BFS(广度优先搜索)和DFS(深度优先搜索)的相关介绍解析
文章目录
- DFS 和 BFS
- BFS 的应用一:层序遍历
- BFS 的应用二:最短路径
-
- 最短路径例题讲解
- DFS简介
- DFS原理分类与分析
-
- 1. DFS连通性模型
- 2. DFS思路应用-穷举求解问题
- 剪枝优化、题型归纳总结
-
- 概述:剪枝与优化
- 1.问题的转化、数据的预处理与压缩
- 2.分组问题
- 3.求最小分组数问题
- 4.求最大分组长度
- 解题思路分析
DFS(深度优先搜索)和 BFS(广度优先搜索)就像孪生兄弟,提到一个总是想起另一个。然而在实际使用中,我们用 DFS 的时候远远多于 BFS。那么,是不是 BFS 就没有什么用呢?
如果我们使用 DFS/BFS 只是为了遍历一棵树、一张图上的所有结点的话,那么 DFS 和 BFS 的能力没什么差别,我们当然更倾向于更方便写、空间复杂度更低的 DFS 遍历。不过,某些使用场景是 DFS 做不到的,只能使用 BFS 遍历。这就是本文要介绍的两个场景:「层序遍历」、「最短路径」。
DFS 和 BFS
先看看在二叉树上进行 DFS 遍历和 BFS 遍历的代码比较。
DFS 遍历使用递归:
void dfs(TreeNode root){
if (root == null) { return; }
dfs(root.left); // 递归左子树
dfs(root.right); // 递归右子树
}
BFS 遍历使用队列数据结构:
void bfs(TreeNode root) {
Queue<TreeNode> queue = new ArrayDeque<>();
queue.add(root); // 加入根节点
while (!queue.isEmpty()) { // 队列不为空
TreeNode node = queue.poll(); // Java 的 pop 写作 poll()
if (node.left != null) {
queue.add(node.left); // 加入左子树
}
if (node.right != null) {
queue.add(node.right); // 加入右子树
}
}
}
只是比较两段代码的话,最直观的感受就是:DFS 遍历的代码比 BFS 简洁太多了!这是因为递归的方式隐含地使用了系统的栈,我们不需要自己维护一个数据结构。如果只是简单地将二叉树遍历一遍,那么 DFS 显然是更方便的选择。
虽然 DFS 与 BFS 都是将二叉树的所有结点遍历了一遍,但它们遍历结点的顺序不同。
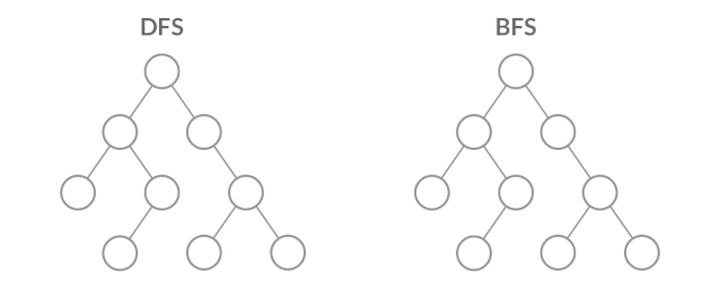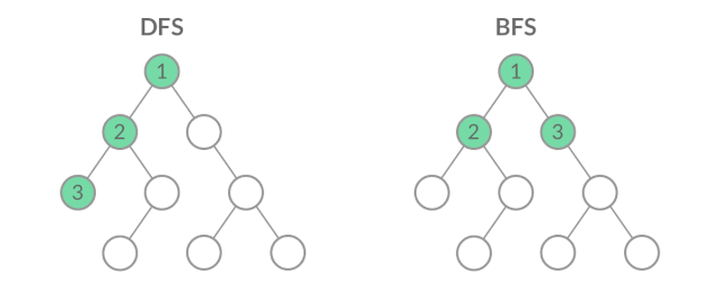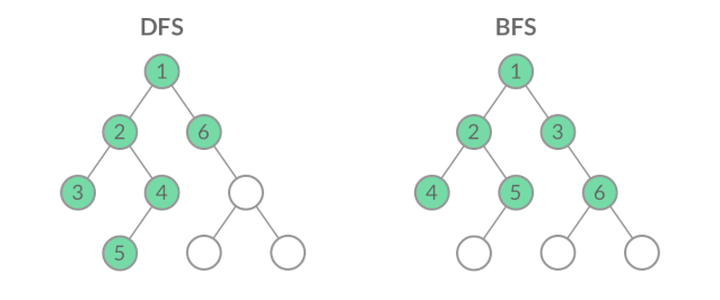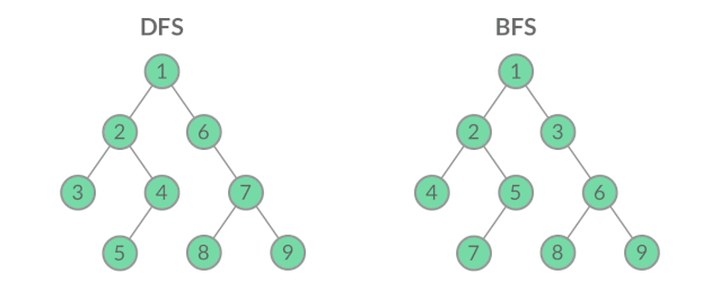
这个遍历顺序也是 BFS 能够用来解「层序遍历」、「最短路径」问题的根本原因。下面,我们结合几道例题来讲讲 BFS 是如何求解层序遍历和最短路径问题的。
BFS 的应用一:层序遍历
LeetCode 102. Binary Tree Level Order Traversal 二叉树的层序遍历(Medium)
给定一个二叉树,返回其按层序遍历得到的节点值。层序遍历即逐层地、从左到右访问所有结点。
什么是层序遍历呢?简单来说,层序遍历就是把二叉树分层,然后每一层从左到右遍历:
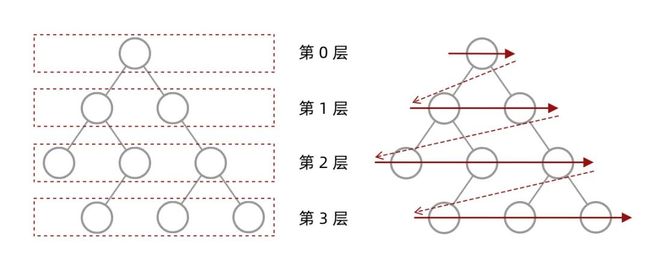
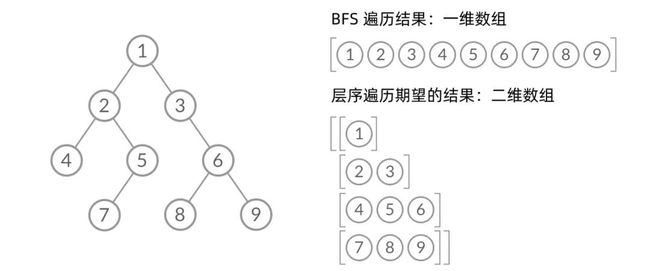
乍一看来,这个遍历顺序和 BFS 是一样的,我们可以直接用 BFS 得出层序遍历结果。然而,层序遍历要求的输入结果和 BFS 是不同的。层序遍历要求我们区分每一层,也就是返回一个二维数组。而 BFS 的遍历结果是一个一维数组,无法区分每一层。
