【深度神经网络原理结合代码剖析】网络训练
关于网络训练代码的剖析还是用一个简单的网络,做图像分类任务来举例。
在以下代码中,我们定义了一个ModelNet网络,包含了卷积池化和全连接层。
接下来我们从路径path中读取了需要的训练数据。数据来源是Imagenet的数据集,从数据集中挑选了2个类别,船桨和蛇,分别放在文件夹‘/1’和文件夹‘/2’下面,1和2也分别作为他们的类别编号。由于Imagenet数据集中的数据大小不同,所以在使用之前需要对数据进行预处理(tran),之后就是读取数据到字典data_dict中。我定义的data_dict结构是这样的:
key:字符串类型图片名(例如:n03874293_775.JPEG)
value:字典类型数据(key:类别编号(例如:1);value:Tensor类型图片数据)
训练的过程大致描述为:数据输入后根据网络的权重进行运算计算出一个结果,计算结果和预期设想的结果之间的差距,根据差距再优化网络里的权重,再进行运算....
在这个过程中,网络已经定义好了,网络里的权重初值没有特别声明就是默认全为0;计算结果和预期设想的结果之间的差距就是损失(loss),损失如何计算,是需要有一个损失函数,代码中我们使用的损失函数为交叉熵函数(CrossEntropyLoss),pytorch也提供了其他损失函数,可以参照用户文档;计算出损失后如何优化网络权重,是需要有一个优化方法,代码中我们使用的优化方法是随机梯度下降法(Stochastic Gradient Descent,SGD),pytorch也提供了其他优化方法,可以参照用户文档。
训练过程:
1.权重梯度清零optimizer.zero_grad() 。通常是因为我们将数据分组(batch)训练,为了不让一个组的数据训练影响下一组的数据训练,所以在本组数据训练开始前将权重梯度清零。代码里没有分组,所以这里可以认为一个数据就是一组。这行代码可以试试隐藏或者训练的时候一个循环用一次,会测试出它对于收敛速度的影响。但其实不是收敛更快就效果会更好,很有可能造成过拟合。因此权重梯度清零,可以让数据间相互影响的关联性降低,是有必要的。
2.通过网络计算出输出数据output。计算出的结果是一个1*2的Tensor,值为[a,b]。
3.明确预期结果target。在这里target对于1类型的图片是[1,0],对于2类型的图片是[0,1]。这是我们在图像分类中常规的定义,建立一个1*类别数class_num的Tensor,对某个类别的分类目标就是将Tensor中自己类别号占位的数字赋1,其他赋0。
4.用损失函数计算损失loss,反向传播计算得到每个权重的梯度值loss.backward()。反向传播计算得到的梯度值结果会保存在网络中每个权重的属性中。
5.用优化方法法更新权重的值optimizer.step()。
6.计算下一组数据(这里就是下一个数据)的时候,会用新的权重。
7.循环epoch_num次,有效的训练会使权重有效的更新,使得损失不断收敛。
代码训练了100次,输出的损失收敛状态如下:
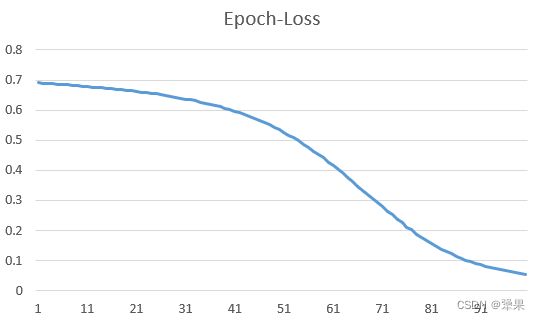
通过重复的程序运行,可以发现训练的结果是不稳定的,有的时候可以收敛的很好,有的时候结果就不是很好。因此如何让网络建立的更好,权重初始化更好,参数设置更好,使得训练程序运行的更稳定和更高效,就是后面网络和优化的部分了~
本章需要的数据会传在CSDN里,可以去我的资源里找哈~
import torch
import torch.nn as nn
import torch.optim as optim
from PIL import Image
from torchvision import transforms as Tran
import torch.nn.functional as Func
import os
#定义网络
class ModelNet(nn.Module):
def __init__(self):
nn.Module.__init__(self)
self.conv1 = nn.Conv2d(in_channels=3, out_channels=3, kernel_size=6, stride=6, padding=0)
self.pool = nn.MaxPool2d(kernel_size=6, stride=2)
self.conv2 = nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=3, padding=0)
self.fc1 = nn.Linear(in_features=150, out_features=60)
self.fc2 = nn.Linear(in_features=60, out_features=20)
self.fc3 = nn.Linear(in_features=20, out_features=2)
def forward(self, x):
x = self.conv1(x)
x = self.pool(x)
x = self.conv2(x)
x = torch.flatten(x)
x = Func.relu(self.fc1(x))
x = Func.relu(self.fc2(x))
x = self.fc3(x)
return x
#读取数据
path = "./data/example/"
data_dict = {}
class_num = 2
tran = Tran.Compose([
Tran.Resize((224, 224)),
Tran.ToTensor(),
Tran.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
for i in range(1, class_num+1):
filepath = path + str(i) + '/'
pathDir = os.listdir(filepath)
for fileDir in pathDir:
file_dict = {}
file_dict[i] = tran(Image.open(filepath + fileDir).convert("RGB"))
data_dict[fileDir] = file_dict
#定义模型、损失和优化器
SGD_lr = 0.001
SGD_m = 0.5
SGD_wd = 1e-4
epoch_num = 100
modelnet = ModelNet()
#https://pytorch-cn.readthedocs.io/zh/latest/package_references/torch-nn/#class-torchnnnlllossweightnone-size_averagetruesource
criterion = nn.CrossEntropyLoss()
#https://pytorch-cn.readthedocs.io/zh/latest/package_references/torch-optim/#optimizer
optimizer = optim.SGD(modelnet.parameters(), lr=SGD_lr, momentum=SGD_m, weight_decay=SGD_wd)
#训练模型
for epoch in range(epoch_num):
running_loss = 0.0
for i, file_name in enumerate(data_dict):
data = data_dict[file_name]
for j, label in enumerate(data):
optimizer.zero_grad()
input = data[label]
output = modelnet(input).resize(1,class_num)
target = torch.FloatTensor(1,class_num).fill_(0)
target[0,label-1] = 1
loss = criterion(output, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
print('loss: %.3f' % (running_loss / (i+1)))
print('Finished Training')