Elasticsearch7.x - REST 基础操作
目录
-
- 索引操作
-
- 创建索引
- 查看所有索引
- 查看单个索引
- 删除索引
- 文档操作
-
- 创建文档
- 查看文档
- 修改文档
- 修改字段
- 删除文档
- 条件删除文档
- 映射操作
-
- 创建映射
- 查看映射
- 索引映射关联
- 高级查询
-
- 查询所有文档
- 匹配查询
- 字段匹配查询
- 关键字精确查询
- 多关键字精确查询
- 指定查询字段
- 过滤字段
- 组合查询
- 范围查询
- 组合+范围查询
- 模糊查询
- 单字排序
- 多字段排序
- 高亮查询
- 分页查询
- 聚合查询
- State聚合
- 桶聚合查询
- QA
-
- failed to create query: Cannot search on field [age] since it is not indexed.
索引操作
创建索引
对比关系型数据库,创建索引就等同于创建数据库
在 Postman 中,向 ES 服务器发 **PUT **请求 :http://127.0.0.1:9200/shopping

{
"acknowledged"【响应结果】: true, # true 操作成功
"shards_acknowledged"【分片结果】: true, # 分片操作成功
"index"【索引名称】: "shopping"
}
# 注意:创建索引库的分片数默认 1 片,在 7.0.0 之前的 Elasticsearch 版本中,默认 5 片
如果重复添加索引,会返回错误信息
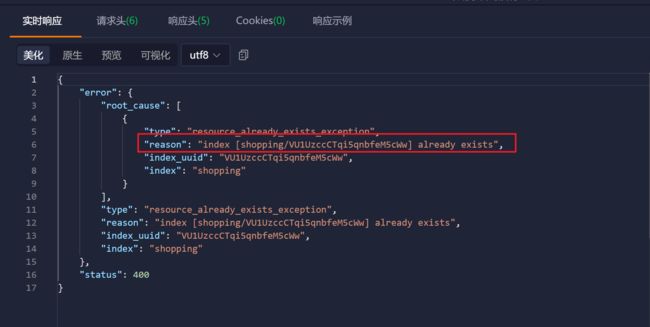
查看所有索引
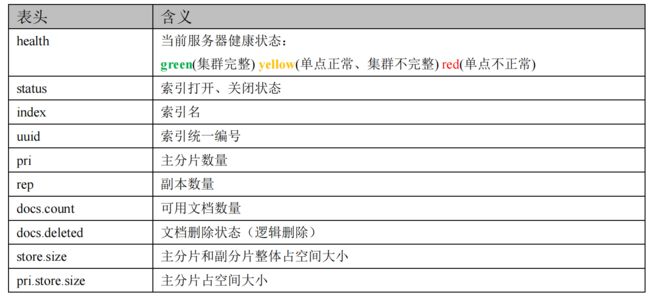
在 Postman 中,向 ES 服务器发 **GET **请求 :http://127.0.0.1:9200/_cat/indices?v
:::warning
这里请求路径中的_cat 表示查看的意思,indices 表示索引,所以整体含义就是查看当前 ES
服务器中的所有索引,就好像 MySQL 中的 show tables 的感觉,服务器响应结果如下
:::
查看单个索引
在 Postman 中,向 ES 服务器发 **GET **请求 :http://127.0.0.1:9200/shopping
查看索引向 ES 服务器发送的请求路径和创建索引是一致的。但是 HTTP 方法不一致。这里
可以体会一下 RESTful 的意义,
请求后,服务器响应结果如下:
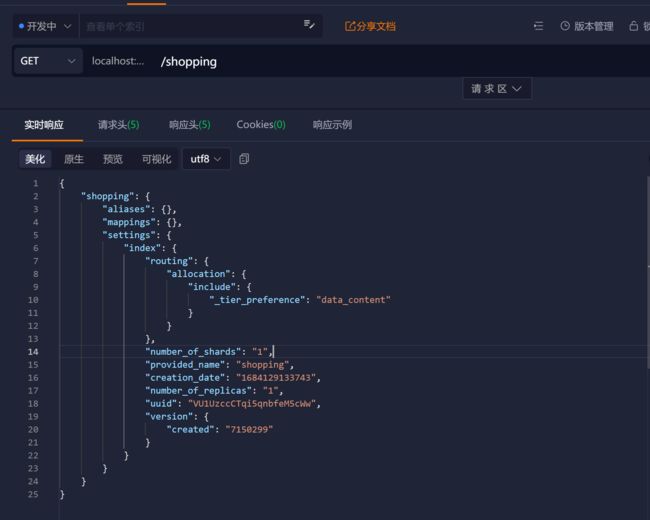
{
"shopping"【索引名】: {
"aliases"【别名】: {},
"mappings"【映射】: {},
"settings"【设置】: {
"index"【设置 - 索引】: {
"creation_date"【设置 - 索引 - 创建时间】: "1614265373911",
"number_of_shards"【设置 - 索引 - 主分片数量】: "1",
"number_of_replicas"【设置 - 索引 - 副分片数量】: "1",
"uuid"【设置 - 索引 - 唯一标识】: "eI5wemRERTumxGCc1bAk2A",
"version"【设置 - 索引 - 版本】: {
"created": "7080099"
},
"provided_name"【设置 - 索引 - 名称】: "shopping"
}
}
}
}
删除索引
在 Postman 中,向 ES 服务器发 **DELETE **请求 :http://127.0.0.1:9200/shopping

