520页(17万字)集团大数据平台整体解决方案word
本资料来源公开网络,仅供个人学习,请勿商用,如有侵权请联系删除,更多浏览公众号:智慧方案文库
1.1.1 系统总体逻辑结构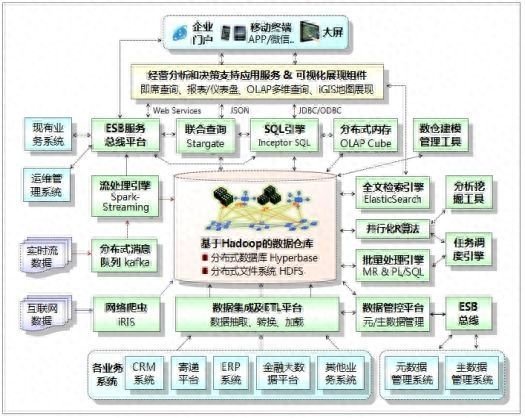
4-14系统总体逻辑结构图
参见上图,基于Hadoop构建的企业级数据仓库,包含:分布式列式存储数据库Hyperbase和分布式文件系统HDFS。通过数据集成及ETL平台,采集集团现有业务系统(CRM、ERP、寄递平台、金融大数据平台等)数据,经清洗、转换、加工后将数据批量加载到数据仓库。通过分布式消息队列(Kafka)和流处理引擎(Spark Streaming),可实时采集处理流数据(如:网站点击流数据、实时事件流数据等);流处理引擎可通过SQL接口将流数据实时加载至分布式内存或分布式数据库中。通过互联网数据采集软件(iRIS)可采集互联网数据(网站、SNS等),并经加工处理后导入数据仓库。本系统还支持在线填报、报表文件上传等数据采集方式。
结构化数据导入数据仓库后,可通过PL/SQL脚本和Hadoop/Spark批处理引擎进行数据关联操作和汇总加工处理;半/非结构化数据导入数据仓库后,可通过全文检索引擎Elastic Search快速创建全文索引。
大数据平台为数据分析挖掘应用开发,提供可视化的数据建模工具、数据分析挖掘工具(RStudio)、并行化R算法模型库及分布式计算引擎。平台还提供分析报表和仪表盘、OLAP多维查询、iGIS地图等可视化数据展现组件。
大数据平台为上层的各类应用提供数据访问接口服务,包括:SQL引擎(Inceptor SQL)、联合查询引擎(Inceptor StarGate,支持结构化数据和非结构数据联合查询)、全文检索引擎(Elastic Search)。本平台还支持分布式内存OLAP Cube功能,多维分析应用可通过SQL引擎快速访问OLAP Cube数据集。
基于支撑平台开发的应用系统采用面向服务架构(SOA)设计。采用J2EE/Spring、Apache CXF框架,实现内置的服务注册功能,能够将已有的外部Web Service进行注册、调用,同时能够将定义的服务以方式对外暴露,供其它应用调用。集团已有的ESB服务总线平台,可通过JDBC/ODBC接口与SQL引擎对接,将分布式数据库查询访问封装为Web Services,供相关应用系统调用;ESB平台可通过HTTP/JSON接口与联合查询引擎对接,将非结构化数据和结构化数据联合查询访问封装为Web Services,供相关应用系统调用;基于ESB平台可将报表/分析平台生成的分析挖掘结果封装为RESTful服务,供相关应用系统调用。本项目中,可应用ESB总线平台实现与集团主数据管理系统、元数据管理系统、统一运维管理平台之间的实时数据交换。
1.1.2 平台组件关系

图4-15整体架构及平台组件关系图
大数据平台系统主要是由大数据分布式计算和存储服务、分布式容器集群管理、数据采集交换、数据管控、应用支撑平台及定制开发的应用服务等组件组成。
参见上图,以下描述了主要的平台组件功能及组件关系:
1、分布式数据存储
² 分布式文件系统(HDFS)
存储半/非结构数据,包括Office文件、XML数据、Email数据、凭证单据扫描件、视频图像、Web网页等数据。有关文件属性数据主要是存于分布式数据库Hyperbase