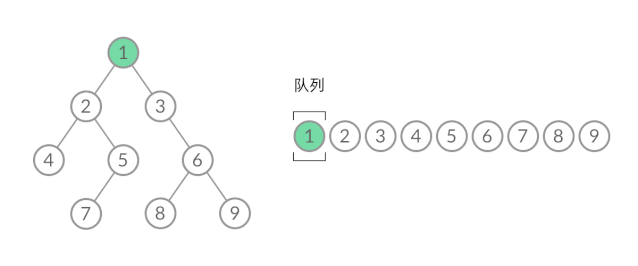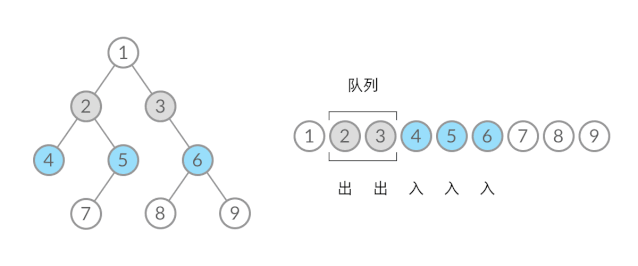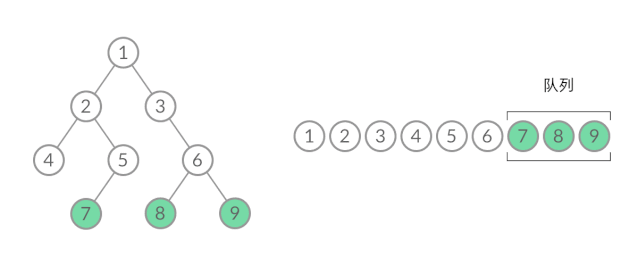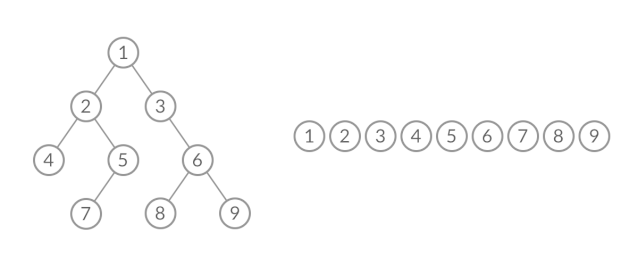
那么,怎么给 BFS 遍历的结果分层呢?我们首先来观察一下 BFS 遍历的过程中,结点进队列和出队列的过程:
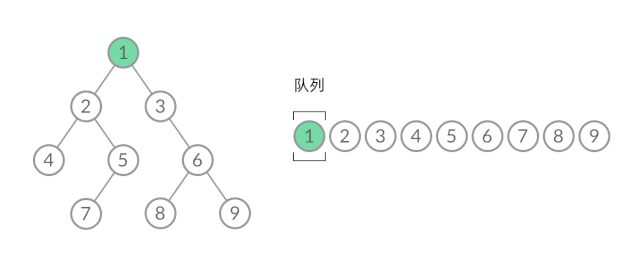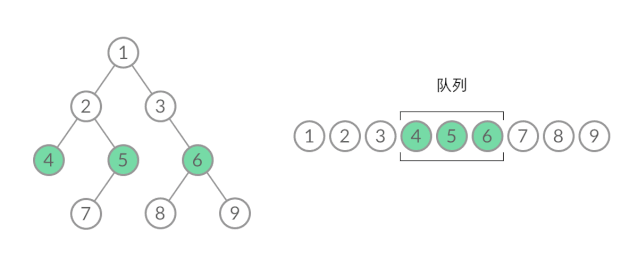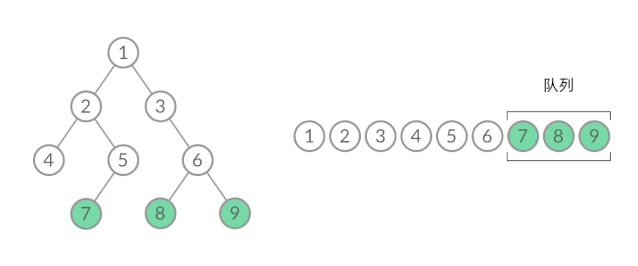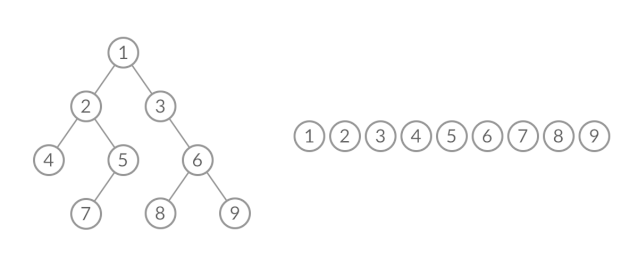
截取 BFS 遍历过程中的某个时刻:
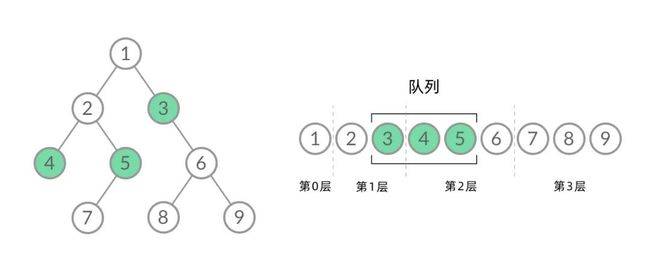
可以看到,此时队列中的结点是 3、4、5,分别来自第 1 层和第 2 层。这个时候,第 1 层的结点还没出完,第 2 层的结点就进来了,而且两层的结点在队列中紧挨在一起,我们无法区分队列中的结点来自哪一层。
因此,我们需要稍微修改一下代码,在每一层遍历开始前,先记录队列中的结点数量 n(也就是这一层的结点数量),然后一口气处理完这一层的 n 个结点。
// 二叉树的层序遍历
void bfs(TreeNode root) {
Queue<TreeNode> queue = new ArrayDeque<>();
queue.add(root);
while (!queue.isEmpty()) {
int n = queue.size(); // 注意这里
for (int i = 0; i < n; i++) { // 这里for循环中要按照n的次数循环, n就是代表每一层的个数
// 变量 i 无实际意义,只是为了循环 n 次
TreeNode node = queue.poll();
if (node.left != null) {
queue.add(node.left);
}
if (node.right != null) {
queue.add(node.right);
}
}
}
}
这样,我们就将 BFS 遍历改造成了层序遍历。在遍历的过程中,结点进队列和出队列的过程为:
可以看到,在 while 循环的每一轮中,都是将当前层的所有结点出队列,再将下一层的所有结点入队列,这样就实现了层序遍历。
最终我们得到的题解代码为:
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> res = new ArrayList<>();
Queue<TreeNode> queue = new ArrayDeque<>();
if (root != null) {
queue.add(root);
}
while (!queue.isEmpty()) {
int n = queue.size();
List<Integer> level = new ArrayList<>();
for (int i = 0; i < n; i++) {
TreeNode node = queue.poll();
level.add(node.val);
if (node.left != null) {
queue.add(node.left);
}
if (node.right != null) {
queue.add(node.right);
}
}
res.add(level);
}
return res;
}
BFS 的应用二:最短路径
在一棵树中,一个结点到另一个结点的路径是唯一的,但在图中,结点之间可能有多条路径,其中哪条路最近呢?这一类问题称为最短路径问题。最短路径问题也是 BFS 的典型应用,而且其方法与层序遍历关系密切。
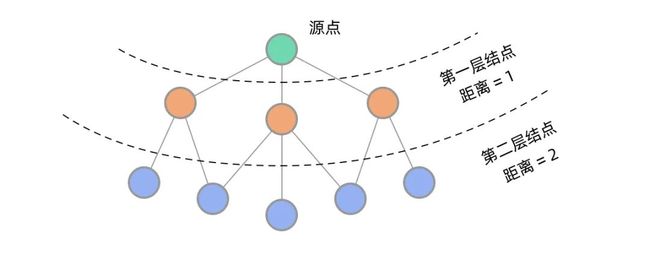
在二叉树中,BFS 可以实现一层一层的遍历。在图中同样如此。从源点出发,BFS 首先遍历到第一层结点,到源点的距离为 1,然后遍历到第二层结点,到源点的距离为 2…… 可以看到,用 BFS 的话,距离源点更近的点会先被遍历到,这样就能找到到某个点的最短路径了。