重新访问索引时,服务器返回响应:索引不存在

文档操作
创建文档
索引已经创建好了,接下来我们来创建文档,并添加数据。这里的文档可以类比为关系型数
据库中的表数据,添加的数据格式为 JSON 格式
在 Postman 中,向 ES 服务器发 **POST 请求 :http://127.0.0.1:9200/shopping/_doc **
请求体内容为:
{
"title":"小米手机",
"category":"小米",
"images":"http://www.gulixueyuan.com/xm.jpg",
"price":3999.00
}

此处发送请求的方式必须为 POST,不能是 PUT,否则会发生错误
{
"_index"【索引】: "shopping",
"_type"【类型-文档】: "_doc",
"_id"【唯一标识】: "Xhsa2ncBlvF_7lxyCE9G", #可以类比为 MySQL 中的主键,随机生成
"_version"【版本】: 1,
"result"【结果】: "created", #这里的 create 表示创建成功
"_shards"【分片】: {
"total"【分片 - 总数】: 2,
"successful"【分片 - 成功】: 1,
"failed"【分片 - 失败】: 0
},
"_seq_no": 0,
"_primary_term": 1
}
上面的数据创建后,由于没有指定数据唯一性标识(ID),默认情况下,ES 服务器会随机
生成一个。
如果想要自定义唯一性标识,需要在创建时指定:http://127.0.0.1:9200/shopping/_doc/**1**

查看文档
查看文档时,需要指明文档的唯一性标识,类似于 MySQL 中数据的主键查询
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/shopping/_doc/1


修改文档
和新增文档一样,输入相同的 URL 地址请求,如果请求体变化,会将原有的数据内容覆盖
在 Postman 中,向 ES 服务器发 **POST **请求 :http://127.0.0.1:9200/shopping**/_doc/1**
{
"title":"华为手机",
"category":"华为",
"images":"http://www.gulixueyuan.com/hw.jpg",
"price":4999.00
}


修改字段
修改数据时,也可以只修改某一给条数据的局部信息
在 Postman 中,向 ES 服务器发 **POST **请求 :http://127.0.0.1:9200/shopping/**_update/1 **
请求体内容为:
{
"doc": {
"price":3000.00
}
}
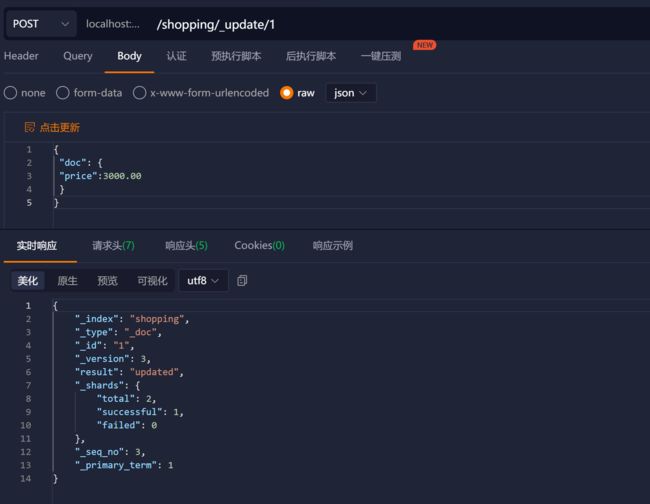
根据唯一性标识,查询文档数据,文档数据已经更新