中;对文本数据生成的索引数据主要是存于全文索引库(Elastic Search)中。
应用系统可通过JAVA API访问HDFS,也可通过FUSE挂载HDFS,将HDFS映射为远程盘访问使用。
² 分布式列式存储数据库(Hyperbase):
存储结构化数据,包括从现有业务系统数据库采集的数据、整合加工后的多主题关联的数据集及面向应用的数据集市等。
应用系统可通过SQL引擎(InceptorSQL)、基于JDBC/ODBC标准接口访问Hyperbase。
² 分布式内存/OLAP Cube
Hyperbase可将数据集市及OLAP Cube数据加载到分布式内存节点,为即时查询、多维统计分析等应用提供快速访问服务。
应用系统可通过SQL引擎(Inceptor SQL)、基于JDBC/ODBC标准接口访问分布式内存/OLAP Cube。
² 分布式全文检索库(Elastic Search)
存储ES索引引擎生成的全文索引数据,并为全文检索查询应用提供HTTP/JSON、JAVA API访问接口。
2、分布式计算处理引擎
² Hadoop MapReduce框架和Spark内存计算引擎
Hadoop MR为分布式批处理计算提供了JAVA API框架;Spark引擎充分利用内存计算技术实现快速分布式处理,支持Java、Scala、Python等语言。
² SQL引擎(Inceptor SQL)
基于Spark实现的高性能、高兼容性(SQL99、SQL2003标准)的SQL
引擎,为应用系统提供JDBC/ODBC标准接口访问Hyperbase数据库。SQL引擎支持PL/SQL,方便开发人员实现多表关联、汇总处理等应用
² 流处理引擎(Spark Streaming)
基于Spark Streaming实现的流处理引擎,可与分布式消息系统Kafka对接,实时接收处理流数据;可通过JMS API接口与集团ESB平台(Tibco EMS消息中间件)对接,实时接收处理业务数据流;可将实时检测出异常事件信息向ESB平台发送。
流处理引擎可通过SQL引擎将流数据实时导入Hyperbase、分布式内存/Cube中。流处理引擎运行中所用到的业务参考数据、规则数据等可放在分布式内存/Cube中,从而大大减少了访问数据库的时间消耗。
² 联合查询引擎(Inceptor Stargate)
联合查询引擎为应用系统提供非结构化数据和结构化数据联合查询服务。应用系统与联合查询引擎之间通过HTTP/JSON接口交互查询请求和响应信息。联合查询引擎支持通过JDBC/ODBC接口访问数据库(Oracle、Teradata、MySQL等);支持通过Inceptor SQL引擎访问分布式数据库Hyperbase、分布式内存/OLAP Cube;支持通过Java API接口访问分布式文件系统HDFS;支持通过HTTP接口访问JSON、XML数据。
² 并行化R算法引擎
基于SparkR实现的并行化R算法引擎,目前已支持近60种并行化R算法。开发人员可通过可视化编程环境RStudio将应用包加载到算法引擎执行。并行化R算法引擎,可通过JDBC接口及SQL引擎向Hyperbase提取所需数据,并将分析结果存入Hyperbase。并行化R算法引擎也可直接读取HDFS上的文件数据。
² 分布式检索引擎(Elastic Search)
