Unity游戏优化(第2版)
1第1章 研究性能问题
确定所能支持的最大/最小性能指标,入允许的内存使用量、可接受的CPU消耗量、并发用户数量等,,确定目标受众,来确定运行游戏的硬件限制是什么,需要达到什么性能目标
附加知识:内存
U3D的Profiler中的GC ALLOC 项让人很麻烦,一直搞不清楚它是什么,因为 GC 是垃圾回收,而alloc是内存分配,那么 GC ALLOC 是 垃圾回收内存分配?
这个名字起的太TM烂了,其实这是U3D的不知哪个二货程序员起的,除了U3D中,其它任何文献中都没有这个名词。
GC_FOR_MALLOC 这是安卓中的名词,它表示 means that the GC was triggered because there wasn’t enough memory left on the heap to perform an allocation. Might be triggered when new objects are being created.,完全不是一个意思。
其实U3D的GC ALLOC就是 heap alloc,只要new了对象,就会有heap alloc
堆,英文是 heap,在内存管理的语境下,指的是动态分配内存的区域。这个堆跟数据结构里的堆不是一回事。这里的内存,被分配之后需要手工释放,否则,就会造成内存泄漏。
栈,英文是 stack,在内存管理的语境下,指的是函数调用过程中产生的本地变量和调用数据的区域。这个栈和数据结构里的栈高度相似,都满足“后进先出”(last-in-first-out 或 LIFO)。
从现代编程的角度来看,使用堆,或者说使用动态内存分配,是一件再自然不过的事情了。下面这样的代码,都会导致在堆上分配内存(并构造对象)。
// C++
auto ptr = new std::vector();
在堆上分配内存,有些语言可能使用new这样的关键字,有些语言则是在对象的构造时隐式分配,不需要特殊关键字。不管哪种情况,程序通常需要牵涉到三个可能的内存管理器的操作:
- 让内存管理器分配一个某个大小的内存块
- 让内存管理器释放一个之前分配的内存块
- 让内存管理器进行垃圾收集操作,寻找不再使用的内存块并予以释放
C++ 通常会做上面的操作 1 和 2。Java 会做上面的操作 1 和 3。而 Python 会做上面的操作 1、2、3。这是语言的特性和实现方式决定的。
注意在图 1e 的状态下,内存管理器是满足不了长度大于 4 的内存分配要求的;而在图 1f 的状态,则长度小于等于 7 的单个内存要求都可以得到满足。
当然,这只是一个简单的示意,只是为了让你能够对这个过程有一个大概的感性认识。在不考虑垃圾收集的情况下,内存需要手工释放;在此过程中,内存可能有碎片化的情况。比如,在图 1d 的情况下,虽然总共剩余内存为 6,但却满足不了长度大于 4 的内存分配要求。
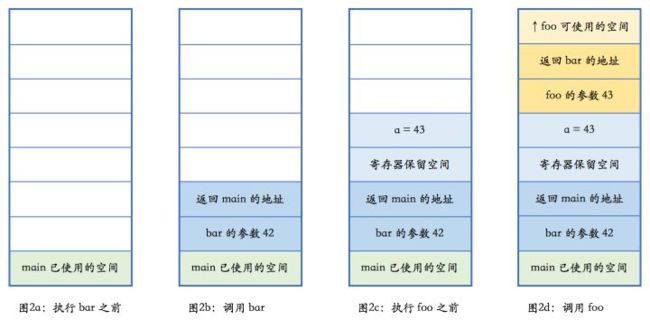
幸运的是,大部分软件开发人员都不需要担心这个问题。内存分配和释放的管理,是内存管理器的任务,一般情况下我们不需要介入。我们只需要正确地使用new和delete。每个new出来的对象都应该用delete来释放,就是这么简单。我们先来看一段示例代码,来说明 C++ 里函数调用、本地变量是如何使用栈的。当然,这一过程取决于计算机的实际架构,具体细节可能有所不同,但原理上都是相通的,都会使用一个后进先出的结构。
void foo(int n) { … }
void bar(int n) { int a = n + 1; foo(a); }
int main() { … bar(42); …}
在我们的示例中,栈是向上增长的。在包括 x86 在内的大部分计算机体系架构中,栈的增长方向是低地址,因而上方意味着低地址。任何一个函数,根据架构的约定,只能使用进入函数时栈指针向上部分的栈空间。当函数调用另外一个函数时,会把参数也压入栈里(我们此处忽略使用寄存器传递参数的情况),然后把下一行汇编指令的地址压入栈,并跳转到新的函数。
新的函数进入后,首先做一些必须的保存工作,然后会调整栈指针,分配出本地变量所需的空间,随后执行函数中的代码,并在执行完毕之后,根据调用者压入栈的地址,返回到调用者未执行的代码中继续执行。
注意到了没有,本地变量所需的内存就在栈上,跟函数执行所需的其他数据在一起。当函数执行完成之后,这些内存也就自然而然释放掉了。我们可以看到:
- 栈上的分配极为简单,移动一下栈指针而已。
- 栈上的释放也极为简单,函数执行结束时移动一下栈指针即可。
- 由于后进先出的执行过程,不可能出现内存碎片。


1.1 Unity Profiler
在比较大的项目中,启用Profiler时,有时会导致严重不一致的行为。可以通过Profiler查看性能分析
通常快速体验一遍程序运行,感觉性能变差时持续关注一段时间,并进行进一步分析,,,这叫做基准分析,,感兴趣的重要指标时渲染帧率、总体内存消耗和CPU活动的行为方式(寻找活动中较大的峰值)、CPU/GPU的温度,不应该接受通过Editor模式生成的基准数据作为真正游戏时的数据,因为Editor会带来额外的开销。应该在应用程序以独立格式在目标硬件上运行时,将分析工具挂接到应用程序中。
1.1.1 启动Profiler
编辑器或独立运行的实例
- 编辑器在Editor的Play状态下可以直接运行Profiler
- Build Settings打开Development Build(开启后,发布的程序右下角会标识Development Build)和Autoconnect Profiler的话,发布的程序包运行在电脑上会自动连接开启的Unity的Profiler进行性能分析


