【综述】跨模态可信感知
文章目录
- 跨模态可信感知综述
-
- 摘要
- 引言
- 跨协议通信模式
-
- PCP
- 网络架构
- 跨模态可信感知
-
- 跨模态可信感知的概念
- 跨模态可信感知的热点研究场景
- 目前存在的挑战
- 可能改进的方案
- 参考文献
跨模态可信感知综述
摘要
随着人工智能相关理论和技术的崛起,通信和感知领域的研究引入了一种全新的模式。传统的通信方式不再局限于传统的调制信号,而是可以利用各种介质收集数据并进行编码。同样,感知的输入也不再受限于传感器的数据,而可以包括来自手机扬声器的音波振幅和能量等信息。这一创新使得在原本没有直接控制关系的运动和声波等数据模式之间实现了跨界控制,为跨模态的方法在控制安全方面带来了挑战。在面对跨模态可信感知的安全问题时,各大设备厂商也纷纷采取一系列对策,限制对数据的感知。面对数据获取层面的限制,跨模态可信感知的研究领域采用了多轴数据融合、数据挖掘、滤波去噪等方法,以尽可能地恢复缺失的信息。这些方法旨在将缺失的数据分布与原始数据分布的差异最小化。目前,在跨模态可信感知领域取得了显著进展,涵盖了音频窃听、高精度词语分割、无人机干扰控制等多个方面。这些进展突破了传统单一强相关的控制关系,实现了跨模态的映射关系,为未来的研究和应用提供了新的可能性。
引言
随着传感器技术和智能设备可用性的不断发展,智能终端设备的功能越来越强大,这使得智能设备面临的应用场景和应用任务变得复杂,然而通信技术仍然依靠信号的输入、处理、输出的过程,信号的输入模式依赖与输出与处理的过程,只要信号输入能够被处理过程接受,那么就会产生相应的输出,也即控制设备作出相应,而这种控制的模式也带来了很多潜在的可能性,比如研究人员发现,声音的振幅与能量能够影响运动传感器的变化,获取这种变化可以对其与声波输入信号建立联系,能够实现从运动传感器的变化中推演声波的变化,从而以一种相关数据的形式实现运动传感器到声波数据输入的建模,实现了对于智能设备音频的窃听,类似的研究成果也诠释着跨模态控制的可能性,这得益于智能设备中数据分布的相关性,在现实生活中智能设备的这种相关性是不可避免的,跨模态可信感知的研究对于数据安全以及控制理论、技术的发展有着重大的意义。同时,跨模态的可信感知又有种种挑战,例如低采样率的限制、设备依赖性的关系。
现代智能手机通常配备三轴加速度计和三轴陀螺仪。这些传感器对设备的运动高度敏感,已广泛应用于感知方向、振动、冲击等。三轴加速度计是一种用于捕捉物体在三个感知轴上的加速度的设备。通常,每个轴都由一个传感单元来处理,该传感单元由一个可移动的地震体、若干个固定电极和几个弹簧腿组成,如图 1所示。当加速度计沿着传感轴经历加速度时,相应的地震质量会朝着相反的方向移动,并且在电极之间会产生电容的变化。这种变化会生成一个模拟信号,然后将其映射到加速度的测量值上。

智能手机上的陀螺仪通常利用科里奥利力来测量三个轴周围的角速度,就像图 2所示。每个轴的传感单元与加速度计的结构相似,但不同之处在于质量可以在两个轴上自由振动,而不仅仅是沿一个轴移动。当陀螺仪受到外部的角速度影响时,由于科里奥利效应,质量会倾向于在同一平面内振动,并施加垂直于旋转轴和质量振动方向的科里奥利力。这个力导致质量的位移,并改变了电极之间的电容。通过测量电容的变化,可以得到设备的角速度信息。在实际应用中,运动传感器捕获的信息不仅取决于其对周围环境的敏感度,还受采样频率的影响。

人类语音信号具有一个基本频率,它承载着重要的语言和非语言信息,如自然度、情感和说话者特质[1]。这个基本频率是声带的振动率,因年龄、性别、个体生理差异等因素而有很大的变化[2][3]。一般来说,成年男性和成年女性的基本频率分别在85-180Hz和165-255Hz之间[4][5]。由于这个基本频率的范围在一定程度上与智能手机传感器的频率范围重叠,因此加速度计和陀螺仪已被用于捕获语音信号中低频带的一小部分信息。
