前言
MMYOLO框架是一个基于PyTorch和MMDetection的YOLO系列算法开源工具箱。MMYOLO定位为YOLO系列热门开源库以及工业应用核心库,MMYOLO框架Github项目地址- 支持的任务:目标检测、旋转目标检测
- 支持的算法:
YOLOv5、YOLOX、RTMDet、RTMDet-Rotated、YOLOv6、YOLOv7、PPYOLOE、YOLOv8
- 支持COCO、VOC数据格式的训练
- 官方有一篇文章标注+训练+测试+部署全流程写的很详细,基本上纯新手也是可以走完流程的。也可以观看视频自定义数据集从标注到部署保姆级教程。MMYOLO系列视频。
- 本文主要是对上述教程的一点点扩展(Win10系统),记录在使用过程中遇到的一些问题,解决过程以及对配置文件的深入解释。
pycocotools安装问题
- 首先从
MMYOLO项目地址中下载整个项目,接着在命令窗口中输入pip install openmim。然后使用cd mmyolo进入项目文件下,注意这里的mmyolo是一个路径,比如你项目文件在D盘下,那你应该写cd D:\mmyolo。进入项目文件夹后输入mim install -r requirements/mminstall.txt
- 我在安装过程中只有一个库安装报错,就是
pycocotools库,报错Microsoft Visual C++ 14.0 or greater is required,对应Github库中作者强调了该错误信息是没有安装Visual C++ 2015 build tools,在文档中作者提供了一个下载地址,但是下载过程中总是报错。于是我找到了离线版本,下载链接
- 安装完成后,再次尝试
mim install -r requirements/mminstall.txt无报错,问题解决!
xml文件path问题
- 因为标定的时候是两个人分开标的,导致
xml文件中的path路径不一致,但不是每个人都有这样的问题,这里仅是做一点记录。
import xml.etree.ElementTree as ET
import os
def modify_xml_path(xml_file):
tree = ET.parse(xml_file)
root = tree.getroot()
for path_elem in root.iter('path'):
path_elem.text = os.path.basename(path_elem.text)
tree.write(xml_file)
folder_path = './data/xml'
for file in os.listdir(folder_path):
file_path = os.path.join(folder_path, file)
modify_xml_path(file_path)
xml文件转json文件
- 因为之前做数据标定的时候没看过
MMYOLO教程文档,所以使用Labelimg软件标定的,VOC格式,生成xml文件。
- 但是教程中使用的是
Labelme,生成的json文件,并且后续的数据分隔、标注检验、数据集探索等等都是基于json文件,所以需要将xml文件转换为json文件。
- 先将文件按下列方式组织:
-mmyolo
- data
- images
- 0001.bmp
- 0002.bmp
- ...
- xml
- 0001.xml
- 0002.xml
- ...
- configs
...
- 在
mmyolo项目文件夹下新建data文件夹,将图片放入.\data\images中,标定文件放入.\data\xml中。
- 然后在
.\tools\dataset_converters文件夹中新建xml2json.py文件,填入代码:
import xml.etree.ElementTree as ET
import os
import json
coco = dict()
coco['images'] = []
coco['type'] = 'instances'
coco['annotations'] = []
coco['categories'] = []
category_set = dict()
image_set = set()
category_item_id = -1
image_id = 0
annotation_id = 0
def addCatItem(name):
global category_item_id
category_item = dict()
category_item['supercategory'] = 'none'
category_item_id += 1
category_item['id'] = category_item_id
category_item['name'] = name
coco['categories'].append(category_item)
category_set[name] = category_item_id
return category_item_id
def addImgItem(file_name, size):
global image_id
if file_name is None:
raise Exception('Could not find filename tag in xml file.')
if size['width'] is None:
raise Exception('Could not find width tag in xml file.')
if size['height'] is None:
raise Exception('Could not find height tag in xml file.')