小贴士:
很多同学一看到「最短路径」,就条件反射地想到「Dijkstra 算法」。为什么 BFS 遍历也能找到最短路径呢?
这是因为,Dijkstra 算法解决的是带权最短路径问题,而我们这里关注的是无权最短路径问题。也可以看成每条边的权重都是 1。这样的最短路径问题,用 BFS 求解就行了。
在面试中,你可能更希望写 BFS 而不是 Dijkstra。毕竟,敢保证自己能写对 Dijkstra 算法的人不多。
最短路径问题属于图算法。由于图的表示和描述比较复杂,本文用比较简单的网格结构代替。网格结构是一种特殊的图,它的表示和遍历都比较简单,适合作为练习题。在 LeetCode 中,最短路径问题也以网格结构为主。
最短路径例题讲解
LeetCode 1162. As Far from Land as Possible 离开陆地的最远距离(Medium)
你现在手里有一份大小为 n*n 的地图网格 grid,上面的每个单元格都标记为 0 或者 1,其中 0 代表海洋,1 代表陆地,请你找出一个海洋区域,这个海洋区域到离它最近的地区域的距离是最大的。
我们这里说的距离是「曼哈顿距离。 ( x 0 , y 0 ) (x_0, y_0) (x0,y0) 和 ( x 1 , y 1 ) (x_1, y_1) (x1,y1) 这两个区域之间的距离是 ∣ x 0 − x 1 ∣ + ∣ y 0 − y 1 ∣ |x_0-x_1|+|y_0-y_1| ∣x0−x1∣+∣y0−y1∣。
如果我们的地图上只有陆地或者海洋,请返回 -1。
这道题就是一个在网格结构中求最短路径的问题。同时,它也是一个「岛屿问题」,即用网格中的 1 和 0 表示陆地和海洋,模拟出若干个岛屿。
在上一篇文章中,我们介绍了网格结构的基本概念,以及网格结构中的 DFS 遍历。其中一些概念和技巧也可以用在 BFS 遍历中:
- 格子
(r, c)的相邻四个格子为:(r-1, c)、(r+1, c)、(r, c-1) 和 (r, c+1); - 使用函数
inArea判断当前格子的坐标是否在网格范围内; - 将遍历过的格子标记为 2,避免重复遍历。
上一篇文章讲过了网格结构 DFS 遍历,这篇文章正好讲解一下网格结构的 BFS 遍历。要解最短路径问题,我们首先要写出层序遍历的代码,仿照上面的二叉树层序遍历代码,类似地可以写出网格层序遍历:
// 网格结构的层序遍历
// 从格子 (i, j) 开始遍历
void bfs(int[][] grid, int i, int j) {
Queue<int[]> queue = new ArrayDeque<>();
queue.add(new int[]{r, c});
while (!queue.isEmpty()) {
int n = queue.size();
for (int i = 0; i < n; i++) {
int[] node = queue.poll();
int r = node[0];
int c = node[1];
if (r-1 >= 0 && grid[r-1][c] == 0) {
grid[r-1][c] = 2;
queue.add(new int[]{r-1, c});
}
if (r+1 < N && grid[r+1][c] == 0) {
grid[r+1][c] = 2;
queue.add(new int[]{r+1, c});
}
if (c-1 >= 0 && grid[r][c-1] == 0) {
grid[r][c-1] = 2;
queue.add(new int[]{r, c-1});
}
if (c+1 < N && grid[r][c+1] == 0) {
grid[r][c+1] = 2;
queue.add(new int[]{r, c+1});
}
}
}
}
以上的层序遍历代码有几个注意点:
- 队列中的元素类型是
int[]数组,每个数组的长度为 2,包含格子的行坐标和列坐标。 - 为了避免重复遍历,这里使用到了和 DFS 遍历一样的技巧:把已遍历的格子标记为 2。注意:我们在将格子放入队列之前就将其标记为2。想一想,这是为什么?