Michalevsky等人[6](出处:Usenix Security 2014)进行了研究,他们将智能手机放置在与扬声器相同的固体表面上的实验设置中。他们利用智能手机的陀螺仪来“捕捉”扬声器发出的语音信号,并使用捕获到的信息进行语音识别和说话人身份识别。在这种情况下,陀螺仪实际上捕捉到的是表面的振动信号。然而,由于陀螺仪对表面振动的敏感度相对较低,而且采样率受到限制(通常为200Hz),因此实现较高的识别成功率变得较为困难。
Zhang等人[7]研究了用户在拿着手机或将其放在桌上时说话的情境。在这个设置中,研究人员利用加速度计来捕捉在空气中传播的语音信号,并使用所得到的加速度计读数进行热词检测,例如“Okay Google”和“Hi Galaxy”。然而,[8]中的实验结果表明,通过空气传播的语音信号可能不太可能对运动传感器产生明显的影响。因此,加速度计可能无法通过捕捉空气振动来收集足够的语音信息。
为了更深入地了解运动传感器对语音隐私的潜在威胁,Anand等人[8](S&P 2018)系统地研究了加速度计和陀螺仪在不同环境设置下对语音信号的响应。他们使用了经过人工生成的、从笔记本电脑发出的以及从扬声器播放的语音信号,这些信号在传播过程中穿越了空气或固体表面。实验结果表明,只有通过扬声器播放的语音信号穿越固体表面时才能对运动传感器产生明显的影响。基于这一观察,Anand等人[8]认为他们所研究的威胁并不超出Michalevsky等人[9]在扬声器和同一表面设置下的研究范畴。
加速度计和陀螺仪在各种应用场景中得到广泛研究,用于感知振动和运动。以下是一些相关研究和应用示例:
Marquardt等人[10]利用智能手机中的加速度计来收集和解码附近键盘上按键产生的振动信号,从而推断用户输入的文本。Owusu等人[11]、Miluzzo等人[12]、Xu等人[13]和Cai等人[14]研究表明,智能手机上的运动传感器可以用来推断用户在触摸屏上的按键动作。Matovu等人[15]展示了智能手机的加速度计测量值可用于检测和分类智能手机播放的歌曲。Son等人[16]探索了通过在无人机上调整陀螺仪的谐振频率以产生声音噪声,从而使无人机失去能力的可能性。Feng等人[17]提出了一种基于加速度计的语音助手连续认证系统,允许语音助手区分主人的命令和其他人的语音信号,通过连接在用户皮肤上的无线加速度计对语音输入进行交叉检查。VibWrite[18]利用振动电机产生的振动信号,在各种表面上实现指纹输入。他们表明,固体表面上的振动信号可以用来提取反映触摸位置和用户手指按压力度的独特特征。
另一个研究方向是基于加速度计的轨迹恢复和活动识别。Han等人[19]证明了当设备所有者在车辆中行驶时,设备上的加速度计可以用来确定设备所有者的轨迹和位置。文献[20][21][22]等研究探索了如何使用智能手机的加速度计和陀螺仪来检测和识别用户的不同活动,如步行、慢跑、骑自行车等。这些研究展示了运动传感器在多个领域中的广泛应用潜力。
跨协议通信模式
PCP
“Common Part Convergence Sublayer”(CPC)[23]是一种通信协议中的子层,通常用于数字通信系统中。它是在OSI(开放系统互联)模型中的数据链路层中的一部分,通常用于传输层和物理层之间的通信。CPC的作用是将来自不同传输层协议的数据进行封装和解封装,以便在物理媒体上传输。它负责处理多路复用、帧的创建和帧的解析等任务,以确保数据能够正确地从发送端传输到接收端。CPC通常与不同的物理层技术和传输层协议一起使用,以支持各种通信标准和网络配置。它提供了一个通用的接口,允许不同的网络设备和协议在数据链路层上进行通信。其已经作为IEEE标准802.16:无线宽带接入标准。IEEE 802.16标准于2001年首次发布,它定义了一种无线宽带接入方式,以取代目前家庭和企业的有线和DSL“最后一英里”服务。