image_id += 1
image_item = dict()
image_item['id'] = image_id
print(file_name)
image_item['file_name'] = file_name + ".jpg"
image_item['width'] = size['width']
image_item['height'] = size['height']
coco['images'].append(image_item)
image_set.add(file_name)
return image_id
def addAnnoItem(object_name, image_id, category_id, bbox):
global annotation_id
annotation_item = dict()
annotation_item['segmentation'] = []
seg = []
seg.append(bbox[0])
seg.append(bbox[1])
seg.append(bbox[0])
seg.append(bbox[1] + bbox[3])
seg.append(bbox[0] + bbox[2])
seg.append(bbox[1] + bbox[3])
seg.append(bbox[0] + bbox[2])
seg.append(bbox[1])
annotation_item['segmentation'].append(seg)
annotation_item['area'] = bbox[2] * bbox[3]
annotation_item['iscrowd'] = 0
annotation_item['ignore'] = 0
annotation_item['image_id'] = image_id
annotation_item['bbox'] = bbox
annotation_item['category_id'] = category_id
annotation_id += 1
annotation_item['id'] = annotation_id
coco['annotations'].append(annotation_item)
def parseXmlFiles(xml_path):
for f in os.listdir(xml_path):
if not f.endswith('.xml'):
continue
xmlname = f.split('.xml')[0]
bndbox = dict()
size = dict()
current_image_id = None
current_category_id = None
file_name = None
size['width'] = None
size['height'] = None
size['depth'] = None
xml_file = os.path.join(xml_path, f)
print(xml_file)
tree = ET.parse(xml_file)
root = tree.getroot()
if root.tag != 'annotation':
raise Exception('pascal voc xml root element should be annotation, rather than {}'.format(root.tag))
for elem in root:
current_parent = elem.tag
current_sub = None
object_name = None
if elem.tag == 'folder':
continue
if elem.tag == 'filename':
file_name = xmlname
if file_name in category_set:
raise Exception('file_name duplicated')
elif current_image_id is None and file_name is not None and size['width'] is not None:
if file_name not in image_set:
current_image_id = addImgItem(file_name, size)
print('add image with {} and {}'.format(file_name, size))
else:
raise Exception('duplicated image: {}'.format(file_name))
for subelem in elem:
bndbox['xmin'] = None
bndbox['xmax'] = None
bndbox['ymin'] = None
bndbox['ymax'] = None
current_sub = subelem.tag
if current_parent == 'object' and subelem.tag == 'name':
object_name = subelem.text
if object_name not in category_set:
current_category_id = addCatItem(object_name)
else:
current_category_id = category_set[object_name]
elif current_parent == 'size':
if size[subelem.tag] is not None:
raise Exception('xml structure broken at size tag.')
size[subelem.tag] = int(subelem.text)
for option in subelem:
if current_sub == 'bndbox':
if bndbox[option.tag] is not None:
raise Exception('xml structure corrupted at bndbox tag.')
bndbox[option.tag] = int(float(option.text))
if bndbox['xmin'] is not None:
if object_name is None:
raise Exception('xml structure broken at bndbox tag')
if current_image_id is None:
raise Exception('xml structure broken at bndbox tag')
if current_category_id is None:
raise Exception('xml structure broken at bndbox tag')
bbox = []
bbox.append(bndbox['xmin'])
bbox.append(bndbox['ymin'])
bbox.append(bndbox['xmax'] - bndbox['xmin'])
bbox.append(bndbox['ymax'] - bndbox['ymin'])
print('add annotation with {},{},{},{}'.format(object_name, current_image_id, current_category_id,
bbox))
addAnnoItem(object_name, current_image_id, current_category_id, bbox)
if __name__ == '__main__':
xml_path = './data/xml'
json_file = './data/annotations/annotations_all.json'
parseXmlFiles(xml_path)
json.dump(coco, open(json_file, 'w'))
- 运行该代码后就可以在
./data/annotations文件夹下生成了annotations_all.json文件。上述转换代码是引用一位博主的博客,并非本人所写,但是因为时间关系,忘记了源地址,如果有人看到请私信我标明出处。
- 这里需要注意的是,如果你的图片后缀不是
jpg和png,请打开生成的annotations_all.json文件,查看file_name字段,使用文本编辑器替换后缀名,比如我的图片是.bmp格式,那我需要将.jpg替换为.bmp
- 最后,需要在
./data/annotations文件夹下新建class_with_id.txt,用于保存数值标签对应的种类。我们可以再次打开annotations_all.json文件,拖到最后,找到''categories''字段,比如我的json文件
"categories": [{"supercategory": "none", "id": 0, "name": "cat"}, {"supercategory": "none", "id": 1, "name": "dog"}]}
- 可以看到种类
0对应cat,种类1对应dog,我们打开class_with_id.txt文件,填入以下内容:
0 cat
1 dog
- 到这里,我们将教程3.1使用脚本转换的工作做完了,其格式与教程无异。最终文件格式组织:
-mmyolo
- data
- images
- 0001.bmp
- 0002.bmp
- ...
- xml
- 0001.xml
- 0002.xml
- ...
- annotations
- annotations_all.json
- class_with_id.txt
- configs
...
检查转换的 COCO label
- 使用
mmyolo项目文件夹下的.\tools\analysis_tools\browse_coco_json.py文件检查数据格式。
- 修改文件参数默认值,按照教程,只修改了
--img-dir和--ann-file参数,添加default选项,代码如下
def parse_args():
parser = argparse.ArgumentParser(description='Show coco json file')
parser.add_argument('--data-root', default=None, help='dataset root')
parser.add_argument(
'--img-dir', default='data/images', help='image folder path')
parser.add_argument(
'--ann-file',
default='data/annotations/annotations_all.json',
help='ann file path')
parser.add_argument(
'--wait-time', type=float, default=2, help='the interval of show (s)')
parser.add_argument(
'--disp-all',
action='store_true',
help='Whether to display all types of data, '
'such as bbox and mask.'