- 在将格子放入队列之前就检查其坐标是否在网格范围内,避免将「不存在」的格子放入队列。
这段网格遍历代码还有一些可以优化的地方。由于一个格子有四个相邻的格子,代码中判断了四遍格子坐标的合法性,代码稍微有点啰嗦。我们可以用一个 moves 数组存储相邻格子的四个方向:
int[][] moves = {
{-1, 0}, {1, 0}, {0, -1}, {0, 1},
};
然后把四个 if 判断变成一个循环:
for (int[][] move : moves) {
int r2 = r + move[0];
int c2 = c + move[1];
if (inArea(grid, r2, c2) && grid[r2][c2] == 0) {
grid[r2][c2] = 2;
queue.add(new int[]{r2, c2});
}
}
写好了层序遍历的代码,接下来我们看看如何来解决本题中的最短路径问题。
这道题要找的是距离陆地最远的海洋格子。假设网格中只有一个陆地格子,我们可以从这个陆地格子出发做层序遍历,直到所有格子都遍历完。最终遍历了几层,海洋格子的最远距离就是几。 (下图为:从单个陆地格子出发的距离(动图))
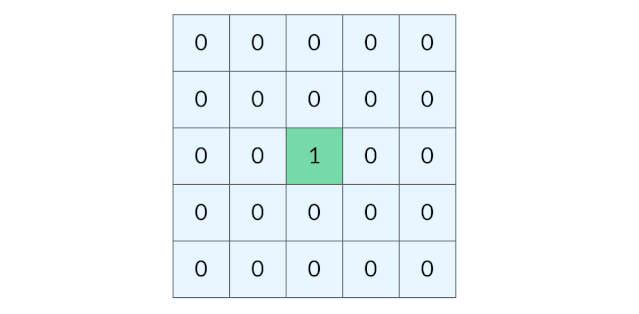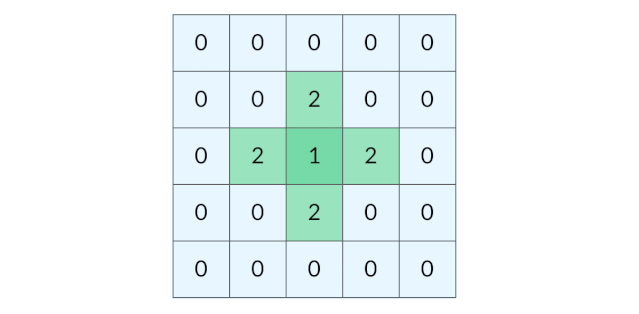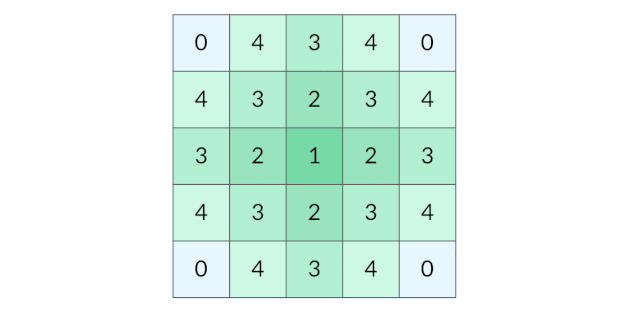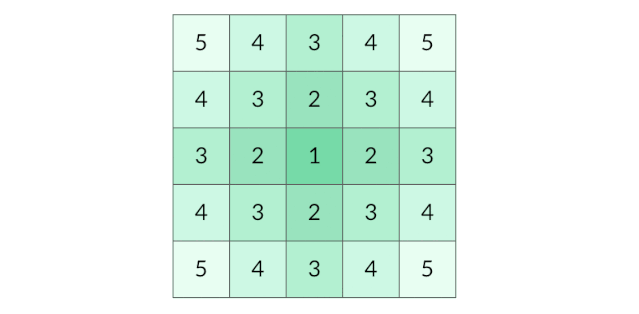
那么有多个陆地格子的时候怎么办呢?一种方法是将每个陆地格子都作为起点做一次层序遍历,但是这样的时间开销太大。
BFS 完全可以以多个格子同时作为起点。我们可以把所有的陆地格子同时放入初始队列,然后开始层序遍历,这样遍历的效果如下图所示:
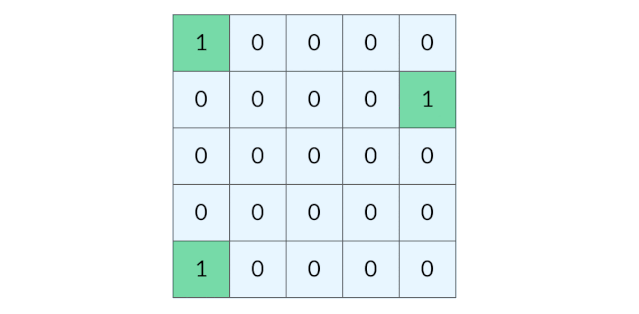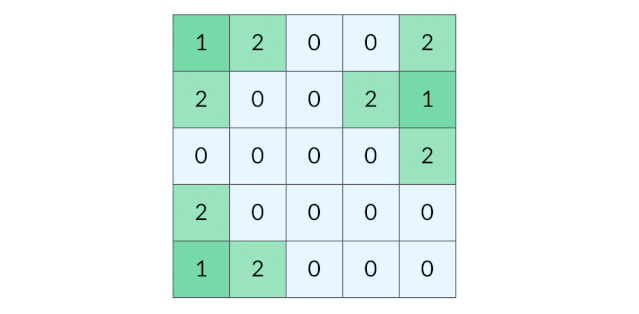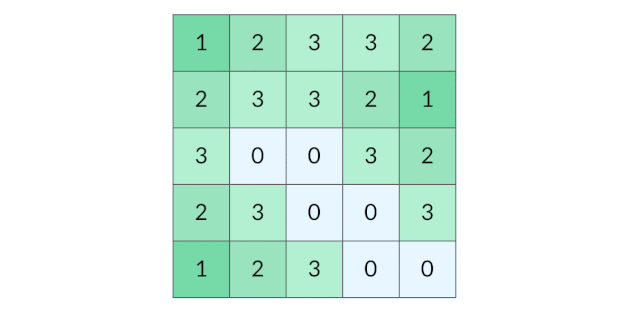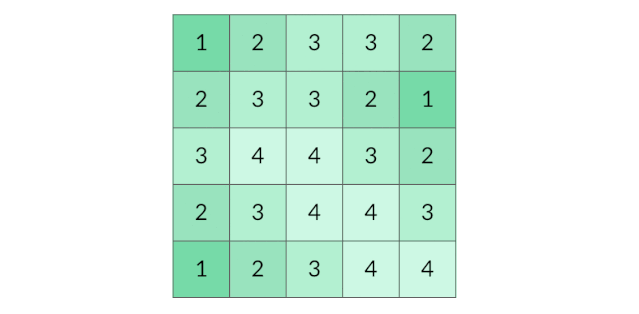
这种遍历方法实际上叫做「多源 BFS」。多源 BFS 的定义不是今天讨论的重点,你只需要记住多源 BFS 很方便,只需要把多个源点同时放入初始队列即可。
需要注意的是,虽然上面的图示用 1、2、3、4 表示层序遍历的层数,但是在代码中,我们不需要给每个遍历到的格子标记层数,只需要用一个distance变量记录当前的遍历的层数(也就是到陆地格子的距离)即可。
最终,我们得到的题解代码为:
public int maxDistance(int[][] grid) {
int N = grid.length;
Queue<int[]> queue = new ArrayDeque<>();
// 将所有的陆地格子加入队列
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
if (grid[i][j] == 1) {
queue.add(new int[]{i, j});
}
}
}
// 如果地图上只有陆地或者海洋,返回 -1
if (queue.isEmpty() || queue.size() == N * N) {
return -1;
}
int[][] moves = {
{-1, 0}, {1, 0}, {0, -1}, {0, 1},
};
int distance = -1; // 记录当前遍历的层数(距离)
while (!queue.isEmpty()) {
distance++;
int n = queue.size();
for (int i = 0; i < n; i++) {
int[] node = queue.poll();
int r = node[0];
int c = node[1];
for (int[] move : moves) {
int r2 = r + move[0];
int c2 = c + move[1];
if (inArea(grid, r2, c2) && grid[r2][c2] == 0) {
grid[r2][c2] = 2;
queue.add(new int[]{r2, c2});
}
}
}
}
return distance;
}
// 判断坐标 (r, c) 是否在网格中
boolean inArea(int[][] grid, int r, int c) {
return 0 <= r && r < grid.length
&& 0 <= c && c < grid[0].length;
}
DFS简介
定义上的深度优先搜索的思路与树的先序遍历非常相似,是针对图的搜索而提出的一种算法,下面是算法导论上的解释:
在深度优先搜索中,对于最新发现的顶点,如果它还有以此为顶点而未探测到的边,就沿此边继续探测下去,当顶点v的所有边都已被探寻过后,搜索将回溯到发现顶点v有起始点的那些边。这一过程一直进行到已发现从源顶点可达的所有顶点为止。如果还存在未被发现的顶点,则选择其中一个作为源顶点,并重复上述过程。整个过程反复进行,直到所有的顶点都被发现时为止。
在深度优先搜索中,每当扫描到已发现的顶点u的邻接表,从而发现新顶点v时,就将置v的先辈域Π[v]为u。与广度优先搜索不同的是,其先辈子图形成一棵树,深度优先搜索产生的先辈子图可以有几棵树所构成,因为搜索可能由多个源顶点开始重复进行。因此,在深度优先搜索中,先辈子图的定义也和广度优先搜索中稍有所不同:GΠ = (V, EΠ),其中EΠ = {(Π[v], v) : v ∈V 且 Π[v] ≠ NIL}
在实际的操作中,我们一般对深度优先搜索问题进行分类:
- 定义的DFS:对图的连通性进行测试,典型的问题:迷宫连通性测试、图的条件搜索等
- 广义的DFS–DFS思路的应用:DFS搜索顺序+规则问题、穷举结果寻求最优解/符合条件解等等,由于其穷举答案的本质,又被称为爆搜
深度优先搜索(下文统称DFS)的精髓在于递归求解问题的思路以及回溯的处理。而针对搜索的过程,又有更为重要的剪枝、优化,必要的剪枝优化(通过对穷举答案方式进行改进)对DFS的顺利执行有着不可或缺的作用。本文章将针对DFS的原理、常见的题型、剪枝优化的思路进行分析。当然,爆搜的题型千千万,不可能一概而论,我会通过具体的题目对几类问题的求解思路进行总结分析,构建基本的思维模型。