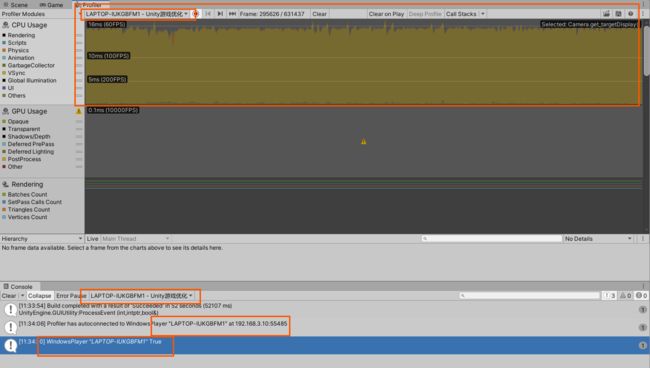
其他连接到笔记本的设备或者通过远程方式,都可以使用这个方法进行性能分析,,远程需要输入IP
1.1.2 Profiler窗口
普通的分析只记录常见的Unity回调方法(如Awake、Start、Update、FixedUpdate)所返回的事件和内存分配信息。启用Deep Profile选项可以用更深层次的指令重新编译脚本,允许它统计每个调用的方法。这导致需要使用大量的内存,因为在运行时收集的是整个调用堆栈的数据,因此大型项目中,使用Deep Profiler甚至是不可能的。
注意:切换Deep Profiler需要完全重新编译整个项目,才能再次开始分析,因此最好避免在测试中来回切换该选项
- CPU使用区域:Raw Hierarchy和Hierarchy很像,但前者把Unity函数调用隔离到单独的条目中,细分试图更难阅读,对于统计某个全局方法调用了多少次,第一个Raw更有用,,,,最有用的模式是Timeline,可以将细分视图垂直组织到不同的部分,代表运行时的不同线程,例如主线程、渲染线程额各种后台线程等,称为Unity Job system(简称job),垂直代表调用栈,更深的链表示在那个栈上有更多的调用,水平轴表示时间,消耗CPU时间越多方块越长。
 顶部的方块是由Unity引擎在运行时调用的函数(技术上说是回调)例如Start、Awake、Update,而下面的方块是那些函数里面调用的函数,可以是其他组件上的函数或常规C#对象
顶部的方块是由Unity引擎在运行时调用的函数(技术上说是回调)例如Start、Awake、Update,而下面的方块是那些函数里面调用的函数,可以是其他组件上的函数或常规C#对象 - GPU使用区域:相关的Unity方法调用和摄像机、绘制、不透明和透明的集合图形、光照、阴影等
- 渲染区域:诸如SetPass调用的数量(也称Draw Call)、渲染到场景的批次总数、通过动态批处理和静态批处理节省的批次数量和他们的生成方式、以及纹理的内存消耗。
- 内存区域:Simple模式只提供子系统内存消耗的高层次概览:包括Unity底层引擎、Mono框架(由垃圾回收管理的整个堆的大小)、图形资源、音频资源、缓冲区、甚至用于保存Profiler收集的数据的内存;Detailed模式显示每个GameObjects和MonoBehaviors为其Native和Managed表示所消耗的内存
- 音频区域:估量音频系统的CPU消耗、以及(所有播放中或暂停的)音频和音频剪辑的总内存消耗
- Physics 3D和Physics 2D,提供不同的物理统计数据,例如Rigidbody、Collider和Contact计数
- 网络消息和网络操作区域:
- 视频区域:
- UI和UI详情区域,,,,使用NGUI,这个区域可能就没什么用了、
- 全局光照区域:全局光照Global Illumination,GI,如果使用了GI,可以参考这个区域远征程序是否正常执行
1.2 性能分析的最佳方法
- 验证目标脚本是否出现在场景中,在Hierarchy的文本框中输入t:
- 验证脚本在场景中出现的次数是否正确
- 验证事件的正确顺序:不能调用相同类型事件的顺序进行细粒度控制。例如加载一个新场景时,都会调用Awake但是无法确定顺序。。。代码库和编译过程中存在随机变化会导致Awake调用的顺序发生变化,其他回调也是如此。。。后期处理初始化最好放在Start回调,,,因为总是在每个对象的Awake之后,第一个Update之前,,,后期更新也可以在LateUpdate回调中完成,,,协程的触发取决于yield类,最难调试/最不可预测的类型时WaitForSeconds yield类型,协程启动和结束中间调用的Update回调数量是可变的
- 最小化正在进行的代码进行更改
- 尽量减少内部干扰:一帧需要很长时间处理,Profiler可能无法获取结果,,当前窗口如果是Profiler,gameObject检测按键操作会失效,因为窗口不是game,,,垂直同步会匹配将应用帧率匹配显示设备帧率,让游戏等待,知道渲染输出的帧为止,减少画面撕裂,VSync的启用会导致Profiler在WaitForTargetFPS的CPU使用情况产生峰值,因为应用程序故意降低速率匹配显示器帧率,编辑器模式峰值更大,因为画面之渲染到一个窗口不需要很多CPU/GPU来工作,,,debug.Log等方法也会产生很大CPU使用率和堆内存消耗,会导致发生垃圾回收,甚至丢失CPU循环,,,
- 尽量减少外部干扰:外部内存占用等,后台等
- 代码片段的针对性分析:1、使用Profiler脚本控制。使用UnityEngine.Profiling命名空间的BeginSample()和EndSample()访问 ,可以在Profiler窗口中查看到开始采样的数据;;;;2、自定义CPU分析
void Update()
{
transform.GetChild(0).transform.Rotate(Vector3.up, 0.05f);
DoSomethingCompletelyStupid();
}
//循环100w添加到list,然后无操作
void DoSomethingCompletelyStupid()
{
Profiler.BeginSample("My Profiler Sample");
List<int> lt = new List<int>();
for (int i = 0; i < 1000000; i++)
{
lt.Add(i);
}
Profiler.EndSample();
}
开始采样
结束采样
1.3 关于分析的思考
- 理解Profiler工具,,窗口内显示的图形的相对性质,不一定高峰值就有问题
- 减少干扰
- 关注问题
第2章 脚本策略
附加知识:using块
作为语句
①用于定义一个范围,在此范围的末尾将释放对象。
using (FileStream fileStream = new FileStream(FilePath + @"\" + files[i].Name, FileMode.Create, FileAccess.Write))
{
//做一些操作
fileStream.Write(bytes, 0, bytes.Length);
}//关闭fileStream
(1)作用
在Using关键字后的括号内实例一些类,然后在下方的方法体内就可以直接调用实例好的类,这些类在Using外部是无法调用的,并且在Using方法体的执行完毕后,该类会被自动释放掉,注意,这个实例的类必须继承IDisposable接口,不然无法编译,释放的时候会自动调用类重写的Dispose方法。
(2)简单示例
首先创建一个继承自IDisposable接口的类,并添加一个开放的函数
using可以多引用,,括号里面实例多个类
public class Test1 : IDisposable {
public void PrintData(string str)
{
Debug.Log("--------------:"+str);
}
public void Dispose()
{
Debug.Log("释放Test1");
}
}
public class TestSave : MonoBehaviour {
void Start () {
using (Test1 test1 = new Test1())
{
test1.PrintData("This is a test1");
}
print("Using语句结束");
}
}

2.1 使用最快的方法获取组件

GetComponent()方法最快
2.2 移除空的回调定义
四个最常用的回调Awake(),Start(),Update(),FixedUpdate(),包括其他回调OnGUI等,,MonoBehavior在场景中的第一次实例化时,Unity会将任何定义好的回调添加到一个函数指针列表中,,,,即使函数体是空的,Unity也会挂接到这些回调中,而Unity没有办法意识到这些函数体可能是空的,它只知道方法已经定义,执行空的回调将浪费少量CPU
可以通过正则表达式regex查找回调是否为空
下图挂载30000个组件有无Update的测试结果