网络架构
PCP的网络架构如图 3所示,“CPC”(Common Part Convergence Sublayer)是一种数据链路层的协议子层,通常在数字通信系统中使用。它的主要作用是在不同的数据链路层协议和物理层之间提供一个通用的接口,以便数据可以在不同的通信网络中进行传输。尤其在移动通信领域,CPC扮演着重要的角色,因为它使得不同的通信标准和网络配置可以协同工作。在物联网(IoT)传感器网络中,大量的传感器部署在不同的位置,用于监测环境参数、采集数据或执行控制任务。这些传感器可能使用不同的通信技术和协议来传输数据,例如Wi-Fi、蓝牙、LoRa、Zigbee等。同时,这些传感器也可能在不同的网络拓扑结构中运行,包括星型、网状或混合型拓扑。在这个情境下,CPC可以被看作是一个通用的数据链路层协议子层,允许各种传感器节点使用不同的通信协议和物理层技术进行数据传输。CPC协议负责将不同协议的数据进行封装和解封装,以确保数据能够在整个物联网中流动,并被正确路由到目的地。假设在一个物联网应用中,一组传感器节点使用Wi-Fi进行数据传输,而另一组使用LoRaWAN。这些传感器节点可以通过CPC协议进行数据通信,CPC将负责将Wi-Fi和LoRaWAN传感器生成的数据进行适当封装,以确保数据能够正确传输到云服务器或其他节点。这种方式使得不同类型的传感器能够协同工作,构建出更强大的物联网应用。
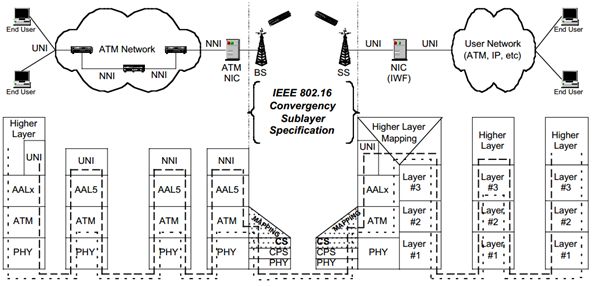
跨模态可信感知
跨模态可信感知的概念
跨模态可信感知(Cross-Modal Trusted Perception)是一种前沿性的研究领域,它融合了多个感知模态以实现可靠的信息感知和识别。该概念涵盖了多种感知方式,包括视觉、听觉、触觉、传感器数据等,旨在通过综合这些模态的信息来提高感知系统的准确性、可信度和安全性。
在跨模态可信感知中,不同感知模态之间的数据融合是核心概念之一。这意味着系统可以同时或交替地利用多个感知模态的数据,以获取更全面的信息。例如,一个跨模态可信感知系统可以结合图像、声音和传感器数据,以实现更精确的目标识别和环境感知。这种数据融合可以大大提高系统的性能,尤其是在复杂和动态的环境中。
另一个关键方面是跨模态可信感知的可信度和安全性。由于感知系统在关键应用中具有重要作用,如自动驾驶汽车、医疗诊断和安全监控,因此必须确保其感知结果的可靠性。这包括对抗攻击检测,以识别和防止恶意干扰。可信感知还需要处理不同感知模态之间的数据不匹配和误差,以确保整个系统的一致性和可靠性。跨模态可信感知的研究面临着多项技术挑战,包括跨模态数据融合、模态间的数据对齐、对抗攻击检测和隐私保护。这个领域的发展有望为未来的感知系统和智能应用带来更高的可靠性和安全性,从而推动科学和工程领域的进步。
跨模态可信感知的热点研究场景
在跨模态感知的研究工作已经持续了很久,本文将热点问题例举为毫米波雷达到人脸信息的感知、运动传感器到声音信息的感知、声波注入的运动系统控制。
A.Zakhor等[24]使用毫米波成像技术进行物体检测和人员筛查的方法,包括人脸识别。这项基本研究给毫米波到人脸信息的感知提供了实验基础。J. Kim等[25] 使用小型调频连续波(FMCW)雷达传感器,中心频率为61 GHz,带宽为6 GHz。在几个人的脸上发射和接收雷达信号来积累雷达传感器数据。基于积累的雷达传感器数据,通过训练卷积神经网络(CNN)设计合适的人脸识别分类器[26]。作者用于雷达传感器收集数据的实验安设如图 4所示。

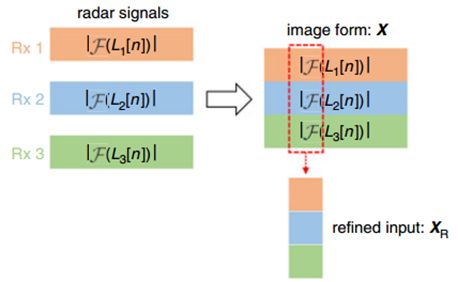
合成从多个接收通道并行接收的雷达信号,以形成图像。也就是说,雷达信号产生的输入图像数据可以表示为式(1)所示。
