大语言模型之七- Llama-2单GPU微调SFT
(T4 16G)模型预训练colab脚本在github主页面。详见Finetuning_LLama_2_0_on_Colab_with_1_GPU.ipynb
在上一篇博客提到两种改进预训练模型性能的方法Retrieval-Augmented Generation (RAG) 或者 finetuning。本篇博客过一下模型微调。
微调:这是采用预训练的LLM并在较小的特定数据集上进一步训练它以适应特定任务或提高其性能的过程。通过微调,我们根据我们的数据调整模型的权重,使其更适合我们应用程序的独特需求。
从Hugging face的开源大模型排行榜open_llm_leaderboard可以看到Llama 2是一个高性能base model,并且其授权许可宽松,可用于商业用途的大语言模型,因而本篇以Llma-2的模型微调为例。
Llama-2 预训练
从零开始训练一个类似LlaMA 2的预训练模型需要庞大的数据和算力,预计的所有花费在一亿美金左右,这是很多公司和个人不具备这一经济条件,因而更容易些的做法是在开源预训练模型的基础上进行微调,这大大降低了数据集和算力的需求,作为个人也是可以实现的。
模型预训练colab脚本在github主页面。详见Finetuning_LLama_2_0_on_Colab_with_1_GPU.ipynb
模型量化
为了模型推理速度更快,对模型进行量化是个不错的选择,而在微调的过程中感知量化微调可以提升量化模型的性能,本小节先介绍模型的量化,下一小节介绍LlaMA-2的感知量化。
内存和磁盘需求
由于磁盘上的模型是完全加载到内存中再运行的,因而内存所需的空间和磁盘空间大小事一样的。
| Model | 模型原始大小 | 4比特量化大小 |
|---|---|---|
| 7B | 13GB | 3.9GB |
| 13B | 24GB | 7.8GB |
| 30B | 60GB | 19.5GB |
| 65B | 120GB | 38.5GB |
模型量化借助于github 上Llama2.cpp工程。可以实现模型的量化和高效的推理,llama2.cpp官方特性介绍如下:
- Plain C/C++ implementation without dependencies
- Apple silicon first-class citizen - optimized via ARM NEON, Accelerate and Metal frameworks
- AVX, AVX2 and AVX512 support for x86 architectures
- Mixed F16 / F32 precision
- 2-bit, 3-bit, 4-bit, 5-bit, 6-bit and 8-bit integer quantization support
- CUDA, Metal and OpenCL GPU backend support
量化的方法
量化的方法比较多,命名方法遵循”q” +量化比特位+变种,如下基于Huggingface上TheBloke模型库列出了可行的量化方法和他们的使用例子。
- q2_k:用Q4_k对attention.wv和feed_forward.w2量化,其他用Q2_K量化;
- q3_k_l:用Q5_k对attention.wv、attention.wo和feed_forward.w2量化,其他用Q2_K量化;
- q3_k_m:用Q4_k对attention.wv、attention.wo和feed_forward.w2量化,其他用Q2_K量化;
- q3_k_s:用用Q3_K量化所有张量;
- q4_0:原始4比特方法量化;
- q4_l:准确度介于q4_0和q5_0之间,但是推理速度比q5模型快;
- q4_k_m:使用Q6_K对attention.wv和feed_forward.w2张量的前一半量化,其他使用Q4_K量化
- q4_k_s:使用Q4_K量化所有张量
- q5_0:更高准确性,更高资源占用率,更慢的推理速度;
- q5_1:相比q5_0,可能有更高准确性,更高资源占用率以及更慢的推理速度;
- q5_k_m:使用Q6_K对attention.wv和feed_forward.w2张量的前一半量化,其他使用Q5_K量化
- q5_k_s:使用Q5_K量化所有张量
- q6_k_s:使用Q8_K量化所有张量
- q8_0:几乎和半精度浮点float16一样,资源占用率和速度都很慢,对大多数用户是不推荐的;
上述的wv、wo的意义如下,关于Llama-2模型的推导,可以大语言模型之四-LlaMA-2从模型到应用

从众多的经验上看,Q5_K_M是模型表现和资源占用平衡不错的模型,如果可以进一步牺牲性能以减少资源的消耗可以考虑Q4_K_M。总的来说K_M版本的量化比K_S版本的性能要好一些。Q2_K和Q3_*的量化版本由于牺牲的性能比较多,所以一半并不推荐。