删除文档
删除一个文档不会立即从磁盘上移除,它只是被标记成已删除(逻辑删除)。
在 Postman 中,向 ES 服务器发 **DELETE **请求 :http://127.0.0.1:9200/shopping**/_doc/1**


删除后再查询当前文档信息

如果删除一个并不存在的文档

“result”【结果】: “not_found”, # not_found 表示未查找到
条件删除文档
一般删除数据都是根据文档的唯一性标识进行删除,实际操作时,也可以根据条件对多条数
据进行删除
首先分别增加多条数据:
{
"title":"小米手机",
"category":"小米",
"images":"http://www.gulixueyuan.com/xm.jpg",
"price":4000.00
}
{
"title":"华为手机",
"category":"华为",
"images":"http://www.gulixueyuan.com/hw.jpg",
"price":4000.00
}
向 ES 服务器发 POST 请求 :http://127.0.0.1:9200/shopping/_delete_by_query
{
"query":{
"match":{
"price":4000.00
}
}
}
删除成功后,服务器响应结果:


映射操作
有了索引库,等于有了数据库中的 database。接下来就需要建索引库(index)中的映射了,类似于数据库(database)中的表结构(table)。
创建数据库表需要设置字段名称,类型,长度,约束等;索引库也一样,需要知道这个类型
下有哪些字段,每个字段有哪些约束信息,这就叫做映射(mapping)。
创建映射
注意: 需要先创建索引
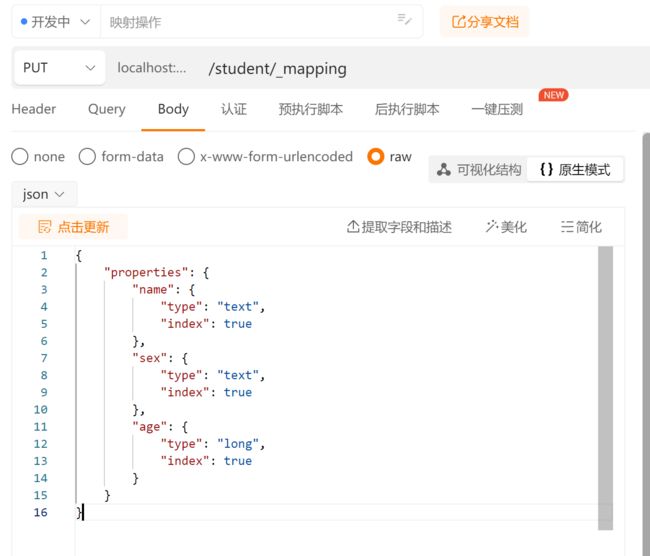
在 Postman 中,向 ES 服务器发 PUT 请求 :http://127.0.0.1:9200/student/_mapping
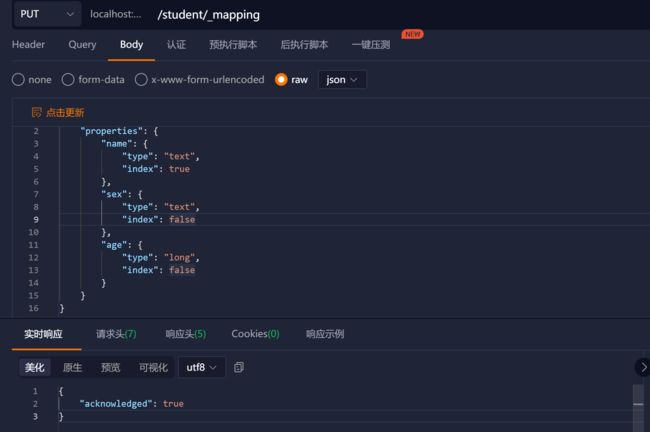
{
"properties": {
"name": {
"type": "text",
"index": true
},
"sex": {
"type": "text",
"index": true
},
"age": {
"type": "long",
"index": true
}
}
}
映射数据说明:
字段名:任意填写,下面指定许多属性,例如:title、subtitle、images、price
type:类型,Elasticsearch 中支持的数据类型非常丰富,说几个关键的:
- String 类型,又分两种:
- text:可分词
- keyword:不可分词,数据会作为完整字段进行匹配
- Numerical:数值类型,分两类
- 基本数据类型:long、integer、short、byte、double、float、half_float
- 浮点数的高精度类型:scaled_float