X = [ ∣ F ( L 1 [ n ] ) ∣ ∣ F ( L 2 [ n ] ) ∣ ⋮ ∣ F ( L I [ n ] ) ∣ ] \boldsymbol{X}=\left[\begin{array}{c} \left|\mathcal{F}\left(L_{1}[n]\right)\right| \\ \left|\mathcal{F}\left(L_{2}[n]\right)\right| \\ \vdots \\ \left|\mathcal{F}\left(L_{I}[n]\right)\right| \end{array}\right] X= ∣F(L1[n])∣∣F(L2[n])∣⋮∣F(LI[n])∣
其中 F ( L i [ t ] ) \mathcal{F}\left(L_{i}[t]\right) F(Li[t])表示时采样LPF输出的 i t h ( i = 1 , 2 , … , I ) i_{\mathrm{th}}(i=1,2, \ldots, I) ith(i=1,2,…,I)通道的快速傅里叶变换(FFT)结果。融合后的数据输入CNN层的方式如图 5所示。
Pengfei Hu等[27]提出了AccEar,一种基于加速度计的新型窃听攻击,可以重建任何具有无约束词汇的音频信号。它使用在智能手机上测量的加速度计信号,同时内置的智能手机扬声器播放音频。Michalevsky等人[28]表明,智能手机中的陀螺仪足够灵敏,可以测量其附近的声信号。作者将智能手机和有源扬声器(即播放声音)放在同一个固体表面上。扬声器发出的声音穿过固体表面,其振动会影响智能手机内置陀螺仪的读数。通过分析陀螺仪的测量值,它们能够识别人的身份,甚至检索一些特定的语音信息。然而,IMU数据只能保留频率低于200Hz的信息,这导致数字识别的准确率较低(77%)。
Roy等人[29]证明,移动设备中的振动电机通过处理其对附近声音的空气振动的响应,使其能够充当麦克风。Wang等[30]通过检测和分析口腔运动的细粒度无线电反射来获取人类对话信息。Wei等[31]使用声无线电变换(ART)算法来恢复扬声器设备的声音。Muscatell等[32]使用激光收发器窃听房间内的声音。特别是,作者使用激光发生器将激光射向房间内的物体,并使用激光接收器接收反射回来的激光。他们可以通过分析反射激光来恢复声音。Nassi等[33]使用悬挂式灯泡和远程光电传感器来窃听声音。作者指出,这种声音会引起灯泡表面的气压波动,从而使灯产生轻微的振动。然后,他们使用光电传感器分析悬挂灯泡对声音的频率响应,以恢复声音。
Zhang Yunfeng[34]提出了一种基于声波通信的通信盲区内的搜索和救援定位方法。利用声波信号的良好穿透和衍射能力来解决通信盲区内的搜索和救援定位问题。这使得无人机的接管控制变得可行,可以采用跨模态感知的技术对输入的声波进行伪造与模拟,使得无人机按照入侵者提供的干扰条件进行相应的运动。Y Son等 [35]介绍了一种使用超声波来对无人机的MEMS陀螺仪进行干扰,使无人机上的MEMS陀螺仪无法正常工作,从而致使无人机无法进行姿态控制,进而使无人机坠毁的方法。运行在笔记本电脑上的脚本程序通过外置声卡生成特定频率的噪音,这些噪音经过声频放大装置的放大后,通过扬声器来干扰MEMS陀螺仪.连接陀螺仪的开源电子原型平台arduino将陀螺仪输出的数据采集并处理,然后将该数据发送到笔记本电脑,笔记本电脑通过对陀螺仪输出的数据的检测来判断当前频段是否为共振频段。流程如图 6所示。