| Model | Measure | F16 | Q4_0 | Q4_1 | Q5_0 | Q5_1 | Q8_0 |
|---|---|---|---|---|---|---|---|
| 7B | perplexity | 5.9066 | 6.1565 | 6.0912 | 5.9862 | 5.9481 | 5.9070 |
| 7B | file size | 13.0G | 3.5G | 3.9G | 4.3G | 4.7G | 6.7G |
| 7B | ms/tok @ 4th | 127 | 55 | 54 | 76 | 83 | 72 |
| 7B | ms/tok @ 8th | 122 | 43 | 45 | 52 | 56 | 67 |
| 7B | bits/weight | 16.0 | 4.5 | 5.0 | 5.5 | 6.0 | 8.5 |
| 13B | perplexity | 5.2543 | 5.3860 | 5.3608 | 5.2856 | 5.2706 | 5.2548 |
| 13B | file size | 25.0G | 6.8G | 7.6G | 8.3G | 9.1G | 13G |
| 13B | ms/tok @ 4th | - | 103 | 105 | 148 | 160 | 131 |
| 13B | ms/tok @ 8th | - | 73 | 82 | 98 | 105 | 128 |
| 13B | bits/weight | 16.0 | 4.5 | 5.0 | 5.5 | 6.0 | 8.5 |
困惑度-模型质量评估
Perplexity的计算基于模型对测试数据集中每个单词的预测概率,将这些概率取对数并取平均值,然后将结果取负指数得到Perplexity值。Perplexity值越低,表示模型对测试数据集的预测能力越好。
上表中的困惑度测量是针对wikitext2测试数据集进行的,上下文长度为512。每个token的时间是在MacBook M1 Pro 32GB RAM上使用4和8线程测量的。
# Variables
MODEL_ID = "mlabonne/EvolCodeLlama-7b"
QUANTIZATION_METHODS = ["q4_k_m"]
# Constants
MODEL_NAME = MODEL_ID.split('/')[-1]
GGML_VERSION = "gguf"
# Install llama.cpp
!git clone https://github.com/ggerganov/llama.cpp
!cd llama.cpp && git pull && make clean && LLAMA_CUBLAS=1 make
!pip install -r llama.cpp/requirements.txt
# Download model
!git lfs install
!git clone https://huggingface.co/{MODEL_ID}
# Convert to fp16
fp16 = f"{MODEL_NAME}/{MODEL_NAME.lower()}.{GGML_VERSION}.fp16.bin"
!python llama.cpp/convert.py {MODEL_NAME} --outtype f16 --outfile {fp16}
# Quantize the model for each method in the QUANTIZATION_METHODS list
for method in QUANTIZATION_METHODS:
qtype = f"{MODEL_NAME}/{MODEL_NAME.lower()}.{GGML_VERSION}.{method}.bin"
!./llama.cpp/quantize {fp16} {qtype} {method}
终端输出如下:
Cloning into 'llama.cpp'...
remote: Enumerating objects: 7959, done.
remote: Counting objects: 100% (30/30), done.
remote: Compressing objects: 100% (22/22), done.
remote: Total 7959 (delta 11), reused 19 (delta 8), pack-reused 7929
Receiving objects: 100% (7959/7959), 7.71 MiB | 15.48 MiB/s, done.
Resolving deltas: 100% (5477/5477), done.
Already up to date.
