EasyExcel生成带下拉列表或二级级联列表的Excel模版+自定义校验导入数据(附仓库)
EasyExcel生成带下拉列表或二级级联列表的Excel模版+自定义校验导入数据(附仓库)
目录
- EasyExcel生成带下拉列表或二级级联列表的Excel模版+自定义校验导入数据(附仓库)
-
- 前言
- 一、说明
- 二、仓库
- 三、 简介
- 四、实现
-
- 1. @ExcelSelected
- 2. 列的预处理对象
- 3. 解析注解
- 4 .SheetWriteHandler 自定义导出处理器
- 5. 工具类
- 五、导出
-
- 1. EasyExcel方式
- 2. 插件方式
- 3. 模版类
- 4.模版效果
- 六、导入
-
- 1. EasyExcel方式
- 2. 插件方式
- 2.自定义导入监听器
- 3. 校验数据
-
- 3.1 自定义校验注解
- 3.2 自定义校验器
- 3.3 动态获取数据处理器
- 3.4 校验数据方法
- 3.5 使用注解
- 3.6 校验结果
- 七、迭代
- 结束
前言
项目需求, 导入数据的Excel模版使用下拉数据限制用户输入, 以配合服务端的数据模型; 支持级联处理
一、说明
看仓库更直观, 请参考最新代码, 文档内容更新不会很勤快
二、仓库
插件 excel-common-spring-boot-starter
如果引入上述模块, 且项目中已有EasyExcel时会冲突, 出现异常
示例 excel-starter-example
包含插件使用示例, 以及EasyExcel使用示例
EasyExcel Doc
三、 简介
模块基于Spring AOP能力, 参考 Pig4Cloud 项目的Excel模块, 在请求和响应时, 通过AOP能力将数据封装, 实现类似 @RequestBody 等注解的能力, 具体体现为: 收到请求时, 将Excel中的记录直接封装为集合, 响应时将数据序列化生成Excel文件等. 但这不是本文主要讨论的要点, 这里不赘述.
下面将着重说明如何生成带下拉菜单的Excel文件.
四、实现
本节实现可完全通过单纯使用EasyExcel复用
1. @ExcelSelected
该注解用于描述需要生成下拉菜单的列信息
- 下拉菜单的数据源 (静态, 动态)
- 下拉菜单生效范围 (行数)
- 级联关系中的父列名称
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.FIELD)
@Inherited
public @interface ExcelSelect {
String[] staticData() default {};
String parentColumn() default "";
Class<? extends ColumnDynamicSelectDataHandler> handler() default DefaultColumnDynamicSelectDataHandler.class;
String parameter() default "";
int firstRow() default 1;
int lastRow() default 0x10000;
}
通过接口动态获取数据
- 对于单列的下拉数据, 应返回
Collection - 对于子列, 存在于父列关联时, 应返回
Map, key为父列的可选值
public interface ColumnDynamicSelectDataHandler<T, R> {
Function<T, R> source();
}
2. 列的预处理对象
该对象将保存针对上述注解解析后的信息, 通过该对象, 进而在后续处理中生成下拉菜单
- 下拉数据
- 列索引
- 父列索引
- 行范围
@Data
public class ExcelSelectDataColumn<T> {
private T source;
private String column;
private int columnIndex;
private String parentColumn;
private int parentColumnIndex;
private int firstRow;
private int lastRow;
public T resolveSource(ExcelSelect excelSelect) {
if (excelSelect == null) {
return null;
}
// 获取固定下拉框的内容
final String[] staticData = excelSelect.staticData();
if (ArrayUtil.isNotEmpty(staticData)) {
return (T) Arrays.asList(staticData);
}
// 获取动态下拉框的内容
final Class<? extends ColumnDynamicSelectDataHandler> handlerClass = excelSelect.handler();
if (Objects.nonNull(handlerClass)) {
final ColumnDynamicSelectDataHandler handler = SpringUtil.getBean(handlerClass);
return (T) handler.source().apply(StrUtil.isNotEmpty(excelSelect.parameter()) ? excelSelect.parameter() : null);
}
return null;
}
}
3. 解析注解
最终形成一个以列索引为key的Map集合
- 主动指定@ExcelProperty的列索引需要更复杂的解析逻辑, 这里取舍通过属性顺序指定列顺序
- 处理存在静态变量, 使用了ExcelIgnore注解的场景
private static <T> Map<Integer, ExcelSelectDataColumn> resolveExcelSelect(Class<T> dataClass) {
Map<Integer, ExcelSelectDataColumn> selectedMap = Maps.newHashMap();
final Field[] fields = ReflectUtil.getFields(dataClass,
field -> !field.isAnnotationPresent(ExcelIgnore.class) && !Modifier.isStatic(field.getModifiers())
);
AtomicInteger annotatedIndex = new AtomicInteger(0);
AtomicInteger maxHeadLayers = new AtomicInteger(1);
Arrays.stream(fields)
.forEach(f -> {
ExcelSelect selected = f.getAnnotation(ExcelSelect.class);