' Default is to display only bbox')
parser.add_argument(
'--category-names',
type=str,
default=None,
nargs='+',
help='Display category-specific data, e.g., "bicycle", "person"')
parser.add_argument(
'--shuffle',
action='store_true',
help='Whether to display in disorder')
args = parser.parse_args()
return args
python tools/analysis_tools/browse_coco_json.py --img-dir ${图片文件夹路径} \
--ann-file ${COCO label json 路径}
划分数据集
- 我们依然可以使用项目文件下的
.\tools\misc\coco_split.py文件来完成这一步
- 修改文件参数默认值,按照教程,只修改了
--json、--out-dir和--ratios参数,添加default选项,代码如下
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument(
'--json', type=str, default='./data/annotations/annotations_all.json', help='COCO json label path')
parser.add_argument(
'--out-dir', type=str, default='./data/annotations', help='output path')
parser.add_argument(
'--ratios',
default=[0.9,0.1],
nargs='+',
type=float,
help='ratio for sub dataset, if set 2 number then will generate '
'trainval + test (eg. "0.8 0.1 0.1" or "2 1 1"), if set 3 number '
'then will generate train + val + test (eg. "0.85 0.15" or "2 1")')
parser.add_argument(
'--shuffle',
action='store_true',
help='Whether to display in disorder')
parser.add_argument('--seed', default=2023, type=int, help='seed')
args = parser.parse_args()
return args
- 尤其需要注意
--ratios的写法,为[0.9,0.1],也可以使用教程中的方法,在命令窗口输入:
python tools/misc/coco_split.py --json ${COCO label json 路径} \
--out-dir ${划分 label json 保存根路径} \
--ratios ${划分比例} \
[--shuffle] \
[--seed ${划分的随机种子}]
python tools/misc/coco_split.py --json ./data/cat/annotations/annotations_all.json \
--out-dir ./data/cat/annotations \
--ratios 0.8 0.2 \
--shuffle \
--seed 10
- 关于
--ratios分隔特性这一块请自行查看教程相关说明
- 最终文件格式组织:
-mmyolo
- data
- images
- 0001.bmp
- 0002.bmp
- ...
- xml
- 0001.xml
- 0002.xml
- ...
- annotations
- annotations_all.json
- class_with_id.txt
- trainval.json
- test.json
- configs
...
新建config文件
- 在
./configs文件夹下新建文件夹custom_dataset,在custom_dataset文件夹下新建yolov6_l_syncbn_fast_1xb8-100e_animal.py文件。其实配置文件是可以直接命名的,但是这样命名是有一定含义的,比如前面的yolov6_l_syncbn_fast表示我训练的是YOLOV6-l的主干,syncbn表示多卡训练时使用所有卡上的数据(全局样本数据)一起计算BN层的均值和标准差,fast是模型型号,1xb8-100e表示我使用1张GPU进行训练,batch size为8,max_epoch为100。由此得到该名称。
- 在项目文件夹下新建文件夹
work_dirs,作为模型保存等其他工作的目录。打开项目文件夹下.\configs\yolov6\README.md文件,提前下载YOLOv6-l的预训练权重yolov6_l_syncbn_fast_8xb32-300e_coco_20221109_183156-91e3c447.pth,放入work_dirs文件夹中。

- 由于我训练的是
YOLOV6-l型号,所以继承的是yolov6_l_syncbn_fast_8xb32-300e_coco.py文件。
- 配置文件以及其注释如下:
_base_ = '../yolov6/yolov6_l_syncbn_fast_8xb32-300e_coco.py'
max_epochs = 100
data_root = './data/'
work_dir = './work_dirs'
load_from = './work_dirs/yolov6_l_syncbn_fast_8xb32-300e_coco_20221109_183156-91e3c447.pth'
train_batch_size_per_gpu = 8
train_num_workers = 4
save_epoch_intervals = 2
base_lr = _base_.base_lr / 32
class_name = ('cracked', 'complete')
num_classes = len(class_name)
metainfo = dict(
classes=class_name,
palette=[(220, 17, 58), (0, 143, 10)]
)
train_cfg = dict(
max_epochs=max_epochs,
val_begin=20,
val_interval=save_epoch_intervals,
dynamic_intervals=[(max_epochs - _base_.num_last_epochs, 1)]
)
model = dict(
bbox_head=dict(
head_module=dict(num_classes=num_classes)),
train_cfg=dict(
initial_assigner=dict(num_classes=num_classes),
assigner=dict(num_classes=num_classes))
)
