bazel高效使用和调优
Bazel 为了正确性和高性能,做了很多优秀的设计,那么我们如何正确的使用这些能力,让我们的构建性能“起飞”呢, 我们将从本地研发和 CI pipeline 两种场景进行分析。
本地研发
本地研发通常采用默认的 Bazel 配置即可,无需为增量构建和 repository_cache 做额外配置,Bazel 默认就处理的很好。
使用时应该信任 bazel 的增量构建机制,即便是从远端仓库同步了代码,也可以直接 build,无须先通过 bazel clean 清理环境。
至于 Remote Cache 和 Remote Execution,则需要结合网络状况和 Action 的执行开销,决定是否开启,参数是 --remote_cache 和 --remote_execution。
正确开启 bazel 的 remote 能力
正确开启 remote_cache 和 remote_execution 对构建效率有显著作用,但网络或 Action 特性,也可能导致收益不明显甚至劣化。
举个例子说明使用 remote_cache 的利弊:
我们假设 Action 的执行时间是 a,上传缓存和下载缓存的时间分别是 b 和 c, 缓存命中率是μ。如果不使用 remote cache,耗时恒定为 a,如果使用 remote cache, 命中缓存耗时是 c,不命中则是 a + b, 结合命中率,可以求出耗时的数学期望是 μc + (1 - μ)(a + b)。也就是说,只有 μc + (1 - μ)(a + b) < a才有收益。
例如 Action 执行时间是 500ms,上传产物时间是 200ms,下载产物时间是 100ms,缓存命中率是 30%, 代入到式子中:0.3 * (500 + 200 - 100)ms = 180ms
实践中,我们不一定能对 Action 做如此精细的数据分析,但可以根据网络状况大致估算。Bazel 提供了精细化的控制方式,可以控制某一种类型的 Action 是否启用 remote_cache,例如:

针对 CppLink 禁用 remote_cache
针对 CppLink 类型的 Action 禁用了 remote_cache 能力,其他类型则可以正常使用。甚至还可以通过 no-remote-cache-upload,设置为只禁止上传缓存,不禁止下载缓存。
对于缓存的精细化设置属于比较高级的功能,Bazel 暂时没有过多开放相关能力,相关的文档也不全。或许我们可以期待一下,未来能使用更方便的配置来管理。
缓存命中率调优
上面的例子可以看出,Action 的缓存命中率直接决定了 remote cache 的收益,如何优化缓存命中率呢?
前文介绍原理时,我们知道 Action 由 inputs 和 commands 组成,inputs 指执行 Action 所需的目录结构和文件内容。而 commands 包括了参数 (args), 执行路径 (workdir) 和环境变量 (envs)。
当缓存命中率不符合预期时,我们需要对 Action 的详情进行调试。
bazel 的 --execution_log_binary_file 参数可以把 Action 的详细信息打印到文件里。
对比两次构建的 Action 详情,就可以知道是什么参数发生了变化。
该参数导出的原始信息是二进制格式,有一些特殊字符,如下图所示:
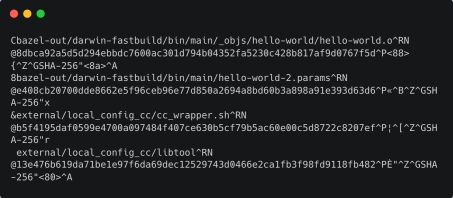
execution_log_binary_file 文本
可以借助 bazel 的 execution_log_parser 工具,把它变成更可读的形式:
该工具需要源码编译 bazel:
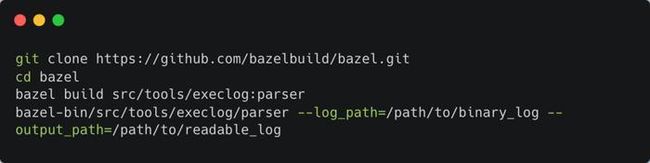
使用 parser 工具把 log 变成可读形式
转换后的文件如下图所示:
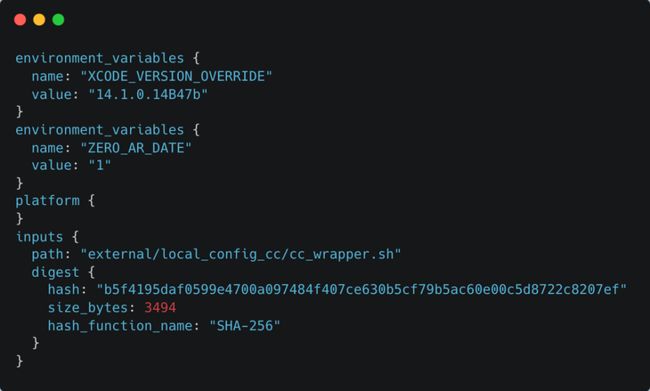
转换后的 execution_log
之后就可以用文本对比工具,对两次构建生成的 execution_log 进行对比。
CI pipeline
再来看到 CI 场景,如果你在公司里搭建了持续集成流水线,则需要考虑更多的东西。在公司内网的模式下,CI 的网络往往不再是瓶颈,我们应该完整的使用 Remote Cache 和 Remote Execution 的能力。
搭建 Remote Execution 服务
使用 Remote 能力的前提是部署支持 Remote Execution 协议的服务,一般来说,开源产品 buildfarm 或 buildbarn 就足够使用了,如果对性能和数据分析有更加极致的要求,可以考虑企业版产品或者基于 Remote Execution API 协议自研。
Remote Execution 服务的架构设计是一个很大,也很有趣的话题。篇幅关系,本文不过多深入细节,但提供几点设计要求可以参考:
Remote Execution 服务通常包括 scheduler 和 worker 组件,集群规模较小时,单 scheduler 可以调度所有 Action,而规模较大时,需要多 scheduler 协同,这是一个很大的挑战。
scheduler 的职责是把 Action 调度给 最合适 的 worker,并且分派的过程 越快越好。
如何衡量任务调度的好与坏,一方面尽量让 Action 均匀分布,避免排队时间过长,另一方面尽量利用 worker 的本地文件缓存,减少重复的文件下载。
不同客户端发来的相同 Action,可以考虑在服务端进行合并。
不同类型的 worker,需要根据系统的负载,进行弹性伸缩,以确保资源的高效利用。
客户端调度增强
除了 Remote Execution 服务,另一块需要注意的地方是客户端调度。不同于本地构建,CI 场景为了追求强隔离性,往往以实时运行 Docker Container 的方式提供构建环境。也就是说,构建环境不包含上一次构建的数据。
这种模式对于 Bazel 构建很不友好,不仅外部依赖要重新下载,而且增量编译功能也无法使用。但我们也有办法尽可能的加快构建速度。
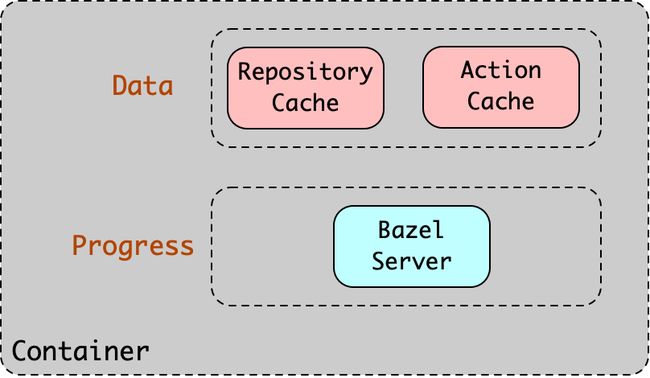
CI 环可复用的要素
首先是使用 Remote Cache 和 Remote Execution 服务,在没有增量构建的场景下,Remote Cache 和 Remote Execution 提供的优化效果是非常夸张的,根据我的观察,提速普遍在 70% 以上,甚至能达到 90%。
其次是缓存本地数据,例如 trivas CI 这样的流水线编排系统,就支持对特定目录进行缓存。它的原理是把目录打包上传到对象存储,下次构建时再下载下来。我们可以将 Bazel 的 repository_cache 和 action_local_cache 相关的目录进行缓存,下次构建就可以直接复用。
如果条件允许的话,甚至可以要求流水线提供常驻容器,这样 Bazel 的进程都可以长期保留着,下次构建时,直接 Attach 到已有的容器上执行命令即可。这种方式有望在 CI pipeline 场景实现秒级构建,这是多么酷的一件事情啊!
不过,常驻容器对安全性也带来了一定的挑战,企业具体采用那种方案,也应该因实际情况而异。
本文属于如下文章中的子章节
bazel学习系列章节汇总_m0_74043383的博客-CSDN博客