ExcelProperty property = f.getAnnotation(ExcelProperty.class);
final int index = annotatedIndex.getAndIncrement();
if (selected != null) {
ExcelSelectDataColumn excelSelectedResolve;
if (StrUtil.isNotEmpty(selected.parentColumn())) {
excelSelectedResolve = new ExcelSelectDataColumn<Map<String, List<String>>>();
} else {
excelSelectedResolve = new ExcelSelectDataColumn<List<String>>();
}
final Object source = excelSelectedResolve.resolveSource(selected);
final int headLayerCount = property != null ? property.value().length : 1;
final String columName = property != null ? property.value()[headLayerCount - 1] : f.getName();
maxHeadLayers.set(Math.max(headLayerCount, maxHeadLayers.get()));
excelSelectedResolve.setParentColumn(selected.parentColumn());
excelSelectedResolve.setColumn(columName);
excelSelectedResolve.setSource(Objects.nonNull(source) ? source : Collections.emptyList());
excelSelectedResolve.setFirstRow(Math.max(selected.firstRow(), headLayerCount));
excelSelectedResolve.setLastRow(selected.lastRow());
excelSelectedResolve.setColumnIndex(index);
selectedMap.put(index, excelSelectedResolve);
}
});
if (CollUtil.isNotEmpty(selectedMap)) {
selectedMap.forEach((k, v) -> {
v.setFirstRow(Math.max(v.getFirstRow(), maxHeadLayers.get()));
});
final Map<String, Integer> indexMap = selectedMap
.values()
.stream()
.collect(Collectors.toMap(ExcelSelectDataColumn::getColumn, ExcelSelectDataColumn::getColumnIndex));
selectedMap.forEach((k, v) -> {
if (indexMap.containsKey(v.getParentColumn())) {
v.setParentColumnIndex(indexMap.get(v.getParentColumn()));
}
});
}
return selectedMap;
}
4 .SheetWriteHandler 自定义导出处理器
通过实现提供的接口, 获得修改Workbook, Sheet等等对象的能力
- 根据注解解析结果, 增加下拉列表和约束
@RequiredArgsConstructor
public class SelectDataSheetWriteHandler implements SheetWriteHandler {
private final Map<Integer, ExcelSelectDataColumn> selectedMap;
@Override
public void beforeSheetCreate(WriteWorkbookHolder writeWorkbookHolder, WriteSheetHolder writeSheetHolder) {}
@Override
public void afterSheetCreate(WriteWorkbookHolder writeWorkbookHolder, WriteSheetHolder writeSheetHolder) {
//尽量少的创建sheet, 也可以只用一个额外的sheet放这些下拉数据
AtomicReference<Sheet> tmpSheet = new AtomicReference<>(null);
AtomicReference<Sheet> tmpCascadeSheet = new AtomicReference<>(null);
AtomicInteger tmpSheetStartCol = new AtomicInteger(0);
AtomicInteger tmpCascadeSheetStartCol = new AtomicInteger(0);
selectedMap.forEach((colIndex, model) -> {
if (StrUtil.isNotEmpty(model.getParentColumn())) {
//直接粘贴该工具类方法到你的项目中
tmpCascadeSheet.set(
ExcelUtil.addCascadeValidationToSheet(
writeWorkbookHolder,
writeSheetHolder,
tmpCascadeSheet.get(),
(Map<String, List<String>>) model.getSource(),
tmpCascadeSheetStartCol,
model.getParentColumnIndex(),
colIndex,
model.getFirstRow(),
model.getLastRow()
)
);
} else {
//直接粘贴该工具类方法到你的项目中
tmpSheet.set(
ExcelUtil.addSelectValidationToSheet(
writeWorkbookHolder,
writeSheetHolder,
tmpSheet.get(),
(List<String>) model.getSource(),
tmpSheetStartCol,
colIndex,
model.getFirstRow(),
model.getLastRow()
)
);
}
});
}
}
5. 工具类
调用API的核心逻辑, 完全复用
- 创建普通下拉列表
- 引用一个表格区域, 区域内的值为下拉列表的值
- 创建数据有效性约束: 当用户输入值不在范围内时报错提示.
