谈谈这张表的一些重要字段的含义:
- 是否热点:用于标识该用户数据是否为我们的热点数据。
- 微服务名称:说明可以根据微服务查找对应的数据库,毕竟微服务是推荐使用独立数据库的。
- 数据库编号:可通过这个编号找到对应的数据库。
- 上次维护日期:维护这条记录的最近日期。
- 用户月登录数:用户在当前月登录过系统的次数,通过这个次数,就可以知道用户是否经常访问系统。对于频繁访问的用户,它的数据往往就是热点数据了。当然,这只是其中一种区分热点数据的方法,只是为了举例,在实践中,也可以根据自己的业务规则来决定如何区分热点数据。
但是,如果需要每次读写映射表,就会造成系统性能的缓慢,为此我们可以考虑在公共服务系统启动的时候,将用户数据库映射表的数据读入到缓存服务器中。当我们访问时,从Redis中读取映射关系,显然,这样就可以大幅度地提高性能了,如下图所示:
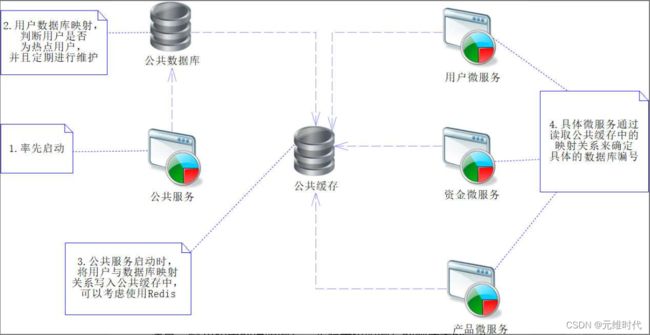
注意,上图中的说明编号,步骤是按照编号的顺序来的。实际上,用户月登录数可以只写入Redis,而不与数据库同步,因为这不是业务数据,并不会影响正常业务的逻辑,但这是判断用户是否为热点用户的依据。之后,每当月末时,通过判断登录次数,决定该用户的数据是否为热点数据,然后将这些热点数据通过数据迁徙的方式,平均分配到各个数据库中,这样,热点数据就被平均分配到各个数据库中了,每个数据库的负荷就相对平均了,系统性能也会比较理想。但是别忘了,在迁徙数据的同时,也需要维护映射表和Redis缓存的数据,这样微服务系统才能够重新从Redis读写最新的映射关系。
热点分配法可以按照一个时间间隔,通过迁徙热点数据的方式,使各个数据库节点的负荷尽可能平衡,从而优化系统性能,减少可能出现的一个数据库繁忙、其他数据库空闲的情况。不过,它需要引入映射表和缓存等机制,这无疑会使算法复杂化,也会加大维护成本。
2.4、分片中间件ShardingSphere
ShardingSphere是Apache基金会下的一个孵化项目,它是由一套开源的分布式数据库中间件解决方案组成的生态圈,主要关注数据分片、分布式事务和数据库协调。它的前身是Sharding JDBC,Sharding JDBC是当当网发布的一款分布式数据库中间件,该中间件在发布后,获得了广泛的使用,在业界很流行。因为Sharding JDBC很成功,所以ShardingSphere就将其纳入进来成为其孵化项目之一。
2.4.1、概述
ShardingSphere主要由以下3个产品构成。
- Sharding-JDBC:它的定位为一种轻量级框架,基于传统的JDBC层,并且在此基础上提供了额外的服务,所以他能够兼容其他的Java数据库技术,例如,连接池和ORM框架(如Hibernate和MyBatis等)。当前能够支持MySQL、Oracle、SQLServer和PostgreSQL。
- Sharding-Proxy:它的定位为透明化的数据库代理端,提供封装数据库二进制协议的服务端版本,目前最先提供的是MySQL版本,它可以使用任何兼容MySQL的协议访问客户端(如MySQL Command Client、MySQL Workbench等)操作数据。因为可以代理分布式数据库,所以它对数据库管理员(DBA)会更友好。
- Sharding-Sidecar:这是目前没有发布的组件,它的定位为Kubernetes或Mesos的云原生数据库代理,以DaemonSet的形式代理所有对数据库的访问,它属于新一代网格数据库。
2.4.2、ShardingSphere的重要概念
ShardingSphere是一个能够支持分片和分库的轻量级框架,在使用它之前,需要了解它的一些重要概念。
- 逻辑表:分表技术是将一个原本存储大量数据的表拆分为具有相同字段但表名不同的一系列表,我们把这一系列表统称为逻辑表。例如,当我们把产品表拆分为表t_product_1、t_product_2、t_product_3……时,把表t_product_1、t_product_2、t_product_3……统称为表t_product,它是一个逻辑概念,不是一个真实存在的表。
- 真实表:是指在数据库中真实存在的表,例如,逻辑表概念中谈到的表t_product_1、t_product_2、t_product_3……这些就是真实表,它真实地存在于数据库中。
- 数据节点:它是ShardingSphere拆分的最小分片单位,它会定位到具体的某个数据库的某张真实表,格式为ds_name.t_product_x,其中ds_name为数据库名称,t_product_x为真实表的名称。
- 绑定表:指分片规则下的主表和子表,这个概念有点复杂,后面再解释它。
上面谈及的绑定表的概念,理解起来可能有一些困难,这里再说明一下。在数据库中,有主表和从表的概念,例如,我们说产品表(t_product)是主表,销售表(t_sales)是从表,因为从表是基于主表派生出来的。在正常情况下,查询真的主从表数据时,使用的SQL应该是:
select p.*, s.* from t_product p join t_sales s on p.id = s.product_id where p.id in (#{productId1}, #{productId2})
我们采用分表技术之后,查询起来就不那么容易了。假设这里将产品表拆分为表t_product_0和t_product_1,同时把销售表拆分为表t_salses_0和t_salses_1,那么上述的SQL就会被ShardingSphere翻译为以下4条SQL:
select p.*, s.* from t_product_0 p join t_sales_0 s on p.id = s.product_id where p.id in (#{productId1}, #{productId2});
select p.*, s.* from t_product_0 p join t_sales_1 s on p.id = s.product_id where p.id in (#{productId1}, #{productId2});
select p.*, s.* from t_product_1 p join t_sales_0 s on p.id = s.product_id where p.id in (#{productId1}, #{productId2});
select p.*, s.* from t_product_1 p join t_sales_1 s on p.id = s.product_id where p.id in (#{productId1}, #{productId2});
这便呈现出了笛卡儿积的关联概念,而绑定表的作用是对数据进行限制,例如,主从表的数据会限制为:如果将产品保存在表t_product_0内,那么从表数据也会保存在t_sales_0内。这样就可以避免笛卡儿积的关联,数据分布就不会杂乱无章了。通过绑定之后,ShardingSphere会将原来的SQL翻译为:
select p.*, s.* from t_product_0 p join t_sales_0 s on p.id = s.product_id where p.id in (#{productId1}, #{productId2});