train_dataloader = dict(
batch_size=train_batch_size_per_gpu,
num_workers=train_num_workers,
dataset=dict(
_delete_=True,
type='ClassBalancedDataset',
oversample_thr=0.5,
dataset=dict(
type=_base_.dataset_type,
data_root=data_root,
metainfo=metainfo,
ann_file='annotations/trainval.json',
data_prefix=dict(img='images/'),
filter_cfg=dict(filter_empty_gt=False, min_size=32),
pipeline=_base_.train_pipeline)))
val_dataloader = dict(
dataset=dict(
metainfo=metainfo,
data_root=data_root,
ann_file='annotations/trainval.json',
data_prefix=dict(img='images/')))
test_dataloader = val_dataloader
val_evaluator = dict(ann_file=data_root + 'annotations/trainval.json')
test_evaluator = val_evaluator
optim_wrapper = dict(optimizer=dict(lr=base_lr))
default_hooks = dict(
checkpoint=dict(
type='CheckpointHook',
interval=save_epoch_intervals,
max_keep_ckpts=5,
save_best='auto'),
param_scheduler=dict(max_epochs=max_epochs),
logger=dict(type='LoggerHook', interval=10))
custom_hooks = [
dict(
type='EMAHook',
ema_type='ExpMomentumEMA',
momentum=0.0001,
update_buffers=True,
strict_load=False,
priority=49),
dict(
type='mmdet.PipelineSwitchHook',
switch_epoch=max_epochs - _base_.num_last_epochs,
switch_pipeline=_base_.train_pipeline_stage2)
]
visualizer = dict(vis_backends=[dict(type='LocalVisBackend'), dict(type='WandbVisBackend')])
visualizer = dict(vis_backends=[dict(type='LocalVisBackend'),dict(type='TensorboardVisBackend')])
- 配置文件前半段理解起来并不困难,但是到
train_cfg时可能就有点懵了,后面我将分段进行更加细致的解释。
config分段详解
- 事实上上面那些配置文件的写法继承至
mmengine库,Github项目地址,参考文档。文档有中文版本,理解起来不太困难。
- 总的来说所有的配置文件都是基于
mmengine.runner方法去写的,可以读一读其API,会对配置文件有更深的理解。
- 值得注意的是配置文件中的所有type参数都对应相应的类,在PyCharm中,可以使用
Ctrl + Shift + F快捷键在文件中搜索类,了解其作用与参数。如果快捷键失效可能是因为搜狗输入法的快捷键冲突导致,可以在属性设置 --> 按键 --> 系统功能快捷键设置 --> 取消勾选简繁切换。
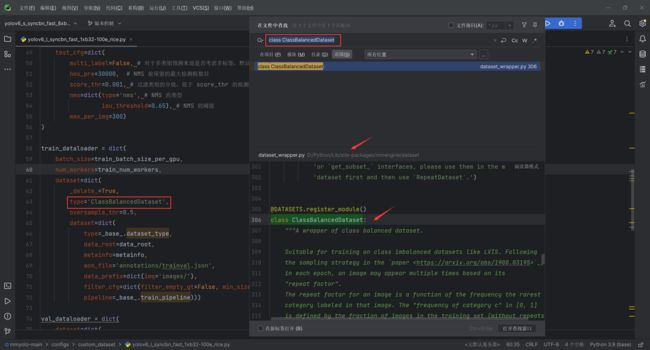
- 例如上述配置文件中的出现的第1个
type,即train_dataloader中的type='ClassBalancedDataset'。
train_cfg
- 在
mmengine.runner方法中,对于train_cfg参数是这样描述的:一个用于建立训练循环的口令。如果它没有提供 "type "键,它应该包含 "by_epoch"来决定应该使用哪种类型的训练循环EpochBasedTrainLoop或者IterBasedTrainLoop。如果指定了train_cfg,还应该指定train_dataloader。默认为None。
- EpochBasedTrainLoop参数文档,我们再来看配置代码
train_cfg = dict(
max_epochs=max_epochs,
val_begin=20,
val_interval=save_epoch_intervals,
dynamic_intervals=[(max_epochs - _base_.num_last_epochs, 1)])
max_epochs = max_epochs:最大训练max_epochs传导val_begin = 20:第20个epoch后再对测试集进行评估val_interval = save_epoch_intervals:每val_interval轮迭代进行一次测试评估dynamic_intervals = [(max_epochs - _base_.num_last_epochs, 1)]):到max_epochs - _base_.num_last_epochs时,每1轮执行一次评估
model
model这一块主要是用于控制模型架构的,所以其更改与继承的原始模型有关,比如我要训练的是YOLOV6-l,那么我根据_base_,不断的往下查找基础类,即.\configs\yolov6\yolov6_s_syncbn_fast_8xb32-400e_coco.py,找到bbox_head字段,代码如下:
bbox_head=dict(
type='YOLOv6Head',
head_module=dict(
type='YOLOv6HeadModule',
num_classes=num_classes,
in_channels=[128, 256, 512],
widen_factor=widen_factor,
norm_cfg=dict(type='BN', momentum=0.03, eps=0.001),
act_cfg=dict(type='SiLU', inplace=True),
featmap_strides=[8, 16, 32]),
loss_bbox=dict(
type='IoULoss',
iou_mode='giou',
bbox_format='xyxy',
reduction='mean',
loss_weight=2.5,
return_iou=False)),
- 可以使用快捷键
Ctrl + Shift + F分别搜索:class YOLOV6Head、class YOLOV6HeadModule、class BN、class SiLU、class IoULoss了解模型配置中各参数
- 还有
train_cfg字段,代码如下:
train_cfg=dict(
initial_epoch=4,
initial_assigner=dict(
type='BatchATSSAssigner',
num_classes=num_classes,
topk=9,
iou_calculator=dict(type='mmdet.BboxOverlaps2D')),
assigner=dict(
type='BatchTaskAlignedAssigner',
num_classes=num_classes,
topk=13,
alpha=1,
beta=6),
),
- 同样的可以使用快捷键
Ctrl + Shift + F分别搜索:class BatchATSSAssigner、class BboxOverlaps2D、class BatchTaskAlignedAssigner了解模型配置中各参数,注意!mmdet.BboxOverlaps2D搜索的时候只用BboxOverlaps2D,不要把mmdet。
- 对比教程给出的代码
model = dict(
bbox_head=dict(
head_module=dict(num_classes=num_classes)),
train_cfg=dict(
initial_assigner=dict(num_classes=num_classes),
assigner=dict(num_classes=num_classes))
)
- 可以看到,更改的仅仅是涉及到分类数方面的参数,关于更细致的架构参数解释,可以看官方教程学习 YOLOV5 配置文件
train_dataloader
train_dataloader:在Runner.train()中被使用,为模型提供训练数据,关于DataLoader的更多可配置参数,可以参考PyTorch API文档- 教程中因为数据量较小,在
dataset中有一个操作RepeatDataset,在每个epoch内重复当前数据集n次,设置5是重复5次。若你数据集够大,不需要这样的操作,可以直接删除即变为:
train_dataloader = dict(
batch_size=train_batch_size_per_gpu,
num_workers=train_num_workers,
dataset=dict(
type=_base_.dataset_type,
data_root=data_root,
metainfo=metainfo,
ann_file='annotations/trainval.json',
data_prefix=dict(img='images/'),
filter_cfg=dict(filter_empty_gt=False, min_size=32),
pipeline=_base_.train_pipeline))
- 因为在我的数据集中存在种类样本不平衡的问题,所以我使用了
ClassBalancedDataset操作,它通过对原始数据集进行重新采样或调整样本权重的方式,使得每个类别的样本数量相对均衡
oversample_thr是一个介于0和1之间的浮点数。它指定了一个阈值,用于确定哪些类别的样本需要进行过采样。具体来说,如果某个类别的样本数量少于oversample_thr * max_samples,则该类别的样本将进行过采样。
train_dataloader = dict(
batch_size=train_batch_size_per_gpu,
num_workers=train_num_workers,
dataset=dict(
_delete_=True,
type='ClassBalancedDataset',
oversample_thr=0.5,
dataset=dict(
type=_base_.dataset_type,
data_root=data_root,
metainfo=metainfo,
ann_file='annotations/trainval.json',
data_prefix=dict(img='images/'),
filter_cfg=dict(filter_empty_gt=False, min_size=32),
pipeline=_base_.train_pipeline)))
- 更多其他数据处理方式可以查看文档
- 关于
dataset中更细致的其他参数,可以在BASEDATASET中找到,参考文档,在MMYOLO中还有一个新的参数type,默认是'CocoDataset'即COCO数据格式
type:数据格式类型data_root:data_prefix和ann_file的根目录metainfo:数据集的元信息,例如类信息ann_file:注释文件路径data_prefix:训练数据的前缀。默认为 dict(img_path=‘’)filter_cfg:过滤数据的配置pipeline:处理管道
val_dataloader
val_dataloader的dataset部分参数与train_dataloader中的相同,这里就不再过多赘述
val_dataloader = dict(
dataset=dict(
metainfo=metainfo,
data_root=data_root,
ann_file='annotations/trainval.json',
data_prefix=dict(img='images/')))
test_dataloader
- 教程中是直接将
val_dataloader赋给了test_dataloader。当然我们也可以自己写
test_dataloader = dict(
dataset=dict(
metainfo=metainfo,
data_root=data_root,
ann_file='annotations/test.json',
data_prefix=dict(img='images/')))
val_evaluator
val_evaluator用于计算验证指标的评估器对象。它可以是一个字典或一个字典列表来构建评估器。
val_evaluator = dict(ann_file=data_root + 'annotations/trainval.json')
- 在继承的配置文件中,完整的
val_evaluator配置为:
val_evaluator = dict(
type='mmdet.CocoMetric',
proposal_nums=(100, 1, 10),
ann_file=data_root + val_ann_file,
metric='bbox')
test_evaluator
- 教程中直接将
val_evaluator赋值给了test_evaluator,我们也可以自己写
test_evaluator = dict(ann_file=data_root + 'annotations/test.json')
optim_wrapper
optim_wrapper计算模型参数的梯度。如果需要自动混合精度或者梯度累积训练。optim_wrapper的类型应该是AmpOptimizerWrapper。
optim_wrapper = dict(optimizer=dict(lr=base_lr))
optim_wrapper = dict(
type='OptimWrapper',
optimizer=dict(
type='SGD',
lr=base_lr,
momentum=0.937,