- 创建子级下拉列表
- 创建名称管理器: 通过 key 可以找到一个表格区域的引用, 引用的值可以作为下拉菜单的值
- 引用 indirect函数, 当父列选择值后, 子列动态加载名称管理器中对应key的值列表
- 创建数据有效性约束: 当用户输入值不在范围内时报错提示.
@UtilityClass
public class ExcelUtil {
private static final int limitation = 100;
public static Sheet addCascadeValidationToSheet(
WriteWorkbookHolder workbookHolder,
WriteSheetHolder sheetHolder,
Sheet tmpSheet,
Map<String, List<String>> options,
AtomicInteger startCol,
int parentCol,
int selfCol,
int startRow,
int endRow
) {
final Workbook workbook = workbookHolder.getWorkbook();
final Sheet sheet = sheetHolder.getSheet();
tmpSheet = createTmpSheet(tmpSheet, workbook, "cascade_sheet");
for (Map.Entry<String, List<String>> entry : options.entrySet()) {
String parentVal = formatNameManager(entry.getKey());
List<String> children = entry.getValue();
if (CollUtil.isEmpty(children)) {
continue;
}
int columnIndex = startCol.getAndIncrement();
createDropdownElement(tmpSheet, children, columnIndex);
if (children.size() >= limitation) {
tmpSheet = createTmpSheet(null, workbook, "cascade_sheet");
}
final String columnName = calculateColumnName(columnIndex + 1);
final String formula = createFormulaForNameManger(tmpSheet, children.size(), columnName);
createNameManager(workbook, parentVal, formula);
}
final String parentColumnName = calculateColumnName(parentCol + 1);
final String indirectFormula = createIndirectFormula(parentColumnName, startRow + 1);
createValidation(workbook, sheet, tmpSheet, indirectFormula, selfCol, startRow, endRow);
return tmpSheet;
}
private static Sheet createTmpSheet(Sheet tmpSheet, Workbook workbook, String sheetName) {
final String actualName = sheetName + workbook.getNumberOfSheets();
if (tmpSheet == null) {
tmpSheet = workbook.createSheet(actualName);
}
return tmpSheet;
}
public static Sheet addSelectValidationToSheet(
WriteWorkbookHolder workbookHolder,
WriteSheetHolder sheetHolder,
Sheet tmpSheet,
List<String> options,
AtomicInteger startCol,
int selfCol,
int startRow,
int endRow
) {
final Workbook workbook = workbookHolder.getWorkbook();
final Sheet sheet = sheetHolder.getSheet();
tmpSheet = createTmpSheet(tmpSheet, workbook, "sheet");
final int columnIndex = startCol.getAndIncrement();
String columnName = calculateColumnName(columnIndex + 1);
final String formula = createFormulaForDropdown(tmpSheet, options.size(), columnName);
createDropdownElement(tmpSheet, options, columnIndex);
createValidation(workbook, sheet, tmpSheet, formula, selfCol, startRow, endRow);
return options.size() >= limitation ? null : tmpSheet;
}
private static void createDropdownElement(Sheet tmpSheet, List<String> options, int columnIndex) {
int rowIndex = 0;
for (String val : options) {
final int rIndex = rowIndex++;