I llama.cpp build info:
I UNAME_S: Linux
I UNAME_P: x86_64
I UNAME_M: x86_64
I CFLAGS: -I. -O3 -std=c11 -fPIC -DNDEBUG -Wall -Wextra -Wpedantic -Wcast-qual -Wdouble-promotion -Wshadow -Wstrict-prototypes -Wpointer-arith -Wmissing-prototypes -pthread -march=native -mtune=native -DGGML_USE_K_QUANTS
I CXXFLAGS: -I. -I./common -O3 -std=c++11 -fPIC -DNDEBUG -Wall -Wextra -Wpedantic -Wcast-qual -Wno-unused-function -Wno-multichar -pthread -march=native -mtune=native -DGGML_USE_K_QUANTS
I LDFLAGS:
I CC: cc (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
I CXX: g++ (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
Git LFS initialized.
Cloning into 'EvolCodeLlama-7b'...
remote: Enumerating objects: 35, done.
remote: Counting objects: 100% (32/32), done.
remote: Compressing objects: 100% (32/32), done.
remote: Total 35 (delta 8), reused 0 (delta 0), pack-reused 3
Unpacking objects: 100% (35/35), 483.46 KiB | 2.78 MiB/s, done.
- Gguf
GGUF是为GGML推理而提出的存储模型的文件格式,GGUF是为了能够快速加载、保存和阅读模型的二进制文件格式,通常由Pytorch或者其他框架训练的模型需要导出为GGUF格式后再由GGML推理使用,GGUF是GGML、GGMF以及GGJT的后继者。
enum ggml_type {
GGML_TYPE_F32 = 0,
GGML_TYPE_F16 = 1,
GGML_TYPE_Q4_0 = 2,
GGML_TYPE_Q4_1 = 3,
// GGML_TYPE_Q4_2 = 4, support has been removed
// GGML_TYPE_Q4_3 (5) support has been removed
GGML_TYPE_Q5_0 = 6,
GGML_TYPE_Q5_1 = 7,
GGML_TYPE_Q8_0 = 8,
GGML_TYPE_Q8_1 = 9,
// k-quantizations
GGML_TYPE_Q2_K = 10,
GGML_TYPE_Q3_K = 11,
GGML_TYPE_Q4_K = 12,
GGML_TYPE_Q5_K = 13,
GGML_TYPE_Q6_K = 14,
GGML_TYPE_Q8_K = 15,
GGML_TYPE_I8,
GGML_TYPE_I16,
GGML_TYPE_I32,
GGML_TYPE_COUNT,
};
GGUF的具体细节参见https://github.com/philpax/ggml/blob/gguf-spec/docs/gguf.md
模型训练流程
安装环境—>加载预训练模型—>微调模型—>保存模型
当然也可以直接使用huggingface开发的模型微调库TRL,这会更简洁。
安装环境
!pip install huggingface_hub
!pip install transformers==4.31.0
!pip install accelerate==0.21.0 peft==0.4.0 bitsandbytes==0.40.2 trl==0.4.7
!pip install sentencepiece
transformers是大语言模型通用的架构,peft(Parameter Efficiency Fine-Tuning) 是集成允许先进的训练技术,如k-bit量化、低秩(low-rank)逼近和梯度检查点,从而产生更高效和资源友好的模型。
trl是Hugging face提供的强化学习库,本文只是指令微调模型,并不涉及Reward model和RLHF训练部分。
bitsandbytes是对CUDA自定义函数的轻量级封装,特别是针对8位优化器、矩阵乘法(LLM.int8())和量化函数。
加载模型
导入预训练模型. 使用transformers库的AutoTokenizer类和 AutoModelForCausalLM 类自动下载和创建模型实例. The BitsAndBytesConfig类用于模型的量化参数设置,比如4-bit是量化位数,torch.bfloat16是微调时用的数据类型。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
# Activate 4-bit precision base model loading
use_4bit = True
# Compute dtype for 4-bit base models
bnb_4bit_compute_dtype = "float16"
# Quantization type (fp4 or nf4)
bnb_4bit_quant_type = "nf4"
# Load tokenizer and model with QLoRA configuration
compute_dtype = getattr(torch, bnb_4bit_compute_dtype)
# Activate nested quantization for 4-bit base models (double quantization)
use_nested_quant = False
bnb_config = BitsAndBytesConfig(
load_in_4bit=use_4bit,
bnb_4bit_quant_type=bnb_4bit_quant_type,
bnb_4bit_compute_dtype=compute_dtype,
bnb_4bit_use_double_quant=use_nested_quant,
)
model_name = "meta-llama/Llama-2-7b-chat-hf"
#Load LLaMA tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# needed for llama tokenizer
tokenizer.pad_token = tokenizer.eos_token
####Below is for mlabonne/guanaco-llama2-1k dataset
#tokenizer.padding_side = "right" # Fix weird overflow issue with fp16 training
#Load the entire model on the GPU 0
device_map = {"": 0}
#Load base model
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map=device_map
)
从peft库导入prepare_model_for_kbit_training函数,并使用该函数进行k-bit量化前准备. gradient_checkpointing_enable() 函数是能了在训练阶段可以降低内存使用的梯度 checkpointing特性。
from peft import prepare_model_for_kbit_training
model.gradient_checkpointing_enable()