可从Hyperbase、HDFS提取文本数据并创建全文索引库。全文索引库数据可存于分布式文件系统HDFS。Elastic Search为全文检索查询应用提供HTTP/JSON访问接口。
3、数据集成和管控平台
² 数据ETL平台
提供数据抽取、转换和加载功能。平台可通过SQL/JDBC/ODBC接口、批量导出脚本、Sqoop并行化抽取等方式,从现有业务系统数据库(Oracle)、Teradata数仓中批量导出数据并经转换处理后,加载到Hyperbase或HDFS中。网络爬虫(iRIS)所抓取的网页数据也可通过ETL平台加载到HDFS或Hyperbase中。
² 数据管控平台
提供元数据管理、主数据管理、数据质量管理、数据标准管理、数据安全管理等功能。可通过ETL平台的元数据采集引擎,统一采集处理分布式文件系统HDFS、分布式数据库Hyperbase、ETL处理流程及规则、现有业务系统数据库以及Teradata、Oracle数据库的元数据,并统一存于数据管控平台的数据库中,建立源库表-->接口表-->ETL处理过程-->目标库表的元数据关联关系,从而为后续的数据标准管理、主数据管理、数据质量管理、数据安全管理奠坚基础。本项目涉及与集团现有的元数据管理、主数据管理系统对接交换数据,可采用ESB平台及消息传输中间件,基于JMS接口与现有系统实时交换元数据、主数据变更记录。
² ESB服务总线平台
集团现有的ESB平台提供消息队列(消息存储转发、消息路由)、消息订阅和发布、Web Service服务编排及组合调用、服务监控等功能。
基于ESB平台及JMS
消息接口,可实现大数据平台系统与集团现有业务系统之间的实时数据交换(包括:运维管理数据、元数据/主数据等),并可将大数据平台分析挖掘的结果数据集实时推送到CRM、ERP、企业门户及APP等应用服务系统。
ESB平台支持JDBC/ODBC、HTTP/JSON接口,可与大数据平台的SQL引擎、联合查询引擎对接,从而可将Hyperbase数据库查询、非结构化和结构化数据的联合查询功能封装为Web Service服务,供相关应用系统调用。
基于应用支撑平台开发的图表展现、多维分析等应用,可封装为轻量级的RESTful/HTTP服务,并注册于ESB平台上,可供相关应用系统调用。
4、经营分析等应用及可视化展现组件
基于J2EE平台和可视化展现组件(即时查询、报表和仪表盘、OLAP多维分析、地图展现等组件)定制开发的经营分析和决策支持应用服务系统,可通过SQL引擎及JDBC/ODBC接口访问分布式数据库Hyperbase、分布式内存/OLAP Cube。应用系统可通过联合查询引擎及HTTP/JSON接口实现非结构化数据(如存于HDFS中的文本数据、XML数据)和结构化数据(包括:Oracle、MySQL、Teradata、Hyperbase等数据库数据)的联合查询。应用系统还可通过HTTP/JSON接口对接全文检索引擎,实现全文检索查询。
基于面向服务架构(SOA)设计思想,将定制开发的经营分析和决策支持应用及分析挖掘结果数据集查询功能封装为轻量级的Web Service服务,注册发布于ESB平台,可供相关应用系统调用。
5、身份认证和访问控制组件(IM/AM)