final Row row = Optional.ofNullable(tmpSheet.getRow(rIndex))
.orElseGet(() -> {
try {
return tmpSheet.createRow(rIndex);
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException(e);
}
});
final Cell cell = row.createCell(columnIndex);
cell.setCellValue(val);
}
}
private static void createValidation(Workbook workbook, Sheet sheet, Sheet tmpSheet, String formula, int selfCol, int startRow, int endRow) {
DataValidationHelper helper = sheet.getDataValidationHelper();
final DataValidationConstraint constraint = helper.createFormulaListConstraint(formula);
CellRangeAddressList addressList = new CellRangeAddressList(startRow, endRow, selfCol, selfCol);
final DataValidation validation = helper.createValidation(constraint, addressList);
validation.setErrorStyle(DataValidation.ErrorStyle.STOP);
validation.setShowErrorBox(true);
validation.setSuppressDropDownArrow(true);
validation.createErrorBox("提示", "请输入下拉选项中的内容");
sheet.addValidationData(validation);
hideSheet(workbook, tmpSheet);
}
private static String createIndirectFormula(String columnName, int startRow) {
final String format = "INDIRECT($%s%s)";
return String.format(format, columnName, startRow);
}
private static String createFormulaForNameManger(Sheet tmpSheet, int size, String columnName) {
final String format = "%s!$%s$%s:$%s$%s";
return String.format(format, tmpSheet.getSheetName(), columnName, "1", columnName, size);
}
private static String createFormulaForDropdown(Sheet tmpSheet, int size, String columnName) {
final String format = "=%s!$%s$%s:$%s$%s";
return String.format(format, tmpSheet.getSheetName(), columnName, "1", columnName, size);
}
private static void createNameManager(Workbook workbook, String nameName, String formula) {
//处理存在名称管理器复用的情况
Name name = workbook.getName(nameName);
if (name != null) {
return;
}
name = workbook.createName();
name.setNameName(nameName);
name.setRefersToFormula(formula);
}
private static void hideSheet(Workbook workbook, Sheet sheet) {
final int sheetIndex = workbook.getSheetIndex(sheet);
if (sheetIndex > -1) {
workbook.setSheetHidden(sheetIndex, true);
}
}
private static String formatNameManager(String name) {
name = name
.replaceAll(" ", "")
.replaceAll("-", "_")
.replaceAll(":", ".");
if (Character.isDigit(name.charAt(0))) {
name = "_" + name;
}
return name;
}
private static String calculateColumnName(int columnCount) {
final int minimumExponent = minimumExponent(columnCount);
final int base = 26, layers = (minimumExponent == 0 ? 1 : minimumExponent);
final List<Character> sequence = Lists.newArrayList();
int remain = columnCount;
for (int i = 0; i < layers; i++) {
int step = (int) (remain / Math.pow(base, i) % base);
step = step == 0 ? base : step;
buildColumnNameSequence(sequence, step);
remain = remain - step;