2.3 缓存组件引用
反复计算一个值时常见的错误,特别是使用GetComponent时,,最好不要把GetComponent赋值放到函数体中,最好在Awake中获取,,这样可以缓存组件引用,不用再每次需要的时候都重新获取,可以节省CPU开销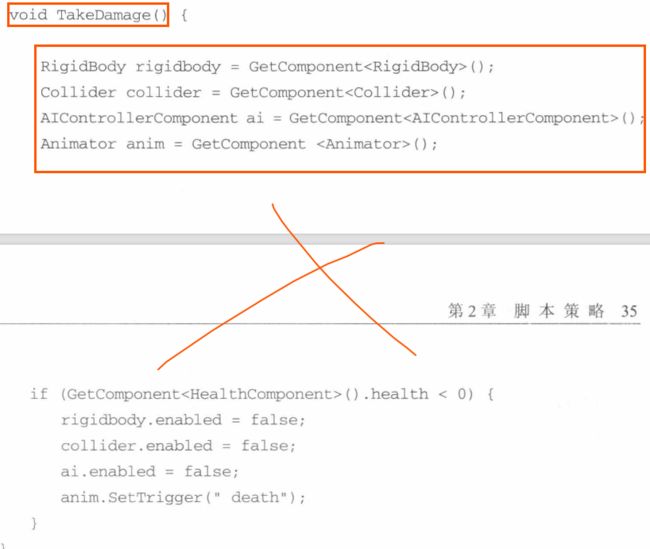
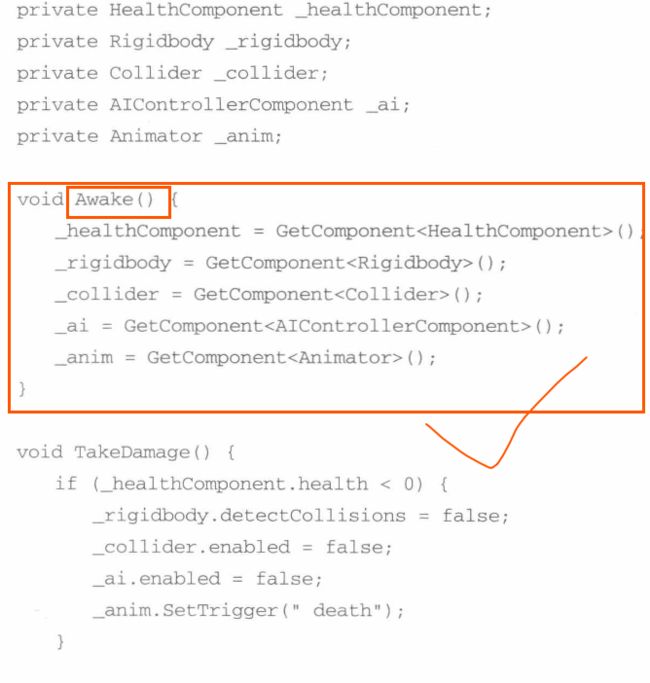
2.4 共享计算输出
如果相同的计算结果,并且计算过程昂贵复杂,,,多个位置都调用了它,那么重构代码例如从字典或文件中读取数据分发给需要的对象,就比较明智
2.5 Update、Coroutines和Invoke Repeating
- Update中以超出需要的频率重复调用某段代码,ProcessAI()可能极为复杂,,减少运行次数
void Update()
{
ProcessAI();
}
//修改为:
private float _aiProcessDelay = 0.2f;
private float _timer = 0.0f;
void Update()
{
//通过计时器降低频率
_timer += Time.deltaTime;
if(_timer > _aiProcessDelay)
{
ProcessAI();
_timer -= _aiProcessDelay;
}
}
//修改为协程
void Start()
{
StartCoroutine(ProcessAICoroutine);
}
IEnumerator ProcessAICoroutine()
{
while(true)
{
ProcessAI();
yield return new WairForSeconds(_aiProcessDelay);
}
}
- 修改为协程:1、开启协程增加额外开销。2、协程独立于Update回调的触发,不要再协程中执行大量的GameObject的构建与析构。3、协程包含的GameObject会在不活动时停止,再次设置为活动时,也不会自动启动。4、方法转换为协程,可减少大部分帧中的性能损失,但如果方法体的单次调用已经超过了帧率预算,无论调用次数怎么减少,都将超过帧率预算。。。最好是因为调用次数太多而超出帧率预算,而不是因为方法本身太昂贵
- 协程归结为while循环,并且再WaitForSeconds(Realtime)上调用yield,可以替换为InvokeRepeating,开销小,,,InvokeRepeating独立于MonoBehavior和GameObject的状态,需要用CancelInvoke或者销毁MonoBehavior或GameObject,,,禁用不会停止
void Start()
{
InvokeRepeating("ProcessingAI", 0f, _aiProcessDelay);
}
2.6 更快的GameObject空引用检查
GameObject执行空引用检查会导致一些不必要的性能开销。因为MonoBehavior和GameObject存储的内存空间的移动会产生开销(跨越本机-托管的桥接),许多微妙的方式都会触发这种额外的开销(开销很小,但是如果大量进行空引用检查,还是不妥)
if (gameObject != null)
DoSomething();
//修改为
if (!System.Object.ReferenceEquals(gameObject, null))
DoSomething();
2.7 避免从GameObject取出字符串属性
GameObject中检索字符串属性例如name和tag也会产生跨越本机-托管的桥接,,,,也会产生开销
tag属性最常用与比较,使用CompareTag()可以避免上述问题
if(listOfObject[i].tag == "Player")
{}
//修改为
if(gameOjbect.CompareTag("Player"))
{}

GC.Collect是垃圾回收,清理无用的内存,,,,使用tag循环100w次,内存大了400mb,使用了1892ms,回收内存都花费了449ms,,,,,,compareTag就明显时间短并且没有垃圾回收的时间
2.8 使用合适的数据结构
遍历对象用list,,,,两个对象相互关联用Dictionary,,,, 需要同时处理两种情况:快速找出那个对象映射到另一个对象,同时还能遍历组。最好在列表和字典中存储数据,虽然需要额外的内存,维护多个数据结构。但迭代列表的好处和迭代字典形成鲜明对比。
2.9 避免运行时修改Transform的父节点
unity会把同父元素的transform根据顺序存储再预先分配的内存缓冲区中,便于迭代,,,但是如果重新指定了父物体,如果与分配的内存空间不够容纳鑫子对象,就需要扩展缓冲区,这会导致开销,尽量避免。
- instantiate时,最好直接传入父物体的transform避免默认父物体开辟缓冲区后再丢弃更改分配的缓冲区重新分配到新的内存缓冲区
- 预定义更大的缓冲区以避拓展缓冲区,,预估子物体数量后,通过Transform组件的hierarchyCapacity属性实现更大的缓冲区。