select p.*, s.* from t_product_1 p join t_sales_1 s on p.id = s.product_id where p.id in (#{productId1}, #{productId2});
这样就避免了数据的复杂分布和SQL的复杂度,性能也会大大提高。
这4个ShardingSphere的核心概念就介绍到这里了,在实际运用中,还是建议少使用分表技术,因为它会带来很多的不便利,引发后续开发的困难。在有条件的情况下,可以使用分库技术,在后续的开发中会相对简单许多,在做主从表时,不会出现笛卡儿积关联等问题,性能会有大幅度的提高。
2.4.3、 ShardingSphere的分片
如果说ShardingSphere的概念是基础的话,那么分片就是其核心内容了。在ShardingSphere中存在分片键、分片算法和分片策略3种概念,这些都是我们需要研究的内容。
1、分片键
分片键是指以表的什么字段进行分片。例如,之前我们使用用户编号(user_id)进行分片,那么user_id就是分片键。ShardingSphere还能支持多个字段的分片。
2、分片算法
分片算法是我们的核心内容,在ShardingSphere中,定义了ShardingAlgorithm接口作为其底层接口,在此基础上,还定义了几个子接口,如下图所示:
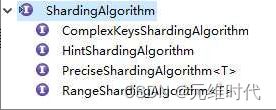
可以看出,ShardingSphere提供了以下4种分片的子接口:
- PreciseShardingAlgorithm:精确分片策略,主要支持SQL中的“=”和“IN”。
- RangeShardingAlgorithm:范围分片策略,主要支持SQL中的“BETWEEN…AND…”。
- ComplexKeysShardingAlgorithm:复合分片,可以支持多分片键,但是需要自己实现分片算法。
- HintShardingAlgorithm:如果非SQL解析方式进行分片的,可以实现这个接口,自定义自己的分片算法,如使用映射表的方式。
它们都是接口,没有实现类,为了更好地使用它们,ShardingSphere采用了策略(Strategy)模式,这便是下面要谈到的分片策略。
3、分片策略
在上面,我们讨论了分片算法(ShardingAlgorithm),但是它们都只是定义接口,并无具体的实现。ShardingSphere的分片是通过策略接口ShardingStrategy来实现的,并且基于这个接口,它还提供了5个实现类,我们可以根据自己的业务需要来选择具体的分片策略,如下图所示:
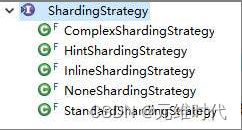
可以看到,分片策略分为以下5种:
- StandardShardingStrategy:标准分片策略。它只支持单分片键,不支持多分片键。它内含两种分片算法,即精确分片(PreciseShardingAlgorithm)和范围分片(RangeShardingAlgorithm)。
- ComplexShardingStrategy:复合分片策略。它能支持多分片键,但是你需要自己编写分片逻辑。
- HintShardingStrategy:提示分片策略。如果不依赖SQL层面的分片策略,你需要根据自己的业务规则进行编写分片策略。
- InlineShardingStrategy:行表达式分片策略。它主要支持那些简单进行分片的策略。例如,如果产品表分为t_product_0和t_product_1,那么可以写作t+prodcut$->{id % 2},表示按照产品编号(id)对2取模,进行分片。
- NoneShardingStrategy:不分片策略。它将返回所有可选择的数据库名或者表名。
4、总结
ShardingSphere是基于当当网开发的开源框架Sharding-JDBC开发的,能够支持数据库的分片技术,但是它还不能支持以下SQL语句:
- HAVING语句。
- UNION和UNION ALL语句。
- OR语句。
- DISTINCT语句。
- 嵌套的SELECT语句。
除此之外,还不能支持同时插入多条记录,例如不能写成:
insert into t_table (id, name, note) values(1, 'name_1', 'note_1'),(1, 'name_2', 'note_2')
简单地讲,它的功能是受限的,所以需要注意使用它的场合。此外,它在联机分析处理(OLAP)方面,性能不佳,所以需要进行分布式统计分析的,不建议使用ShardingSphere。
3、 分布式数据库事务
在互联网的世界中,有些数据对一致性的要求是十分苛刻的,如商品的库存和用户的账户资金,而这些却极有可能分别存储在不同的数据库节点中,那么如何在多个数据库节点中保证这些数据的一致性,就是分布式数据库事务要解决的问题。
分布式数据库事务比单机数据库事务要复杂得多,它涉及多个数据库节点之间的协作。BASE理论,在分布式数据库中,存在强一致性和弱一致性。所谓强一致性是指任何多个后续线程或者其他节点的访问都会返回最新值。弱一致性是指当用户对数据完成更新操作后,并不保证在后续线程或者其他节点马上访问到最新值,它只是通过某种方法来保证最后的一致性。强一致性的好处是,对于开发者来说比较友好,数据始终可以读取到最新值,但这种方式需要复杂的协议,并且需要牺牲很多的性能。弱一致性,对于开发者来说相对没有那么友好,无法保证读取的值是最新的,但是不需要引入复杂的协议,也不需要牺牲很多的性能。事实上,在发生一定的不一致的情况下,我们可以采取多种方式进行补救,用户的快速体验,往往比保证强一致性重要,所以在当今互联网的开发中,弱一致性占据了主导地位。而从微服务的角度来说,强一致性是不符合微服务的设计理念的。
3.1、强一致性事务
现今流行的强一致性事务,主要有两种实现方式:第一种是两阶段提交协议;第二种是为了克服两阶段提交协议的一些缺陷,衍生出来的三阶段提交协议。为了解释两阶段和三阶段的概念,我们先从单机数据库事务开始讲述,首先看下图:

从上图中可以看出,单机数据库事务只需要对数据库发送提交或者回滚命令就能操作数据库,一个阶段就能完成,无须外界干预。这样的单机数据库事务应该说是简单易用的,但是放到分布式数据库就不一样了。分布式数据库比单机数据库要复杂得多,首先它是多个节点的协作,其次网络有不可靠性。为了说明分布式数据库事务的复杂性,看下图:

在上图中,由于应用系统需要访问两个数据库,而两个数据库之间并无关联关系,因此无法感知另一个数据库的状态,从而无法保证数据的一致性。如果我们引入对应的通信机制,就需要进行一些协议约定,但实际上,通信机制也不是绝对可靠的,因为通信机制依赖的网络不是绝对可靠的。
为了解决这些问题,Tuxedo(分布式操作扩展之后的Unix事务系统)首先提出了著名的分布式协议——XA协议,跟着The Open Group(它的建立是为了向UNIX环境提供标准)将其确认为处理分布式事务的规范。但是XA协议也有很大的弊端,为了克服这些弊端,衍生出了三阶段提交协议,这就是我们下面需要学习的内容。不过需要需要注意以下两点:
- 在微服务系统中,不适合使用这样的强一致性事务。
- 即使使用强一致性,也可能出现低概率的数据不一致的情况,依然需要使用其他机制保证所有数据的一致性。
3.1.2、两阶段提交协议——XA协议
XA协议是一种两阶段提交协议(Two-Phase Commit,2PC),它分两个阶段来完成分布式事务。在XA协议中,首先会引入一个中间件,叫作事务管理器,它是一个协调者。独立数据库的事务管理器称为本地资源管理器。为了更好地解释XA协议的原理,先看下图:
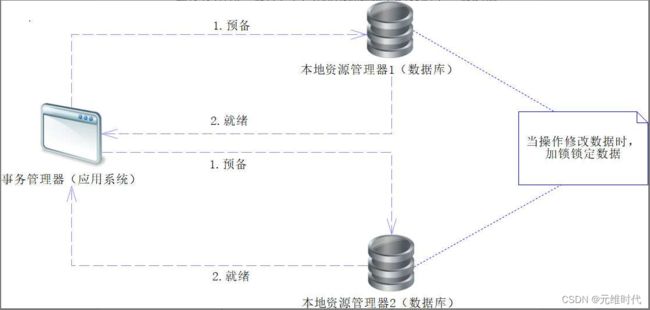
上图所展示的是XA协议的第一阶段,下面让我们来分析它执行的步骤:
- 应用系统使用事务管理器,首先将数据发送给需要操作的分布式数据库,并且给予预备命令。
- 当分布式数据库得到数据和预备命令后,对数据进行锁定(MySQL和Oracle都会将事务隔离级别设置为Serializable——序列化),保证数据不会被其他事务干扰。
- 在本地资源管理器做好上一步后,对事务管理器提交就绪信息。
在XA协议中,任何一步都依赖上一步的成功,于是就有3种可能:当事务管理器接收到所有数据库的本地资源管理器所发送的就绪信息后,执行第二阶段的操作;当事务管理器没有接收到所有数据库的就绪信息时,它会等待,直至收到所有数据库的就绪信息为止;当然等到的消息也有可能是某个数据库操作失败,这个时候事务管理器会通知其他数据库进行回滚,从而保证所有数据都不会被修改。
一般来说,在本地资源管理器发出就绪命令之前,数据库就会预执行SQL,这样能够最大限度地保证事务提交的可能性,后续阶段的提交成功率会十分高,基本不会失败。在正常情况下,事务管理器可以得到所有数据库提交的就绪信息,能继续发起第二阶段的命令,也就是提交命令,如下图所示:
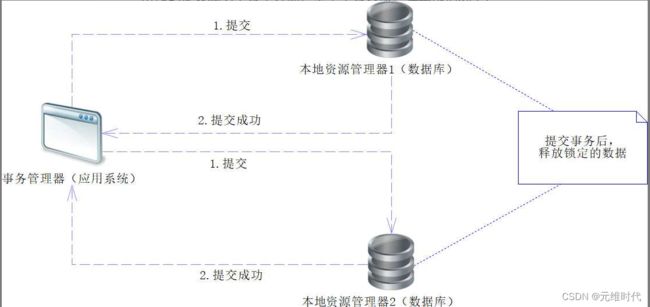
上图展示的就是XA协议第二个阶段提交的过程,下面再用文字描述一下:
- 当事务管理器接收到XA协议第一阶段得到的所有数据库的就绪信息后,就会对所有数据库发送提交的命令。
- 当各个本地资源管理器接收到提交的命令时,就会将在XA协议第一阶段锁定的数据进行提交,然后释放锁定的数据。
- 当做完上一步后,本地资源管理器就会对事务管理器发送提交成功的信息,表明数据已经操作成功了。
做完第二阶段的提交,所有数据都会被提交到各自的数据库中,各个数据库的数据就会保持一致性。
为了支持XA协议,Java方面定义了JTA(Java Transaction API)规范,和JDBC一样,JTA只是一个规范,它需要具体的数据库厂商进行实现,这是一种典型的桥接模式。在JTA中,定义了接口XAConnection和XADataSource,这两个接口的实现需要具体的数据库厂商提供。在MySQL中,5.0以后的版本才开始支持XA协议,因此在MySQL中使用JTA,需要使用MySQL 5.0以后的版本。MySQL中提供了XAConnection和XADataSource两个接口的具体实现类,因而支持XA协议。为了更好地支持分布式事务,一些开源框架也提供了很好的支持,其中以Atomikos、Bitronix和Narayana最为出名。当今评价最高、使用较广泛的是Atomikos,所以这里选它来实现分布式事务。
3.1.3、 三阶段提交协议
为了解决两阶段提交协议带来的网络问题造成的不一致,还有更为严重的死锁问题,在两阶段提交协议的基础上,一些工程师提出了三阶段提交协议(Three-Phase Commit,3PC)。该协议实现比较复杂,当前还不是主流技术,因此这里就不展示代码了,只讨论其原理。事实上,三阶段提交协议是在两阶段提交协议的基础上演变出来的,它只是增加了询问和超时的功能。询问功能是指在执行XA协议之前,对数据库连接和资源进行验证。超时功能是指数据库在执行XA协议的过程中锁定的资源,在超过一个时间戳后,会自动释放锁,避免死锁。具体的时序如下图所示:
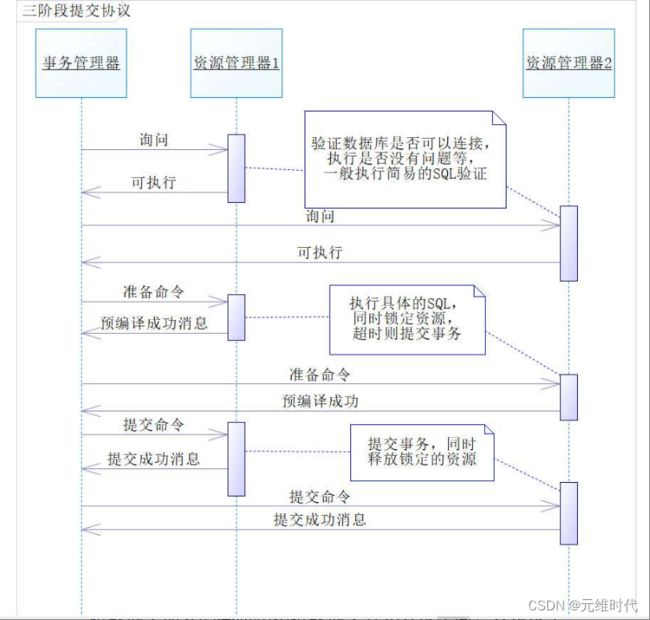
三阶段提交命令的本质和两阶段提交并无太多不同,只是多了以下两点:
- 增加询问阶段:在执行两阶段前做一些询问和验证,如验证连接数据库是否成功,可通过执行简易查询SQL是否成功进行验证,如果成功了,就继续执行,如果没成功,则中断执行,这样就能在大大提升成功率的同时,减少出错的可能性。
- 增加超时机制:其次,在执行XA协议的过程中,如果事务执行超时,则提交事务。这里也许有读者会问:为什么不是回滚事务呢?那是因为互联网的大量实践经验表明,在大部分情况下,提交事务的合理性要远远超过回滚事务。这样操作的好处在于,可以防止数据库锁定资源,导致系统出现的死锁问题。
无论是两阶段提交协议,还是三阶段提交协议,当前都不是企业保证一致性的主流技术了,原因大体有两个。第一,它们的实现相对来说比较复杂,日后维护和运维起来都比较困难。第二,使用了大量锁技术,在高并发的情况下,会造成大量的阻塞,导致用户体验不佳,影响用户的忠诚度。因此,两阶段和三阶段提交协议就都渐渐地没落了,取代它们的是弱一致性事务的技术。
3.2、弱一致性事务
弱一致性是指当用户对数据完成更新操作后,并不保证后续线程或者其他节点能马上访问到最新值,一致性由后续操作保证。弱一致性的好处是,各个服务实例的操作可以在无锁的情况下进行,性能上没有损失,能迎合高并发的要求,实现起来也相对简单和灵活。
关于弱一致性事务,我们需要再次回到BASE理论的3个概念:基本可用(BA)、软状态(S)和最终一致性(E)。对于分布式来说,首先要保证的是基本可用,也就是能尽快反馈给用户。软状态是指在一个时间段内,有些数据可能不一致。最终一致性是指对于那些处于软状态的数据,系统采取一定的措施使得数据达到最终一致性。弱一致性事务和强一致性事务的不同在于,强一致性事务基于数据库本身的层面,而弱一致性则基于应用的层面。也就是说,强一致性使用的是数据库本身提供的协议或者机制来实现,如XA协议;而弱一致性则需要自己在应用中处理,使用一定的手段保持数据的一致性。
一般来说,弱一致性会“尽可能”保证事务的一致性,但不能绝对保证,也就是说,使用弱一致性事务后,虽然数据可能会存在不一致的情况,但是不一致的情况会大大减少。弱一致性的方法很多,也没有固定的模式,常见的方法有状态表、可靠事件、补偿性事务和其衍生的TCC(Try Confirm Cancel)模式等。但是无论使用何种模式,都不能保证所有的数据都达到一致性,为了达到完全的一致性,一些企业还会有事后对账的机制。例如,选择某个时间点——日结时刻,通过对账的形式来发现不一致的地方,然后通过补救措施使数据达到一致。因为采用了弱一致性,不一致性的情况会大大减少,所以一般来说,不一致性的数据也不会太多,运维和业务人员的工作量也会大大降低。和强一致性事务一样,弱一致性事务也无法保证绝对一致性,但是能够尽可能地大幅度降低数据的不一致性,使得运维和业务人员后续的工作量能够不断减少。
3.2.1、使用状态表
使用状态表的方式,可以避免强一致性事务的锁机制,使得各个系统在无锁的情况下执行。其弊端是需要借用第三方(例如Redis)。
请注意,使用状态表也不能完全消除不一致性,只是提供了一种修复的手段,尽可能保证数据的一致性,后续还可以通过事后比对数据的方式进行补救。
3.2.2、使用可靠消息源——RabbitMQ
请注意,这样的确认方式,只是保证了事件的有效传递,但是不能保证消费类能够没有异常或者错误发生,当消费类有异常或错误发生时,数据依旧会存在不一致的情况。这样的方式,只是保证了消息传递的有效性,降低了不一致的可能性,从而大大降低了后续需要运维和业务人员处理的不一致数据的数量。
3.2.3、提高尝试次数和幂等性
在分布式系统中,我们无法保证消息能正常传递给服务提供者,如果可以尝试数次,那么消息不能传达的概率就会大大降低,从而降低数据的不一致性。但是使用多次尝试也会带来一个问题——需要防止多次尝试调用造成的数据不一致,这便是我们需要谈的幂等性。所谓幂等性,是指在HTTP协议中,一次和多次请求某一个资源,对于资源本身应该具有同样的结果,也就是其执行任意多次时,对资源本身所产生的影响,与执行一次时的相同。