}
return sequence.stream()
.map(Object::toString)
.collect(Collectors.joining());
}
private static void buildColumnNameSequence(List<Character> sequence, int columnIndex) {
final int capitalAAsIndex = 64;
sequence.add(0, (char) (capitalAAsIndex + columnIndex));
}
private static int minimumExponent(int source) {
final int base = 26;
int exponent = 0;
while (Math.pow(base, exponent) < source) {
exponent++;
}
return exponent;
}
}
五、导出
1. EasyExcel方式
API接口
@PostMapping("/template")
public void template(HttpServletRequest request, HttpServletResponse response) {
String filename = "文件名称";
try {
String userAgent = request.getHeader("User-Agent");
if (userAgent.contains("MSIE") || userAgent.contains("Trident")) {
// 针对IE或者以IE为内核的浏览器:
filename = java.net.URLEncoder.encode(filename, "UTF-8");
} else {
// 非IE浏览器的处理:
filename = new String(filename.getBytes(StandardCharsets.UTF_8), StandardCharsets.ISO_8859_1);
}
response.setContentType("application/vnd.ms-excel");
response.setHeader("Content-disposition", String.format("attachment; filename=\"%s\"", filename + ".xlsx"));
response.setHeader("Cache-Control", "no-cache");
response.setHeader("Pragma", "no-cache");
response.setDateHeader("Expires", -1);
response.setCharacterEncoding("UTF-8");
ExcelWriter excelWriter = EasyExcel.write(response.getOutputStream()).build();
WriteSheet writeSheet = EasyExcelUtil.writeSelectedSheet(TestImportTemplateDTO.class, 0, "模版");
excelWriter.write(new ArrayList<String>(), writeSheet);
excelWriter.finish();
} catch (UnsupportedEncodingException e) {
log.error("导出Excel编码异常", e);
} catch (IOException e) {
log.error("导出Excel文件异常", e);
}
}
工具方法
public static <T> WriteSheet writeSelectedSheet(Class<T> head, Integer sheetNo, String sheetName) {
//数据预处理方法
Map<Integer, ExcelSelectedResolve> selectedMap = resolveSelectedAnnotation(head);
return EasyExcel.writerSheet(sheetNo, sheetName)
.head(head)
//注册自定义write处理器
.registerWriteHandler(new SelectedSheetWriteHandler(selectedMap))
.build();
}
2. 插件方式
通过包里已经编写的增强类来预处理下拉数据并配置自定义处理器
- 逻辑于上述无异
@ResponseExcel(
name = "excel模板",
sheets = @Sheet(sheetName = "模版", sheetNo = 0),
enhancement = DynamicSelectDataWriterEnhance.class
)
@PostMapping("/template")
public List<xxxxImportTemplateDTO> templateV2() {
return Collections.singletonList(new xxxxImportTemplateDTO());
}
3. 模版类
@ColumnWidth(50)
@Data
public class ExcelExample implements Serializable {
public static final String FIRST_LAYER_TITLE = "测试第一级标题";
@ExcelProperty({FIRST_LAYER_TITLE, "普通列"})
private String regularColumn;
@ExcelSelect(staticData = {"静态1", "静态2", "静态3"})
@ExcelProperty({FIRST_LAYER_TITLE, "静态单列下拉列表"})
private String staticSelectColumn;
@ExcelSelect(handler = DynamicSelectPrimaryHandler.class)