model = prepare_model_for_kbit_training(model)
可训练参数
print_trainable_parameters函数用于打印模型可训练参数. 从peft库导入 LoraConfig 和 get_peft_model函数。LoraConfig用于配置缩减训练参数的LORA (Low Rank Approximation)方法。get_peft_model将LORA方法应用于模型. 打印的是模型可训练参数的情况。
从终端输出可以看到使用LORA方法后约11%的参数才会被微调时更新, 这大大降低了内存,不同的LORA参数会需要不同的内存,下图中的两种配置,分别对应了训练的时候需要内存情况。
不同的LORA参数设置,可训练的参数量会有所差异。
def print_trainable_parameters(model):
"""
Prints the number of trainable parameters in the model.
"""
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"trainable params: {trainable_params} || all params: {all_param} || trainable%: {100 * trainable_params / all_param}"
)
from peft import LoraConfig, get_peft_model
# LoRA attention dimension 64, 8
lora_r = 8
# Alpha parameter for LoRA scaling 16,32
lora_alpha = 32
# Dropout probability for LoRA layers 0.1 0.05
lora_dropout = 0.1
peft_config = LoraConfig(
r=lora_r,
lora_alpha=lora_alpha,
target_modules=["q_proj","v_proj"],
lora_dropout=lora_dropout,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, peft_config)
print_trainable_parameters(model)
该函数输出的一个示例是:
trainable params: 32768 || all params: 139493376 || trainable%: 0.02349072116513977
trainable params: 65536 || all params: 139526144 || trainable%: 0.04697040864255519
trainable params: 98304 || all params: 156336128 || trainable%: 0.06287989939216097
trainable params: 131072 || all params: 156368896 || trainable%: 0.08382229673093043
trainable params: 163840 || all params: 240820224 || trainable%: 0.06803415314487873
trainable params: 196608 || all params: 240852992 || trainable%: 0.08162987653481174
trainable params: 229376 || all params: 257662976 || trainable%: 0.08902171493975138
trainable params: 262144 || all params: 257695744 || trainable%: 0.10172616587722923
trainable params: 294912 || all params: 342147072 || trainable%: 0.086194512282718
trainable params: 327680 || all params: 342179840 || trainable%: 0.09576250897773522
trainable params: 360448 || all params: 358989824 || trainable%: 0.10040618867235634
trainable params: 393216 || all params: 359022592 || trainable%: 0.10952402683338658
trainable params: 425984 || all params: 443473920 || trainable%: 0.09605615590652997
trainable params: 458752 || all params: 443506688 || trainable%: 0.10343744805038882
trainable params: 491520 || all params: 460316672 || trainable%: 0.1067786656226086
trainable params: 524288 || all params: 460349440 || trainable%: 0.11388913604413203
trainable params: 557056 || all params: 544800768 || trainable%: 0.10224948875255624
trainable params: 589824 || all params: 544833536 || trainable%: 0.10825765321465088
trainable params: 622592 || all params: 561643520 || trainable%: 0.11085180863477247
trainable params: 655360 || all params: 561676288 || trainable%: 0.11667930692491686
trainable params: 688128 || all params: 646127616 || trainable%: 0.10650032330455289
trainable params: 720896 || all params: 646160384 || trainable%: 0.11156610925871926
trainable params: 753664 || all params: 662970368 || trainable%: 0.11367989225123257
trainable params: 786432 || all params: 663003136 || trainable%: 0.11861663351167015
trainable params: 819200 || all params: 747454464 || trainable%: 0.10959864974463515
trainable params: 851968 || all params: 747487232 || trainable%: 0.11397759901803915
trainable params: 884736 || all params: 764297216 || trainable%: 0.11575810842676156
trainable params: 917504 || all params: 764329984 || trainable%: 0.1200402992433174
trainable params: 950272 || all params: 848781312 || trainable%: 0.11195722461900763
trainable params: 983040 || all params: 848814080 || trainable%: 0.11581334748829802
...