- Date:日期类型
- Array:数组类型
- Object:对象
- index:是否索引,默认为 true,也就是说你不进行任何配置,所有字段都会被索引。
- true:字段会被索引,则可以用来进行搜索
- false:字段不会被索引,不能用来搜索
- store:是否将数据进行独立存储,默认为 false
- 原始的文本会存储在_source 里面,默认情况下其他提取出来的字段都不是独立存储 的,是从_source 里面提取出来的。当然你也可以独立的存储某个字段,只要设置 “store”: true 即可,获取独立存储的字段要比从_source 中解析快得多,但是也会占用 更多的空间,所以要根据实际业务需求来设置。
- analyzer:分词器,这里的 ik_max_word 即使用 ik 分词器,后面会有专门的章节学习
查看映射
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_mapping
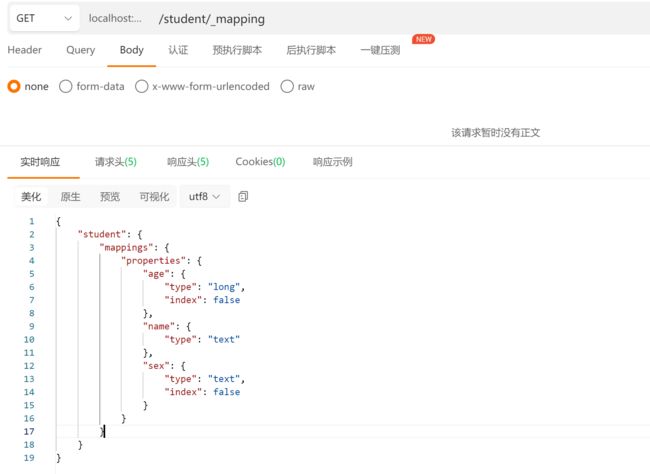
索引映射关联
在 Postman 中,向 ES 服务器发 **PUT **请求 :http://127.0.0.1:9200/student1

高级查询
Elasticsearch 提供了基于 JSON 提供完整的查询 DSL 来定义查询
定义数据 :
# POST /student/_doc/1001
{
"name":"zhangsan",
"nickname":"zhangsan",
"sex":"男",
"age":30
}
# POST /student/_doc/1002
{
"name":"lisi",
"nickname":"lisi",
"sex":"男",
"age":20
}
# POST /student/_doc/1003
{
"name":"wangwu",
"nickname":"wangwu",
"sex":"女",
"age":40
}
# POST /student/_doc/1004
{
"name":"zhangsan1",
"nickname":"zhangsan1",
"sex":"女",
"age":50
}
# POST /student/_doc/1005
{
"name":"zhangsan2",
"nickname":"zhangsan2",
"sex":"女",
"age":30
}
查询所有文档
在 Postman 中,向 ES 服务器发 **GET **请求 :http://127.0.0.1:9200/student/_search
{
"query": {
"match_all": {}
}
}
# "query":这里的 query 代表一个查询对象,里面可以有不同的查询属性
# "match_all":查询类型,例如:match_all(代表查询所有), match,term , range 等等
# {查询条件}:查询条件会根据类型的不同,写法也有差异