@ExcelProperty({FIRST_LAYER_TITLE, "级联下拉列表第一级"})
private String dynamicSelectPrimaryColumn;
@ExcelSelect(parentColumn = "级联下拉列表第一级", handler = DynamicSelectSecondaryHandler.class)
@ExcelProperty({FIRST_LAYER_TITLE, "级联下拉列表第二级"})
private String dynamicSelectSecondaryColumn;
@ExcelSelect(handler = DynamicSelectDataHandler.class)
@ExcelProperty({FIRST_LAYER_TITLE, "动态单列下拉列表"})
private String dynamicSelectColumn;
@ExcelSelect(handler = DynamicSelectPrimaryHandler.class)
@ExcelProperty({FIRST_LAYER_TITLE, "复用级联1"})
private String dynamicSelectPrimaryColumn2;
@ExcelSelect(parentColumn = "复用级联1", handler = DynamicSelectSecondaryHandler.class)
@ExcelProperty({FIRST_LAYER_TITLE, "复用级联1子集"})
private String dynamicSelectSecondaryColumn2;
private static final long serialVersionUID = -8498694378786074852L;
}
4.模版效果
图片非上述模版类效果, 但基本一样
单列默认值写死直接生成

单列动态通过处理器处理后获取
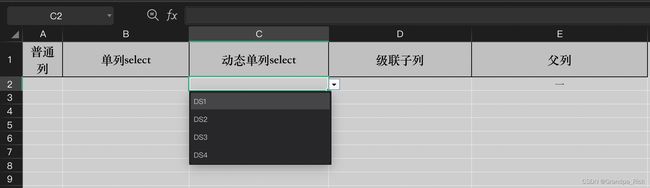
父列通过处理器获取
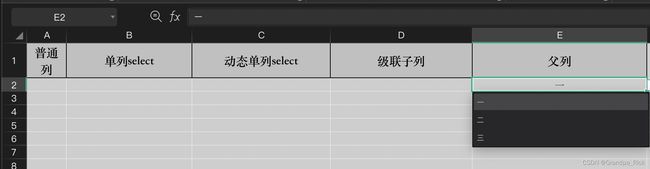
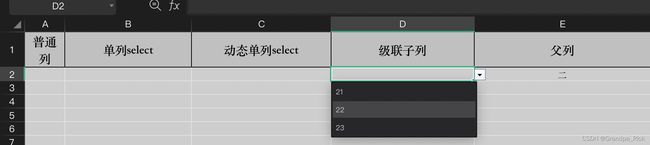
级联列根据父列选择的内容加载名称管理器中的值, 达到级联效果

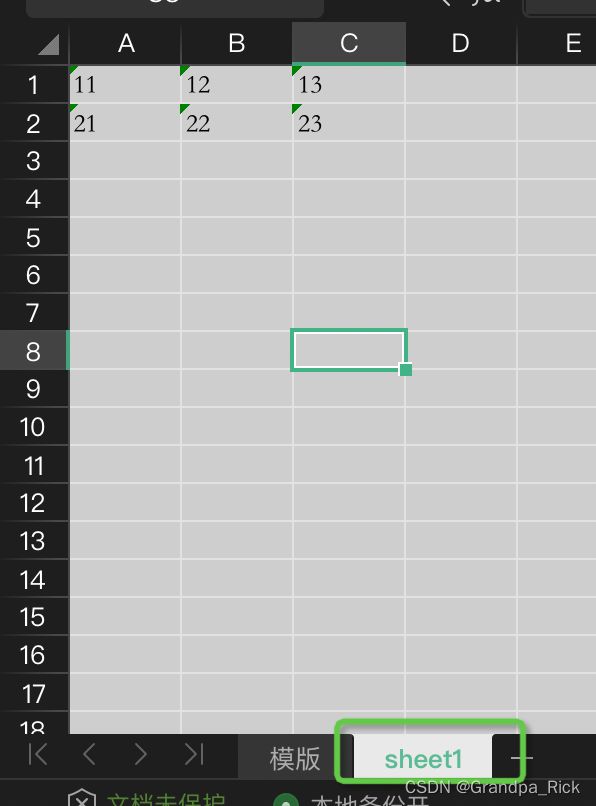
在WPS Excel的名称管理器中可见创建了两个名称,分别对应父列的值
名称管理器中创建新名称不能有特殊字符

实际就是在第二个Sheet中横向的生成数据, 这里为了展示, 没有调用隐藏sheet的方法, 如果调用了, sheet1将被隐藏
在主Sheet中创建了数据有效性验证约束, 当值不是名称管理中的对应列表下的值时, 报错
下拉列表中引用了父列的值
当输入了不在范围内的值时,报错提示
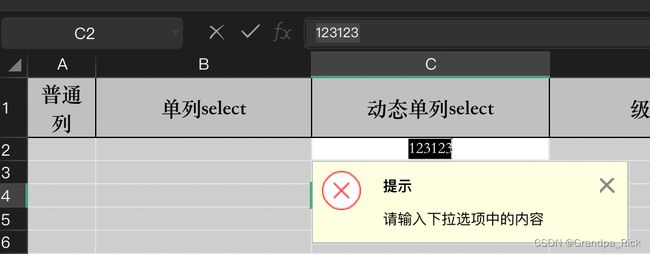
六、导入
因为我在项目中使用的涉及到存在合并行的情况, 所以这里自定义处理导入;
最终处理为Map<合并行第一行的行号, Collection<合并行>>
1. EasyExcel方式
@PostMapping("/import")
public AjaxResult import(MultipartFile file) {
Map<Integer, List<ImportDTO>> map = new HashMap<>(16);
EasyExcel.read(file.getInputStream(), ImportDTO.class, new EasyExcelUtil.ImportEventListener<>(map))
.extraRead(CellExtraTypeEnum.MERGE)
.excelType(ExcelTypeEnum.XLSX)
.headRowNumber(1)
.sheet(0)
.doRead();
xxxxService.validateImport(map);
return xxxxService.import(map);
}
2. 插件方式
@PostMapping("/import")
public AjaxResult importProjectV2(
@RequestExcel(
listener = MergeRowAnalysisEventListener.class,
enhancement = {MergeRowReaderEnhance.class}
)
Map<Integer, List<xxxImportDTO>> map
) {
xxxtService.validateImport(map);
return xxxService.import(map);
}
2.自定义导入监听器
MergeRowAnalysisEventListener 或 EasyExcelUtil.ImportEventListener 作用都一样
非必要 或者清空extra方法,在这个监听器里做校验就行了
以下代码不难看出, 其实可以在EasyExcel处理数据的时候就校验数据, 并合理使用其抛异常方法抛出异常, 但是debug之后发现处理合并行方法 extra 在最后执行, 没利用到组件的 onException 方法, 所以推迟到组件处理完数据后再统一校验
public static class ImportEventListener<T> extends AnalysisEventListener<T> {
private final Map<Integer, List<T>> map;
private Integer headRowNumber = 1;
public ImportEventListener(Map<Integer, List<T>> map) {
this.map = map;
}
// 这个是每行的数据(每一行都会执行这个)
@Override
public void invoke(T data, AnalysisContext context) {
final List<T> list = new ArrayList<>();
list.add(data);
map.put(map.keySet().size(), list);
}
//所有数据处理之后