2.10 注意缓存Transform的变化
transform组件只存储与父组件相关的数据,如果是绝对坐标的position、rotation等的修改就会导致大量未预料到的矩阵乘法计算,,因此使用localPosition、localRotation等成本较小。当然将数学计算从世界空间更改为本地空间,会把问题变复杂,因此牺牲一点性能也是值得的。,,不断更改Transform组件的属性也会向Collider等组件发送通知,通知组件进行处理。
FixedUpdate在Update之前执行,因此可以在Update中的函数使用成员变量记录要修改的transform属性,让FixedUpdate在下一帧开始前通过成员变量修改ransform,从而保证在这一帧物理和渲染系统与当前Transform状态保持同步
附加:静态类学习
1、静态类不能继承和被继承!(严格点说是只能继承System.Object)也就是说你的静态类不可能去继承MonoBehaviour,不能实现接口。
2、静态方法不能使用非静态成员!如果你大量使用静态方法,而方法里又需要用到这个类的成员,那么你的成员得是静态成员。
第2点需要注意:如果你想在Unity的编辑器下调整某个参数,那么这个参数就不能是静态的(哪怕你自定义EditorWindow去修改这个值也没用),解决的办法是通过UnityEngine.ScriptableObject去存放配置(生成*.asset文件),然后在运行中通过LoadAsset去加载,然后再改变静态成员。至于原因,相信不难理解——你看到的所有Unity组件都是一个个实例,你要通过Unity的编辑器去配置,那么你就得有一个这样的可配置实例。
从面向对象上想一下:静态方法或者静态类,不需要依赖对象,类是唯一的;单例的静态实例,一般就是唯一的一个对象(当然也可以有多个)。差别嘛。。。好像也不大。。。
附加:God Class

2.11 避免在运行时使用Find()和SendMessage()方法
场景初始化阶段调用Find可以接受,例如Start和Awake回调期间,,,但是场景变大之后,开销非常大,,SendMessage开销也很大
一、功能:用于向某个GameObject发送一条信息,让它完成特定功能。
1、执行GameObject自身的Script中“函数名”的函数
**SendMessage (“函数名”,参数,SendMessageOptions) **
2、执行自身和子节点GamgeObject的Script中“函数名”的函数
BroadcastMessage (“函数名”,参数,SendMessageOptions)
3、自身和父节点GamgeObject的Script中“函数名”的函数
SendMessageUpwards (“函数名”,参数,SendMessageOptions)
可以用GetComponent函数来低成本替换SendMessage,见书P68
2.11.1 将引用分配给预先存在的对象
使用[SerializeField]让private属性在Inspector表现为一个公共字段用来提前赋值,但安全的封装在代码库中

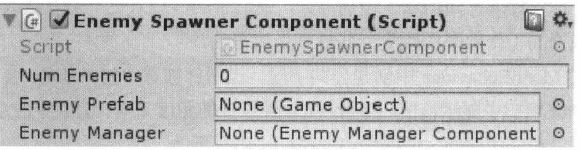
_enemyManager字段是一个特定的MonoBehavior类类型的引用,如果拖拽包含了该类类型的GameObject放到字段上,将引用给定对象上的组件,而不是引用GameObject本身(赋值脚本)
unity可以序列基本类型int等和内置类型Vector3等,记忆枚举、类、结构和包含其他可序列化类型的数据结构如list,,,但是静态字段、只读字段、属性、字典不能序列化
2.11.2 静态类
定义整个代码库全局可访问的类
单例模式对于管理共享资源或繁重的数据流量(如文件访问、下载、数据解析和消息传递)非常有用
静态类每个方法、属性、字段都附加static和public

因为StaticEnemyManager是静态类,所以无法调用非静态的类型,因此Unity的Inspector无法赋值,所以需要一个伙伴组件用来序列化一个private变量手动复制后,通过函数把这个变量引用传给静态类
2.11.3 单例组件
静态类很难和Unity相关的功能交互,不能直接利用MonoBehavior的特性,如事件回调、协程、分层设计和预制块等,在Inspector窗口中没有选择的对象,无法在运行时通过Inspector窗口检查静态类的数据,,,,单例可以实现。。。。
不确定Singleton实例对象是否是最后销毁的,因此如果在OnDestroy回调使用单例组件执行操作,可能使已销毁的Singleton再次创建实例,导致波坏场景文件,因为实例留在了场景中**,不要再OnDestroy中调用单例组件**
使用Observer设计模式,对象在创建时通常会注册到系统,在运行时使用它,然后再使用结束时从系统注销,或者为了清理而在关机时注销,,,单例组件的初始化不应发生在场景初始化期间,,第一次获取实例调用Find会由性能峰值。最好使用God类简单的访问每个单例对象的instance属性,来确保场景初始化期间重要单例对象的实例化
2.11.4 全局消息传递系统
消息发送者可以广播消息而不关心正在听的人,侦听器的职责是确定他们感兴趣的消息,,,,,在程序变复杂时保持对象通信的模块化、解耦和快速。
- 信息系统应该可以全局访问,吗,,单例模式
- 任何对象都能注册/注销为侦听器(Observer设计模式)
- 广播给定的消息时,注册对象应该提供一个调用方法。编写interface接口包含一个EndNotify函数,所有敌人继承接口,并重写EndNotify函数,所有敌人注册到manager中作为Observer,当player死亡时,执行NotifyObserver函数,遍历执行每一个Observer的EndNotify函数
- 合适的时间范围内将消息发送给侦听器,但不要同时处理太多请求。
2.12 禁用未使用的脚本和对象
第一人称和赛车游戏,,,视野之外或者太远而显得不重要的东西,因为玩家活动在开阔的区域,而非可视对象可以临时禁用,而不会产生任何影响
2.12.1 通过可见性禁用对象
Unity自带内置的渲染功能,视锥剔除
使用OnBecameVisible和OnBecameInvisible()回调,必须附加一个可渲染的组件MeshRenderer必须保证接受可见性回调的组件和渲染对象连接在一个GameObject上
2.12.2 通过距离禁用对象
距离玩家足够远,以至于看不见或者并不关注,可以关闭
2.13 使用距离平方而不是距离
CPU擅长浮点数相乘,不擅长计算平方根,,可能会损失一些使用平方根值的精度,但是性能收益可观,如果不是非常高精度的场景,都可以使用
sqrMagnitude替换Distance
2.14 最小化反序列化行为
Unity序列化系统主要应用于场景、预制体、ScriptableObjects和各种资产类型,当其中一种对象类型保存到磁盘是,就用YAML格式转换为文本文件,稍后可以反序列化为原始对象类型
反序列化活动都伴随着显著的性能成本,反序列化在调用Resources.load时发生,用于在Resources文件中查找路径,一旦数据从磁盘加载到内存,后续重新加载相同引用会快很多,但是第一次总需要磁盘活动
层次越深,需要反序列化的数据越多,,UI预制块尤其是个问题
场景开始时加载会造成CPU峰值和加载时间,,,如果在运行时加载他们,可能会掉帧
2.14.1 减小序列化对象
UI预制块很适合分割,通常不需要整个UI可以一次加载一个
2.14.2 异步加载序列化对象
Resources.LoadAsync()以异步方式加载预制块和其他序列化内从,吧磁盘读取的任务转移到工作线程上,从而减轻主线程的负担,,通过检查这个方法调用返回的ResourceRequest对象的isDone属性判断是否完成序列化对象加载
2.14.3 在内存中保存之前加载的序列化对象
序列化对象加载到内存中,会保存在内存中,需要显示调用Resources.Unload释放内存,,,如果内存预算很大,可以保存在内存中,将减少磁盘读取
2.14.4 将公共数据移入ScriptableObject
游戏设计值,如命中率、力量、速度等这些公共数据序列化到ScriptableObject中加载,,,及那个减少储存在预制文件中的序列化数据量,并可以避免过多的重复工作,显著减少加载时间
2.15 叠加、异步地加载场景
如果让玩家尽快进行后续操作,或没有时间等待场景对象出现,最好使用同步加载模式(主线程将阻塞,知道场景加载完成),如果在游戏第一关加载或者返回主菜单,通常使用同步加载
异步加载模式让场景逐渐加载到背景中,而不会对用户体验造成明显的影响,,,SceneManager.LoadSceneAsync()并传递LoadSceneMode.Additive以加载模式参数
场景不遵循游戏关卡的概念,比如第一个场景1-1a在玩家接近下一个章节时,异步并叠加式加载下一个场景1-1b,通过系统检测玩家在关卡中的位置,广播“玩家即将进入下一个章节”,并开始异步加载,需要确保出发场景的异步加载有足够的时间,以便玩家不会看到对象弹出到游戏中
2.16 创建自定义的Update()层
成千上万的MonoBehanvior在长久那个开始时一起初始化,每个都启用协程,既有可能在同一帧触发,导致一段时间内出现一个巨大的峰值,希望时间分散调用
- 每次计时器过期或者协程触发、生成一个随即等待时间、
- 将协程的初始化分散到每个帧中,这样每个帧值启动少量的协程
- 将调用更新的职责传递给某个God类,对每帧的调用数进行限制
最好的方法是不使用Update

