Protobuf 原理大揭秘
一、定义
Google推出的一种 结构化数据 的数据存储格式(类似于 XML、Json )。
多个版本的源码地址
https://github.com/protocolbuffers/protobuf/
1、为什么选择它
优点:
- 效率高:Protobuf 以二进制格式存储数据,比如 XML 和 JSON 等文本格式更紧凑,也更快。序列化和反序列化的速度也很快。
- 跨语言支持:Protobuf 支持多种编程语言,包括 C++、Java、Python、Objective、C、Ruby、Go、PHP、Dart、JavaScript(版本3.26)。
- 清晰的结构定义:使用 Protobuf,可以清晰地定义数据的结构,这有助于维护和理解。
- 向后兼容性:你可以添加或者删除字段,而不会破坏老的应用程序。这对于长期的项目来说是非常有价值的。
缺点:
- 不直观:由于 Protobuf 是二进制格式,人不能直接阅读和修改它。这对于调试和测试来说可能会有些困难。
- 缺乏一些数据类型:例如没有内建的日期、时间类型,对于这些类型的数据,需要手动转换成可以支持的类型,如 string 或 int。
- 需要额外的编译步骤:你需要先定义数据结构,然后使用 Protobuf 的编译器将其编译成目标语言的代码,这是一个额外的步骤,可能会影响开发流程。
2、语法
Protobuf协议文件名后缀名为.proto。一个简单的Protobuf协议如下:
1 syntax="proto3";
2
3 package protobuf.addressbook;
4
5 enum PhoneType
6 {
7 MOBILE = 0;
8 HOME = 1;
9 WORK = 2;
10 }
11
12 message Person
13 {
14 optional string name = 1;
15 optional uint32 age = 2;
16 optional string email = 3;
17
18 message PhoneNumber
19 {
20 optional string number = 1;
21 optional PhoneType type = 2;
22 }
23
24 repeated PhoneNumber phone = 4;
25
26 }
27
28
29 message AddressBook
30 {
31 repeated Person person = 1;
32 }必须指明版本:syntax = "proto3";
proto3比proto2的变化:
1、proto3比proto2支持跟多语言,语言增加 Go、Ruby、JavaNano 支持。
2、字段规则移除了"required",并把optional改名为了singlar,但是optional还可以用。
3、移除了 default 选项,在 proto2 中,可以使用 default 选项为某一字段指定默认值。在 proto3 中,字段的默认值只能根据字段类型由系统决定。也就是说,默认值全部是约定好的,而不再提供指定默认值的语法。
【在字段被设置为默认值的时候,该字段不会被序列化。这样可以节省空间,提高效率。但这样就无法区分某字段是根本没赋值,还是赋值了默认值。这在 proto3 中问题不大,但在 proto2 中会有问题。】
4、proto3默认采用 packed 编码,在 proto2 中,需要明确使用 [packed=true] 来为字段指定比较紧凑的 packed 编码方式。
5、枚举类型的第一个字段必须为 0。
6、移除了对分组的支持。
7、移除了对扩展的支持,新增了 Any 类型。proto3 中新增的 Any 类型有点像 C/C++ 中的 void* 。
8、增加了 JSON 映射特性。
1)、标识符:
syntax:标识使用的protobuf是哪个版本。上面表示使用的是3.x版本。
package:标识生成目标文件的包名。在C++中表示的是命名空间。上面。表示生成的类和函数在protobuf命名空间的addressbook命令空间下。
enum:表示一个枚举类型。会在目标.h文件中自动生成一个枚举类型。
message:标识一条消息。会在目标文件中自动生成一个类。
2)、字段:
字段格式:role type name = tag [default value]
a、role有三种取值:
required:该字段必须给值,不能为空。否则message被认为是未初始化的。如果试图建立一个未初始化的message将会抛出RuntimeException异常,解析未初始化的message会抛出IOException异常。(proto3已经移除)