对于MEMS传感器的共振问题最简单的解决方法是对传感器进行物理隔离。该文献中提到,采用L3G4200陀螺仪的无人机由于受到超声波干扰而坠毁,而iPhone 5s手机中的同一型号的陀螺仪却可以免受超声波噪声的干扰这正是由于iPhone 5s手机的外壳减弱了超声波的功率。文献[36]提出了使用泡沫对MEMS传感器进行物理隔离的方案,一英尺的泡沫可以将超声波的噪声降低120分贝,从而可以很大程度上减轻超声波对MEMS传感器的干扰.文献[37]也介绍了一种物理隔离保护方案,即采用一种有镍纤维制作的保护罩来减弱超声波噪声对MEMS陀螺仪的干扰。虽然物理隔离可以缓解超声波对MEMS陀螺仪的影响,但是也带来一些其他方面的问题。比如,采用泡沫隔离板会带来散热不畅等问题.针对物理隔离方法存在的一些缺陷,文献[37]提出了一种可以主动减弱超声波对MEMS陀螺仪影响的方案,即使用两个陀螺仪并配合一定的算法来缓解超声波对陀螺仪的影响。此外,还有一些文献提出在MEMS陀螺仪上加装其反馈调节装置来减少共振带来的影响。例如,文献[38][39]提出了通过在MEMS陀螺仪上加装反馈电容来调节共振频率来减弱共振对陀螺仪的影响。
目前存在的挑战
跨模态感知技术对于智能设备的内部数据采样有着较高的依赖性,谷歌限制手机的采样率是指谷歌公司对Android操作系统中的移动设备(如智能手机)的传感器数据采样率进行了一定的限制。这些传感器数据包括加速度计、陀螺仪等,用于感知设备的运动和环境信息。限制采样率的目的可能是出于隐私和安全考虑。通过限制采样率,可以减少传感器数据的生成和传输频率,这使得完整地获取传感数据变得困难,不同的Android设备和版本可能会有不同的采样率限制,这取决于设备的硬件能力和操作系统的设置。开发人员通常需要在应用程序中考虑这些限制,以确保其在不同设备上的性能和稳定性。
另外存在的挑战是对于设备的依赖性,有很多任务并不单单靠一台智能设备就可以完成,面对这样的任务往往获取到单一设备的数据是不足以完成可信感知的。不同设备厂商生产的传感器和硬件可能存在差异,包括性能、精度和数据格式等方面。因此,开发可信感知系统需要考虑如何适应多样性的设备。有些设备可能容易受到物理攻击或篡改,而其他设备可能具有更高的安全性。确保系统在使用不同设备时依然可信是一个挑战。不同设备生成的数据可能存在格式和单位的差异,这可能会导致数据集成和处理的困难。确保数据一致性对于可信感知至关重要。
跨模态可信感知也存在着噪声干扰以及人为干扰的挑战,噪声来源于外界设备的影响,例如地磁场对于地磁计的干扰,对于未校准的加速度计等都会出现感知数据的误差,同时在人为干扰的情况下,可能会给感知模式带来灾难性的系统扰动,面对异常数据的处理也是跨模态可信感知面临的巨大挑战。
可能改进的方案
面对低采样率限制以及设备依赖性的挑战,目标能够有效的改进方案总结如下:
低采样率限制:浙江大学韩劲松教授提到一种思路,可以利用骨传导的运动传感器对外放的声音进行感知,根据奈奎斯特定理,可以解决限制频率的问题,因为IMU的采样率≤200Hz。
高频缺失:在应对声音数据高频缺失问题时,需要采用多种策略来综合传感器数据,并运用数据挖掘技术来填补缺失的高频信息。首先,可以考虑多轴数据融合策略,将不同传感器轴的数据整合起来以获取更全面的声音信息。这包括了加速度计、陀螺仪以及其他传感器数据的协同利用,因为不同轴的传感器能够捕捉不同方向上的振动和运动信息。其次,对于缺失的高频数据点,可以采用数据插值和外推技术来进行估算。这些技术基于已知数据点的模式和趋势,能够有效预测缺失值,常见的插值方法包括线性插值、多项式插值和样条插值。另外,滤波去噪是一项重要的步骤,可降低噪音的影响并还原缺失的高频信息。这可以采用低通滤波和带通滤波等方法来处理声音数据。同时,频域分析和合成是一种有效手段,可以通过分析已知频率成分的声音数据,进而合成缺失的高频成分。这需要运用傅里叶变换和逆傅里叶变换等技术。此外,机器学习和深度学习模型也可用于学习声音数据的模式和特征,然后用这些模型来填补缺失值。这包括回归模型、循环神经网络(RNN)以及卷积神经网络(CNN)等。最后,如果可能的话,可以考虑增加数据的采样率,以捕获更多的高频信息。这可能需要更高分辨率的传感器或更高的采样率设置。通过综合运用这些方法,可以最大限度地还原缺失的高频声音信息,以提高声音数据的质量和完整性。选择合适的方法将依赖于数据的性质、可用的传感器和具体应用场景。