应该说,实现幂等性的方法很多,加锁、防止重复表等,但是这里不谈这些,这里只谈最简单、最普遍的方式——SQL方式。回到这里的例子,因为在我们调用资金服务的时候,会传递流水号(xid)过来,所以这里考虑使用它来完成幂等性。在扣减账户资金的时候,我们可以根据流水号来增加一个判断条件来防止重复。例如,下面的SQL:
/* 假设t_account为账户表,t_transaction_details为账户交易明细表 */
/* 根据用户编号(#{userId})更新扣减账户资金(#{amount}) */
update t_account a set a.balance= a.balance -#{amount} where a.user_id = #{userId}
/* 判定交易明细不存在相同流水号(#{id}),也就是没有扣款成功过 */
and not exists (selelect * from t_transaction_details d where d.xid = #{xid});
注意这里的not exists语句,通过它可以判断对应的流水号有没有被操作过,如果有,就不再执行扣减账户资金的操作了。通过执行这条SQL语句返回的影响条数,就可以决定是否往账户交易明细表插入新的数据了。通过这样的方法,就能够防止多次重试造成数据不一致的错误了。
3.2.4、 TCC补偿事务
TCC是try(尝试)、confirm(确认)和cancel(取消)这3个英文单词首字母组成的简写。之所以这样,是因为在TCC事务中,要求任何一个服务逻辑都有3个接口,它们对应的就是尝试(try)方法、确认(confirm)方法和取消(cancel)方法。然后按照一定的流程来完成业务逻辑,如下图所示:
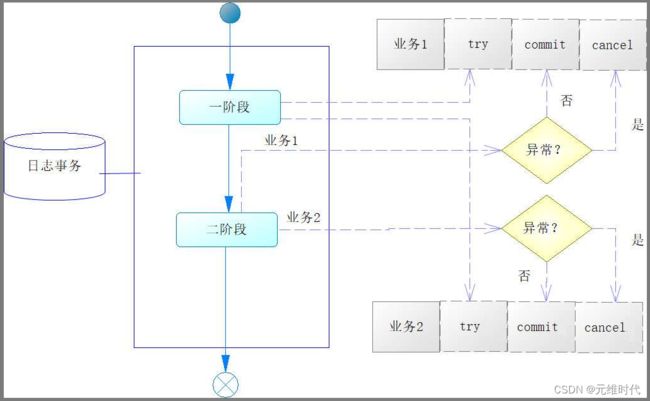
一些企业的实践数据表明,TCC事务的一致性可达99.99%,是一种较为成熟的方案,因此在目前有着较为广泛的应用。
3.2.5、 总结
弱一致性是当今企业采用的主流方案,它并不能保证所有数据的实时一致性,所以有时候实时读取数据是不可信的。它只是在正常的流程中,加入了提供修复数据的可能性,从而减少数据不一致的可能性,大大降低数据不一致的可能性。上述的几种方法,也体现了这样的设计思路。实际上,开发者也可以根据自己的需要来实现弱一致性事务,因为同一个设计思路的实现方法并不是唯一的,甚至是多样性的,完全可以根据自己的需要来实现它,以满足企业的实际需要。
4、分布式缓存——Redis
分布式系统要解决的是高并发、大数量和快速响应的问题。事实上,在互联网中,大部分的业务还是以查询数据为主,而非更改数据为主。在互联网出现高并发的时刻,查询关系数据库,会造成关系数据库的压力增大,容易导致系统宕机的严重后果。为了解决这个问题,一些开发者提出了数据缓存技术,数据缓存和关系数据库最大的不同在于,缓存的数据是保存在计算机内存上的,而关系数据库的数据主要保存在磁盘上。
使用缓存技术最大的问题是数据的一致性问题,缓存中存储的数据是关系数据库中数据的副本,因为缓存机制与数据库机制不同,所以它们的数据未必是同步的。虽然我们可以使用弱一致性去同步数据,但是现实很少会那么做,因为在互联网系统中,往往查询是可以允许部分数据不实时的,甚至是失真的,例如,一件商品的真实库存是100件,而现在显示是99件,这并不会妨碍用户继续购买。如果使用弱一致性,一方面会造成性能损失,另外一方面也会造成开发者工作量的大量增加。
缓存技术可以极大提升读写数据的速度,但是也有弊端。缓存技术是基于内存的,内存的大小要比磁盘小得多,同时成本也比磁盘高得多。因此缓存太大会浪费资源,过小,则在面临高并发的时候,可能会被快速填满,从而导致内存溢出、缓存服务失败,进而引发一系列的严重问题。
在一般情况下,单服务器缓存已经很难满足分布式系统大数量的要求,因为单服务器的内存空间是有限的,所以当前也会使用分布式缓存来应对。分布式缓存的分片算法和分布式数据库系统的算法大同小异。一般情况下,缓存技术使用起来比关系数据库简单,因为分布式数据库还会有事务和协议,而缓存数据一般不要求一致性,数据类型也远不如关系数据库丰富。缓存数据的用途大多是查询,查询和更新不同,对实时性没有那么高的要求,允许有一定的失真,这就给性能的优化带来了更大的空间。
当然相对关系数据库来说,缓存技术速度更快,正常来说,使用Redis的速度会是使用MySQL的几倍到十几倍。可见缓存能极大地优化分布式系统的性能,但是并不是说缓存可以代替关系数据库。首先,缓存主要基于内存的形式存储数据,而关系数据库主要是基于磁盘;内存空间相对有限,价格相对较高,而磁盘空间相对较大,价格相对较低。其次,内存一旦失去电源,数据就会丢失。虽然Redis提供了快照(RDB)和记录追加写命令(AOF)这两种形式进行持久化,但是机制相对简单,难以保证数据不丢失。关系数据库则有其完整的理论和实现,能够有效使用事务和其他机制保证数据的完整性和一致性。因此,当前用缓存技术代替关系数据库技术是不太现实的,但是可以使用缓存技术来实现网站常见的数据查询,这能大幅度地提升性能。
一般来说,适合使用缓存的场景包含以下几种:
- 大部分是读业务数据的系统(一般互联网系统都满足该条件)。
- 需要快速响应的系统。
- 需要预备数据(在系统或者某项业务前准备那些经常访问的数据到缓存中,以便于系统开始就能够快速响应,也称为预热数据)的系统。
- 对数据安全和一致性要求不太严格的系统。
不适合使用缓存的场景:
- 读业务数据少且写入频繁的系统。
- 对数据安全和一致性有严格要求的系统。
在使用缓存前,我会从3个方面进行考虑:
- 业务数据常用吗?后续命中率如何?命中率很低的数据,没有必要写入缓存。
- 该业务数据是读的多还是写的多,如果是写的多,需要频繁写入关系数据库,也没有必要使用缓存。
- 业务数据大小如何?如果要存储很庞大的内容,就会给缓存系统带来很大的压力,有没有必要?能截取最有价值的部分进行缓存而不全部缓存吗?
4.1、Redis的高可用
在Redis中,缓存的高可用分两种,一种是哨兵,另外一种是集群。
4.1.1、 哨兵模式
在Redis的服务中,可以有多台服务器,还可以配置主从服务器,通过配置使得从机能够从主机同步数据。在这种配置下,当主Redis服务器出现故障时,只需要执行故障切换(failover)即可,也就是作废当前出故障的主Redis服务器,将从Redis服务器切换为主Redis服务器即可。这个过程可以由人工完成,也可以由程序完成,如果由人工完成,则需要增加人力成本,且容易产生人工错误,还会造成一段时间的程序不可用,所以一般来说,我们会选择使用程序完成。这个程序就是我们所说的哨兵(sentinel),哨兵是一个程序进程,它运行于系统中,通过发送命令去检测各个Redis服务器(包括主从Redis服务器),如下图所示:
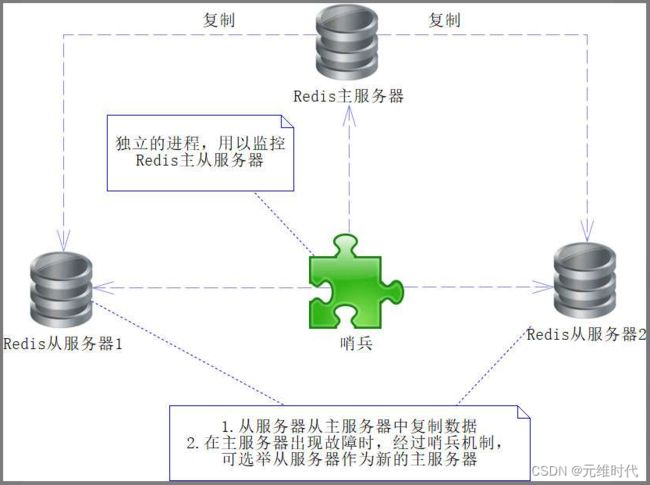
图中有2个Redis从服务器,它们会通过复制Redis主服务器的数据来完成同步。此外还有一个哨兵进程,它会通过发送命令来监测各个Redis主从服务器是否可用。当主服务器出现故障不可用时,哨兵监测到这个故障后,就会启动故障切换机制,作废当前故障的主Redis服务器,将其中的一台Redis从服务器修改为主服务器,然后将这个消息发给各个从服务器,使得它们也能做出对应的修改,这样就可以保证系统继续正常工作了。通过这段论述大家可以看出,哨兵进程实际就是代替人工,保证Redis的高可用,使得系统更加健壮。