{
"took": 791,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1002",
"_score": 1,
"_source": {
"name": "lisi",
"nickname": "lisi",
"sex": "男",
"age": 20
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1003",
"_score": 1,
"_source": {
"name": "wangwu",
"nickname": "wangwu",
"sex": "女",
"age": 40
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1004",
"_score": 1,
"_source": {
"name": "zhangsan1",
"nickname": "zhangsan1",
"sex": "女",
"age": 50
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1005",
"_score": 1,
"_source": {
"name": "zhangsan2",
"nickname": "zhangsan2",
"sex": "女",
"age": 30
}
}
]
}
}

匹配查询
match 匹配类型查询,会把查询条件进行分词,然后进行查询,多个词条之间是 or 的关系
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{
"query": {
"match": {
"name": "zhangsan"
}
}
}
执行结果
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1.3862942,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
}
]
}
}
字段匹配查询
multi_match 与 match 类似,不同的是它可以在多个字段中查询。
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{
"query": {
"multi_match": {
"query": "zhangsan",
"fields": ["name","nickname"]
}
}
}
执行结果如下
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1.3862942,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
}
]
}
}
关键字精确查询
term 查询,精确的关键词匹配查询,不对查询条件进行分词。
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{
"query": {
"term": {
"name": {
"value": "zhangsan"
}
}
}
}
执行结果如下
{
"took": 4,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1.3862942,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
}
]
}
}
多关键字精确查询
terms 查询和 term 查询一样,但它允许你指定多值进行匹配。
如果这个字段包含了指定值中的任何一个值,那么这个文档满足条件,类似于 mysql 的 in
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{
"query": {
"terms": {
"name": [
"zhangsan",
"lisi"
]
}
}
}
执行结果
{
"took": 12,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1002",
"_score": 1,
"_source": {
"name": "lisi",
"nickname": "lisi",
"sex": "男",
"age": 20
}
}
]
}
}
指定查询字段
默认情况下,Elasticsearch 在搜索的结果中,会把文档中保存在_source 的所有字段都返回。
如果我们只想获取其中的部分字段,我们可以添加_source 的过滤
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{
"_source": ["name","nickname"],
"query": {
"terms": {
"nickname": ["zhangsan"]
}
}
}
执行结果如下 :
{
"took": 18,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan"
}
}
]
}
}
过滤字段
我们也可以通过:
- includes:来指定想要显示的字段
- excludes:来指定不想要显示的字段
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{
"_source": {
"includes": [
"name",
"nickname"
]
},
"query": {
"terms": {
"nickname": [
"zhangsan"
]
}
}
}
执行结果如下
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan"
}
}
]
}
}
在 Postman 中,向 ES 服务器发 **GET **请求 :http://127.0.0.1:9200/student/_search
{
"_source": {
"excludes": [
"name",
"nickname"
]
},
"query": {
"terms": {
"nickname": [
"zhangsan"
]
}
}
}
执行结果如下 :
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1,
"_source": {
"sex": "男",
"age": 30
}
}
]
}
}
组合查询
bool把各种其它查询通过must(必须 )、must_not(必须不)、should(应该)的方
式进行组合
在 Postman 中,向 ES 服务器发 **GET **请求 :http://127.0.0.1:9200/student/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "zhangsan"
}
}
],
"must_not": [
{
"match": {
"age": "40"
}
}
],
"should": [
{
"match": {
"sex": "男"
}
}
]
}
}
}
执行结果如下 :
{
"took": 238,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 2.261763,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 2.261763,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
}
]
}
}
范围查询
range 查询找出那些落在指定区间内的数字或者时间。range 查询允许以下字符