能量分布差异:为了处理不同设备之间的声波频谱分布差异,特别是不同手机的声波数据,可以考虑采用一些增益系数的方法来进行数据校正和恢复原始数据。首先,需要对不同设备的声波传感器特征进行详细分析,包括频率响应、灵敏度、噪音水平等。这可以通过实验测量或设备制造商提供的规格进行获取。根据设备特征分析的结果,可以为每个设备制定特定的增益校正曲线。这些校正曲线可以在数据采集过程中应用,以调整不同设备的声波数据,使其在频谱分布上更加一致。其次,您提到的横切和竖切方法可以用于进一步校正和恢复原始数据。通过对声波数据进行横切和竖切分析,可以识别和矫正频谱中的差异,以尽可能减小不同设备之间的差异。对于缺失的数据点,可以考虑使用插值和外推技术来估算这些点的值。这可以在频谱分布中填补缺失的部分,以保持数据的完整性。此外,利用机器学习模型,如回归模型或深度学习模型,可以学习设备之间的差异和声波频谱分布的模式。然后,这些模型可以用于调整和校正不同设备的声波数据。如果可能的话,可以考虑在实时数据采集过程中进行校正,以确保获取的声波数据始终在预期的范围内。综合使用这些方法,可以更好地处理不同设备之间的声波频谱分布差异,并恢复原始数据的准确性。选择哪种方法将取决于具体的应用需求和可用的数据处理工具。
设备依赖性:在应对跨模态可信感知中的设备依赖性挑战时,我们可以采用多种方法来消除或减轻这种依赖性,以确保模型的可信度和泛化性。数据处理和特征工程方面,我们可以利用数据降维、特征选择和数据标准化等技术,以减小轴间能量差异对模型的影响。此外,数据融合是一个有力的工具,它可以将来自不同轴和设备的数据进行融合,综合考虑各个轴的信息。为了增加数据集的多样性,我们可以采用数据增强策略,例如合成虚拟样本、引入噪音或数据扰动。与此同时,模型适应性也至关重要,我们可以在模型设计中考虑设备依赖性,使用适应性算法动态调整模型参数以适应不同设备的数据。跨设备校准是另一个关键步骤,它可以确保设备采集的数据在一定程度上保持一致性。最后,深度学习技术如迁移学习和领域自适应也可以用来减少设备依赖性,提高模型的鲁棒性。这些方法可以相互结合使用,根据具体应用场景和数据特点进行灵活选择,以有效地处理设备依赖性挑战,从而提高跨模态可信感知系统的性能。
噪声干扰:在面对噪声或潜在的干扰挑战时,采取一系列信号处理和防御措施至关重要,以确保跨模态可信感知系统的可靠性和鲁棒性。其中包括信号调制、调频、和多元协同攻击等策略。首先,信号调制是一种有效的方法,通过将原始数据进行编码和解码,以使其在传输和接收过程中更具抗干扰性。不同的调制技术可以根据具体情况选择,例如,QPSK、QAM等。这些技术可以提高信号的可靠性,减少数据传输中的误码率。其次,调频技术可以用于对抗频率干扰和拐点干扰等问题。通过频率跳变或频率扩展,可以减轻干扰对信号的影响,提高信号的稳定性。这在无线通信和传感器网络中经常被使用。另外,多元协同攻击是指采用多种不同的攻击方式,以增加攻击的复杂性和难度,从而提高系统的安全性。例如,同时进行频率干扰和干扰信号的加性白噪声,以增加攻击者破解系统的难度。综合考虑这些策略,可以有效地缓解噪声和干扰对跨模态可信感知系统的影响,提高系统的稳定性和安全性。不同的应用场景可能需要不同的组合和定制化的方法来对抗噪声和干扰,因此在系统设计和部署时需要综合考虑这些因素。
参考文献
[1] H. Fujisaki, “Dynamic characteristics of voice fundamental frequency in speech and singing,” in The production of speech. Springer, 1983, pp. 39–55.