加载训练数据集
from datasets import load_dataset
dataset = load_dataset("Abirate/english_quotes")
dataset = dataset.map(lambda samples: tokenizer(samples["quote"]), batched=True)
Downloading readme: 0%| | 0.00/5.55k [00:00 Downloading data files: 0%| | 0/1 [00:00 Downloading data: 0%| | 0.00/647k [00:00 Extracting data files: 0%| | 0/1 [00:00 Generating train split: 0 examples [00:00, ? examples/s]
Map: 0%| | 0/2508 [00:00 从Huggingface的datasets库导入load_dataset函数, 用其加载"Abirate/english_quotes"数据集中的“quotes”字段,然后使用LLaMA tokenizer对其tokenize化。
定义训练参数并训练模型
可以使用tranformers和trl库两种方式实现微调,TRL是huggingface开发的模型微调库,旨在简化和简化语言模型的微调过程,凭借其直观的接口和广泛的功能,TRL使研究人员和从业者能够轻松高效地微调大型语言模型,如LLaMA-v2-7B。
通过利用TRL,我们可以释放语言模型化的全部潜力。它为各种NLP任务提供了一套全面的工具和技术,包括文本分类、命名实体识别、情感分析等等。有了TRL,能够根据特定需求微调LLaMA-v2-7B定制模型的功能。
这里使用了transformers库中的Trainer类,使用模型, 训练数据集, 以及训练参数对Trainer实例化,训练数据集设置了训练时的各种参数,比如 batch size, learning rate, and 优化算法 (paged_adamw_8bit)。 DataCollatorForLanguageModeling 用于整理和批处理(batch)标记化数据。 最终调用trainer.train()方法开启微调训练。在后文又给了基于trl库的更简单的接口。
import transformers
################################################################################
# TrainingArguments parameters
################################################################################
# Output directory where the model predictions and checkpoints will be stored
output_dir = "./results"