DFS原理分类与分析
1. DFS连通性模型
在测试图的连通性时,DFS与实际人们的思想一致,相对于起点选择一条路走到底,发现不行就返回选择的节点换一条路试,直到试出一条能到达终点的路。当然,一直试不出来就表示该起点与某点(终点)不连通。其他DFS连通性模型的思想与之类似。
针对实际问题,我又将连通性模型按照是否需要回溯继续细分:
- 无需回溯:统计某点能到达的点的个数问题
在这类问题中,我们一般从某点出发进行搜索,对于已经被搜索过的点可以直接抛弃(标记不可访问),对于当前被搜索的点递归搜索周围邻接的点并进行计数,直到无法搜索到合法的点返回。最终计数变量将记录所有能到达的点。
典型模板题:ACWing.1113 红与黑
解题报告:https://blog.csdn.net/yanweiqi1754989931/article/details/109243556X
- 需要回溯:迷宫类问题,测试两点间连通性
在这类问题中,由于当前选择的路径未必能够到达目标点,因此需要设置回溯,当搜索到非法路径返回时需要“恢复现场”,即:对于该路径下各点的访问状态重置。具体的搜索过程如下图所演示:
典型模板题:ACWing.1112 迷宫
解题报告:https://blog.csdn.net/yanweiqi1754989931/article/details/109239579
二维矩阵里走迷宫,非常简单
典型模板题:ACWing.1116 马走日
解题报告:https://blog.csdn.net/yanweiqi1754989931/article/details/109247649
这题堪称经典,与迷宫模板不同的是移动路径的选择和点合法性的判断,属于简单的搜索题
根据数据结构,又可以将两个模型分别继续细分,DFS可以基于邻接矩阵、邻接表、边集数组实现,思路相同,只是路径的遍历方式、点的访问有所改变。
这里留个坑,以后会选择不同数据结构类型的题目补充在这里
总结一下DFS的模板框架(简单描述)
function dfs(当前状态){
if(当前状态 == 目的状态){
···
}
for(···寻找新状态){
if(状态合法){
vis[访问该点];
dfs(新状态);
?是否需要恢复现场->vis[恢复访问]
}
}
if(找不到新状态){
···
}
}
2. DFS思路应用-穷举求解问题
在无路可走时,我们往往会选择搜索算法,因为我们期望利用计算机的高性能来有目的的穷举一个问题的部分甚至所有可能情况,从而在这些情况中寻找符合题目要求的答案。这也是“爆搜”之名的由来
我们约定,对于问题的介入状态,叫初始状态,要求的状态叫目标状态。
这里的搜索就是对实时产生的状态进行分析检测,直到得到一个目标状态或符合要求的最佳状态为止。对于实时产生新的状态的过程叫扩展(由一个状态,应用规则,产生新状态的过程)
搜索的要点:
- 选定初始状态,在某些问题中可能是从多个合法状态分别入手搜索;
- 遍历自初始状态或当前状态所产生的合法状态,产生新的状态并进入递归;
- 检查新状态是否为目标状态,是则返回,否则继续遍历,重复2-3步骤
对状态的处理:DFS时,用一个数组存放产生的所有状态。
- 把初始状态放入数组中,设为当前状态;
- 扩展当前的状态,从合法状态中旬寻找一个新的状态放入数组中,同时把新产生的状态设为当前状态;
- 判断当前状态是否和前面的状态重复,如果重复则回到上一个状态,产生它的另一状态;
- 判断当前状态是否为目标状态,如果是目标目标状态,则找到一个解答,根据实际问题需求,选择继续寻找答案或是直接返回。
- 如果数组为空,说明对于该问题无解。
与图的搜索类似,算法的框架基本不变,不同的是对于新状态的寻找、控制递归终止的条件更为复杂。在实际的题目中,会有一些题目需要对合法的新状态进行干预:可能在首轮搜索无法应用规则或所有条件均不满足且需要人为创建新的规则以继续搜索答案。这里也会设计到一系列剪枝与优化的问题。
function dfs(当前状态, 一系列其他的状态量){
if(当前状态 == 目的状态){
···
}
for(···寻找新状态){
if(状态合法){
vis[访问该点];
dfs(新状态);
?是否需要恢复现场->vis[恢复访问]
}
}
if(找不到新状态){
是否需要创建新规则?{
创建并对当前状态进行访问vis;
继续搜索;
恢复现场/恢复访问vis;
}
}
}
这里举一道具体的题目案例来演示:ACWing分成互质组
题目描述:
给定 n 个正整数,将它们分组,使得每组中任意两个数互质。至少要分成多少个组?
输入格式
第一行是一个正整数 n。
第二行是 n 个不大于10000的正整数。
输出格式
一个正整数,即最少需要的组数。
数据范围
1≤n≤10
输入样例:
6
14 20 33 117 143 175
输出样例:
3
题目分析与算法设计:
给定n个数字分成互质组,那么考虑最坏的情况,要分成n组(n个数均不互质)。因为题目的数据量并不大,可以采用DFS解决,具体思路如下:
预备工作:准备一个数组存输入数据,准备一个容器,用于存不同的组,准备一个检索函数,可以检索指定分组内是否存在与目的数字重合的
- **开始DFS:**首先是递归终止条件,判断是否搜到末尾,搜到末尾则更新组数计数的值,返回;
- **继续:**每次在已有分组中从头开始搜索,用检索函数判断当前数字是否可以加入分组,若可以,加入后递归向下一个数字搜索
- **新建分组:**考虑组数为0的情况、找不到可以加入组的情况,应该设置创建新分组的情况,加入新分组后,同样递归向后搜索。
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
const int N = 11;
int n, p[N], cnt, ans = N;
vector<int> num[N]; //这里使用STL中的Vector,其长度可变,更方便模拟分组的状态
int gcd(int x, int y){
return y ? gcd(y, x % y) : x; //辗转相除求最大公约数
}
//判断两数是否互质
bool check(int x, int t){
for (int i = 0; i < num[t].size(); i++){
if (gcd(x, num[t][i]) > 1) return false;
}
return true;
void dfs(int now)