[2] A. De Cheveigne and H. Kawahara, “Yin, a fundamental frequency ´ estimator for speech and music,” The Journal of the Acoustical Society of America, vol. 111, no. 4, pp. 1917–1930, 2002.
[3] S. Grawunder and I. Bose, “Average speaking pitch vs. average speaker fundamental frequency–reliability, homogeneity, and self report of listener groups,” in Proceedings of the International Conference Speech Prosody, 2008, pp. 763–766.
[4] I. R. Titze and D. W. Martin, “Principles of voice production,” Acoustical Society of America Journal, vol. 104, p. 1148, 1998.
[5] R. J. Baken and R. F. Orlikoff, Clinical measurement of speech and voice. Cengage Learning, 2000.
[6] Y. Michalevsky, D. Boneh, and G. Nakibly, “Gyrophone: recognizing speech from gyroscope signals,” in Proceedings of the 23rd USENIX conference on Security Symposium. USENIX Association, 2014, pp. 1053–1067.
[7] L. Zhang, P. H. Pathak, M. Wu, Y. Zhao, and P. Mohapatra, “Accelword: Energy efficient hotword detection through accelerometer,” in Proceedings of the 13th Annual International Conference on Mobile Systems, Applications, and Services. ACM, 2015, pp. 301–315.
[8] S. A. Anand and N. Saxena, “Speechless: Analyzing the threat to speech privacy from smartphone motion sensors,” in 2018 IEEE Symposium on Security and Privacy (SP). IEEE, 2018, pp. 1000–1017.
[9] Y. Michalevsky, D. Boneh, and G. Nakibly, “Gyrophone: recognizing speech from gyroscope signals,” in Proceedings of the 23rd USENIX conference on Security Symposium. USENIX Association, 2014, pp. 1053–1067.
[10] P. Marquardt, A. Verma, H. Carter, and P. Traynor, “(sp) iphone: Decoding vibrations from nearby keyboards using mobile phone accelerometers,” in Proceedings of the 18th ACM conference on Computer and communications security. ACM, 2011, pp. 551–562.
[11] E. Owusu, J. Han, S. Das, A. Perrig, and J. Zhang, “Accessory: password inference using accelerometers on smartphones,” in Proceedings of the Twelfth Workshop on Mobile Computing Systems & Applications. ACM, 2012, p. 9.
[12] E. Miluzzo, A. Varshavsky, S. Balakrishnan, and R. R. Choudhury, “Tapprints: your finger taps have fingerprints,” in Proceedings of the 10th international conference on Mobile systems, applications, and services. ACm, 2012, pp. 323–336.
[13] Z. Xu, K. Bai, and S. Zhu, “Taplogger: Inferring user inputs on smartphone touchscreens using on-board motion sensors,” in Proceedings of the fifth ACM conference on Security and Privacy in Wireless and Mobile Networks. ACM, 2012, pp. 113–124.
[14] L. Cai and H. Chen, “Touchlogger: Inferring keystrokes on touch screen from smartphone motion.” HotSec, vol. 11, no. 2011, p. 9, 2011.
[15] R. Matovu, I. Griswold-Steiner, and A. Serwadda, “Kinetic song comprehension: Deciphering personal listening habits via phone vibrations,” arXiv preprint arXiv:1909.09123, 2019.
[16] Y. Son, H. Shin, D. Kim, Y. Park, J. Noh, K. Choi, J. Choi, and Y. Kim, “Rocking drones with intentional sound noise on gyroscopic sensors,” in Proceedings of the 24th USENIX Conference on Security Symposium. USENIX Association, 2015, pp. 881–896.
[17] H. Feng, K. Fawaz, and K. G. Shin, “Continuous authentication for voice assistants,” in Proceedings of the 23rd Annual International Conference on Mobile Computing and Networking. ACM, 2017, pp. 343–355.
[18] P. Marquardt, A. Verma, H. Carter, and P. Traynor, “(sp) iphone: Decoding vibrations from nearby keyboards using mobile phone accelerometers,” in Proceedings of the 18th ACM conference on Computer and communications security. ACM, 2011, pp. 551–562.
[19] J. Han, E. Owusu, L. T. Nguyen, A. Perrig, and J. Zhang, “Accomplice: Location inference using accelerometers on smartphones,” in 2012 Fourth International Conference on Communication Systems and Networks (COMSNETS 2012). IEEE, 2012, pp. 1–9.