第3章 批处理的优势
批处理:将大量任意数据块组合在一起并将他们作为单个大数据块进行处理的过程。。这对于CPU非常理想,因为可以使用多个内核同时处理多个任务,在内存中的不同位置来回切换内核是需要时间的,因此切换内核所花的时间越少越好。
Unity中的批处理,通常指的是两种用于批处理网格数据的主要机制:动态和静态批处理。。。本质上是集合体合并的两种不同形式,用于多个对象的网格数据合并到一起,并在单一指令中渲染他们,而不是单独准备和绘制每个几何体。
将多个网格批处理为单个网格是可以实现的,,,因为没有规定网格对象必须是3D空间中连续的几何体,Rendering Pipeline可以接受一系列没有共同边的顶点
3.1 Draw Call
Draw Call只是一个从CPU发送到GPU中用于绘制对象的请求。Unity也称为SetPass Call,可以将Draw Call理解为初始化当前渲染过程之前的配置选项
请求Draw Call之前,需要一下工作:
- 网格和纹理数据必须从CPU内存(RAM)推送到GPU(VRAM)中,场景初始化期间完成,仅限于场景文件知道的纹理和网格,,,非场景中的纹理和网格数据在云夕能使动态实例化对象时完成加载
- CPU必须配置处理对象(这些对象就是Draw Call的目标)所需的选项和渲染特性,为CPU做好准备
渲染对象前,必须为准备管线渲染而配置的大量设置常常统称为渲染状态(Render State)


3.2 材质和着色器
渲染状态本质上是通过材质呈现给开发者的。材质是着色器的容器,着色器是一种用于定义CPU应该如何渲染输入的顶点和纹理数据的简单程序。着色器需要注入漫反射纹理、法线映射和光照信息之类的输入,并有效地规定为了呈现传入地数据需要设置那些渲染状态变量。每个着色器都需要一个材质,每个材质都必须有一个着色器。。。新导入场景地网格,如果没有赋予材质,会被自动赋予默认材质,提供基本的漫反射着色器和白色色彩。
最小化渲染状态修改地频率:减少场景中使用的材质数量(CPU每帧花费更少时间生成指令传给GPU,GPU不需要经常停止重新同步状态的变更)
详见P86,修改了8个物体的材质为一个材质Batches,但依然是9个Batches(一个用来渲染背景),因为渲染管线不够智能,无法意识到在重复写入完全相同的渲染状态
3.3 Frame Debugger
Window-Analysis-Frame Debugger,,,左边列出了所有的Draw Call行为,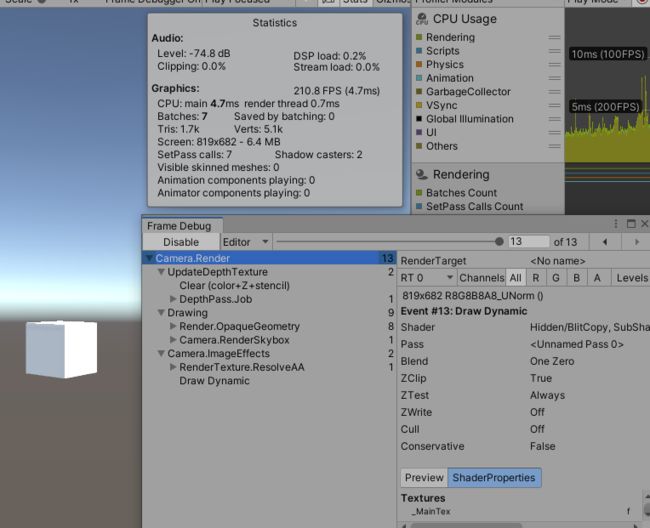
 绘制阴影,Clear清除屏幕,在一个job的Draw Call中绘制网格,Draw Call绘制天空盒,,,左边面板每一项后面的数字表示一个Graphics API调用,Draw Call只是一种API调用,调用API和Draw Dall的开销差不多,但复杂场景中大多数的API都采用Draw Call的形式,因此最好先关注Draw Call的最小化,再去担心注入后处理效果等API通信开销。
绘制阴影,Clear清除屏幕,在一个job的Draw Call中绘制网格,Draw Call绘制天空盒,,,左边面板每一项后面的数字表示一个Graphics API调用,Draw Call只是一种API调用,调用API和Draw Dall的开销差不多,但复杂场景中大多数的API都采用Draw Call的形式,因此最好先关注Draw Call的最小化,再去担心注入后处理效果等API通信开销。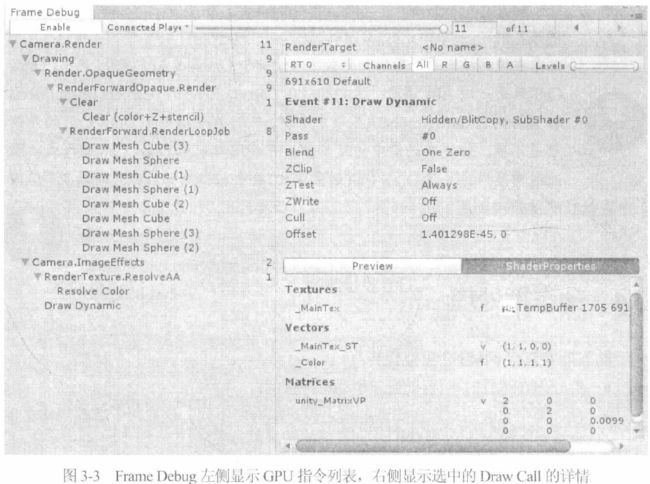
3.4 动态批处理
动态批处理优势:
- 批处理在运行时生成(批处理是动态产生的)
- 批处理中包含的对象在不同的帧之间可能有所不同,取决于哪些网格在主摄像机视图当中是可见的(批处理的内容是动态的)
- 甚至能在场景中运动的对象也是可以批处理(对动态对象有效)
Player Settings 开启Dynamic Batching
4个立方体合并到一个名为Dynamic Batch的Draw Call中
3.4.1 顶点属性
Unity查看顶点需要到MeshFilter组件,在Inspector窗口的Preview区域查看verts值
300个顶点的网格,最多对应3个顶点属性(位置、发现、一组UV坐标)即便少于3个属性,也最多300顶点,组成900属性数
方块8个顶点,共24个属性,,,球515个顶点共1545个属性,因此动态批处理只能节省3个Draw Call,查看没有加入到Dynamic Batch的项,会有Why this draw call can’t be batched with the previous one
3.4.2 网格缩放
对象应用统一的等比缩放,或每个对象都有不一样的非等比缩放,才能包含到动态批处理中。等比缩放意味着向量的3个分量都相同(不同的网格不需要买组这个条件),非等比缩放意味着3个分量中最少有一个和其他是不同的
分量3个值中负数值的奇数或偶数相关,0个轴/2个轴负数缩放一个批处理,,1个轴/3个轴负数缩放一个批处理,,尽量减少是否负数缩放
3.4.3 动态批处理总结
应用动态批处理的可能情况如下:
如果组织两个对象动态批处理的唯一条件是:他们使用了不同的纹理,就应该花点时间和精力合并纹理(通常称为图集),重新生成UV,以便进行动态批处理。牺牲了纹理质量或纹理文件变大,也是值得的
3.5 静态批处理
静态批处理取,只处理标记为Static的对象
3.5.1 Static标记