在 Postman 中,向 ES 服务器发 **GET **请求 :http://127.0.0.1:9200/student/_search
{
"query": {
"range": {
"age": {
"gte": 30,
"lte": 35
}
}
}
}
查询年龄范围在 30 ~ 35 :
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 2,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1005",
"_score": 1,
"_source": {
"name": "zhangsan2",
"nickname": "zhangsan2",
"sex": "女",
"age": 30
}
}
]
}
}
组合+范围查询
在 Postman 中,向 ES 服务器发 **GET **请求 :http://127.0.0.1:9200/student/_search
{
"query": {
"bool": {
"must": [
{
"range": {
"age": {
"gte": 30,
"lte": 35
}
}
},
{
"match": {
"sex": "男"
}
}
]
}
}
}
查询结果 :
{
"took": 6,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.8754687,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1.8754687,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
}
]
}
}
模糊查询
返回包含与搜索字词相似的字词的文档。
编辑距离是将一个术语转换为另一个术语所需的一个字符更改的次数。这些更改可以包括
- 更改字符(box → fox)
- 删除字符(black → lack)
- 插入字符(sic → sick)
- 转置两个相邻字符(act → cat)
为了找到相似的术语,fuzzy 查询会在指定的编辑距离内创建一组搜索词的所有可能的变体
或扩展。然后查询返回每个扩展的完全匹配。
**通过 fuzziness 修改编辑距离。一般使用默认值 AUTO,根据术语的长度生成编辑距离。 **
在 Postman 中,向 ES 服务器发 **GET **请求 :http://127.0.0.1:9200/student/_search
{
"query": {
"fuzzy": {
"name": {
"value": "zhangsan"
}
}
}
}
执行结果
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1.3862942,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1004",
"_score": 1.2130076,
"_source": {
"name": "zhangsan1",
"nickname": "zhangsan1",
"sex": "女",
"age": 50
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1005",
"_score": 1.2130076,
"_source": {
"name": "zhangsan2",
"nickname": "zhangsan2",
"sex": "女",
"age": 30
}
}
]
}
}
在 Postman 中,向 ES 服务器发 **GET **请求 :http://127.0.0.1:9200/student/_search
{
"query": {
"fuzzy": {
"name": {
"value": "zhangsan",
"fuzziness": 2
}
}
}
}
执行结果如下 :
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1.3862942,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1004",
"_score": 1.2130076,
"_source": {
"name": "zhangsan1",
"nickname": "zhangsan1",
"sex": "女",
"age": 50
}
},
{
"_index": "student",
"_type": "_doc",
"_id": "1005",
"_score": 1.2130076,
"_source": {
"name": "zhangsan2",
"nickname": "zhangsan2",
"sex": "女",
"age": 30
}
}
]
}
}
单字排序
sort 可以让我们按照不同的字段进行排序,并且通过 order 指定排序的方式。desc 降序,asc
升序。
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{
"query": {
"match": {
"name": "zhangsan"
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
执行结果如下
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1004",
"_score": null,
"_source": {
"name": "zhangsan1",
"nickname": "zhangsan1",
"sex": "女",
"age": 50
},
"sort": [
50
]
},
{
"_index": "student",
"_type": "_doc",
"_id": "1003",
"_score": null,
"_source": {
"name": "wangwu",
"nickname": "wangwu",
"sex": "女",
"age": 40
},
"sort": [
40
]
},
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": null,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
},
"sort": [
30
]
},
{
"_index": "student",
"_type": "_doc",
"_id": "1005",
"_score": null,
"_source": {
"name": "zhangsan2",
"nickname": "zhangsan2",
"sex": "女",
"age": 30
},
"sort": [
30
]
},
{
"_index": "student",
"_type": "_doc",
"_id": "1002",
"_score": null,
"_source": {
"name": "lisi",
"nickname": "lisi",
"sex": "男",
"age": 20
},
"sort": [
20
]
}
]
}
}
多字段排序
假定我们想要结合使用 age 和 _score 进行查询,并且匹配的结果首先按照年龄排序,然后
按照相关性得分排序
在 Postman 中,向 ES 服务器发 **GET **请求 :http://127.0.0.1:9200/student/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
},
{
"_score": {
"order": "desc"
}
}
]
}
执行结果
{
"took": 3,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1004",
"_score": 1,
"_source": {
"name": "zhangsan1",
"nickname": "zhangsan1",
"sex": "女",
"age": 50
},
"sort": [
50,
1
]
},
{
"_index": "student",
"_type": "_doc",
"_id": "1003",
"_score": 1,
"_source": {
"name": "wangwu",
"nickname": "wangwu",
"sex": "女",
"age": 40
},
"sort": [
40,
1
]
},
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
},
"sort": [
30,
1
]
},
{
"_index": "student",
"_type": "_doc",
"_id": "1005",
"_score": 1,
"_source": {
"name": "zhangsan2",
"nickname": "zhangsan2",
"sex": "女",
"age": 30
},
"sort": [
30,
1
]
},
{
"_index": "student",
"_type": "_doc",
"_id": "1002",
"_score": 1,
"_source": {
"name": "lisi",
"nickname": "lisi",
"sex": "男",
"age": 20
},
"sort": [
20,
1
]
}
]
}
}
高亮查询
在进行关键字搜索时,搜索出的内容中的关键字会显示不同的颜色,称之为高亮。
Elasticsearch 可以对查询内容中的关键字部分,进行标签和样式(高亮)的设置。
在使用 match 查询的同时,加上一个 highlight 属性:
- pre_tags:前置标签
- post_tags:后置标签
- fields:需要高亮的字段
- title:这里声明 title 字段需要高亮,后面可以为这个字段设置特有配置,也可以空
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{
"query": {
"match": {
"name": "zhangsan"
}
},
"highlight": {
"pre_tags": "",
"post_tags": "",
"fields": {
"name": {}
}
}
}
执行结果
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.3862942,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1001",
"_score": 1.3862942,
"_source": {
"name": "zhangsan",
"nickname": "zhangsan",
"sex": "男",
"age": 30
},
"highlight": {
"name": [
"zhangsan"
]
}
}
]
}
}
分页查询
from:当前页的起始索引,默认从 0 开始。 from = (pageNum - 1) * size
size:每页显示多少条
在 Postman 中,向 ES 服务器发 **GET **请求 :http://127.0.0.1:9200/student/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 0,
"size": 2
}
执行结果
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "student",
"_type": "_doc",
"_id": "1004",
"_score": null,
"_source": {
"name": "zhangsan1",
"nickname": "zhangsan1",
"sex": "女",
"age": 50
},
"sort": [
50
]
},
{
"_index": "student",
"_type": "_doc",
"_id": "1003",
"_score": null,
"_source": {
"name": "wangwu",
"nickname": "wangwu",
"sex": "女",
"age": 40
},
"sort": [
40
]
}
]
}
}
聚合查询
聚合允许使用者对 es 文档进行统计分析,类似与关系型数据库中的 group by,当然还有很
多其他的聚合,例如取最大值、平均值等等。
对某个字段取最大值 max
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{
"aggs": {
"max_age": {
"max": {
"field": "age"
}
}
},
"size": 0
}