IM/AM组件是为访问企业门户、经营分析等应用的用户统一提供身份认证和鉴权访问控制服务。用户证书、授权信息可存于关系数据库(Oracle或MySQL)或轻量级的LDAP目录库中。可通过专有接口或ESB平台的JMS接口,与集团CA中心交换用户证书信息。IM/AM组件还提供SSO Agent插件,可实现对多种应用系统、管理系统的SSO单点登录集成。
6、分布式容器集群管理系统(TOS)
基于分布式容器集群管理系统(TOS)构建的服务器虚拟化资源池,可为大数据平台系统的各类应用、分布式计算和存储服务组件提供多租户隔离的容器资源调配管理、应用打包部署及SLA管理、作业调度管理以及统一运维监控管理。系统配置管理信息以及系统运行监控记录是存于本地的关系数据库中,可对外提供SNMP协议接口、ESB平台的JMS消息接口,以实现与集团运维管理平台交换运维监控信息。
1.1.3 系统接口设计
平台对外提供各种开发接口,包括完全兼容Hadoop生态圈开源各个组件API接口,REST访问接口包括Web HDFS以及StarGate/Hyperbase REST接口;同时通过支持SQL2003标准以及PL/SQL,提供JDBC/ODBC接口,能够使传统业务场景向大数据平台上进行平滑迁移;此外,大数据平台为数据挖掘提供Java API以及R语言接口。通过接口,用户可以直接使用R语言与SQL进行交互式数据挖掘探索,同时可以通过平台开放的API进行二次开发,通过JDBC/ODBC接口给上层应用进行SQL查询。此外,Inceptor中还包含了基础的并行统计挖掘算法库的Java API,用户可以通过并行算法库进行数据挖掘的二次开发。
1.1.1.1 项目概述
随着利率市场化进程加快、互联网金融业态的发展,传统银行与实体经济的业务横向联系与深度融合进展迅速,业务数据的内容不断丰富,建立在数据处理技术之上业务洞察能力也需要不断提升。
恒丰银行处于业务发展的新阶段,新业务模式的创新离不开数据的支持,也对数据信息服务的总体能力提出了新的要求。基于大数据平台技术,整合现有行内数据,接入行外数据,搭建处理能力更强,更易于扩展,性能更高的统一数据平台。不仅可以很好的满足高计算、高存储、高负载的要求,更能够对海量的数据进行数据存储、清洗、加工、建模等,把先前无法利用的数据充分利用,提升对数据的认识,抓住机遇为恒丰银行数据平台建设做好最基础、最扎实的工作。
根据恒丰银行的实际应用需要,分别搭建基于大数据平台的企业数据仓库和历史数据分析探索平台,满足海量数据的低成本高效存储、加工、使用,完成企业数据仓库应用的迁移和优化重构,满足移动互联渠道场景的高并发低延时数据服务需求,协助业务数据分析团队自主的数据探索和业务建模。
恒丰银行传统数据仓库是建立在IOE体系之下,支持TB级别数据存储并提供复杂数据查询功能的数据管理体系。传统数据仓库建设多年,已接入数据源30多个,配套监管数据集市、数据分析集市,风险数据集市三个数据集市,负责十几个管理应用和监管系统的数据需求,下游建有银行管理类系统如综合经营分析系统(管理驾驶舱)、自定义查询平台等,并为各分行提供数据下发服务。
随着恒丰银行业务发展,与外部机构的跨界合作的展开,历史数据越来越多,半结构化数据、非结构数据也越来越多,数据的统一存储和处理已面临硬件成本压力。
充分发挥大数据平台的技术优势,确保系统平稳安全运行,恒丰银行基于星环科技Transwarp Data Hub大数据技术构建全新的IT信息系统架构,为各数据应用系统提供功能完善、稳定可靠的大数据应用基础技术平台,更好的支持各类型海量业务数据的存储、加工、使用和数据价值提炼。
