1806TIP_ETH-CNN和ETH-LSTM应用在HEVC帧内编码块划分加速
文章目录
-
-
- Title: Reducing Complexity of HEVC_ A Deep Learning Approach
- Introduction
- 相关工作
-
- 1. 启发式算法(heuristic approaches)
- 2. 基于学习的方法(learning-based approaches)
- 从回归的视角看待CU划分
- 建立帧内模式数据集
- 降低HEVC帧内模式复杂度——ETH-CNN
-
- 1. 一种新的划分决策表达(HCPM)
- 2. ETH-CNN structure for learning HCPM
- 降低HEVC帧间模式的复杂度——ETH-LSTM
- 实验结果
-
Title: Reducing Complexity of HEVC_ A Deep Learning Approach
题目:基于深度学习降低HEVC编码复杂度的方法研究
以往的工作将CU划分看作是一个分类问题,本文提出了一种新的视角,即将其视作分层CU划分图(Hierarchical CU partition map,HCPM),基于此,提出了针对帧内编码块划分加速的 基于提前终止分层的CNN(Early-Terminal-Hierarchical CNN),取代了HM中的暴力搜索(brute-search)四叉树;针对帧间层次,提出了使用基于提前终止分层的LSTM(ETH-LSTM)预测CU划分。同时,作者构建了一个大型开源数据集用来进行模型训练。
Introduction
四叉树划分十分耗时,在参考软件HM种至少有80%的时间花费在寻找RDO(RD Optimization)的划分决策。
早期的CU划分加速的工作,大多基于启发式的方法,例如[4]-[6],15年之后,更多围绕在机器学习的方法,例如[7]-[11],[8]提出了一种基于SVM的三层联合分类器,[9]提出了使用CNN网络进行CU的划分加速,但是受限于训练集的规模(JCT-VT提供的测试数据),网络大多很浅,学习能力有限,本文因此构建了一个大规模数据集,用来训练深层的CNN网络。
同时,所有已经提出的方法,都没有探索过相邻帧的CU划分加速方法,本文首次提出使用LSTM获取相邻帧的CU划分的时间相关性信息。
本文的主要贡献有四点:
- 构建了用于CU划分的大规模开源数据集,支持帧内和帧间模式
- 提出将CU划分视作一个回归问题,而不是分类问题,并将问题抽象为HCPM(分层CU划分图)
- 基于HCPM的视角,提出了深层CNN网络模型ETH-CNN
- 首次提出ETH-LSTM用来学习CU划分的时空相关性(spatio-temporal relationship)
相关工作
1. 启发式算法(heuristic approaches)
启发式算法大多基于某些中间特征简化了暴力搜索CU的过程,具体地讲,可分为两个优化方向:
a. frame level
[4] 跳过了某些在历史帧中很少被发现的CU划分模式
b. CU level
[5],[14] 用到了金字塔运动散度和高频关键点
[6] 选择了一些关键且计算友好的特征,例如RD_cost和帧间预测误差,并最小化贝叶斯风险求得最优解
[13] 贝叶斯决策+剪枝
也有一些工作关注到了降低PU和TU划分复杂度以及RDO量化过程的加速。此外,HEVC中的帧内帧间模式预测和环路滤波的加速工作也有一些基于启发式算法的进展。
2. 基于学习的方法(learning-based approaches)
a. hand-crafted features
对于帧内编码块划分问题,一般将其视作一个二分类问题,并力图从中抽象出规律(generalize the rules of HEVC encoding components)。
对于帧间模式,[7]提出了三层提前终止框架和一些数据挖掘的技巧,[8]提出学习HEVC domain features,并使用联合SVM学习这些特征
b. deep learning
相关工作较少,[9],[26]将CNN应用在帧内编码块划分,但是这些工作受限于训练集的规模(JCT-VT提供的测试数据),网络大多很浅,学习能力有限,本文因此构建了一个大规模数据集,用来训练深层的CNN网络。
从回归的视角看待CU划分
一个RD_search的过程分为checking process(top-down)和 comparison process(bottom-up)两个阶段,如下图所示