使用该标记才能使用静态批处理,但是不能修改对象的变换,因此,任何想要使用静态批处理的对象不能通过任何方式移动、旋转、缩放。
3.5.2 内存需求
静态批处理在工作时,将所有标记为Static的可见网格数据复制到一个更大的网格数据缓冲中,并通过一个Draw Call传到管线渲染中,并忽略原始网格,如果所有进行静态批处理的网格都不相同,那么与正常渲染对象相比,不会增加内存使用量,因为存储网格需要的内存空间量是一样的,,,,,如果渲染1000个相同的对象,消耗的内存是不使用静态批处理渲染相同树的1000倍(相同的网格重复复制到缓冲区)
3.5.3 材质引用
使用不同材质的网格会划分到各自的静态批处理中,,,缺点:静态批处理渲染所有静态网格时,使用Draw Call数量最多只能等于所需的材质数量。
3.5.4 静态批处理的警告
- Draw Call减少了,但不能直接在Stats中看到,要在运行时才能看到
- 运行时场景中引入标记为Batching Static的对象,不能自动包含进静态批处理中,因为在重新计算网格和与渲染管线同步之间造成巨大的运行时开销,Unity不愿意尝试自动执行


大多数情况下,应该尝试让任何期望被静态批处理的网格出现在场景的原始文件中。如果需要动态实例化、或者使用叠加方式加载场景,就可以使用StaticBatchUtility.Combine()方法控制批处理,这个函数不会将给定的网格与预先存在的任何批处理组合并在一起,即使拥有相同材质,无法通过实例化或叠加加载的静态网格来减少Draw调
静态批处理的显著优势:用于不同形状和巨大尺寸的网格
第4章 着手处理艺术资源
艺术资产质量和运行速度的平衡
4.1 音频
运行时音频处理会称为CPU和内存消耗的重要来源,产生音频瓶颈的缘由多种多样。过度压缩、过多的音频操作、过多的活动音频组件、低效的内存存储方法和访问速度都是导致内存和CPU性能低下的原因。
4.1.1 导入音频文件
导入设置包括加载行为、压缩行为、质量、采样率,以及是否支持双声道音频
4.1.2 加载音频文件
一下三种设置可以指定音频文件的加载方式,3种方式有很大的不同
- Preload Audio Data,决定音频数据是在场景初始化期间自动加载,还是以后加载
- Load In Background,确定此活动是在完成之前阻塞主线程,还是在后台异步加载
- Load Type,,定义了讲什么类型的数据拉入内存,以及一次拉入多少数据
音频文件的典型用例:分配给AuidoSource对象的audioClip属性,该对象将音频文件包装在AudioClip对象中,通过AudioSource.Play()或AudioSource.PlayOneShot()触发播放,以这种方式分配的每个音频剪辑都将在场景初始化期间加载到内存种,因为场景包含对这些文件的即使引用,需要这些文件之前必须先解析这些引用。这事Preload Audio Data的默认情况。如果禁用Preload Audio Data就会再场景初始化期间跳过音频文件加载,从而加快场景加载,当Play时, 阻塞主线程,访问磁盘,检索文件,加载到内存,解压缩播放
禁用Preload Audio Data后,应使用Load In Background选项,让音频加载更改为异步任务,在线程中完成加载之前,文件还没准备好用于播放,需要加载到内存。因此Play()和音频播放会有延时。通常在不涉及操作的电梯或长走廊加载或卸载音频
Load Type包含三种选择:Decompress On Load压缩磁盘上的文件,再首次加载时解压缩到内存,这是标准方法,解压缩会导致加载过程中的额外开销,但会减少播放音频文件时所需的工作量;Compressed In Memory加载时直接将音频从磁盘复制到内存种,再播放音频时,才解压缩,播放时牺牲CPU但是音频休眠时提高加载速度,减少运行内存消耗,适合大型音频文件或内存消耗上遇到瓶颈愿意牺牲CPU周期;Streaming在运行时加载、解码和播放文件,具体做法是将文件推过一个小缓冲区,一次只缓存整个文件的一小部分数据,对特定音频剪辑使用的内存量最小,但是运行时CPU使用的内存量最大。定期播放的单实例音频剪辑,不能与自己或其他流式音频剪辑重叠,例如该设置与环境音乐背景音效一起使用。
4.1.3 编码格式与品质级别
Inspector中查看音频剪辑的属性,有Compressed Format选项决定三种格式:Compressed(取决于目标平台)、PCM(无损未压缩,适用于极短暂且需要高清晰度的音效)、ADPCM(大小与CPU消耗比PCM高效多,但是压缩会产生相当大的噪声,用做爆炸、碰撞、冲击会掩盖噪声),,,,音频的节省值根据目标平台而不同。
ADPCM
4.1.4 音频性能增强
- 最小化活动音频数量。通过中介发送音频播放请求,使用中介控制音频实例化数量。
- 为3D声音启用强制为单声道。Force to Mono,文件的总磁盘和内存空间使用量有效地降低了50%,一般不要给二维音效使用(通常用于创建特定的音频体验),两个通道相同的音频剪辑上可以启用,因为这样的立体声没有意义。
- 重新采样到低频。对于大多数情况下,采样率低可以减少文件大小。
- 考虑所有的压缩格式。
- 注意流媒体。磁盘流式传输文件应该仅限于大型的单实例文件。
- 通过混音器组应用过滤效果以减少重复。Audio Mixer
- 谨慎地使用远程内容流。WWW类或UnityWebRequest类,丢弃引用后需要手动释放内存。
- 考虑用于背景音乐地音频模块(Audio Module)文件,音轨(音频)模块可以节省大量空间,且没有任何明显质量损失
4.2 纹理文件
纹理是简单的图像文件、一个颜色数据的大列表,已告知插值程序,图像的每个像素应该是什么颜色
精灵是网格的2D等价物
运行时,这些文件加载进内存推送到GPU的显存,并在给定的DrawCall期间,由着色器渲染到目标精灵或网格上
4.2.1 纹理压缩格式
通道总位数越多消耗越大,例如α通道
4.2.2 纹理性能增强
- 减小纹理文件的大小,纹理越大,推送纹理消耗的GPU内存宽带就越多
- 谨慎使用Mip Map,对于某些不重要的小细节,例如小石头等,纹理不重要,可以通过Mip Map获取不同分辨率的纹理,尽管图像大了,但是会根据相机距离,选择纹理Mip Map级别,,,,距离不变的纹理不要使用Mip Map,请直接降低纹理大小