基于星环科技Transwarp Data Hub平台,恒丰银行将原有的基于Oracle的数据仓库平台平滑迁移至星环大数据平台,提升数据仓库的批处理能力,同时也建设历史数据探索的能力,基于大数据架构,完成了符合恒丰银行现状的开创型应用,例如:准实时系统日志分析应用、客户实时风险监测、基于互联网点击流数据的用户体验优化与客户行为分析、客户标签化画像应用等。
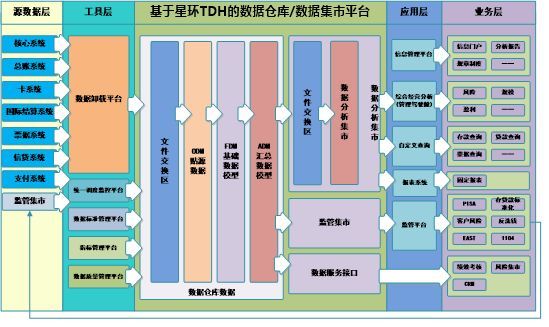 图4-3恒丰银行大平台架构
图4-3恒丰银行大平台架构
恒丰银行搭建的基于星环科技Transwarp Data Hub的大数据平台承载了恒丰银行分布在全国的数千万用户数据,服务于全国用户与行内业务人员,数据总存储量达到几十TB。
根据恒丰银行的项目建设的需求,我们推荐恒丰银行采用基于星环Transwarp Data Hub大数据平台来构建新一代数字银行平台,满足恒丰银行数据仓库的迁移、数据集市的搭建,同时协助恒丰银行构建客户360度视图应用,准实时日志和精准营销等应用。
技术组件和相关方案如下所示:
(1) Transwarp Hadoop,完成海量数据的存储。
(2) Transwarp Inceptor,完成传统基于关系型数据库SQL应用的语义解析和编译,使得基于传统关系型数据库的应用可以直接迁移至星环大数据平台,在Transwarp Data Hub平台实现企业级数据仓库的核心组件。
(3) Transwarp Hyperbase,完成银行海量历史交易明细数据的存储,支持高并发的快速查询。
(4) Transwarp Discover,完成客户画像,风险预警等分析挖掘任务。
(5) Transwarp Stream,完成实时日志的采集与报警。
1.1.1.2 项目实施情况
星环科技协助恒丰银行搭建了行内统一基于Transwarp Data Hub的数据平台,一期工作完成将原有Oracle数据仓库中的全量数据进行迁移,同时在大数据平台完成了数据批处理、数据建模、数据集市等工作。
数据移植说明:
数据仓库原有数据全部移植到新的大数据平台之上,并对数据结构进行重构。数据移植的基本流程如下图所示:
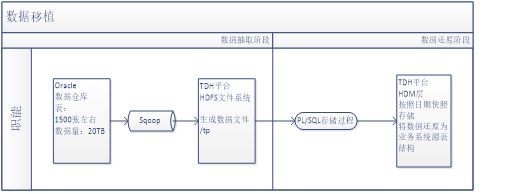 图4-4恒丰银行大平台数据移植流程
图4-4恒丰银行大平台数据移植流程
除Sqoop数据抽取阶段,剩下的主要的数据处理阶段放在大数据平台上实现,避免了对原数据仓库正常运行的影响。
数据仓库日终ETL体系流程说明:
每日业务系统日终完成后会生成相关数据文件提供给数据平台,数据平台获取文件并加载文件数据。
对每个业务系统提供的数据文件,数据平台必须对文件进行合法性校验。合法则加载文本,不合法通知业务系统人员对数据文本的导出进行调整。
ODM构建文本的映射外表,通过PL/SQL存储过程将ODM数据备份到HDM层。
部分原数据仓库的基础整合模型保留在FDM层,通过PL/SQL还原原仓库数据处理程序,并逐步将FDM层数据转移到CDM层公共模型中。
ODM层数据每日经过清洗、加工、整合后放在CDM层公共数据模型层,在公共模型层之上构建DSI服务接口,向外部集市或应用提供数据服务。
集市回流数据依照ODM-->HDM的处理方法进行数据的备份。
如图所示:
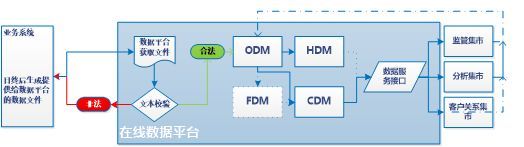
