第25步 机器学习分类实战:Xgboost建模
文章目录
- 前言
- 一、Python调参
-
- (1)建模前的准备
- (2)Xgboost的调参策略
- (3)Xgboost调参演示
- 总结
前言
Xgboost,我们来了~
一、Python调参
(1)建模前的准备
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv('X disease code fs.csv')
X = dataset.iloc[:, 1:14].values
Y = dataset.iloc[:, 0].values
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size = 0.30, random_state = 666)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
(2)Xgboost的调参策略
先复习一下参数,需要调的参数有11个,很多都是熟悉的:
包括eta、gamma、max_depth、min_child_weight、max_delta_step、subsample、colsample_bytree、colsample_bylevel、lambda、alpha、n_estimators。
① n_estimators:基础模型数量,都懂了;
② eta:类似于Adaboost的leanring_rate,eta通过缩减特征的权重使提升计算过程更加保守(越不容易过拟合),默认0.3;
③ max_depth:树的最大深度,值越大,越容易过拟合,默认6;
④ gamma:值越大,算法越保守(越不容易过拟合),默认0,范围(0,1];
⑤ min_child_weight:值较大时,可以避免模型学习到局部的特殊样本,这个值过高,会导致欠拟合,默认1;
⑥ max_delta_step:设置正值算法会更保守(越不容易过拟合),默认0;
⑦ subsample:减小这个值算法会更加保守,避免过拟合,但是设置的过小,它可能会导致欠拟合,默认1,范围(0,1];
⑧ colsample_bytree:每颗树随机采样的列数的占比,默认1,范围(0,1];
⑨ colsample_bylevel:对列数的采样的占比,默认1,范围(0,1];
⑩ lambda:L2 正则化项的权重系数,越大模型越保守,默认1;
⑪ alpha:L1 正则化项的权重系数,越大模型越保守,默认0;
(3)Xgboost调参演示
(A)先默认参数走一波:
import xgboost as xgb
classifier = AdaBoostClassifier()
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
y_testprba = classifier.predict_proba(X_test)[:,1]
y_trainpred = classifier.predict(X_train)
y_trainprba = classifier.predict_proba(X_train)[:,1]
from sklearn.metrics import confusion_matrix
cm_test = confusion_matrix(y_test, y_pred)
cm_train = confusion_matrix(y_train, y_trainpred)
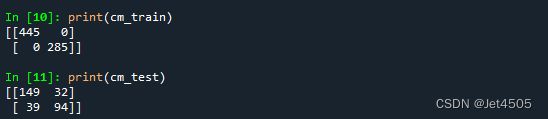
print(cm_train)
print(cm_test)
看结果,妥妥的过拟合:
(B)一个一个参数的调整,主要是解决过拟合问题了:
(a)n_estimators
import xgboost as xgb
param_grid=[{
'n_estimators':[i for i in range(100,1000,100)],
},
]
boost = xgb.XGBClassifier()
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(boost, param_grid, n_jobs = -1, verbose = 2, cv=10)
grid_search.fit(X_train, y_train)
classifier = grid_search.best_estimator_
classifier.fit(X_train, y_train)
最优的参数:n_estimators=100,那还得调小一些:
param_grid=[{
'n_estimators':[i for i in range(10,200,5)],
},
]
boost = xgb.XGBClassifier()
最优的参数:n_estimators=35。

似乎变差了~
(b)eta
param_grid=[{
'eta':[0.01,0.02,0.04,0.08,0.1,0.2,0.3],
},
]
boost = xgb.XGBClassifier(n_estimators=35)
最优的参数:eta=0.2。

过拟合有点点点缓解~
(c)max_depth
param_grid=[{
'max_depth':[i for i in range(1,20,1)],
},
]
boost = xgb.XGBClassifier(n_estimators=35, eta=0.2)
最优的参数:max_depth=2。

嗯,有点意思了~
(d)gamma
param_grid=[{
'gamma':[0,0.1,1.0,2.0,3.0],
},
]
boost = xgb.XGBClassifier(n_estimators=35, eta=0.2, max_depth=2)
最优的参数:gamma=0。
还是默认的取值~
(e)min_child_weight
param_grid=[{
'min_child_weight':[i for i in range(1,20,1)],
},
]
boost = xgb.XGBClassifier(n_estimators=35, eta=0.2, max_depth=2, gamma=0)
最优的参数:min_child_weight=6。

