英伟达最新开源 | FasterViT: 面相硬件优化的高效神经网络架构

Title: FasterViT: Fast Vision Transformers with Hierarchical Attention
Paper: https://arxiv.org/pdf/2306.06189.pdf
Code: https://github.com/NVlabs/FasterViT
导读
今天为大家带来 NVIDIA 研究团队最新开源的一个高效神经网络架构 “FasterViT”,旨在提高计算机视觉领域的图像处理速度。
与常规的神经网络架构一样,FasterViT 结合了CNN在局部特征学习方面的优势和Transformer在全局建模能力方面的优势。此外,论文的亮点是引入了一种称为Hierarchical Attention, HAT的方法,将具有二次复杂度的全局自注意力机制分解为多级注意力,以降低计算成本。该方法利用了高效的基于窗口的自注意力机制,每个窗口都有专用的"carrier tokens",参与局部和全局特征学习。在高层级输出特征上,全局自注意力机制以较低的成本实现了窗口间的高效交流。
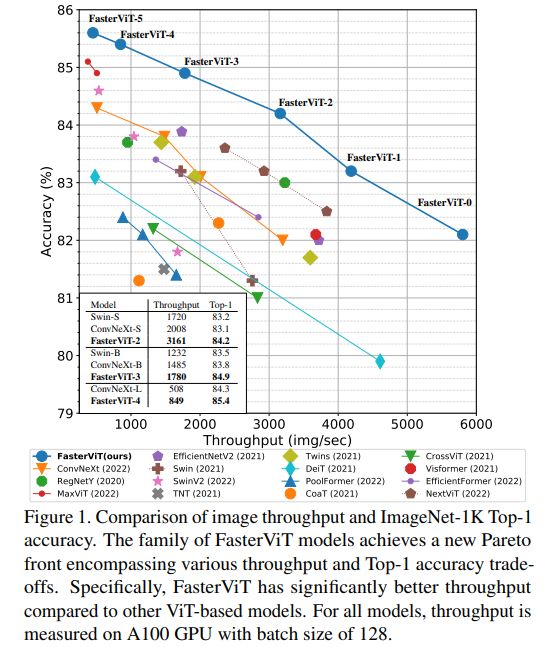
FasterViT在准确性与图像处理速度之间达到了最优的权衡点,并在图像分类、目标检测和语义分割等多个计算机视觉任务上得到了广泛验证。研究人员还展示了HAT可以作为现有网络的插件模块使用,并增强它们的性能。与竞争对手相比,FasterViT在高分辨率图像上表现出更快速和更准确的性能。
动机
FasterViT 提出的动机是解决 CV 领域中在处理高分辨率图像时所面临的效率问题。尽管 ViT 在各个任务上取得了优秀的性能,但其自注意力机制的计算复杂度对于高分辨率图像来说是很高的,导致处理速度较慢。此外,原始的 ViT 模型在学习特征表示时缺乏多尺度的能力,对于一些下游任务,如目标检测和语义分割,这种等向性结构并不适用。
FasterViT 的架构设计着重于在 CV 任务中实现最高的吞吐量,并针对主流的通用硬件进行优化,这些硬件在并行计算方面表现出色。该架构的计算涉及一组具有 CUDA 和 Tensor 核心作为计算单元的流式多处理器(SMs)。计算过程中需要频繁进行数据传输,而数据移动带宽可能会对计算产生影响。因此,受计算限制的操作是受数学计算限制的,而受内存传输限制的操作则是受内存限制的。需要在两者之间进行权衡,以最大化吞吐量,下面带大家具体分析下。
看多几个网络的小伙伴都了解,在一般的分层视觉模型中,随着深度的增加,中间表示的空间维度会缩小。初始网络层通常具有较大的空间维度和较少的通道(例如,112x112x64?),使它们受限于内存。这使得更适合于计算密集型操作,例如密集卷积,而不是对传输成本产生额外开销的深度可分卷积或稀疏卷积。此外,还存在一些无法用矩阵操作表示的 op,如非线性激活、池化和批归一化,也受限于内存,应尽量减少使用。相反,较后面的层通常受限于计算,需要进行计算密集型操作。例如,分层 CNN 的特征图大小为 14x14,具有高维度的卷积核。这为更具表现力的操作提供了空间,如层归一化、注意力机制等,对吞吐量影响相对较小。