左边开启MipMap,右边关闭MipMap
可以看到,当我们开启MipMap时,摄像机远处的纹理变模糊了。而右边关闭MipMap的纹理,远处没有模糊。这就是MipMap的作用,在游戏中,我们距离玩家视角较远的模型(比如树)会有质量上的递减效果。
MipMap就是对纹理进行了LOD处理。



- 从外部管理分辨率的降低,unity会给PSD等文件缩放,可能降低分辨率,并出现混叠失真
- 调整Anisotropic Filtering级别,非常轻些的角度观察纹理是提升纹理品质特性。

![]() 如果没有特别倾斜,不要用
如果没有特别倾斜,不要用
- 考虑使用图集,最小化使用DrawCall数量,是利用动态批处理的有效办法,角色动画不要合并到Sprite Atlas,要根据设备来确定,移动设备的纹理大小有限制


- 调整非正方形纹理的压缩率,例如256256类似的比较好,256512就不好
- Sparse Texture,运行时从磁盘传输纹理数据流,Sparse Texture将许多纹理合成一个巨大的纹理文件实现,而这个文件因为太大,无法作为一个纹理文件存到图形内存中,从而手动选择从磁盘中动态加载小片段纹理,在游戏中需要的时候取出来,节省大量的内存和宽带。可以显著提升性能。