weight_decay=weight_decay,
nesterov=True,
batch_size_per_gpu=train_batch_size_per_gpu),
constructor='YOLOv5OptimizerConstructor')
hook
hook编程是一种编程模式,是指在程序的一个或者多个位置设置位点(挂载点),当程序运行至某个位点时,会自动调用运行时注册到位点的所有方法。
默认hook
default_hooks = dict(
checkpoint=dict(
type='CheckpointHook',
interval=save_epoch_intervals,
max_keep_ckpts=5,
save_best='auto'),
param_scheduler=dict(max_epochs=max_epochs),
logger=dict(type='LoggerHook', interval=10))
- 教程中的默认
hook类型为CheckpointHook,CheckpointHook按照给定间隔保存模型的权重,如果是分布式多卡训练,则只有主(master)进程会保存权重。
- 如果想要详细了解其功能即更多参数,可以查阅CheckpointHook API文档,这里我挑选在教程文件中出现的参数。
interval:保存周期。如果by_epoch=True,则interval表示epochs(周期),否则表示迭代次数。max_keep_ckpts:要保留的最大检查点。在某些情况下,我们只需要最新的几个检查点,并希望删除旧的检查点以节省磁盘空间。save_best:如果指定了指标,它将在评估期间测量最佳检查点。如果通过了一系列指标,它将测量与通过的指标相对应的一组最佳检查点。
- 关于
ParamSchedulerHook,我们可以找到继承的配置文件中的参数:
default_hooks = dict(
param_scheduler=dict(
type='YOLOv5ParamSchedulerHook',
scheduler_type='cosine',
lr_factor=lr_factor,
max_epochs=max_epochs),
checkpoint=dict(
type='CheckpointHook',
interval=save_epoch_intervals,
max_keep_ckpts=max_keep_ckpts,
save_best='auto'))
- 教程的写法相当于仅改变了
param_scheduler中的max_epochs。
LoggerHook负责收集日志并把日志输出到终端或者输出到文件、TensorBoard 等后端。教程中每迭代10次(interval=10)就输出(或保存)一次日志
自定义hook
custom_hooks = [
dict(
type='EMAHook',
ema_type='ExpMomentumEMA',
momentum=0.0001,
update_buffers=True,
strict_load=False,
priority=49),
dict(
type='mmdet.PipelineSwitchHook',
switch_epoch=max_epochs - _base_.num_last_epochs,
switch_pipeline=_base_.train_pipeline_stage2)
]
EMAHook在训练过程中对模型执行指数滑动平均操作,目的是提高模型的鲁棒性。注意:指数滑动平均生成的模型只用于验证和测试,不影响训练。- EMAHooK API文档,部分参数解释
ema_type:EMA策略momentum:用于更新ema参数的动量update_buffers:如果为True,它将计算模型参数和缓冲区的运行平均值。strict_load:是否严格强制state_dict检查点中的键与返回的键匹配self.module.state_dictpriority:hook优先级
ExpMomentumEMA我没有在官方文档中找到,可以在Pycharm中使用快捷键Ctrl + Shift + F搜索class ExpMomentumEMA。注释信息为:
class ExpMomentumEMA(MMDET_ExpMomentumEMA):
"""ExpMomentumEMA类是一种使用指数动量策略的指数移动平均(EMA)方法,常用于YOLO模型。
参数:
model(nn.Module):要进行平均的模型。
momentum(float):用于更新EMA参数的动量。
EMA参数的更新公式为:
averaged_param = (1-momentum) * averaged_param + momentum * source_param。默认值为0.0002。
gamma(int):在训练初期使用较大的动量,逐渐过渡到较小的值,以平滑地更新EMA模型。动量计算公式为
(1 - momentum) * exp(-(1 + steps) / gamma) + momentum。默认值为2000。
interval(int):两次更新之间的间隔。默认值为1。
device(torch.device,可选):如果提供,平均模型将存储在该device上。默认值为None。
update_buffers(bool):如果为True,将计算模型的参数和缓冲区的运行平均值。默认值为False。
"""
mmdet.PipelineSwitchHook是MMDetection库中的一部分,用于在switch_epoch切换数据管道,API文档
数据集可视化
- 我们可以按照教程,使用
.\tools\analysis_tools\dataset_analysis.py文件分析数据。注意:此时的数据是经过变换后的,比如进行了ClassBalancedDataset或RepeatDataset操作的
- 该文件可以生成4种分析图:
- 显示类别和
bbox实例个数的分布图:show_bbox_num
- 显示类别和
bbox实例宽、高的分布图:show_bbox_wh
- 显示类别和
bbox实例宽/高比例的分布图:show_bbox_wh_ratio
- 基于面积规则下,显示类别和
bbox实例面积的分布图:show_bbox_area
- 修改文件参数默认值,按照教程,修改
----config、--val-dataset、--class-name、--area-rule、--func和--out-dir参数,(注意,需要将代码中的config替换成--config才能运行,否则报错)添加default选项,代码如下
def parse_args():
parser = argparse.ArgumentParser(
description='Distribution of categories and bbox instances')
parser.add_argument('--config', default='./configs/custom_dataset/yolov6_l_syncbn_fast_1xb8-100e_animal.py', help='config file path')
parser.add_argument(
'--val-dataset',
default=False,
action='store_true',
help='The default train_dataset.'