{
if (now == n){
ans = min(ans, cnt); //每次搜完取最小组数
return;
}
for (int i = 0; i < cnt; i++){
if (check(p[now], i)){
num[now].push_back(p[now]);
dfs(now + 1);
num[i].pop_back();
}
}
//需要考虑首次搜索无组可加、当前状态无组可加
num[cnt++].push_back(p[u]);
dfs(now + 1);
num[--cnt].pop_back();
}
int main(){
cin >> n;
for (int i = 0; i < n; i++) cin >> p[i];
dfs(0);
cout << ans << endl;
return 0;
}
剪枝优化、题型归纳总结
在通过搜索解决实际问题的过程中,我们是通过穷举每种情况来寻找合法解,然而在一些情况比较复杂的题目、数据量较强的题目中,由于算法的时间复杂度较高、数据规模过大,从而会导致运行超时甚至程序卡死,因此在对复杂问题的答案进行搜索时,我们应该灵活的针对每种题型设计对应的搜索规则并进行优化,通常通过设置剪枝、排除无效情况、对问题进行适当的转化等手法对搜索算法进行优化,使算法高效的执行并得出我们想要的结果。
对算法的剪枝与优化堪称是爆搜算法的精髓,如何合理的设置剪枝优化直接关系能否得到结果,这对我们的解题思维是一个很大的挑战,本板块将对常见的剪枝优化思路、对细节的处理进行归纳总结。
概述:剪枝与优化
一.剪枝与优化的原则
1.正确性
剪枝优化的过程是使算法逼近最优解的过程,而不是使算法远离最优解甚至跳过最优解的过程。剪枝的前提是保证对最优解不丢不漏。
2.准确性
在保证正确性的前提下,我们采取必要的手段使算法跳过一定不含有目标状态/最优解的分支,从而保证算法高效地进行并更迅速的找出
3.高效性
设计优化程序的根本目的,是要减少搜索的次数,使程序运行的时间减少. 但为了使搜索次数尽可能的减少,我们又必须花工夫设计出一个准确性较高的优化算法,而当算法的准确性升高,其判断的次数必定增多,从而又导致耗时的增多,这便引出了矛盾. 因此,如何在优化与效率之间寻找一个平衡点,使得程序的时间复杂度尽可能降低,同样是非常重要的。
二.剪枝与优化的一般入手点
1.优化搜索顺序:
在一些题目中,可以通过对子问题分支进行分析,先解决相对简单的子问题从而使尚未解决的子问题得到简化,通过对搜索顺序的优化可以实现这一点。
2.排除冗余信息:
对限制条件进行分析,不要额外添加没有意义的搜索规则
3.可行性剪枝:
对于显然不包含目标状态的搜索方向及时停止搜索,转而向可能包含目标状态的分支进行搜索
4.最优性剪枝:
每次搜索完成后更新当前得到的最优状态/最优解,在每次搜索开始前判断当前解是否已经比上次得出的状态/解更劣?如果是则停止本次搜索,转向其他搜索分支
5.记忆化搜索:
这是技术活~这里不展开赘述
1.问题的转化、数据的预处理与压缩
在解决实际问题时,我们可以巧妙地对题目给出的数据进行适当的转化,从而构造出DFS的模型进行求解。
这与数学上的构造函数思想类似,在掌握题目数据的基础上对数据进行预处理从而构造可以按照某规则进行检索的新数据,通过对新数据进行搜索从而得出原数据符合要求的解。
对于问题的转化:这里举一个有趣的题目作为例子:ACWing.1117 单词接龙,本题有一种解法便是在读入单词数目后初始化一张邻接表,用于表示对应序号的两个单词重叠部分的长度,同时再设置一个访问状态数组,这样就可以在表中进行搜索,每搜索完一轮更新最长长度,最终得到的便是最长“龙”的长度。
题目描述
单词接龙是一个与我们经常玩的成语接龙相类似的游戏。现在我们已知一组单词,且给定一个开头的字母,要求出以这个字母开头的最长的“龙”,每个单词最多被使用两次。
在两个单词相连时,其重合部分合为一部分,例如 beast 和 astonish ,如果接成一条龙则变为 beastonish。
我们可以任意选择重合部分的长度,但其长度必须大于等于1,且严格小于两个串的长度,例如 at 和 atide 间不能相连。
输入格式
输入的第一行为一个单独的整数 n 表示单词数,以下 n 行每行有一个单词(只含有大写或小写字母,长度不超过20),输入的最后一行为一个单个字符,表示“龙”开头的字母。
你可以假定以此字母开头的“龙”一定存在。
输出格式
只需输出以此字母开头的最长的“龙”的长度。
输入样例:
5
at
touch
cheat
choose
tact
a
输出样例
23
提示:连成的“龙”为 “atoucheatactactouchoose”。
#include <bits/stdc++.h>
#define N 26
using namespace std;
vector<int> ver[N],edge[N];//匹配的单词编号和匹配长度
string word[N];
int n, res;
int st[N];
void dfs(string u, int k)
{
st[k] ++;
res = max(res, (int)u.size());
for(int i = 0;i < ver[k].size(); i++)
{
int point = ver[k][i],d = edge[k][i];
if(st[point]<2)
dfs(u + word[point].substr(d), point);
}
st[k]--;
}
int main(){
cin >> n;
for(int i=1;i<=n;i++) cin >> word[i];
for(int i=1;i<=n;i++)
for(int j=1;j<=n;j++)
{
string a = word[i] , b = word[j];
int len = min(a.size(),b.size());
for(int k=1;k<len;k++)
{
if(a.substr(a.size()-k)==b.substr(0,k))
{
ver[i].push_back(j);
edge[i].push_back(k);
break;
}
}
}
string head;
cin >> head;
for(int i = 1; i <= n; i++)
if(head[0] == word[i][0]) dfs(word[i], i);
cout << res << endl;