optional:表示该字段是可选值,可以为空。如果不设置,会设置一个默认值。也可以自定义默认值。如果没有自定义默认值,会是用系统默认值。
repeated:表示该字段可以重复,可等同于动态数组。
注意:required字段是永久性的,如果之后不使用该字段,或者该字段标识改为optional或repeated,那么使用就接口读取新协议时,如果发现没有该字段,会认为该消息不完整,会拒收或者丢弃该消息。
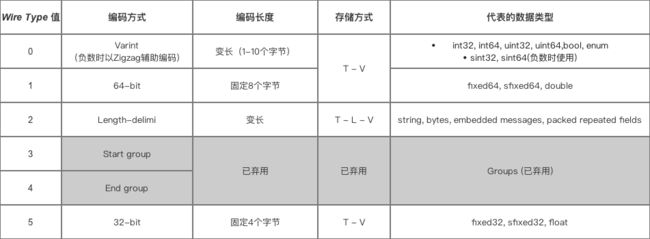
b、type的种类(下图中的 代表的数据类型 栏)
二、原理解析
1、数据存储方式
T - L - V,即Tag - Length - Value 【标识 - 长度 - 字段值】。
其中Length是可选的。示意图:
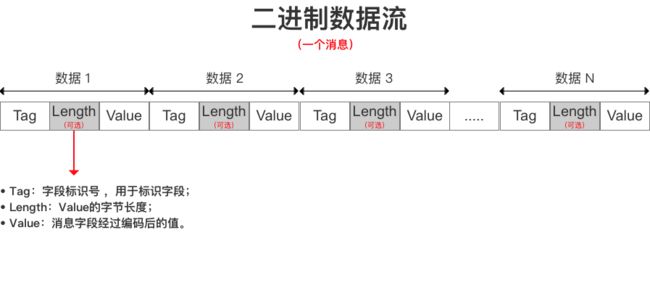
可以看出:T - L - V 存储方式不需要分隔符,数据就很紧凑,存储空间利用非常高,而且这里面还有很多优化方式,使得数据被压缩到足够小。
2、T - L - V的具体表示
1)、Tag的具体表示
Tag = 字段序号[field_number] + 字段数据类型[wire_type] 。使用Varint编码(这个下面会讲到),占用1~5个字节的长度。
字段数据类型现在只有0~5(6种类型)其中3、4是废弃的,所以它可以用3个bit位表示,其他bit表示字段序号,这里举两个例子简单说明一下(简单交代一下每个字节的第一个bit是标记位,表示是否结束,0表示结束【这其实就是Varint的性质】)。
例一 :Tag = 【00110010】 第一个字节的第一个bit=0表示后面没有Tag的数据,OK,我们来处理这个数据。首先去掉标记位得到新的数据【0110010】。最后3个bit = 010 = 2,表示字段数据类型为2(6种类型中的一种);剩下的4个bit = 0110 = 6,表示字段序号是6。
例二:Tag = 【10000010 00000001】 第一个字节的第一个bit=1表示后面还有Tag的数据,第二个字节的第一个bit=0表示结束,OK,我们来处理这个数据。首先将两个字节颠倒位置(Protobuf是小端编码),得到新的数据【00000001 10000010】,然后将标记位去掉又得到一个新的数据 【 0000001 0000010】。最后3个bit = 010 = 2,表示字段数据类型为2(6种类型中的一种);剩下的11个bit = 00000010000 = 16,表示字段序号是16。
2)、Length的具体表示
使用Varint编码(这个下面会讲到),占用1~5个字节的长度。数值表示后面数据(Value)的长度,现在只有字段数据类型 = 2 时需要Length字段。
3)、Value的具体表示
表示具体的数据,采用小端编码。String类型采用UTF-8编码。
3、编码方式
1)、Varint编码方式
a、简介
一种变长的编码方式,优点是对于小的数值可以用很少的字节表示,从而进行数据压缩。
存储方式是 T - V。
b、原理
Varint编码的每个字节的最高位都有特殊含义:
如果是1,表示后续的字节也是该数值的一部分;如果是0,表示这是最后一个字节。
因此:小于128的数值可以用1个字节就表示了。上面在解释Tag的具体表示时已经举例过两个字节的计算方式,在这里再举一个3字节的例子加强一下认识。
例子:【10101100 10000011 00000001】 (注意这里假定这个数据不是 sint32 / sint64 类型 ,后面讲到Zigzag编码方式时会说明)。
可以看出第一个字节的最高位=1,说明后面的字节也是该数值的一部分,看第二个字节的最高位也是=1,同理,我们又看第三个字节的最高位=0,说明这是最后一个字节。OK,我们确定了数值的数据是3个字节表示的,现在开始计算。首先颠倒着3个字节(Protobuf是小端编码 后面遇到不会再做强调),得到新的数据【00000001 10000011 10101100】,然后将标记位去掉又得到一个新的数据【0000001 0000011 0101100】,计算得出数值为16812 。
讲到这里就要说一下Varint编码方式的不足了,在计算机里,负数的最高位是1(符号位),所以在用Varint编码时会被当成很大的整数,这就不利于数据的压缩了。解决方案是Protobuf定义了sint32 / sint64 的类型表示负数,通过先采用Zigzag编码(将有符号数 转换成 无符号数),再采用Varint编码,从而减少编码后的字节数。
2)、Zigzag编码方式
a、简介
Zigzag编码是弥补Varint在对负数编码时的不足,从而更好的帮助Protobuf进行数据的压缩。
b、原理
代码分析:
public int int_to_zigzag(int n)
// 传入的参数n = 传入字段值的二进制表示(此处以负数为例)
// 负数的二进制 = 符号位为1,剩余的位数为 该数绝对值的原码按位取反;然后整个二进制数+1
{
return (n <<1) ^ (n >>31);
// 对于sint 32 数据类型,使用Zigzag编码过程如下:
// 1. 将二进制表示数 左移1位(左移 = 整个二进制左移,低位补0)
// 2. 将二进制表示数 右移31位
// 对于右移:
// 首位是1的二进制(有符号数),是算数右移,即右移后左边补1
// 首位是0的二进制(无符号数),是逻辑左移,即右移后左边补0
// 3. 将上述二者进行异或
// 对于sint 64 数据类型 则为: return (n << 1> ^ (n >> 63) ;
}
// 附:将Zigzag值解码为整型值
public int zigzag_to_int(int n)
{
return(n >>> 1) ^ -(n & 1);
// 右移时,需要用不带符号的移动,否则如果第一位数据位是1的话,就会补1
}
举例:将 -2 进行Zigzag编码:
-2 在计算机中是以补码的形式存在的(补码忘记的请百度了解),即1111 1110,这里为了方便只写8个bit位。开始计算:先整体左移1位,右边补0得到 1111 1100,然后整体右移31位,右边补1得到1111 1111,最后将两个数进行按位异或得到 0000 0011,即通过Zigzag编码后,-2 变成了 3 。
所以,如果提前预知字段值可能取负数的时候,记得采用 sint32 / sint64 的数据类型。
3)、定长编码方式
对于字段数据类型 = 1和5的编码方式较简单:编码后的数据具备固定大小,需要记住的是【Protobuf是小端编码】,处理数据时记得颠倒字节数据就可以了。
4、Wire Type字段数据类型的编码&数据存储方式
1)、Wire Type = 0 的编码&数据存储方式
编码方式是Varint,数据存储方式是T - V。
如果数据类型是 sint32 / sint64 ,编码方式是先Zigzag编码,再用Varint编码。
2)、Wire Type = 1 & 5 的编码&数据存储方式
编码方式是32-bit & 64-bit,数据存储方式是T - V。
需要注意的是它们都是高位在后低位在前(小端编码)。
3)、Wire Type = 2 的编码&数据存储方式
编码方式是Length-delimi,数据存储方式是T - L - V。
针对 wire_type=2 的编码,下面主要分析三种数据类型:string、messages(嵌套消息类型)、通过packed修饰的repeat字段(即packed repeated fields)。
a、string类型
编码方式:字段值采用 UTF-8 编码。
例子:
message Test2
{
required string str = 2;
}
// 将str设置为:testing
Test2.setStr(“testing”)
// 经过protobuf编码序列化后的数据以二进制的方式输出
// 输出为:18, 7, 116, 101, 115, 116, 105, 110, 103
Tag = 18 = 0001 0010 =》 field_number = 2 wire_type = 2
Length = 7 = 0000 0111 =》数据长度为7(这里只取了一个字节是因为该字节的最高位为0,不明白请看前面写的Varint编码方式)
Value = 116,101,115,116,105,110,103 ( 写二进制太长了,这里直接写的十进制 )
即内容为 "testing"。
b、嵌套消息类型(message)
编码方式:字段值根据字段的数据类型采用不同编码方式。
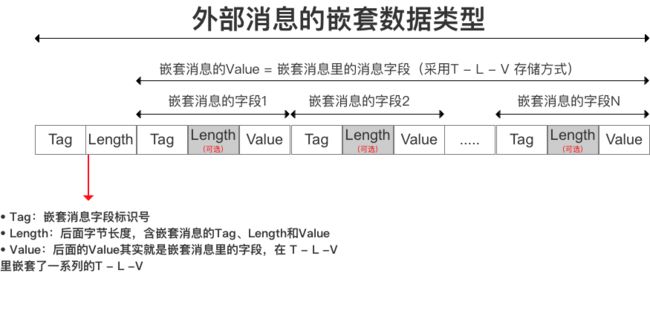
例子:
message Test2
{
required string str = 1;
required int32 id1 = 2;
}
message Test3 {
required Test2 c = 1;
}
// 将Test2中的字段str设置为:testing
// 将Test2中的字段id1设置为:296
// 编码后的字节为:10 ,12 ,18,7,116, 101, 115, 116, 105, 110, 103,16,-88,2
编码&存储方式如下:
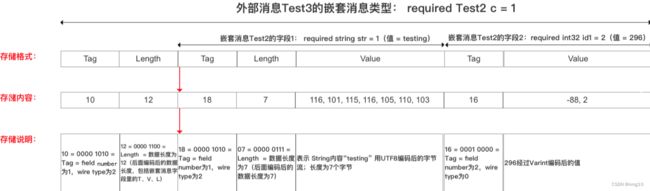
c、通过packed修饰的 repeat 字段
不带repeat的数据:T - V - T - V - T - V ...