图4-5恒丰银行大数据平台数据同步流程
每日在线数据平台处理数据经过处理后,经数据复制将数据同步到历史数据平台。
校验成功后的文本同步到历史数据平台进行归档。
历史数据平台的数据与在线数据平台保持一致,存期延长。
历史数据平台之上建立历史数据查询模型,提供历史数据查询服务。
1.1.1 系统网络结构
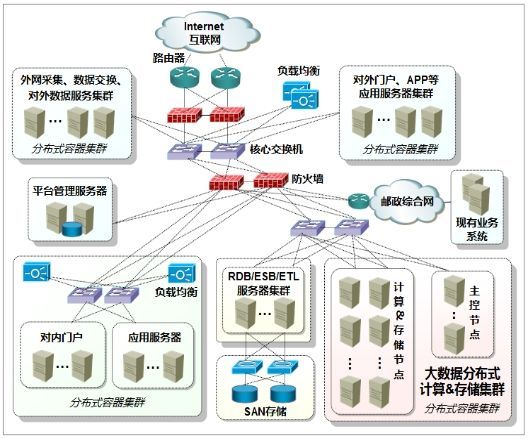
图4-16 系统网络结构图
参见上图,采用防火墙隔离,将系统划分为外网和内网两个区域。在外网区域,部署对外服务门户(含Web门户、APP接入服务等)应用服务器集群、数据采集交换服务器集群、交换机和负载均衡器等设备;在内网区域,部署平台管理服务器、对内服务门户和经营分析应用服务器集群、大数据分布式计算和存储节点服务器集群、RDB/ESB/ETL服务器集群(运行关系数据库、ESB和ETL平台软件)、交换机、负载均衡器、SAN存储等设备。内网区域的系统,通过核心交换机、路由器与集团综合网互联,与集团现有业务系统实现数据交换;集团全国、省、市三级机构人员可通过集团综合网访问本系统提供的大数据应用服务。
采用分布式容器集群管理系统(星环TOS),可为内外网区域的服务器设备及所部署的各类应用、分布式计算和存储服务组件,提供多租户隔离的容器资源(CPU、内存、存储和网络资源)分配和调度管理、应用打包部署及运行、服务注册和发现、动态扩缩、均衡容灾等资源管理服务。
平台管理服务器由两台PC服务器组成,主要用于系统配置管理、系统运维监控管理,并与集团运维管理平台系统实现对接,实时上报网管信息。
大数据分布式计算和存储节点服务器集群,基于TOS可将节点集群划分为主控节点、计算&存储节点集群:主控节点主要运行Hadoop/Spark的NameNode及MasterNode、Hyperbase的HMasterNode以及任务调度和运行监控等主控节点服务组件,而各个计算&存储节点上主要是分布式存储数据、运行主控节点所分配的分布式计算任务。
RDB/ESB/ETL服务器集群,主要部署运行关系数据库(Oracle和MySQL,用于存储机构信息、用户认证及授权信息、平台配置和监控管理等数据)、ESB和ETL平台软件。为保证数据库数据、ESB/ETL处理数据存储的高可靠性,建议配置SAN存储设备与RDB/ESB/ETL服务器连接,保证数据不丢失。数据库服务器、ESB/ETL服务器可基于HA软件构建一主一从或双机互备、N+1模式的高可用、高可靠性的服务器集群。
2 系统功能设计
2.1 概述
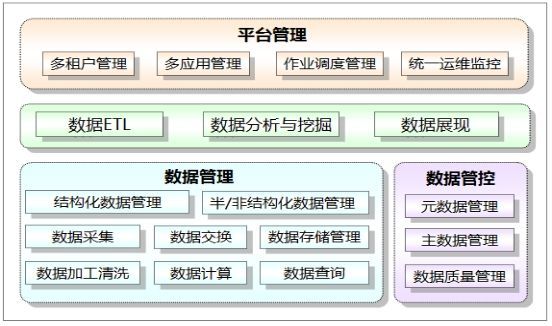
图5-1系统功能设计内容
参见上图,系统功能设计主要包括:平台管理(多租户管理、多应用管理、作业调度管理、统一运维监控)、数据管理(结构化数据管理、半/非结构化结构数据管理、数据采集、数据交换、数据存储管理、数据加工清洗、数据计算、数据查询)、数据管控(元数据、主数据管理、数据质量管理)、数据ETL、数据分析与挖掘、数据展现等。
2.2 平台管理功能
2.2.1 多应用管理
星环Transwarp Data Hub大数据平台对企业级用户提供多应用场景的支持,例如:通过Transwarp Stream提供实时数据计算场景支持,通过Transwarp Inceptor提供批处理场景支持,通过Transwarp Hyperbase提供在线数据服务场景支持,通过Transwarp Discover提供数据分析、挖掘场景支持。