变化不大~
(f)max_delta_step
param_grid=[{
'max_delta_step':[i for i in range(1,20,1)],
},
]
boost = xgb.XGBClassifier(n_estimators=35, eta=0.2, max_depth=2, gamma=0, min_child_weight=6)
最优的参数:max_delta_step=2。
一点都没变~
(g)subsample
param_grid=[{
'subsample':[0.1,0.2,0.4,0.6,0.8,1.0],
},
]
boost = xgb.XGBClassifier(n_estimators=35, eta=0.2, max_depth=2, g0amma=0, min_child_weight=6, max_delta_step=2)
最优的参数:subsample=1。
没变,是默认值~
(h)colsample_bytree
param_grid=[{
'colsample_bytree':[0.1,0.2,0.4,0.6,0.8,1.0],
},
]
boost = xgb.XGBClassifier(n_estimators=35, eta=0.2, max_depth=2, gamma=0, min_child_weight=6, max_delta_step=2, subsample=1)
还是默认参数~
(i)colsample_bylevel
param_grid=[{
'colsample_bylevel':[0.1,0.2,0.4,0.6,0.8,1.0],
},
]
boost = xgb.XGBClassifier(n_estimators=35, eta=0.2, max_depth=2, gamma=0, min_child_weight=6, max_delta_step=2, subsample=1, colsample_bytree=1)
还是默认参数~
(j)reg_lambda
param_grid=[{
'reg_lambda':[i for i in range(5,100,5)],
},
]
boost = xgb.XGBClassifier(n_estimators=35, eta=0.2, max_depth=2, gamma=0, min_child_weight=6, max_delta_step=2, subsample=1, colsample_bytree=1, colsample_bylevel=1)
最优的参数:reg_lambda=10。
(k)reg_alpha
param_grid=[{
'reg_alpha':[i for i in range(1,100,2)],
},
]
boost = xgb.XGBClassifier(n_estimators=35, eta=0.2, max_depth=2, gamma=0, min_child_weight=6, max_delta_step=2, subsample=1, colsample_bytree=1, colsample_bylevel=1, reg_lambda=10)
最优的参数:reg_alpha=5。

综上,合适的参数是:
boost = xgb.XGBClassifier(n_estimators=35, eta=0.2, max_depth=2, gamma=0, min_child_weight=6, max_delta_step=2, subsample=1, colsample_bytree=1, colsample_bylevel=1, reg_lambda=10, reg_alpha=5)
(l)综合调整
上面找出来的参数,在适当的扩大一下范围试一试效果:
import xgboost as xgb
param_grid=[{
'n_estimators':[35,40],
'eta':[0.1,0.2],
'max_depth':[1,2],
'gamma':[0,0.1],
'min_child_weight':[5,6],
'max_delta_step':[1,2],
'subsample':[0.8,1.0],
'colsample_bytree':[0.8,1.0],
'colsample_bylevel':[0.8,1.0],
'reg_lambda':[9,10],
'reg_alpha':[5,6],
},
]
boost = xgb.XGBClassifier()
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(boost, param_grid, n_jobs = -1, verbose = 2, cv=10)
grid_search.fit(X_train, y_train)
classifier = grid_search.best_estimator_
classifier.fit(X_train, y_train)
y_pred = classifier.predict(X_test)
y_testprba = classifier.predict_proba(X_test)[:,1]
y_trainpred = classifier.predict(X_train)
y_trainprba = classifier.predict_proba(X_train)[:,1]
from sklearn.metrics import confusion_matrix
cm_test = confusion_matrix(y_test, y_pred)
cm_train = confusion_matrix(y_train, y_trainpred)
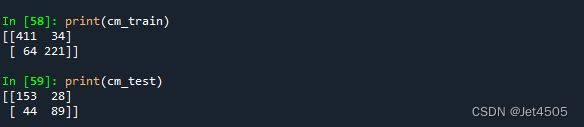
print(cm_train)
print(cm_test)
最优的参数有点变动:
boost = xgb.XGBClassifier(n_estimators=35, eta=0.2, max_depth=2, gamma=0.1, min_child_weight=6, max_delta_step=1, subsample=1, colsample_bytree=1, colsample_bylevel=1, reg_lambda=9, reg_alpha=6)
(C)顺便唠叨一下:
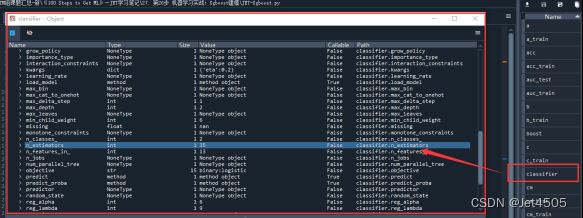
顺便提一句,可能有些同学还不懂怎么看每一步的最优参数:
我提一句,运行完这个代码以后:
classifier = grid_search.best_estimator_
在运行窗口单独运行(不需要前缀的赋值代码,就会直接输出)
grid_search.best_estimator_

或者,双击打开classifier,弹出对话框,里面也有参数:
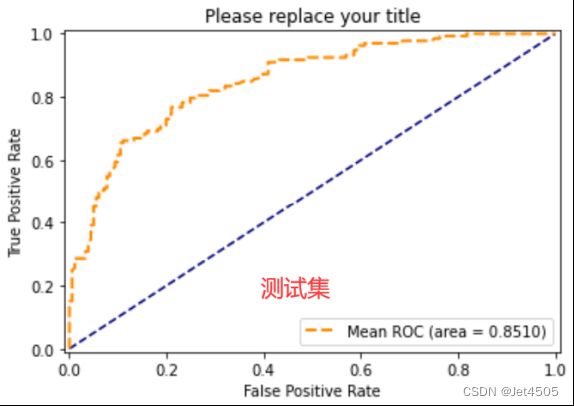
(D)最后来看看效果,似乎最后一步还把性能下降了一点,尴尬:

总结
注意,这次又提供了一种调参的思路和方法,仅供参考,大家自己都试一试。