@Override
public void doAfterAllAnalysed(AnalysisContext context) {
}
//可以考虑有一条错就抛, 还是所有数据处理完,其中有异常,全部抛
@Override
public void onException(Exception exception, AnalysisContext context) throws Exception {
throw exception;
}
// 这个是读取单元格和并时的信息
@SneakyThrows
@Override
public void extra(CellExtra extra, AnalysisContext context) {
if (headRowNumber == null) {
headRowNumber = context.readSheetHolder().getHeadRowNumber();
}
// 获取合并后的第一个索引
Integer index = extra.getFirstRowIndex() - headRowNumber;
final List<T> first = map.get(index);
// 获取合并后的最后一个索引
Integer lastRowIndex = extra.getLastRowIndex() - headRowNumber;
for (int i = index + 1; i <= lastRowIndex; i++) {
final List<T> c = map.get(i);
if (CollUtil.isNotEmpty(c)) {
first.addAll(c);
map.remove(i);
}
}
}
}
3. 校验数据
基于javax.validation, org.hibernate.validator, 点进去看看就差不多清楚了
3.1 自定义校验注解
使用到自定义校验器, 和一个获取动态数据的处理器
@Target({ElementType.METHOD, ElementType.FIELD, ElementType.ANNOTATION_TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Inherited
@Constraint(validatedBy = DynamicSelectDataValidator.class) // 校验器
public @interface DynamicSelectData {
String message() default "请填写规定范围的值";
Class<?>[] groups() default {};
Class<? extends Payload>[] payload() default {};
String parameter() default "";
Class<? extends ColumnDynamicSelectDataHandler> handler() default DefaultColumnDynamicSelectDataHandler.class;
}
3.2 自定义校验器
在校验时, 这个校验器会校验对应注解, 获取到注解的信息, 初始化动态数据处理器, 调用校验方法时查询数据并完成校验, 校验为false时, 会根据提示信息保存在ConstraintViolation对象中, 最后形成一个集合
@Slf4j
public class DynamicSelectDataValidator implements ConstraintValidator<DynamicSelectData, String> {
private String arg = null;
private ColumnDynamicSelectDataHandler handler = null;
@Override
public void initialize(DynamicSelectData data) {
this.arg = data.parameter();
final Class<? extends ColumnDynamicSelectDataHandler> sourceHandlerClass = data.handler();
this.handler = SpringUtil.getBean(sourceHandlerClass);
}
@Override
public boolean isValid(String value, ConstraintValidatorContext constraintValidatorContext) {
if (StrUtil.isEmpty(value) || Objects.isNull(handler)) {
return true;
}
try {
final List<String> constrainSource = (List<String>) handler.source().apply(arg);
return constrainSource.contains(value);
} catch (Exception e) {
return false;
}
}
}
3.3 动态获取数据处理器
只是获取合法数据集, 随便怎么写都行, 优化后这里的处理器和模版导出时的相同
3.4 校验数据方法
每一行校验一次, 每行所有列的问题返回一个map集合, 实际怎么封装校验结果可以自己修改
这里也能发现一个明显问题, 获取数据的方法每行都会被调用, 我的场景里数据量不是很大, 但是如果比较大的话, 还是需要准备一个上下文之类的存一下会一直重复的数据集, 避免每次都查询
public static <T> Optional<Map<String, Object>> validateData(T data) {
//这里的默认validator可以改成静态成员变量, 避免每次行记录都调
final Validator validator = Validation.buildDefaultValidatorFactory().getValidator();
//校验数据后的结果
Set<ConstraintViolation<T>> set = validator.validate(data, Default.class);