然而有时候单个哨兵也可能不太可靠,因为哨兵本身也可能出现故障,所以Redis还提供了多哨兵模式。多哨兵模式可以有效地防止单哨兵不可用的情况,如下图所示:
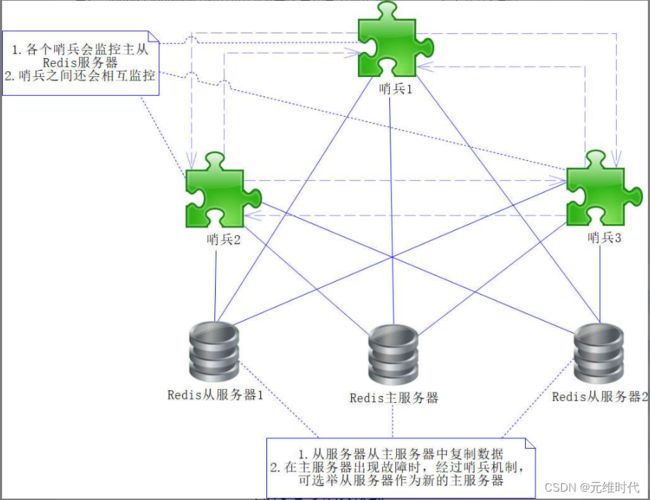
在上图中,多个哨兵会相互监控,使得哨兵模式更为健壮,在这个机制中,即使某个哨兵出现故障不可用,其他哨兵也会监测整个Redis主从服务器,使得服务依旧可用。不过,故障切换方式和单哨兵模式的完全不同,这里我们通过假设举例进行说明。假设Redis主服务器不可用,哨兵1首先监测到了这个情况,这个时候哨兵1不会立即进行故障切换,而是仅仅自己认为主服务器不可用而已,这个过程被称为主观下线。因为Redis主服务器不可用,跟着后续的哨兵(如哨兵2和3)也会监测到这个情况,所以它们也会做主观下线的操作。如果哨兵的主观下线达到了一定的数量,各个哨兵就会发起一次投票,选举出新的Redis主服务器,然后将原来故障的主服务器作废,将新的主服务器的信息发送给各个从Redis服务器做调整,这个时候就能顺利地切换到可用的Redis服务器,保证系统持续可用了,这个过程被称为客观下线。
4.1.2、 Redis集群
除了可以使用哨兵模式外,还可以使用Redis集群(cluster)技术来实现高可用,不过Redis集群是3.0版本之后才提供的,所以在使用集群前,请注意你的Redis版本。不过在学习Redis集群前,我们需要了解哈希槽(slot)的概念,为此先看下图:
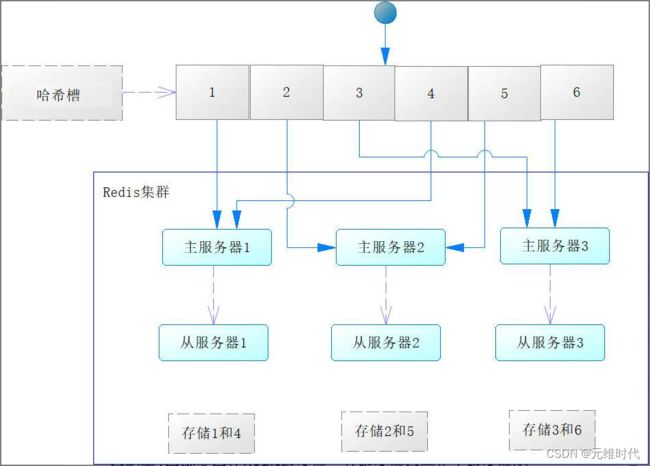
图中有整数1~6的图形为一个哈希槽,哈希槽中的数字决定了数据将发送到哪台主Redis服务器进行存储。每台主服务器会配置1台到多台从Redis服务器,从服务器会同步主服务器的数据。那么它的工作机制是什么样的呢?下面我们来进行解释。
Redis是一个key-value缓存,假如计算key的哈希值,得到一个整数,记为hashcode。如果此时执行:n = hashcode % 6 + 1得到的n就是一个1到6之间的整数,然后通过哈希槽就能找到对应的服务器。例如,n=4时就会找到主服务器1的Redis服务器,而从服务器1就是其从服务器,会对数据进行同步。
在Redis集群中,大体也是通过相同的机制定位服务器的,只是Redis集群的哈希槽大小为(2^14=16384),也就是取值范围为区间[0, 16383],最多能够支持16384个节点,Redis设计师认为这个节点数已经足够了。对于key,Redis集群会采用CRC16算法计算key的哈希值,关于CRC16算法,本书就不论述了,感兴趣的读者可以自行查阅其他资料进行了解。当计算出key的哈希值(记为hashcode)后,通过对16384求余就可以得到结果(记为n),根据它来寻找哈希槽,就可以找到对应的Redis服务器进行存储了。它们的计算公式为:
# key为Redis的键,通过CRC16算法求哈希值
hashcode = CRC16(key);
# 求余得到哈希槽中的数字,从而找到对应的Redis服务器
n = hashcode % 16384
这样n就会落入Redis集群哈希槽的区间[0, 16383]内,从而进一步找到数据。下面举例进行说明,如下图所示:
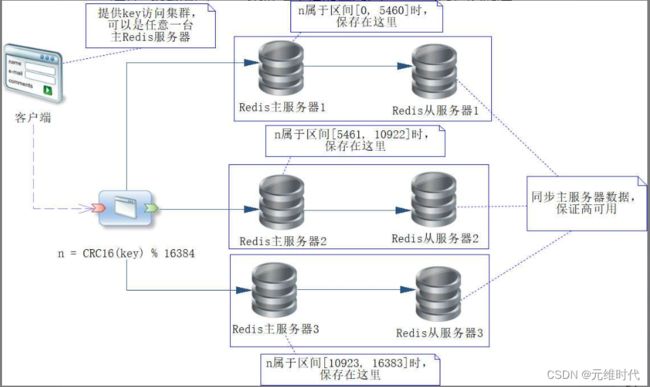
这里假设有3个Redis主服务器(或者称为节点),用来存储缓存的数据,每一个主服务器都有一个从服务器,用来复制主服务器的数据,保证高可用。其中哈希槽分配如下:
- Redis主服务器1:分配哈希槽区间为[0, 5460]。
- Redis主服务器2:分配哈希槽区间为[5461, 10922]。
- Redis主服务器3:分配哈希槽区间为[10923, 16383]。
这样通过CRC16算法求出key的哈希值,再对16384求余数,就知道n会落入哪个哈希槽里,进而决定数据存储在哪个Redis主服务器上。
注意,集群中各个Redis服务器不是隔绝的,而是相互连通的,采用的是PING-PONG机制,内部使用了二进制协议优化传输速度和带宽,如下图所示:
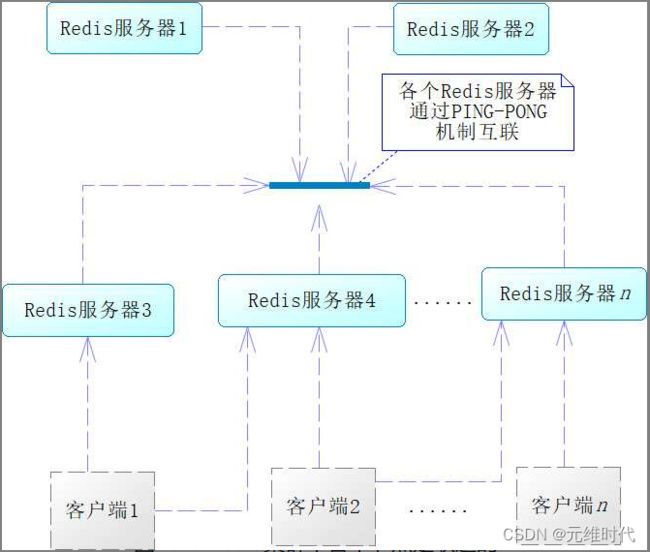
从上图中可以看出,客户端与Redis节点是直连的,不需要中间代理层,并且不需要连接集群所有节点,只需连接集群中任何一个可用节点即可。在Redis集群中,要判定某个主节点不可用,需要各个主节点进行投票,如果半数以上主节点认为该节点不可用,该节点就会从集群中被剔除,然后由其从节点代替,这样就可以容错了。因为这个投票机制需要半数以上,所以一般来说,要求节点数大于3,且为单数。因为如果是双数,如4,投票结果可能会为2:2,就会陷入僵局,不利于这个机制的执行。
在某些情况下,Redis集群会不可用,当集群不可用时,所有对集群的操作做都不可用。那么什么时候集群不可用呢?一般来说,分为两种情况:
- 如果某个主节点被认为不可用,并且没有从节点可以代替它,那么就构建不成哈希槽区间[0, 16383],此时集群将不可用。
- 如果原有半数以上的主节点发生故障,那么无论是否存在可代替的从节点,都认为该集群不可用。
Redis集群是不保证数据一致性的,这也就意味着,它可能存在一定概率的数据丢失现象,所以更多地使用它作为缓存,会更加合理。
4.2、使用一致性哈希(ShardedJedis)
集群实际包含了高可用,也包含了缓存分片两个功能。但是对于集群来说,分片算法是固定且不透明的,可能会因为某种原因使得多数的数据,落入同一个Redis服务中,使负荷不同。有时候,我们还希望使用一致性哈希算法,关于该算法,在分布式数据库分片算法中也进行了详尽的介绍,所以这里就不再重复了。在Jedis中还提供了类ShardedJedis,有了这个类,我们可以很容易地在Jedis客户端中使用一致性哈希算法。
ShardedJedis内部已经采用了一致性哈希算法,并且为每个Redis服务器提供了虚拟节点(虚拟节点个数为权重×160)。
4.3、分布式缓存实践
在分布式缓存中,还会遇到许多的问题。例如,保存的对象过大,网络传输较慢,又如缓存雪崩等,所以要用好分布式缓存也需要考虑一些常见的问题。
4.3.1、大对象的缓存
在Java中,有些对象可能很大,尤其是那些读取文件的对象。对于大的对象,一次性读出来需要使用很多的网络传输资源,这样会引发性能瓶颈。在Redis官网中,建议我们使用Redis的哈希(Hash)结构去缓存大对象的内容,把它的属性保存到哈希结构的字段(field)中。在读取很大的对象时,往往只需要先读取部分内容,后续再根据需要读取对应的字段即可,如下图所示:
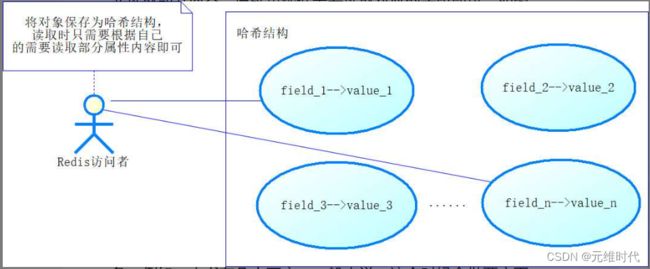
也许还有一种可能,就是哈希结构中的某个字段的值也是大对象,例如一本书有几十万字。一般来说,这个时候会做两方面的考虑。一方面是有必要全部保存吗?是否保存部分最常用的即可?另一方面,可以拆分字符串,将原有的字段拆分为多个字段,拿上图来说,假如field3需要存储的是很大的字符串,我们可以将其拆分为field3_1, field3_2, …, field3_n,分段保存字符串,然后读取的时候,也分段读取即可。
4.3.2、缓存穿透、并发和雪崩