repeat=true的数据:T - V - V - V ...
很容易发现后者去掉了相同的Tag,优化了存储,所以proto3已经默认采用。
Protocol Buffer的packed修饰只用于repeated字段 或 基本类型的repeated字段- 用在其他字段,编译
.proto文件时会报错
三、完整的Protobuf举例 (加深理解)

这个例子有一个特点,就是AllDataType这一结构体中包含了Protobuf所支持的全部数据类型。下一步,使用protoc编译该proto文件,并在程序中声明一个AllDataType类型的数据,将其序列化,并打印出来。下面的代码是以golang为例:
package main
import (
"fmt"
"/example"
"github.com/golang/protobuf/proto"
)
func main() {
test := example.AllDataType{
Fint32: 257,
Fint64: -2,
Fuint32: 1,
Fuint64: 1025,
Fsint32: 0,
Fsint64: -2,
Ffixed32: 17,
Ffixed64: 2049,
Fdouble: -0.1,
Ffloat: 0.6,
Fbool: true,
Fenum: example.DayOfWeek_SUNDAY,
Fmessage: &example.Child{Fsint64: 3},
Fmap: map[uint32]float64{3: -0.1, 0: 2.12},
Frepeatbool: []bool{true, false, true},
Fstring: "Hello World",
Fbytes: []byte{129, 0, 19, 56},
Fsfixed32: 12345,
Fsfixed64: 54321,
}
data, _ := proto.Marshal(&test) // protobuf将结构体序列化为二进制串
fmt.Println(data) // 打印AllDataType类型的数据序列化后的二进制串
} 最后一行打印的结果为:

接下来就是最关键的一幅图,我们逐个字节地来分析一下上面的打印结果中,每个字节所代表的含义(可查看大图):

图中橙色部分(如第1行第1列,第1行第4列)用于表示字段 field_number(简写为fn)以及wire_type(简写为wt)。其中field_number是.proto文件中标注的该字段数字代号,而wire_type表示本字段的数据类型属于哪种归类。
四、特别注意&使用建议
1、特别注意
1)、若 required字段没有被设置字段值,那么在IsInitialized()进行初始化检查会报错并提示失败。
所以
required字段必须要被设置字段值。
2)、序列化顺序 是根据 Tag标识号 从小到大 进行编码。
和
.proto文件内 字段定义的数据无关。
3)、T - V的数据存储方式保证了Protobuf的版本兼容:高<->低 或 低<->高都可以适配。
若新版本 增加了
required字段, 旧版本 在数据解码时会认为IsInitialized()失败,所以慎用required字段。
2、使用建议
1)、多用 optional或 repeated修饰符。
因为若
optional或repeated字段没有被设置字段值,那么该字段在序列化时的数据中是完全不存在的,即不需要进行编码,相应的字段在解码时才会被设置为默认值。
2)、字段标识号(field_number)尽量只使用 1-15,且不要跳动使用。
因为
Tag里的field_number是需要占字节空间的。如果field_number>=16时,field_number的编码就会占用2个字节,那么Tag在编码时也就会占用更多的字节;如果将字段标识号定义为连续递增的数值,将获得更好的编码和解码性能。可以把f
ield_number小于16的值
3)、若需要使用的字段值出现负数,请使用 sint32 / sint64,不要使用int32 / int64
因为采用
sint32 / sint64数据类型表示负数时,会先采用Zigzag编码再采用Varint编码,从而更加有效压缩数据。
4)、对于repeated字段,尽量增加packed=true修饰
因为加了
packed=true修饰repeated字段采用连续数据存储方式,即T - L - V - V -V方式。