if (CollUtil.isEmpty(set)) {
return Optional.empty();
}
List<String> columnExceptions = new ArrayList<>();
for (ConstraintViolation<T> cv : set) {
columnExceptions.add(cv.getMessage());
}
if (CollUtil.isEmpty(columnExceptions)) {
return Optional.empty();
}
final Map<String, Object> rowExceptionMap = new HashMap<>(16);
rowExceptionMap.put("exceptions", columnExceptions);
return Optional.of(rowExceptionMap);
}
3.5 使用注解
这里只展示跟上述内容相关的注解, 其他例如NotEmpty, Digits, Email之类的注解有自己对应的校验器
如果写死的列表用正则就行了, 动态的数据配置处理器查询
@Data
public class TestImportDTO{
@ExcelProperty(value = "普通列")
private String common;
@Pattern(regexp = "^(A|B|C|D)$", message = "校验信息")
@ExcelSelect(staticData = "[\"A\", \"B\", \"C\", \"D\", \"E\"]")
@ExcelProperty(value = "单列select")
private String singleSelect;
@DynamicSelectData(message = "动态单列select请填写给定的选项", handler = {DynamicDataConstrainSourceHandler.class}, parameter = "自定义参简单参数")
@ExcelSelect(handler = ExcelTestSourceHandler.class)
@ExcelProperty(value = "动态单列select")
private String dynamicSingleSelect;
//parent字段定义父列名称
@DynamicSelectData(message = "级联子列请填写给定的选项", handler = {ChildConstrainSourceHandler.class})
@ExcelSelect(parentColumn = "父列", handler = ExcelChildSourceHandler.class)
@ExcelProperty(value = "级联子列")
private String child;
@DynamicSelectData(message = "父列请填写给定的选项", handler = {ChildConstrainSourceHandler.class})
@ExcelSelect(handler = ExcelParentSourceHandler.class)
@ExcelProperty(value = "父列")
private String parent;
}
3.6 校验结果
{
"msg": "导入数据异常",
"code": 500,
"data": [
{
"row": "第1条记录异常",
"exceptions": [
"xxx不能为空"
]
},
{
"row": "第1条记录的第2条子记录记录异常",
"exceptions": [
"子记录xxx请填写纯数字(整数位不超过10位,小数位不超过两位)"
]
},
{
"row": "第2条记录异常",
"exceptions": [
"xxx不能为空"
]
},
{
"row": "第3条记录异常",
"exceptions": [
"xxxx请填写纯数字(整数位不超过10位,小数位不超过两位)"
]
},
{
"row": "第3条记录的第3条子记录异常",
"exceptions": [
"子记录xxx请填写纯数字(整数位不超过10位,小数位不超过两位)"
]
}
]
}
七、迭代
- 2023-08-10: 计算下拉列表的列名称逻辑上无数量限制, 实际如WPS中, 一个Sheet最多可使用16384列生成下拉
- 2023-05-30: 精简博客内容, 只保留最主要的介绍信息
- 2023-05-16: note:
- 同好 niceGoingGn 提到的下拉数据提示文件损坏的问题, 可能是由于poi的API在实现用一个数组作为dropdown数据时, 底层是拼字符串的方式, 该方式在Excel有字符数量限制. 所以会导致异常, 之前也是我的场景局限性太强, 目前已经调整为所有的dropdown都通过引用的方式加载, 1000+ elements都没问题.
- 同好 小宇哥JJ 提到的对存在一个多级表头时处理注解的优化(能拉, 但只能拉一点点), 以及级联复用时, 名称管理器重复创建会报错的情况, 目前已经调整. 复用时不再出现异常, 同时对多个级联存在时优化了生成sheet的逻辑.
- optimizations: 纵向生成数据, 支持676+26列带下拉, 优化存在多级表头的问题, 优化生成的隐藏sheet数量. 同时需要注意的是, 在创建垂直生成的dropdown的elements时, 如创建了A999元素后, 根据逻辑循环到B0之前, poi很可能选择写到磁盘(懒得深究了), 内存就没有这个第0行Row对象了, 人以为这个row0应该存在, 并且要参与下一列的数据创建, 但是判断的时候就是null了, 此时如果调用创建row的api就报这row已经存在的异常. 所以这里的取舍目前是超过100个元素后, 下一列就在新的sheet上创建, 避免这个问题.
- 历史省略
结束
本文主要是介绍如何导出带下拉菜单和级联菜单的数据表, 利用自定义校验完成与此模版的整合校验, 保证数据完整性, 主要是理解整个的逻辑和概念, 通过AOP的增强, 最主要的是为了向配置的方式靠近, 减少编码的过程, 仓库仅供参考, 互相学习…peace out