星环大数据平台通过Transwarp Operating System云平台系统(以下简称TOS)实现大数据平台多应用管理,支持对应用的服务级别管理(SLA),实现应用的访问资源控制,支持资源隔离。
TOS基于Docker容器技术,支持一键部署TDH各个组件,支持优先级的抢占式资源调度和细粒度资源分配,让大数据应用轻松拥抱云服务,满足企业对于构建统一的企业大数据平台来驱动各种业务的强烈需求。
TOS主要由4部分组成,底层由基于Docker的容器技术作为所有应用服务的承载,通过将应用服务装载在Docker容器中,能够实现应用环境和底层环境的解耦合;通过优化过的Kurbernetes对整个集群的资源进行管理与调度;在此之上,内置了丰富的系统级服务应用,如完整Docker化的Transwarp Data Hub集群各个组件等;对于其他应用服务的接入,提供了完整的Docker Images Repository集中服务管理库,用户可以通过TOS提供的接口,将应用服务制作为Docker Image,加载入TOS Repository,通过定义调度规则,在TOS统一管理与调度。

图5-2大数据云平台架构图
便捷部署:基于TOS,用户可以通过Web UI、REST API或者命令行一键瞬间安装和部署TDH集群,能自动根据服务的依赖性安装所需的其他服务组件。在虚拟技术之前,部署硬件资源满足新的应用需求需要几天时间,通过虚拟化技术把这个时间降到了分钟级别,而目前基于Docker的TOS云平台把时间降到了秒级别。Docker作为装载进程的容器,不必重新启动操作系统,几秒内能关闭,可以在数据中心创建或销毁,没有额外消耗。典型的数据中心利用率是30%,通过更积极的资源分配,以低成本方式对新的实例实现更合理的资源分配,从而提高数据中心的利用效率。
完整的资源隔离:TOS通过优化Kubernetes资源管理框架实现了基于Docker容器对CPU,内存,硬盘和网络更好的隔离。TOS中Docker容器的隔离目前是由Linux内核提供的六项隔离,包括主机名与域名的隔离,信号量、消息队列和共享内存的隔离,进程编号的隔离,网络设备、网络栈、端口的隔离,挂载点(文件系统)的隔离,用户和用户组的隔离。这些隔离保证了不同容器的运行环境是基本不受影响的,比如挂载点的隔离,就保证了一个容器中的进程不能随意访问另外一个容器中的文件。
TOS平台相比于传统的Apache Yarn管理框架和开源Kubernetes的资源管理框架而言,在资源粒度方面可以管控磁盘和网络,而传统资源调度框架只能管理到CPU和内存;在隔离性方面,容器技术有天然的优势;在依赖性和通用性方面,不依赖于Hadoop组件以及技术,这意味着可以实现所有上层应用的云化开发、测试、升级以及管理调度。容器的隔离目前是由Linux内核提供的六项隔离,包括主机名与域名的隔离,信号量、消息队列和共享内存的隔离,进程编号的隔离,网络设备、网络栈、端口的隔离,挂载点(文件系统)的隔离,用户和用户组的隔离。这些隔离保证了不同容器的运行环境是基本不受影响的,比如挂载点的隔离,就保证了一个容器中的进程不能随意访问另外一个容器中的文件。
篇幅有限,无法完全展示,喜欢资料可转发+评论,私信了解更多信息。