Python爬虫学习(2):爬取网站返回的内容为乱码解决方法
1、爬取某网站内容时,返回的结果为乱码,如图:

2、原因解释
Requests会基于HTTP头部响应的编码做出有根据的推测,当访问r.text时,Requests会使用其推测的文本编码。
查看网页返回的字符集类型:r.apparent_encoding
查看自动判断的字符集类型:r.encoding

可以看到Requests推测的文本编码(ISO-8859-1)与源网页编码(utf-8) 不一致,因此会导致乱码问题的出现。
注:源网页也能直接查看编码格式,如下图:

3、解决方法
这里要注意顺序,需要先指定r.encoding的编码格式,再访问r.text。即第9行代码必须写在第10行代码之前。
(1)方法一:直接指定r.encoding为源网页的编码格式
r.encoding="utf-8"
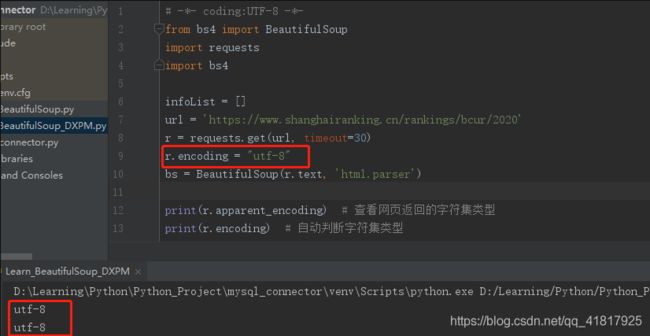
(2)方法二:通过r.apparent_encoding属性来指定,直接将其值赋给r.encoding
r.encoding = r.apparent_encoding

(3)方法三:通过编码、解码的方式

4、乱码问题解决

-----end-----