[20] J. R. Kwapisz, G. M. Weiss, and S. A. Moore, “Activity recognition using cell phone accelerometers,” ACM SigKDD Explorations Newsletter, vol. 12, no. 2, pp. 74–82, 2011.
[21] A. Matic, V. Osmani, and O. Mayora, “Speech activity detection using accelerometer,” in 2012 Annual International Conference of the IEEE Engineering in Medicine and Biology Society. IEEE, 2012, pp. 2112– 2115.
[22] M. Shoaib, H. Scholten, and P. J. Havinga, “Towards physical activity recognition using smartphone sensors,” in 2013 IEEE 10th international conference on ubiquitous intelligence and computing and 2013 IEEE 10th international conference on autonomic and trusted computing. IEEE, 2013, pp. 80–87.
[23] Zupko R J. Introduction to IEEE standard 802.16: wireless broadband access[J]. Rivier Academic Journal, 2007: 1-11.
[24] Clark S E, Lovberg J A, Martin C A, et al. Passive millimeter-wave imaging for concealed object detection[C]//Sensors, and Command, Control, Communications, and Intelligence (C3I) Technologies for Homeland Defense and Law Enforcement. SPIE, 2002, 4708: 128-133.
[25] Kim J, Lee J E, Lim H S, et al. Face identification using millimetre‐wave radar sensor data[J]. Electronics Letters, 2020, 56(20): 1077-1079.
[26] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[J]. Advances in neural information processing systems, 2012, 25.
[27] Hu P, Zhuang H, Santhalingam P S, et al. Accear: Accelerometer acoustic eavesdropping with unconstrained vocabulary[C]//2022 IEEE Symposium on Security and Privacy (SP). IEEE, 2022: 1757-1773.
[28] Y. Michalevsky, D. Boneh, and G. Nakibly, “Gyrophone: Recognizing speech from gyroscope signals,” in 23rd fUSENIXg Security Symposium (fUSENIXg Security 14), 2014, pp. 1053–1067.
[29] N. Roy and R. Roy Choudhury, “Listening through a vibration motor,” in Proceedings of the 14th Annual International Conference on Mobile Systems, Applications, and Services, 2016, pp. 57–69.
[30] G. Wang, Y. Zou, Z. Zhou, K. Wu, and L. M. Ni, “We can hear you with wi-fi!” IEEE Transactions on Mobile Computing, vol. 15, no. 11, pp. 2907–2920, 2016.
[31] T. Wei, S. Wang, A. Zhou, and X. Zhang, “Acoustic eavesdropping through wireless vibrometry,” in Proceedings of the 21st Annual International Conference on Mobile Computing and Networking, 2015, pp. 130–141.
[32] R. P. Muscatell, “Laser microphone,” The Journal of the Acoustical Society of America, vol. 76, no. 4, pp. 1284–1284, 1984.
[33] B. Nassi, Y. Pirutin, A. Shamir, Y. Elovici, and B. Zadov, “Lamphone: Real-time passive sound recovery from light bulb vibrations.” IACR Cryptol. ePrint Arch., vol. 2020, p. 708, 2020.
[34] Yunfeng Z, Yang Y, Yimin D, et al. UAV search and rescue positioning method based on sound wave communication[J]. International Journal of Wireless and Mobile Computing, 2021, 21(3): 265-273.
[35] Son Y, Shin H, Kim D, et al. Rocking drones with intentional sound noise on gyroscopic sensors[C]//24th USENIX Security Symposium (USENIX Security 15). 2015: 881-896.
[36] Roth G. Simulation of the effects of acoustic noise on mems gyroscopes[D]. , 2009.
[37] Soobramaney P. Mitigation of the effects of high levels of high-frequency noise on MEMS gyroscopes[D]. Auburn University, 2013.
[38] MacDonald N C, Bertsch F M, Shaw K A, et al. Capacitance based tunable micromechanical resonators: U.S. Patent 5,640,133[P]. 1997-6-17.
[39] Jeong C, Seok S, Lee B, et al. A study on resonant frequency and Q factor tunings for MEMS vibratory gyroscopes[J]. Journal of micromechanics and microengineering, 2004, 14(11): 1530.
个人课程论文,内容仅供参考,参会2023智能安全物联网会议,思路来源于浙江大学韩劲松教授的《跨界为王–跨模态可信感知初探》