方法
Framework
上面我们简要分析了一些动机,基于这些要点,本文提出了一种可以从加速计算硬件中获益的新颖架构,整体框架如图所示:
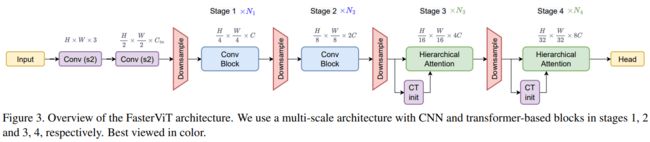
是不是很简洁?可以看出,该方法利用较早阶段的卷积层对更高分辨率的输入进行处理。模型的后半部分依赖于新颖的分层注意力层,在整个特征图上进行空间推理。在这个设计中,论文针对计算和吞吐量对架构进行了优化。因此,网络的前半部分和下采样块使用密集的卷积核。同时,在较高分辨率的阶段(即1、2阶段),避免使用挤压激励操作,并将层归一化最小化。而架构的后半部分(即3、4阶段)通常受限于计算,因为 GPU 硬件在计算方面花费的时间较多,与内存传输成本相比不成比例。因此,应用多头注意力机制不会成为瓶颈。
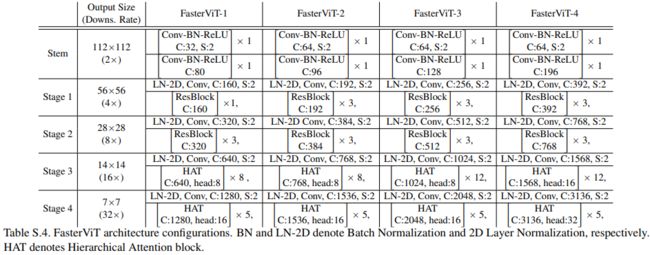
其实后面的网络设计思路都大差不差了。我们主要看下 HAT 的设计思路即可。
HAT
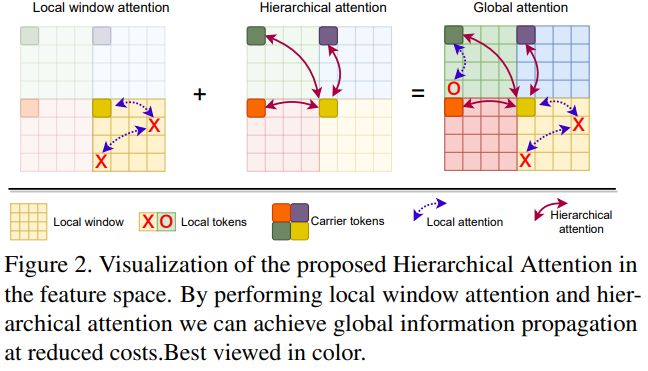
HAT 是一种新颖的窗口注意力机制。该模块旨在以较低的计算成本促进局部和全局信息的交换,其中引入了载体标记(CTs)的概念,并执行分层自注意力操作。
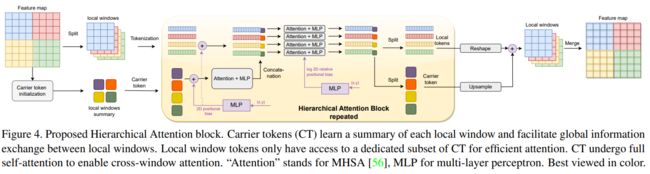
如上图所示,HAT 模块首先将输入特征图分割成局部窗口,类似于 Swin 的操作。每个局部窗口由一组标记表示。关键思想是引入 CTs,用于总结每个局部窗口内的信息。CTs 通过池化和卷积操作获得,它们提供了各自局部窗口的摘要信息。每个局部窗口都有独特的 CTs。
在 HAT 块中,CTs 经过多头自注意力(MHSA)操作,然后进行层归一化和多层感知机(MLP)操作。这个注意力过程允许 CTs 交换信息并总结全局特征。接下来,局部窗口标记和 CTs 进行拼接,并应用另一组注意力操作来建模它们之间的交互作用,从而实现短距离和长距离空间信息的交流。随后,标记再次被分割成各自的局部窗口和 CTs,并在该阶段的多个层上迭代应用这些操作。为了促进长程交互,最后在该阶段进行全局信息传播。输出结果通过对 CTs 进行上采样,并与局部窗口标记合并来计算。
为了融入位置信息,本文使用一个两层的 MLP 向 CTs 和局部窗口标记添加了绝对位置偏置。此外,还采用了 SwinV2 中提出的对数空间相对位置偏置,以增强具有图像样本局部性的注意力。总体而言,HAT 模块实现了局部窗口和全局特征之间的信息交换,有效的促进了整个特征图层次结构中的空间推理能力。
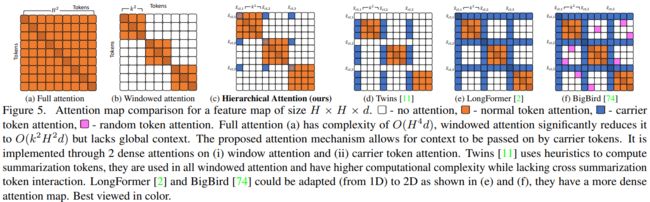