return 0;
}
对于数据的预处理和规模压缩,这里同样举一个非常巧妙地例子:数独
题目描述
数独是一种传统益智游戏,你需要把一个9 × 9的数独补充完整,使得图中每行、每列、每个3 × 3的九宫格内数字1~9均恰好出现一次。
请编写一个程序填写数独。
输入格式
输入包含多组测试用例。
每个测试用例占一行,包含81个字符,代表数独的81个格内数据(顺序总体由上到下,同行由左到右)。
每个字符都是一个数字(1-9)或一个”.”(表示尚未填充)。
您可以假设输入中的每个谜题都只有一个解决方案。
文件结尾处为包含单词“end”的单行,表示输入结束。
输出格式
每个测试用例,输出一行数据,代表填充完全后的数独。
输入样例:
4…8.5.3…7…2…6…8.4…1…6.3.7.5…2…1.4…
…52…8.4…3…9…5.1…6…2…7…3…6…1…7.4…3.
end
输出样例:
417369825632158947958724316825437169791586432346912758289643571573291684164875293
416837529982465371735129468571298643293746185864351297647913852359682714128574936
题目分析:
本题目数据量较大,用爆搜解决超时是个问题,因此如何优化剪枝便成了重点,下面是需要进行的准备工作,这些预处理极其关键!:
借鉴自yxc大佬的思路,本题可以用二进制位表示的方法巧妙地解决,因此需要提前准备一些数位转换的表以便使用
- 数组map:在进行lowbit运算时,将返回值转换成对应的含义(数字)
- 数组ones:每个数的二进制表示中有几个1
- 数组sudoku:存放原始数据和解
- 数组row、col,cell,表示每行可供选择的数、每列可供选择的数,每个3*3方格可供选择的数
- 函数lowbit:返回一个数字的二进制表达式中最低位的1所对应的值
- 函数makeg:制作两张查询表:ones、map,以便搜索时查询
- 函数init:初始化数组row、col,cell,从输入的数据中检索每行每列的合法数字
- 函数get:找到数组row、col,cell的交集,即满足条件的合法数字
- 函数dfs:深搜解题
dfs的思路(借鉴自yxc大佬):
- 开始时判断是否搜索成功,若成功则返回
- !优化:找出备选方案数最少的空格,先填它,从而实现整体的优化
- 找出能填的数字怼上去试试,能行继续搜,搜到底return上来true,搜不到返回false,那么恢复现场,继续找数搜
#include <iostream>
#include <algorithm>
#include <cstring>
using namespace std;
const int N = 9;
int map[1 << N], ones[1 << N];
int row[N], col[N], cell[3][3];
char sudoku[100];
inline int lowbit(int x){
return x & (-x);
}
inline int get(int x, int y){
return row[x] & col[y] & cell[x / 3][y / 3];
}
void makeg(){
for(int i = 0; i < N; i++) map[1 << i] = i;
for(int i = 0, k = 0; i < (1 << N); i++, k = 0){
for(int j = i; j; j -= lowbit(j)) k++;
ones[i] = k;
}
}
void init(){
for (int i = 0; i < N; i++) row[i] = col[i] = (1 << N) - 1;
for(int i = 0; i < 3 ; i++)
for(int j = 0; j < 3; j++) cell[i][j] = (1 << N) - 1;
}
bool dfs(int cnt){
//搜索成功结束
if(!cnt) return true;
//找出备选数字数目最少的空格
int minn = 10;
int x, y;
for(int i = 0; i < N; i++){
for(int j = 0; j < N; j++){
if(sudoku[i * 9 + j] == '.'){
int tmp = ones[get(x, y)];
if(tmp < minn) minn = tmp, x = i, y = j;
}
}
}
for(int i = get(x, y); i; i -= lowbit(i)){
int tmp = map[lowbit(i)];
row[x] -= 1 << tmp;
col[y] -= 1 << tmp;
cell[x / 3][y /3] -= 1 << tmp;
sudoku[x * 9 + y] = '1' + tmp;
if(dfs(cnt - 1)) return true;
row[x] += 1 << tmp;
col[y] += 1 << tmp;
cell[x / 3][y / 3] += 1 << tmp;
sudoku[x * 9 + y] = '.';
}
return false;
}
int main(){
makeg();
while(cin >> sudoku, sudoku[0] != 'e'){
init();
int cnt = 0;
for(int i = 0, k = 0; i < N; i++){
for(int j = 0; j < N; j++, k++){
if(sudoku[k] != '.'){
int tmp = sudoku[k] - '1';
row[i] -= 1 << tmp;
col[j] -= 1 << tmp;
cell[i / 3][j / 3] -= 1 << tmp;
}
else cnt++;
}
}
dfs(cnt);
cout << sudoku << endl;
}
return 0;
}
从本题中可以看出,通过合理利用位运算使运算和数据的规模极大的得到了缩小,因此,合理利用巧解法可以优化搜索算法。但这类思路通常难以想到,需要大量的刷题经验积累。
2.分组问题
典型的例题:分成互质组: 给定 n 个正整数,将它们分组,使得每组中任意两个数互质。至少要分成多少个组?