'To change it to val_dataset, enter "--val-dataset"')
parser.add_argument(
'--class-name',
default=None,
type=str,
help='Display specific class, e.g., "bicycle"')
parser.add_argument(
'--area-rule',
default=None,
type=int,
nargs='+',
help='Redefine area rules,but no more than three numbers.'
' e.g., 30 70 125')
parser.add_argument(
'--func',
default=None,
type=str,
choices=[
'show_bbox_num', 'show_bbox_wh', 'show_bbox_wh_ratio',
'show_bbox_area'
],
help='Dataset analysis function selection.')
parser.add_argument(
'--out-dir',
default='./dataset_analysis',
type=str,
help='Output directory of dataset analysis visualization results,'
' Save in "./dataset_analysis/" by default')
args = parser.parse_args()
return args
python tools/analysis_tools/dataset_analysis.py ${CONFIG} \
[--val-dataset ${TYPE}] \
[--class-name ${CLASS_NAME}] \
[--area-rule ${AREA_RULE}] \
[--func ${FUNC}] \
[--out-dir ${OUT_DIR}]
python tools/analysis_tools/dataset_analysis.py ./configs/custom_dataset/yolov6_l_syncbn_fast_1xb8-100e_animal.py \
--out-dir work_dirs/dataset_analysis_cat/train_dataset
优化Anchor尺寸
- 由于我训练的是YOLOV6模型,所以不需要进行该步
可视化config配置中数据处理部分
- 我们可以按照教程,使用
.\tools\analysis_tools\browse_dataset.py文件可视化数据处理部分。
- 修改文件参数默认值,按照教程,修改
config为--config,运行代码
def parse_args():
parser = argparse.ArgumentParser(description='Browse a dataset')
parser.add_argument('--config', default='./configs/custom_dataset/yolov6_l_syncbn_fast_1xb8-100e_animal.py', help='train config file path')
parser.add_argument(
'--phase',
'-p',
default='train',
type=str,
choices=['train', 'test', 'val'],
help='phase of dataset to visualize, accept "train" "test" and "val".'
' Defaults to "train".')
parser.add_argument(
'--mode',
'-m',
default='transformed',
type=str,
choices=['original', 'transformed', 'pipeline'],
help='display mode; display original pictures or '
'transformed pictures or comparison pictures. "original" '
'means show images load from disk; "transformed" means '
'to show images after transformed; "pipeline" means show all '
'the intermediate images. Defaults to "transformed".')
parser.add_argument(
'--out-dir',
default='output',
type=str,
help='If there is no display interface, you can save it.')
parser.add_argument('--not-show', default=False, action='store_true')
parser.add_argument(
'--show-number',
'-n',
type=int,
default=sys.maxsize,
help='number of images selected to visualize, '
'must bigger than 0. if the number is bigger than length '
'of dataset, show all the images in dataset; '
'default "sys.maxsize", show all images in dataset')
parser.add_argument(
'--show-interval',
'-i',
type=float,
default=3,
help='the interval of show (s)')
parser.add_argument(
'--cfg-options',
nargs='+',
action=DictAction,
help='override some settings in the used config, the key-value pair '
'in xxx=yyy format will be merged into config file. If the value to '
'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
'Note that the quotation marks are necessary and that no white space '
'is allowed.')