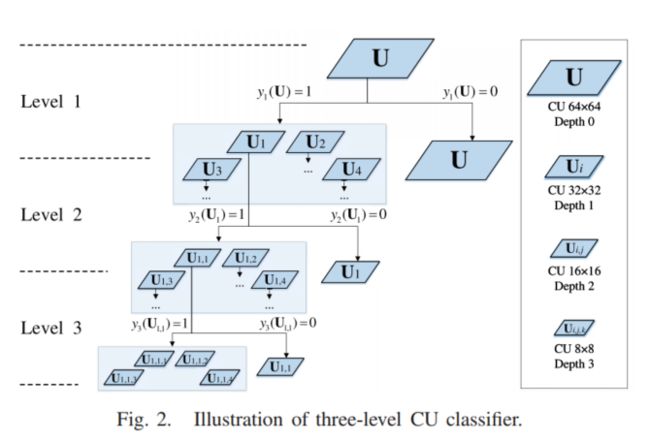
注意,本文默认CTU的尺寸为标准尺寸(64×64),最小CU的尺寸为(8×8),因此最多划分三层。
从图中不难发现,对于一个64×64的CTU可能要检查85个可能的CUs(1+4+4**2+4**3),但是最后可能最少用到一个CU(不划分)或者最多用到64个CUs(划分为8*8),不论如何都有大量的CUs并没有被用到,而计算它们的RD-cost耗费了大量的时间,这意味着可以优化的空间很大。
建立帧内模式数据集
数据集规模:2000张图片=training(1700)+validation(100)+test(200)
每个数据集被均分为四个子训练集,将高分辨率的图像进行下采样,以使得模型适应不同分辨率的图像。
所有的图像被HM 16.5编码,本文设置了4个不同的QPs{22,27,32,37},配置文件详见附录encoder_intra_main.cfg,编码后可获得slitting flags(splitting=1,non-splitting=0),一共获得110,405,784个样本。
降低HEVC帧内模式复杂度——ETH-CNN
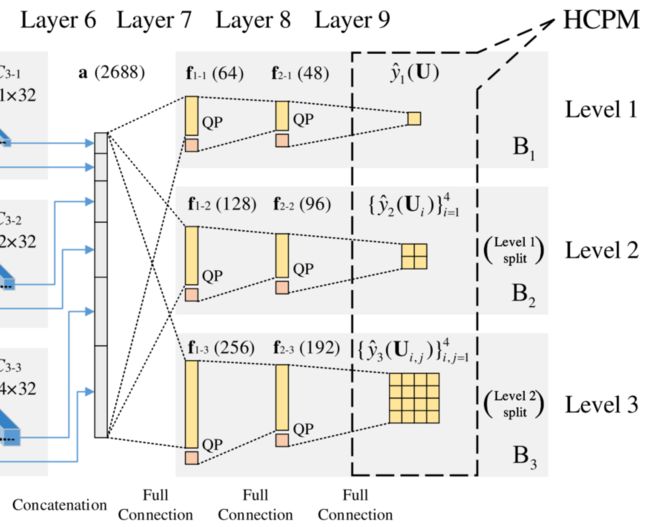
1. 一种新的划分决策表达(HCPM)
HCPM的全称是Hierarchical CU Partition Map,即分层次的CU划分图。
首先,将整个CU划分可以看作是三层二分类标签的组合 y l l = 1 3 {y_l}_{l=1}^3 yll=13,符号约定:depth 0 表示为 U U U, first-level label y 1 ( U ) y_1(U) y1(U), depth 1表示为 U i {U_i} Ui,i=1,2,3,4,second-level label y 2 ( U i ) y_2(U_i) y2(Ui),depth 2表示为 U i , j U_{i,j} Ui,j, j=1,2,3,4,third-level label y 3 ( U i , j ) y_3(U_{i,j}) y3(Ui,j)
HCPM结构