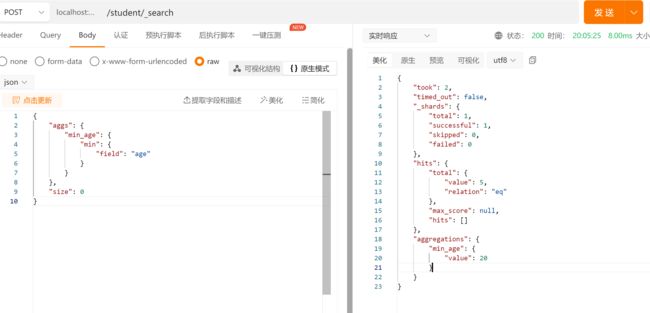
**对某个字段取最小值 min **
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{
"aggs": {
"min_age": {
"min": {
"field": "age"
}
}
},
"size": 0
}
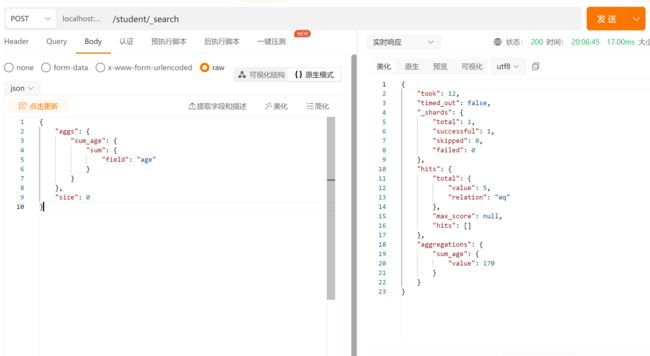
对某个字段求和 sum
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{
"aggs": {
"sum_age": {
"sum": {
"field": "age"
}
}
},
"size": 0
}
对某个字段取平均值 avg
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{
"aggs": {
"avg_age": {
"avg": {
"field": "age"
}
}
},
"size": 0
}