当客户端通过一个键去访问缓存时,缓存没有数据,跟着又去访问数据库,数据库也没有数据,这时因为数据库返回也为空,所以不会将该数据放到缓存中,我们把这样的情况称为缓存穿透,如下图所示:
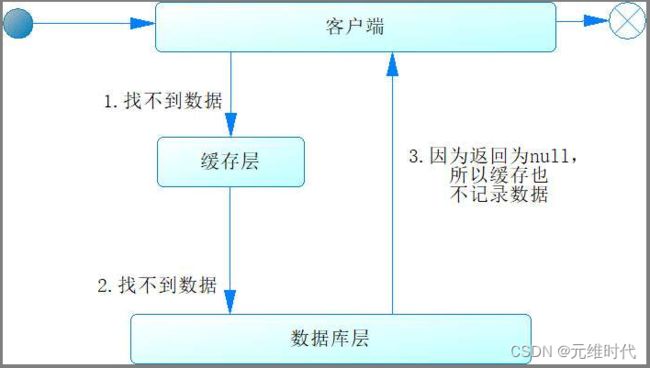
如果我们再次请求这个的键,还是会按照此流程再走一遍。如果出现高并发访问这个键的情况,数据就会频繁访问数据库,给数据库带来很大的压力,甚至可能导致数据库出现故障,这便是缓存穿透带来的危害。
为了解决这个问题,相信大家很快想到,如果在访问数据库后也得到控制,可以在缓存中记录一个字符串(如“null”,代表是空值),即可解决这个问题。但是这样会引发一个问题,就是在很多时候我们访问数据库也得不到数据,这样就会在缓存中存储大量的空值,这显然也会给缓存带来一定的浪费。为此可以增加一个判断,就是判断该键是否是一个常用的数据,如果是常用的,就将它也写入缓存中,这样就不会出现缓存穿透导致数据库被频繁访问的情况了,如下图所示:
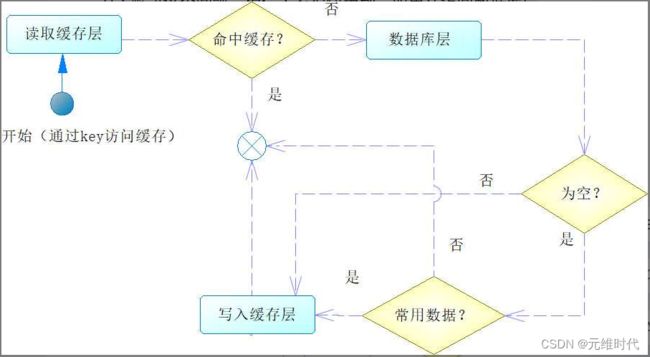
在使用缓存的过程中,我们往往还会设置超时时间,当数据超时的时候,就不能从缓存中读取数据了,而是到数据库中读取。有些数据是热点数据,例如我们最畅销的产品,假如在高并发期间,这个产品和它的关联信息在缓存中超时失效了,就会导致大量的请求访问数据库,给数据库带来很大的压力,甚至可能导致数据库宕机,类似这样的情况,我们称为缓存并发,如下图所示:

为了防止出现缓存并发的情况,一般来说,我们可以采用以下几种方式避免缓存并发。
- 限流:也就是防止过多的请求来访问缓存系统,从而导致压垮数据库,例如使用Resilience4j进行限流,但是这会影响并发线程数量。
- 加锁:对缓存数据加锁,使得线程只能一条条地通过去访问,而不能并发访问,这样就能避免缓存并发的现象,但是分布式锁比较难以实现,所以一般来说我们不会考虑这个办法。
- 错峰失效:网站一般是在上网高峰期或者热门商品抢购时,才会出现高并发现象,而这是有规律的,所以可以自己设置那些需要经常访问的缓存,错过这段时间失效,一般就不会出现缓存并发的现象了,这个做法的成本相对低,也容易实现,所以我比较推荐它。
上述我们谈了缓存穿透和缓存并发,事实上,还有一种缓存雪崩,那什么是缓存雪崩呢?典型的情况是,我们在启动系统的时候,一般会把最常用的数据放入缓存中,并且设置一个固定的超时时间,这便是我们常说的预热数据,它有助于系统性能的提高。但是,因为设置了一个固定的超时时间,所以会导致在某个时间点有大量缓存的键值对数据超时,如果在这个时间点出现高并发,就会导致请求大量访问数据库,造成数据库压力过大,甚至宕机,这便是缓存雪崩,如下图所示:
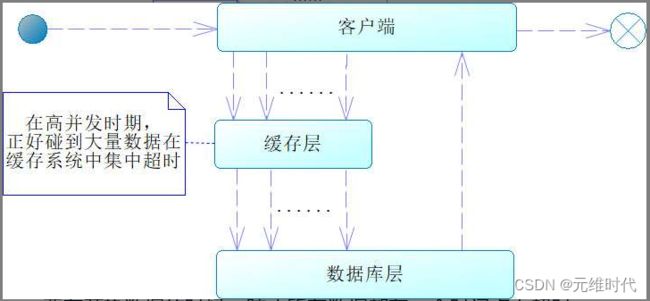
这里容易混淆的是缓存并发和缓存雪崩的概念,缓存并发是针对一个键值对来说的,而缓存雪崩是针对多个键值对在某个时间点同时超时来说的。一般来说,为了避免缓存雪崩,我们需要在预热数据的时候,防止所有数据都在一个时间点上超时。为此,可以设置不同的超时时间,来避免多个键值对同时失效。例如,key1失效是1小时,key2是1.5小时、key3是30分钟……这样就能够避免数据同时失效了。
4.3.3、缓存实践的一些建议
- 对于采用了微服务架构的系统,建议缓存服务器只存储某项业务的数据,不掺杂其他业务的数据,这样可以避免业务数据的耦合。
- 对于存入缓存的预热数据,尽量设置不同的超时时间,以避免同时超时引发缓存雪崩。
- 在使用缓存前,要判断应不应该使用缓存。
- 缓存会造成数据的不一致,也可能存在一定的失真,但是性能好,能够支持高并发的访问,所以多用于读取数据,而对于更新数据,一定要以数据库为基准,不要轻信缓存。
- 对于热门数据,应该考虑错峰失效,错峰更新,避免出现缓存并发现象。
- 在需要大量操作Redis的时候,可以考虑采用流水线(pipeline)的方式,这样可以在很大程度上提高传输的效率。
- 在读数据的时候,先读缓存再读数据库。在写数据的时候,先写数据库再写缓存。
5、分布式会话
会话(session)是指客户端和服务器之间的交互过程中,由服务器端分配的一片内存空间,它用于存储客户端和服务端交互的数据,例如,典型的电商网站的购物车。这片内存空间是由对应的客户端和服务器共享的,它可以存储那些需要暂存的和常用的数据,以便后续快速方便地读出。在会话机制中,为了使浏览器和服务器能够对应起来,会使用一个字符串进行关联,例如,Tomcat中的sessionId。在单体系统中,因为服务器实例只有一个,所以只需要将用户的数据存入到自己的内存中就可以反复读出了。在分布式系统中,有多个服务器节点,这些节点甚至是跨服务的,如果会话信息只在一个节点上,就需要一定的机制来保证会话在多个服务节点之间能够共享,即分布式会话。在分布式会话中,最重要的功能是安全验证,因为不同的用户会有不同的权限。
5.1、分布式会话的几种方式
应该说,分布式会话有多种实现方法,各种方法都有利弊。一般来说,分布式会话分为以下几种:
- 黏性会话:黏性会话是指根据用户的IP地址,将会话指向一个固定的分布式节点,只使用该节点与该IP地址的用户进行会话。
- 服务器会话复制:对多个分布式服务器节点的Session采用相互复制的机制,使得各个节点的会话信息保持一致,这样就可以从各个节点中读取会话信息了。
- 使用缓存:将会话信息保留在缓存(如Redis)中,然后对各个节点开放缓存,这样就可以从缓存中获取会话信息了。
- 持久化到数据库:将会话信息保存到数据库中,然后对分布式其他节点共享该数据库,就可以从该数据库中读会话信息了。
注意,以上只是列举了几种类型,还会有其他的方式。而当今,黏性会话、服务器会话复制和持久化到数据库这些方式都已经不再常用了,最流行的是使用缓存,下面让我们稍微讨论一下它们的优缺点。
5.2、黏性会话
黏性会话,典型的是Nginx的负载均衡方式——ip_hash,也就是按照客户端的IP地址,求得哈希值后,再分配到某台服务器节点上。例如,将Nginx配置如下:
# 将地址springcloud.example.com做负载均衡
upstream springcloud.example.com{
# 服务器列表
server 192.168.224.136:80;
server 192.168.224.137:80;
# 采用求IP哈希的负载均衡算法
ip_hash;
}
因为提交到Nginx的客户端请求中包含客户端自己的IP信息,所以Nginx可以通过它来求哈希值,然后在会话期间将其固定地分配到服务器列表中的某台机器上,这样就能够做到类似单体系统那样来应答用户了。
只是这样的方式已经使用不多了,因为它有两个很大的缺点:
- 高可用性差:如果路由到的具体节点发生故障,显然会话就不可用了,因为其他的节点并无对应的会话信息。
- 微服务不适用:因为微服务系统是按业务拆分为多个节点的,业务需要多台节点相互协作,且单个节点往往不能满足业务的需求,所以在微服务系统中,无法经过黏性会话的机制得到类似单体系统的服务,因此无法在微服务系统中使用黏性会话。
5.3、服务器会话复制
服务器会话复制,也可以称为服务器会话共享,它是通过一定的机制将分布式中的服务器会话通过复制的手段,使得各个服务器的信息共享起来。Tomcat、Jetty等服务器都能够支持这样的机制,只是这样的机制当前使用得比较少了,举例也相对麻烦,所以这里只论述其基本原理。为此先看下图:
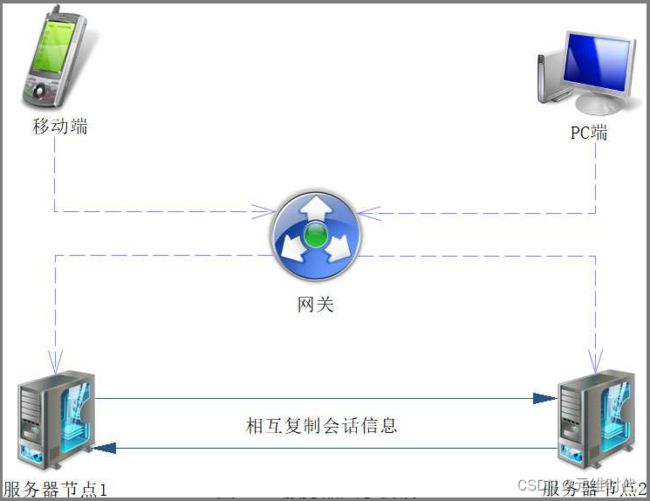
请求会通过网关来到具体的服务器节点,而各个服务器节点会通过某种机制相互复制(如Tomcat中的NIO)。当某个服务器节点保存会话数据时,其他的服务器节点就会将其复制过去,从而使得各个服务器节点的会话信息保持一致。这样无论访问哪个具体的服务器,都能够得到相同的会话信息。
这样的机制配置相对简单,易于理解,同时具备高可用,即便有某个节点发生故障,其他服务器也会有会话副本。只是这样做也有比较大的缺陷,主要有两个:
- 耗网络资源较多:如果会话数据大,且频繁复制,可能会造成网络堵塞,拖慢服务器,降低性能。
- 数据冗余:将数据复制到各个服务器节点,就会产生很多重复的副本,从而导致数据冗余。因为单体服务器的内存资源也是有限的,所以在大型服务网站中,可能会因为会员数众多,导致单体服务器难以承受那么庞大的数据量。
基于这两个原因,服务器会话复制这样的机制只能在小型分布式系统中使用,应该来说,目前使用它的已经不多了。
5.4、使用缓存(spring-session-data-redis)
这是一种使用比较普遍的方式,也是当今的主流方式。顾名思义,就是将会话数据保存到缓存服务器中,如下图所示:
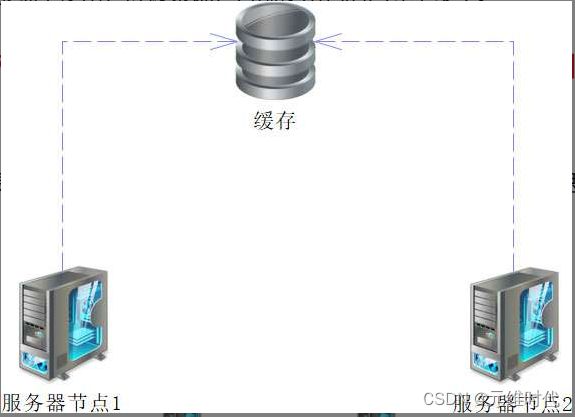
对于一些缓存服务系统,可以配置高可用使系统更为健壮,例如Redis的哨兵模式和集群方式,加上缓存服务还可以无限扩展,因此无论灵活性、可靠性和可扩展性都得到了更大的保证,所以这种方式是企业实现分布式会话的主要方式。
在现今企业的选择中,缓存大部分会选择Redis,所以Spring也为此提供了自己的实现包——spring-session- data-redis。
示例代码:
package com.spring.cloud.chapter17.main;
/**** imports ****/
@SpringBootApplication
// 启动使用Spring Session Redis
@EnableRedisHttpSession
@RestController
@RequestMapping("/session")
public class Chapter17Application {
public static void main(String[] args) {
SpringApplication.run(Chapter17Application.class, args);
}
// 写入测试
@GetMapping("/set/{key}/{value}")
public Map<String, String> setSessionAtrribute( HttpServletRequest request,
@PathVariable("key") String key, @PathVariable("value") String value) {
Map<String, String> result = new HashMap<>();
result.put(key,value);
request.getSession().setAttribute(key, value);
return result;
}
// 读出测试
@GetMapping("/get/{key}")
public Map<String, String> getSessionAtrribute( HttpServletRequest request,
@PathVariable("key") String key) {
Map<String, String> result = new HashMap<>();
String value = (String) request.getSession().getAttribute(key);
result.put(key, value);
request.getSession().setAttribute(key, value);
return result;
}
}
代码中的注解@EnableRedisHttpSession是用来启动Spring Session Redis的,通过这样就能够将会话数据保存到Redis中了,十分方便。setSessionAtrribute方法是设置一个Session数据,而getSessionAtrribute方法则是读出Session数据。
5.5、持久化到数据库
顾名思义,就是将会话信息保存到数据库中。这种方式的一个很大的优点是,会话数据不会轻易丢失,但是缺点也很明显,就是性能和使用缓存相差太远,如果发生高并发场景,这样的机制就很难保证性能了,此外也增加了维护数据库的代价。基于它的缺点,这样的方式在目前几乎没有企业采用了,所以就不再讨论了。
6、分布式系统权限验证
在计算机系统中,权限往往也是很重要的一个部分。在单体系统中,权限往往很容易控制,但是在分布式系统中,则不然。因为在单体系统中往往只有一个节点,只要解决单点就可以了。但是分布式系统是多节点协作,不能一个节点验证通过后,另外一个节点却没有验证通过。实际上,在分布式会话中谈到的使用缓存存储会话(spring-session- data-redis),也能在一定程度上支持分布式的权限验证,不过一切还需要从最基础的Spring Security开始讲起。
6.1、 Spring Security
Spring Security是Spring框架提供的一个安全认证框架,Spring Boot在此基础上封装成了spring-boot-starter-security,这样会更加方便我们的使用。
Spring Security是基于过滤器(Filter)来开发的,在默认的情况下,它内部会提供一系列的过滤器来拦截请求,以达到安全验证的目的。此外,Spring Security还会涉及一些页面的内容,所以也引入了Thymeleaf。在Spring Security的机制下,在访问资源(如控制器返回的数据或者页面)之前,请求会经过Spring Security所提供的过滤器进行的验证,如果验证不通过,就会被过滤器拦截,这样就不能访问对应的资源了。同样的在我们需要增加验证功能的时候,只需要在Spring Security中加入对应的过滤器就可以了。
6.1.1、简单使用Spring Security
为了使用Spring Security,这里新增配置类SecurityConfig。
package com.spring.cloud.security.config;
/**** imports ****/
@Configuration
public class SecurityConfig extends WebSecurityConfigurerAdapter { // ①
// 编码器
private PasswordEncoder encoder = new BCryptPasswordEncoder(); // ②
/**
* 用户认证
* @param auth -- 认证构建
* @throws Exception
*/
@Override
protected void configure(AuthenticationManagerBuilder auth)
throws Exception {
auth.inMemoryAuthentication() // 使用内存保存验证信息
.passwordEncoder(encoder). // 设置编码器