args = parser.parse_args()
return args
python tools/analysis_tools/browse_dataset.py ./configs/custom_dataset/yolov6_l_syncbn_fast_1xb8-100e_animal.py \
--show-interval 3
训练
训练可视化
MMYOLO目前提供 2 种方式wandb和TensorBoard,根据自己的情况选择其一即可
wandb
- 个人比较推荐的一种方式,因为只需要登录网页端就可以实时看到训练情况,非常方便,而且可视化做的更好
- 首先需要在wandb官网注册,并且在设置中获取到
wandb的``API Keys
- 然后在命令行安装wandb,并进行登录
pip install wandb
wandb login
- 最后在新建的
config文件.\configs\custom_dataset\yolov6_l_syncbn_fast_1xb8-100e_animal.py末尾添加配置代码:
visualizer = dict(vis_backends=[dict(type='LocalVisBackend'), dict(type='WandbVisBackend')])
TensorBoard
pip install tensorboard
- 然后在新建的
config文件.\configs\custom_dataset\yolov6_l_syncbn_fast_1xb8-100e_animal.py末尾添加配置代码:
visualizer = dict(vis_backends=[dict(type='LocalVisBackend'),dict(type='TensorboardVisBackend')])
- 运行训练命令后,
Tensorboard文件会生成在可视化文件夹work_dirs\yolov6_l_syncbn_fast_1xb8-100e_animal\${TIMESTAMP}\vis_data下, 运行下面的命令便可以在网页链接使用Tensorboard查看loss、学习率和coco/bbox_mAP等可视化数据了:
执行训练
- 打开
.\tools\train.py文件,修改参数,将config改为--config,并设定默认值。
def parse_args():
parser = argparse.ArgumentParser(description='Train a detector')
parser.add_argument('--config',default='./configs/custom_dataset/yolov6_l_syncbn_fast_1xb8-100e_animal.py' ,help='train config file path')
parser.add_argument('--work-dir', help='the dir to save logs and models')
parser.add_argument(
'--amp',
action='store_true',
default=False,
help='enable automatic-mixed-precision training')
parser.add_argument(
'--resume',
nargs='?',
type=str,
const='auto',
help='If specify checkpoint path, resume from it, while if not '
'specify, try to auto resume from the latest checkpoint '
'in the work directory.')
parser.add_argument(
'--cfg-options',
nargs='+',
action=DictAction,
help='override some settings in the used config, the key-value pair '
'in xxx=yyy format will be merged into config file. If the value to '
'be overwritten is a list, it should be like key="[a,b]" or key=a,b '
'It also allows nested list/tuple values, e.g. key="[(a,b),(c,d)]" '
'Note that the quotation marks are necessary and that no white space '
'is allowed.')
parser.add_argument(
'--launcher',
choices=['none', 'pytorch', 'slurm', 'mpi'],
default='none',
help='job launcher')
parser.add_argument('--local_rank', type=int, default=0)
args = parser.parse_args()
if 'LOCAL_RANK' not in os.environ:
os.environ['LOCAL_RANK'] = str(args.local_rank)
return args
- 运行后可以在
wandb网页或者tensorboard中看到训练的具体信息

- 下面是 1 x 2080Ti、batch size = 8,训练100 epoch 最佳精度权重
work_dirs\best_coco_bbox_mAP_epoch_97 得出来的精度:
coco/bbox_mAP: 0.8910 coco/bbox_mAP_50: 1.0000 coco/bbox_mAP_75: 1.0000 coco/bbox_mAP_s: -1.0000 coco/bbox_mAP_m: -1.0000 coco/bbox_mAP_l: 0.8910 data_time: 0.0004 time: 0.0256
推理
- 使用最佳模型进行推理,打开
.\demo\image_demo.py文件,更改--img、--config、--checkpoint参数,值得注意的是img参数可以是文件夹路径,可以是单独的文件路径,也可以是URL。--config参数是我们新建的那个配置文件。--checkpoint参数是训练的最佳权重。
def parse_args():
parser = ArgumentParser()
parser.add_argument('--img', default='./data/images/Image_20230621152815633.bmp', help='Image path, include image file, dir and URL.')
parser.add_argument('--config', default='./configs/custom_dataset/yolov6_l_syncbn_fast_1xb8-100e_animal.py', help='Config file')
parser.add_argument('--checkpoint', default='./work_dirs/best_coco_bbox_mAP_epoch_97.pth', help='Checkpoint file')
parser.add_argument(
'--out-dir', default='./output', help='Path to output file')
parser.add_argument(
'--device', default='cpu', help='Device used for inference')
parser.add_argument(
'--show', action='store_true', help='Show the detection results')
parser.add_argument(
'--deploy',
action='store_true',
help='Switch model to deployment mode')
parser.add_argument(
'--tta',
action='store_true',
help='Whether to use test time augmentation')
parser.add_argument(
'--score-thr', type=float, default=0.3, help='Bbox score threshold')
parser.add_argument(
'--class-name',
nargs='+',
type=str,
help='Only Save those classes if set')
parser.add_argument(
'--to-labelme',
action='store_true',
help='Output labelme style label file')
args = parser.parse_args()
return args
其他帮助文档
- 下面列举几个我认为有帮助的文档(有些文档不在最新文档中,可以打开官方文档在左下角切换版本为
v:dev)
- 训练和测试技巧
- 多尺度训练和测试
- 冻结指定网络层权重
- 轻松更换主干网络