# Number of training epochs
num_train_epochs = 1
# Enable fp16/bf16 training (set bf16 to True with an A100)
fp16 = False
bf16 = False
# Batch size per GPU for training
per_device_train_batch_size = 4
# Batch size per GPU for evaluation
per_device_eval_batch_size = 4
# Number of update steps to accumulate the gradients for
gradient_accumulation_steps = 1
# Enable gradient checkpointing
gradient_checkpointing = True
# Maximum gradient normal (gradient clipping)
max_grad_norm = 0.3
# Initial learning rate (AdamW optimizer)
learning_rate = 2e-4
# Weight decay to apply to all layers except bias/LayerNorm weights
weight_decay = 0.001
# Optimizer to use, paged_adamw_8bit paged_adamw_32bit etc...
optim = "paged_adamw_8bit"
# Learning rate schedule
lr_scheduler_type = "cosine"
# Number of training steps (overrides num_train_epochs)
max_steps = -1
# Ratio of steps for a linear warmup (from 0 to learning rate)
warmup_ratio = 0.03
# Group sequences into batches with same length
# Saves memory and speeds up training considerably
group_by_length = True
# Save checkpoint every X updates steps
save_steps = 0
# Log every X updates steps
logging_steps = 25
# Fine-tuned model name
new_model = "llama-2-7b-shichaog"
# Set training parameters
training_arguments = transformers.TrainingArguments(
output_dir=output_dir,
num_train_epochs=num_train_epochs,
per_device_train_batch_size=per_device_train_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
optim=optim,
save_steps=save_steps,
logging_steps=logging_steps,
learning_rate=learning_rate,
weight_decay=weight_decay,
fp16=fp16,
bf16=bf16,
max_grad_norm=max_grad_norm,
max_steps=max_steps,
warmup_ratio=warmup_ratio,
group_by_length=group_by_length,
lr_scheduler_type=lr_scheduler_type,
report_to="tensorboard"
)
## needed for llama tokenizer
tokenizer.pad_token = tokenizer.eos_token
trainer = transformers.Trainer(
model=model,
train_dataset=dataset["train"],
# args=transformers.TrainingArguments(
# per_device_train_batch_size=1,
# gradient_accumulation_steps=4,
# warmup_steps=2,
# max_steps=10,
# learning_rate=2e-4,
# fp16=True,
# logging_steps=1,
# output_dir="outputs",
# optim="paged_adamw_8bit"
# ),
args=training_arguments,
data_collator=transformers.DataCollatorForLanguageModeling(tokenizer, mlm=False),
)
model.config.use_cache = False # silence the warnings. Please re-enable for inference!
trainer.train()
trainer.model.save_pretrained(new_model)
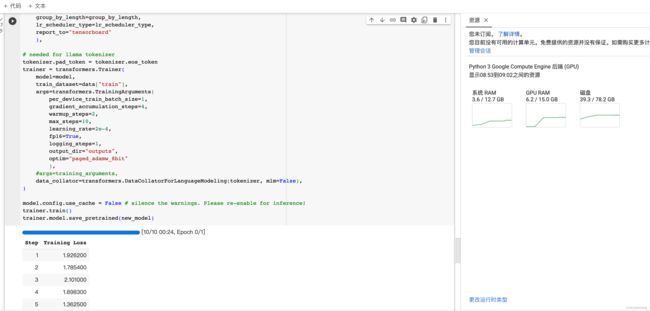
图右侧显示了GPU内存使用情况
可以使用trl库接口实现上面的功能,这会比上面更简单一些,作用上是一致的。
################################################################################
# SFT parameters
################################################################################
from trl import SFTTrainer
# Maximum sequence length to use
max_seq_length = None
# Pack multiple short examples in the same input sequence to increase efficiency
packing = False
# Load the entire model on the GPU 0
device_map = {"": 0}
# Set supervised fine-tuning parameters from trl library
trainer2 = SFTTrainer(
model=model,
train_dataset=dataset["train"],
peft_config=peft_config,
dataset_text_field="quote",
max_seq_length=max_seq_length,
tokenizer=tokenizer,
args=training_arguments,
packing=packing,
)
# Train model
trainer2.train()
# Save trained model
trainer2.model.save_pretrained(new_model)
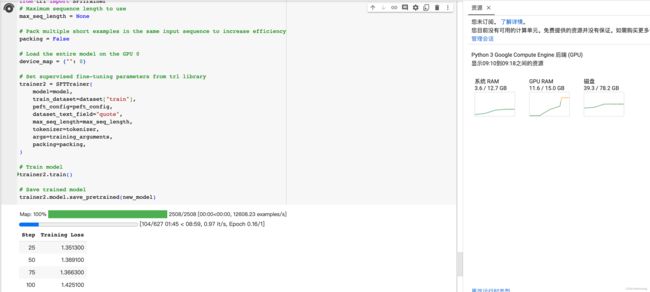
这段代码和上一段使用transformers库的Trainer是一样的意义和作用,这里的SFTTrainer是对上面Trainer的封装,参数的意义都是一样的。因为trl库支持了PPO之类的RLHF,所以把SFT也支持了会使trl库更完备一些。