给定n个数字分成互质组,那么考虑最坏的情况,要分成n组(n个数均不互质)。因为题目的数据量并不大,可以采用DFS解决,具体思路如下:
预备工作:准备一个数组存输入数据,准备一个容器,用于存不同的组,准备一个检索函数,可以检索指定分组内是否存在与目的数字重合的
- 开始DFS:首先是递归终止条件,判断是否搜到末尾,搜到末尾则更新组数计数的值,返回;
- 继续:每次在已有分组中从头开始搜索,用检索函数判断当前数字是否可以加入分组,若可以,加入后递归向下一个数字搜索
- 新建分组:考虑组数为0的情况、找不到可以加入组的情况,应该设置创建新分组的情况,加入新分组后,同样递归向后搜索。
//dfs搜索函数的框架:
void dfs(int now)
{
if (now == n){
ans = min(ans, cnt); //每次搜完取最小组数
return;
}
for (int i = 0; i < cnt; i++){
if (check(p[now], i)){ //check函数为检查两数是否互质的函数
num[now].push_back(p[now]);
dfs(now + 1);
num[i].pop_back();
}
}
//需要考虑首次搜索无组可加、当前状态无组可加
num[cnt++].push_back(p[u]);
dfs(now + 1);
num[--cnt].pop_back();
}
3.求最小分组数问题
请区分2!这里使求最小分组数,即存在多组可能的分组方案,
剪枝的基本思路:对于每组数据定长或有最大长度,用vector储存每组长度,如果存不下则新建分组。每轮搜索完毕更新最小组数,每次搜索开始判断当前分组数量是否已经超过历史最优解数量,如果是,放弃该搜索分支。
典型的例题:小猫爬山
太简单,上文章链接(原创):
https://blog.csdn.net/yanweiqi1754989931/article/details/109603191
https://heartfirey.github.io/2020/11/08/ACWing-165-%E5%B0%8F%E7%8C%AB%E7%88%AC%E5%B1%B1-DFS%E5%89%AA%E6%9E%9D/
4.求最大分组长度
预处理的时候要求出合法的分组长度,对于合法长度存在的区间也要进行分析,例如:
ACWing.167 木棒 DFS+剪枝(可直接参考博文内容)
https://blog.csdn.net/yanweiqi1754989931/article/details/109603322
https://heartfirey.github.io/2020/11/08/ACWing-167-%E6%9C%A8%E6%A3%92-DFS-%E5%89%AA%E6%9E%9D/
题目描述
乔治拿来一组等长的木棒,将它们随机地砍断,使得每一节木棍的长度都不超过50个长度单位。
然后他又想把这些木棍恢复到为裁截前的状态,但忘记了初始时有多少木棒以及木棒的初始长度。
请你设计一个程序,帮助乔治计算木棒的可能最小长度。
每一节木棍的长度都用大于零的整数表示。
输入格式
输入包含多组数据,每组数据包括两行。
第一行是一个不超过64的整数,表示砍断之后共有多少节木棍。
第二行是截断以后,所得到的各节木棍的长度。
在最后一组数据之后,是一个零。
输出格式
为每组数据,分别输出原始木棒的可能最小长度,每组数据占一行。
数据范围
数据保证每一节木棍的长度均不大于50。
输入样例:
9
5 2 1 5 2 1 5 2 1
4
1 2 3 4
0
输出样例:
6
5
解题思路分析
需要的准备工作如下:
- 一个数组stick:用于存放题目的输入
- 一个数组vis:记录对每根木棒的访问
- 变量cnt:用于记录总的木棍数
- 变量len:用于dfs前找到合法的长度并记录
- 变量group:分组数
- 变量total:记录总长度
下面分析解题思路:
- 木棒的原始长度未知,但是所有木棒的总长度已知,因此我们可以通过枚举每个”假设“合法的长度(可以被总长度整除),并通过搜索判断该长度是否真正合法。这里有一点要注意,合法的长度一定比最长的木棒大,比所有的木棒短,因此变得到了合法长度存在的区间;
- 在假设合法长度确定的同时也就确定了小木棒的数量cnt=sum/len,那么这个就可以作为合法标志的判断条件:在所有的小木棍都用完的情况下拼成了cnt个长度相等的小木棒。
- dfs的搜索思路:
- 枚举长度len;
- 用之前还没有使用过的小木棍拼凑小木棒;
- 判断该长度方案是否可行。
剪枝与优化:
- 在搜索时设置一个fail变量,标记拼接失败的木棍的长度, 避免同样长度的木棒重复搜索
- 不容易考虑到的是:当该木棍在开头和结尾都不可以使用的时候, 那么该方案就失败了。因此在搜索失败时要进行及时判断处理
- 可以在一开始时对所有的木棒排序,从大到小,若填上最长的之后没有可以匹配的话,那么这个长度绝对是不合法的。(大块一定比小块需要搜索的次数少)
- 限制小木棍加入到木棒中的编号,保证加入进来的木棍的长度是递减的(必须先排序)
参考文章(侵删)
BFS 的使用场景:层序遍历、最短路径问题
深度优先搜索(DFS) 总结(算法+剪枝+优化总结)