对某个字段的值进行去重之后再取总数
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{
"aggs": {
"avg_age": {
"avg": {
"field": "age"
}
}
},
"size": 0
}

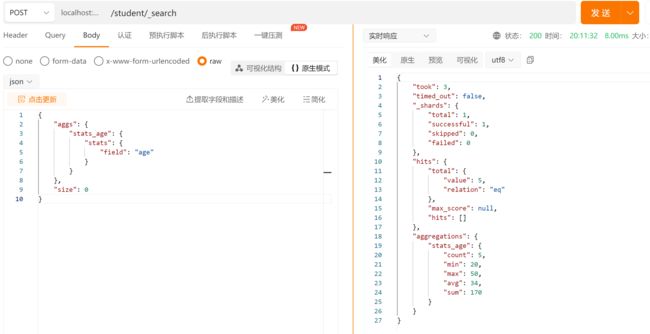
State聚合
stats 聚合,对某个字段一次性返回 count,max,min,avg 和 sum 五个指标
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{
"aggs": {
"stats_age": {
"stats": {
"field": "age"
}
}
},
"size": 0
}
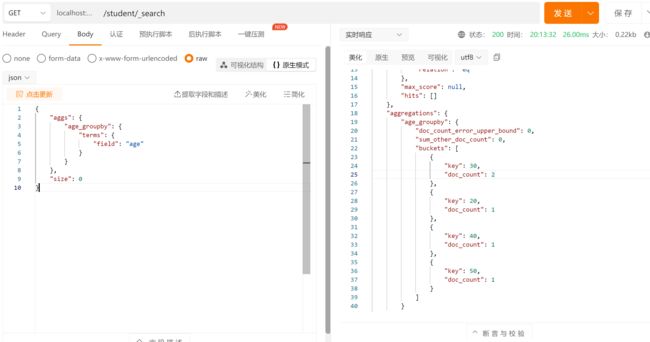
桶聚合查询
桶聚和相当于 sql 中的 group by 语句
terms 聚合,分组统计
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{
"aggs": {
"age_groupby": {
"terms": {
"field": "age"
}
}
},
"size": 0
}
在 terms 分组下再进行聚合
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{
"aggs": {
"age_groupby": {
"terms": {
"field": "age"
},
"aggs": {
"sum_age": {
"sum": {
"field": "age"
}
}
}
}
},
"size": 0
}
分组求年龄和 执行结果
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 5,
"relation": "eq"
},
"max_score": null,
"hits": []
},
"aggregations": {
"age_groupby": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 30,
"doc_count": 2,
"sum_age": {
"value": 60
}
},
{
"key": 20,
"doc_count": 1,
"sum_age": {
"value": 20
}
},
{
"key": 40,
"doc_count": 1,
"sum_age": {
"value": 40
}
},
{
"key": 50,
"doc_count": 1,
"sum_age": {
"value": 50
}
}
]
}
}
}
QA
failed to create query: Cannot search on field [age] since it is not indexed.
{
"error": {
"root_cause": [
{
"type": "query_shard_exception",
"reason": "failed to create query: Cannot search on field [age] since it is not indexed.",
"index_uuid": "TVDw9Y2TSkyVrSSr3YfAug",
"index": "student"
}
],
"type": "search_phase_execution_exception",
"reason": "all shards failed",
"phase": "query",
"grouped": true,
"failed_shards": [
{
"shard": 0,
"index": "student",
"node": "TKF8MSkJRCW3XVne72ASkQ",
"reason": {
"type": "query_shard_exception",
"reason": "failed to create query: Cannot search on field [age] since it is not indexed.",
"index_uuid": "TVDw9Y2TSkyVrSSr3YfAug",
"index": "student",
"caused_by": {
"type": "illegal_argument_exception",
"reason": "Cannot search on field [age] since it is not indexed."
}
}
}
]
},
"status": 400
}
如果索引映射已经存在, 就必须删除索引, 索引映射无法修改和删除
添加映射 , 开启 age 的索引