一个64×64的CTU一共有 1 + ( 1 + ( 1 + 1 ) 4 ) 4 = 83522 1+(1+(1+1)^4)^4=83522 1+(1+(1+1)4)4=83522种划分模式,因为划分模式众多,直接一次性预测出HCPM不太现实(intractable),而且模型的稳健性也不强,所以采用分阶段的产生三层HCPM, y ^ 1 ( U ) \hat{y}_1(U) y^1(U)、 { y ^ 2 ( U i ) } i = 1 4 \{\hat{y}_2(U_i)\}_{i=1}^4 {y^2(Ui)}i=14和 { y ^ 3 ( U i , j ) } j = 1 4 \{\hat{y}_3(U_{i,j})\}_{j=1}^4 {y^3(Ui,j)}j=14。(due to the enormous patterns of the CU partition, the prediction should be made step by step in a hierarchy to yield y_1, y_2 and y_3)
之前的工作往往是每层都调用一次模型,这会造成额外的消耗,但是基于HCPM,我们使用一个多阶段的预测模型,替代多次invoke同一个模型,大大减少了决策时间。
2. ETH-CNN structure for learning HCPM
ETH-CNN一共包括两层预处理层、三层卷积层、一层全连接层,如图所示,输入为一个64×64的CTU
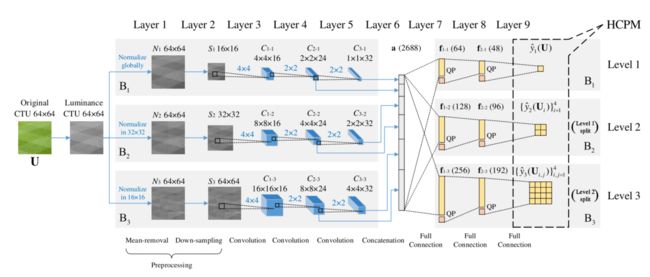
全连接层:三个branch分别在64×64、32×32和16×16的尺寸进行mean-removal,减少输入CTU的方差;同时为了让同一个的卷积核能够应用在三层,而且卷积输出为HCPM对应每层的大小,需要对三层分别进行下采样。
卷积层:为了和non-overlap CU splitting一致,设置卷积的步长等于对应卷积核的尺寸(non-overlap convolution)【但是这样的设置真的合理吗?】
拼接层:从第二层和第三层的结果进行拼接,而不是仅输出最后一层。
全连接层:两层隐藏层,一层输出层,因为QP也是影响CU划分的重要变量,所以也被拼接在最后一层。
其他:全连接层在训练时第一层和第二层会有50%和20%的概率dropout,默认激活函数为relu,输出层的激活函数是sigmoid。
Loss function
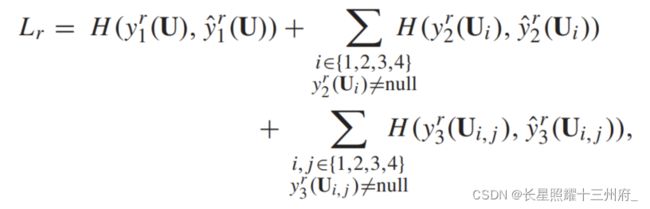
其中, H是交叉熵损失函数。
Bi-Threshold Decision Scheme
假设 P 1 ( U ) , P 2 ( U i ) 和 P 3 ( U i , j ) P_1(U),P_2(U_i)和P_3(U_{i,j}) P1(U),P2(Ui)和P3(Ui,j)分别代表 y ^ 1 ( U ) = 1 \hat{y}_1(U)=1 y^1(U)=1, y ^ 2 ( U i ) = 1 \hat{y}_2(U_i)=1 y^2(Ui)=1, y ^ 3 ( U i , j ) = 1 \hat{y}_3(U_{i,j})=1 y^3(Ui,j)=1的概率。
一般默认决策阈值 α l \alpha_l αl为0.5,当P(U)>0.5时,判定为划分,否则判定为不划分。
但是如果阈值设置的不合适,导致无论如何优化,都不能使PD最好,即PD degradation,此时我们需要考虑采用一种更加灵活的,能够在RD性能和编码复杂度之间取一个trade off的方式,庆幸的是,[8]提出了使用双门限阈值的方法, [ α ˉ l , α l ] [\bar{\alpha}_l,\alpha_l] [αˉl,αl],前者是splitting threshold,后者是non-splitting threshold。
在使用中,我们需要遍历双门限阈值内所包含的所有决策模式,则门限范围越宽,需要遍历的模式就越多,但是能够防止PD degradation,这样就是上面所谓的 complexity-PD trade-off。在实际使用中,出于简化编码复杂度的考虑,[8]提出在low-levels的branch采用更窄的门限范围,即 [ α ˉ l , α l ] ⊂ [ α ˉ 2 , α 2 ] ⊂ [ α ˉ 3 , α 3 ] [\bar{\alpha}_l,\alpha_l]\subset[\bar{\alpha}_2,\alpha_2]\subset[\bar{\alpha}_3,\alpha_3] [αˉl,αl]⊂[αˉ2,α2]⊂[αˉ3,α3],而且上门限和下门限关于0.5对称,这样就将原来的6个未知参数减少为3个。
降低HEVC帧间模式的复杂度——ETH-LSTM
首先我们分析视频图像的帧间块划分是否具有时间相关性,作者使用了两个例子,如下图所示,其中红色的块就是块划分模式不变的块,可见块划分随着时间距离的增大而逐渐不相关

作者基于相关系数和MSE分别定量的阐述了这个问题:

这充分证实了帧间的CU划分模式存在长短时间相关性(long- and short-term dependency)
作者设计了LSTM网络如下图所示

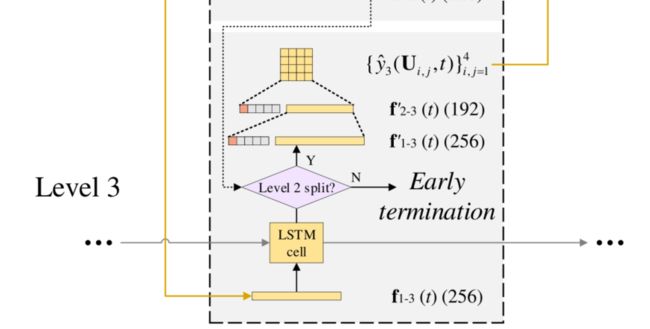
可见LSTM也是分层设计的,首先对CTU进行预测,得到残差CTU,作为LSTM的输入,在LSTM之后就是ETH-CNN训练得到的全连接层:
同时作者也考虑到了early termination的影响。
实验结果
intra-mode
从左到右:comlexity reduction ,率失真RD,CRD performance
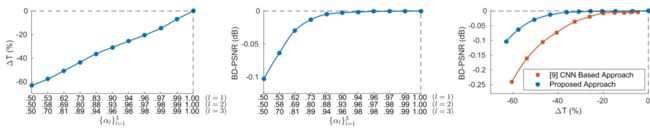
在HM16.5上的运行结果(时间占比)

:comlexity reduction ,率失真RD,CRD performance
[外链图片转存中…(img-beRsDEzo-1639058846305)]
在HM16.5上的运行结果(时间占比)
[外链图片转存中…(img-VMg0Lgn5-1639058846306)]