上图简单展示了高效的全局局部自注意力机制的注意力图比较。可以看出,所提出的分层注意力将自注意力分为局部和子全局部分,都可以压缩为两个密集的注意力操作。
实验
图像分类
:::block-1
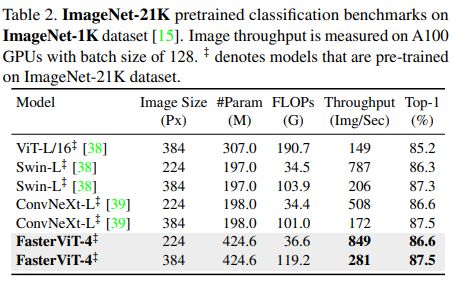
在ImageNet-1K数据集上,与各种混合、卷积和基于Transformer的网络相比,FasterViT模型在相同吞吐量下实现了更高的准确性。例如,与ConvNeXt-T相比,准确率提高了2.2%。考虑到准确性和吞吐量的权衡,FasterViT模型比基于Transformer的模型(如Swin Transformer系列)具有显著的速度优势。此外,与最近的EfficientFormer和MaxViT等混合模型相比,FasterViT在平均吞吐量上具有更高的性能,并且在ImageNet top-1性能方面表现更好。在模型优化方面,如TensorRT,FasterViT模型的延迟-准确性Pareto前沿趋势依然存在。
:::
目标检测
:::block-1
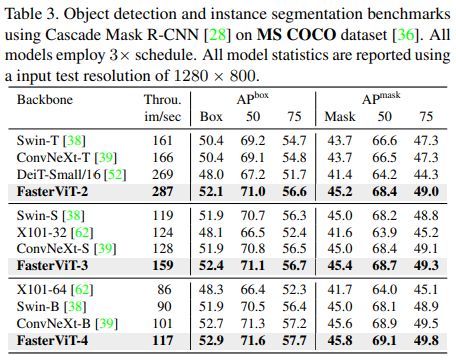
在MS COCO数据集上,使用Cascade Mask R-CNN网络进行目标检测和实例分割的性能评估中,FasterViT模型在准确性和吞吐量的权衡上表现更好。例如,FasterViT-4在盒子AP指标上优于ConvNeXt-B和Swin-B,分别提升了0.2和1.0,在掩膜AP指标上分别提升了0.3和1.0,同时吞吐量分别快了15%和30%。在其他模型变体中也观察到类似的趋势。此外,使用FasterViT-4作为ImageNet-21K预训练的骨干网络,与最先进的DINO模型进行额外的目标检测实验,达到了58.7的盒子AP,验证了FasterViT作为骨干网络与更复杂、最先进的模型的有效性。
:::
语义分割
:::block-1
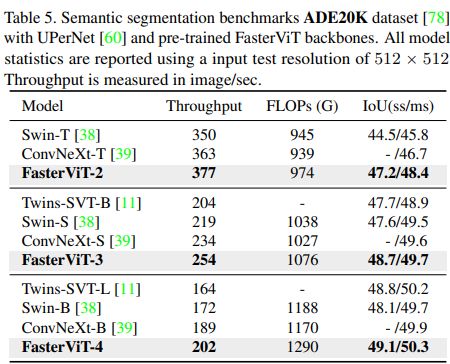
在 ADE20K 数据集上,使用 UPerNet 网络进行语义分割实验,FasterViT 模型也在性能和吞吐量的权衡上取得了良好的表现。例如,FasterViT-4 在 mIoU 指标上优于 Swin-B,单尺度和多尺度推理分别提高了1.0和0.7,并且吞吐量高出16.94%。与 ConvNeXt-B 相比,在多尺度推理方面,FasterViT-4的吞吐量照样提高了7.01%,mIoU提高了0.4。
:::
总结
FasterViT 被设计为一种混合网络结构,综合了 CNN 和 ViT 的优势,旨在实现高效的图像处理速度。同时,为了处理高分辨率图像,论文中引入了一种新的 HAT 模块,用于捕捉短距离和长距离的空间依赖关系,并有效地建模窗口间的交互。通过这些改进,本文模型能够很好的在图像处理速度和性能之间取得最佳平衡的解决方案。