// 设置用户名、密码和角色
withUser("admin").password(encodePwd("abcdefg"))
// roles方法会自动给字符串加入前缀“ROLE_”
.roles("ADMIN", "USER") // 赋予两个角色
// 创建第二个用户
.and().withUser("user").password(encodePwd("123456789"))
.roles("USER"); // 赋予一个角色
}
/**
* 请求路径权限限制
* @param http -- HTTP请求配置
* @throws Exception
*/
@Override
public void configure(HttpSecurity http) throws Exception {
http
// 访问ANT风格“/admin/**”需要ADMIN角色
.authorizeRequests().antMatchers("/admin/**")
.hasAnyRole("ADMIN")
// 访问ANT风格“/user/**”需要USER或者ADMIN角色
.antMatchers("/user/**").hasAnyRole("USER", "ADMIN")
// 无权限配置的全部开放给已经登录的用户
.anyRequest().permitAll()
// 使用页面登录
.and().formLogin();
}
// 对密码进行加密
private String encodePwd(String pwd) {
return encoder.encode(pwd);
}
}
这个类标注了@Configuration,说明该类是一个配置类。代码①处继承了WebSecurityConfigurerAdapter,说明它是一个配置Spring Security的类。代码②处创建了编码器,在最新版本的Spring 5之后,Spring Security中都需要设置编码器,加密密码,这样可以有效增强用户密码的安全性。这段代码的核心是两个方法configure(AuthenticationManagerBuilder)和configure(HttpSecurity)。
configure(AuthenticationManagerBuilder)方法主要用于用户验证,configure(HttpSecurity)方法主要用于URL权限配置。代码中有清晰的注释,请读者自行参考。这里需要指出的是,加粗的roles、hasRole和hasAnyRole方法,在默认的情况下,Spring Security会加入前缀“ROLE_”,这是后续开发需要特别注意的。当然,如果不想加入这些前缀,可以使用authorities、hasAuthority和hasAnyAuthority方法代替。
6.1.2、使用自定义用户验证
在上面的例子,我们使用的是内存存储权限信息,这显然不符合企业的需要,更多的时候,企业会希望使用数据库存储用户信息。为此,我们来实现这个目标,这里先在数据库里创建对应的表,表的设计如下图所示:
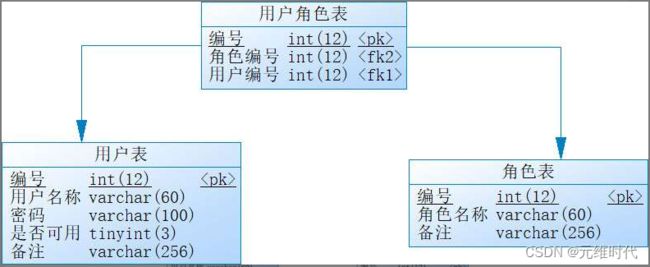
自定义用户验证权限(security模块):
package com.spring.cloud.security.service.impl;
/**** imports ****/
@Service
public class UserDetailsServiceImpl implements UserDetailsService { // ①
// 注入UserService对象
@Autowired
private UserService userService = null;
@Override
public UserDetails loadUserByUsername(String userName)
throws UsernameNotFoundException {
// 获取用户角色信息
UserRolePo userRole = userService.getUserRoleByUserName(userName);
// 转换为Spring Security用户详情
return change(userRole);
}
private UserDetails change(UserRolePo userRole) {
// 权限列表
List<GrantedAuthority> authorityList = new ArrayList<>();
// 获取用户角色信息
List<RolePo> roleList = userRole.getRoleList();
// 将角色名称放入权限列表中
for (RolePo role: roleList) {
GrantedAuthority authority
= new SimpleGrantedAuthority(role.getRoleName());
authorityList.add(authority);
}
UserPo user = userRole.getUser(); // 用户信息
// 创建Spring Security用户详情
UserDetails result // ②
= new User(user.getUserName(), user.getPassword(), authorityList);
return result;
}
}
6.1.3、使用自定义用户验证
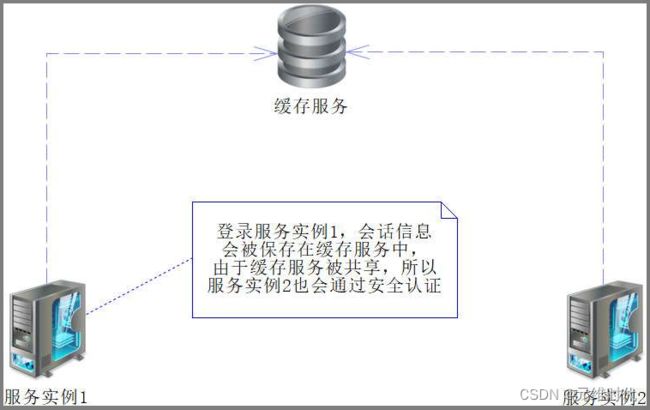
其实使用缓存共享也可以实现分布式权限管理,例如之前所谈到的分布式会话方案spring-session- data-redis,就能够在一定程度上实现分布式权限验证。
6.1.4、跨站点请求伪造(CSRF)攻击
跨站点请求伪造(Cross-Site Request Forgery,CSRF)是一种常见的攻击手段,我们先来了解什么是CSRF。如下图所示,首先,用户通过浏览器请求安全网站,进行登录,在登录后,浏览器会记录一些信息,以Cookie的形式保存。然后,用户可能会在不关闭浏览器的情况下,访问危险网站,危险网站通过获取Cookie信息来仿造用户请求,进而请求安全网站,这样就给网站带来了很大的危险。

为了避免发生这种危险,Spring Security提供了针对CSRF的过滤器。在默认的情况下,它会启用这个过滤器来防止CSRF攻击。当然,我们也可以关闭这个功能,代码如下:
http.csrf().disable().authorizeRequests()......
因为后续的OAuth 2.0需要跨域访问,所以需要经常使用这段关闭CSRF过滤器的代码。
对于不关闭CSRF的Spring Security,每次HTTP请求的表单(Form)提交时,都要求有CSRF参数。当访问表单的时候,Spring Security就生成CSRF参数,放入表单中,这样在将表单提交到服务器时,就会连同CSRF参数一并提交到服务器。Spring Security会检查CSRF参数,判断该参数是否与其生成的一致。如果一致,它就认为该请求不是来自CSRF的攻击。如果CSRF参数为空或者与服务器的不一致,它就认为这是一个来自CSRF的攻击,会拦截请求,拒绝访问。因为这个参数不在Cookie中,所以第三方网站是无法伪造的,这样就可避免CSRF攻击了。