- 程序化材质
- 异步纹理上传,禁用Read/Write Enable选项,可以启用Asynchronous Texture Uploading特性,让纹理异步上传到RAM,并且传输发生在渲染线程而不是主线程;如果开启Read/Write Enable选项,就是告知Unity要随时读取和编辑该纹理,按时GPU需要随时刷新对他的访问,从而使上传任务在主线程中执行,开启选项从而模拟在画布上画画。上传缓冲区和时间上限可以调整
4.3 网格和动画文件
- 减少多边形数量
- 调整网格压缩:Edit-Project Settings-Player-Other Settings设置Vertex Compression(用来配置在启用Mehs Compression的情况下导入网格文件时被优化的数据类型,全局,可以基于每个平台进行配置,因为是一个player设置)和Optimize Mesh Data(将剔除往前使用材质不需要的数据,例如网格包含切线信息但着色器不包含切线信息,将忽视),减少了磁盘占用,但是花费额外时间加载解压缩网格数据。
- Read/Write Enable启用意味着把原始网格数据保存在内存中以方便我们修改,因此如果确定要使用的最终网格后,就关闭。等比缩放可以关闭,如果经常以不同的比例重新出现,需要启用。
- 考虑烘焙动画。如果网格的多边形数足够低,而存储大量顶点信息比蒙皮数据更便宜,可以显著节省空间。
- 合并网格,特别是当网格对于动态批处理太大,不能与其他静态批处理组很好的配合时,本质上等同于静态批处理,不过时手动执行的。如果大部分时间只是部分可见,就不要这样做。这样做将生成一个全新的网格资产文件,如果对原始网格做任何更改都不会反映在合并的网格中,每次需要更改时,都将产生繁琐的工作流程。
4.4 Asset Bundle和Resource
Resource System以Nlog(N)的方式从序列化文件中获取数据,难以基于每个设备提供不同的素材数据。
Asset Bundle可以为应用程序提供小型的、定期的自定义内容更新。而Resource System需要完全替换整个应用程序,才能达到相同的效果。Asset Bundle还提供了更多的功能,如内容流式传输、内容更新、内容生成和共享,可以减少应用程序提高性能。维护更复杂
第5章 加速物理
如果错过了重要的碰撞事件或者计算复杂物理时间卡顿,或者玩家摔倒可能回产生负面影响。除了喜剧物理类型(模拟山羊),,,,对于大量任务的游戏,例如MMO精确物理不重要
5.1 物理引擎的内部工作情况
Unity有两种不同的物理引擎:3D物理的Nvidia的PhysX和2D物理的开源项目Box2D
5.1.1 物理和时间
物理引擎通常是按固定值前进的假设下运行的。每个迭代都成为时间步长,物理引擎只是用非常特定的时间值来处理每个时间不长,与上一帧花费的时间无关。称为Fixed Update Timestep,默认20ms,每秒50次更新。 固定更新在物理引擎执行更新前进行处理
固定更新在物理引擎执行更新前进行处理
如果有足够的时间,固定更新将调用所有激活的mono定义的FixedUpdate,处理协程的waitForFixedUpdate,在这个过程中调用的方法不能保证执行的顺序。完成这些任务,物理引擎才开始处理当前的时间步长。如果自上次固定更新以来经过的时间太少(<20ms,,说白了就是帧率太高了,就跳过fixedupdate),则跳过当前的固定更新。高帧率下,渲染更新比物理引擎更新次数更多( 会跳过该次固定更新和物理引擎更新 )。物理引擎会根据两个状态进行可见位置的插值。FixedUpdate用于放置任何期望独立于帧率的游戏行为,例如AI计算。
**FixedUpdate:**调用 FixedUpdate 的频度常常超过 Update。如果帧率很低,可以每帧调用该函数多次;如果帧率很高,可能在帧之间完全不调用该函数。在 FixedUpdate 之后将立即进行所有物理计算和更新。在 FixedUpdate 内应用运动计算时,无需将值乘以 Time.deltaTime。这是因为 FixedUpdate 的调用基于可靠的计时器(独立于帧率)。
假设我们在Project Settings中设置固定时间步长为0.01秒/10毫秒,即每秒进行100次固定更新和物理引擎更新
当我们的游戏以60fps运行时,每帧大约0.01666秒/16.67毫秒,由于我们设置的固定时间步长为0.01秒/10毫秒,可以知道此时进行一次固定更新和物理引擎更新大概10毫秒,即此时每帧画面都调用一次固定更新和物理引擎更新
当我们的游戏以30fps运行时,每帧大约0.03333秒/33.33毫秒,由于我们设置的固定时间步长0.01秒/10毫秒,可以知道此时,进行一次固定更新和物理引擎更新大概10毫秒,即此时每帧画面要调用三次的固定更新和物理引擎更新
当我们的游戏以20fps运行时,每帧大约0.05秒/50毫秒,由于我们设置的固定时间步长0.01秒/10毫秒,可以知道此时,进行一次固定更新和物理引擎更新大概10毫秒,即此时每帧画面要调用五次的固定更新和物理引擎更新
当帧率继续降低时,每一帧需要的固定更新和物理引擎更新次数将会越来越多
因此,我们需要最大允许的时间步长Maximum Allowed Timestep,一般设置为0.3333秒/333.33毫秒,即每帧渲染超过333.33毫秒之后不再进行固定更新和物理引擎更新,来为其他的处理省下时间
5.1.2 静态碰撞器和动态碰撞器
动态碰撞器意味着gameobject包含collider和rigidbody,会对外部的里与其他rigidbody的碰撞做出反应。如果一个动态碰撞器碰撞一个无rigidbody的静态碰撞器,静态碰撞器没有相应,动态碰撞器有响应。相当于石头扔到无限质量的物体上。
5.1.3 碰撞检测
Discrete离散(对于高速移动有丢失碰撞的风险)、Continuous连续(尽在给定碰撞器与静态碰撞器启用连续碰撞检测,,如果与动态碰撞器的碰撞还是离散碰撞检测)、ContinuousDynamic连续动态(与动态静态碰撞器都是连续碰撞检测)。后两个从时间步长的其实和结束位置插入碰撞器,检查这个时间段中是否有任何碰撞。
5.1.4 碰撞器类型
 Concave凹至少有一个大于180的内角,开启Convex将生成类似左侧的Convex凸碰撞体,,,上限255个顶点。凹面网格碰撞不能时动态碰撞器,只能用作静态碰撞器或触发体积isTrigger。
Concave凹至少有一个大于180的内角,开启Convex将生成类似左侧的Convex凸碰撞体,,,上限255个顶点。凹面网格碰撞不能时动态碰撞器,只能用作静态碰撞器或触发体积isTrigger。
5.1.5 碰撞矩阵
矩阵定义允许哪些对象与哪些其他对象发生碰撞。
5.1.6 Rigidbody激活和休眠状态
如果物体的速度在短时间内没有 超过某个阈值,那么物理引擎将假设物体在经历新的碰撞或施加新的力之前不需要再次移动,将进入休眠状态。直到被外力或碰撞事件唤醒。
5.1.7 射线与对象投射
射线从一个点投射到另一个点。
对象投射。Physics.OverlapSphere,检查空间中固定点的优先距离内获得目标列表。Physics.ShpereCast在空间中向前投射整个对象(宽激光束)
5.1.8 调试物理
Physics Debugger检查碰撞等物理问题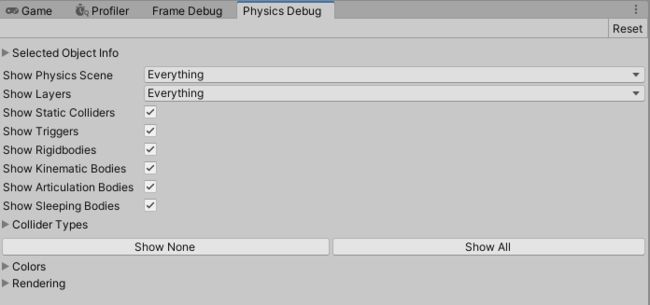
5.2 物理性能优化
5.2.1 场景设置
- 缩放:Unity的1个单位等于1米,缩放会导致物体重力相对变化,例如5倍大小的物体,重力就会减弱5倍。物体缩放很小会看起来下落很快
- 位置:越接近(0,0,0)将具有更好的浮点数精度。(偷偷传送玩家回世界中心)
- 质量:通常1.0表示1kg,但是可以指定一个人的质量是1.0(130kg),汽车的质量是10.0(1300kg),确保最大相对质量比在100左右,避免问题。可以禁用UseGravity,在固定更新期间应用自己定义的重力。
5.2.2 适当使用静态碰撞器
**如果不希望碰撞体与其他物体发生物理碰撞的情况下移动,应该添加Rigidbody称为动态碰撞器并开启Kinematic标志,来防止对象收到对象间碰撞的外部脉冲做出反应,类似静态碰撞器,但仍可以通过Transform组件或施加到Rigidbody的力来移动。(Kinematic对象不会对撞机的其他物体产生反应,在运动时会推开其他动态碰撞器,常应用于Player玩家物体)Is Kinematic 运动学:**如果我们只是需要让物理系统进行碰撞检测,不需要使用物理系统控制游戏对象,而是在脚本中使用 Transform 控制物体,此时我们可以勾选刚体组件中的 Is Kinematic 属性。
5.2.3 恰当使用触发体积
OnCollider…()回调体哦国内了一个Collision对象作为回调参数,其包含了详细的碰撞信息,OnTrigger…()没有
5.2.4 优化碰撞矩阵

5.2.5 首选离散碰撞检测

5.2.6 修改固定更新频率
增加频率,使其更容易通过离散碰撞检测捕获碰撞。
减小频率,CPU有更多时间完成其他任务,但是物体的移动速度降低了,难以通过离散碰撞检测。
5.2.7 调整允许的最大时间步长
如果处理物理计算的时间经常超过允许的最大时间步长,将导致一些看起来很奇怪的物理行为,由于物理引擎需要在完全处理其整个时间配额之前,尽早退出时间步长的计算,因此刚体似乎会减速或突然停止。出现这种情况,很明显需要从其他地方优化物理行为,但是最起码这个阈值可以防止游戏在物理处理过程的峰值中完全卡住。。。默认0.333,超过该值,帧率显著下降。
5.2.8 最小化射线发射和边界体积检查
射线投射方法好用但消耗大。特别是CapsuleCast和SphereCast方法。避免在Update中调用。如果在场景使用持续的西安、射线或区域碰撞(例如激光,火焰,光束武器等)并且保持相对静止,简单的触发体积也很好。不可避免使用的话,最好用layermask调整最小化处理量。
5.2.9 避免复杂的网格碰撞器
- 使用更简单的基本体

- 使用更简单的网格碰撞器
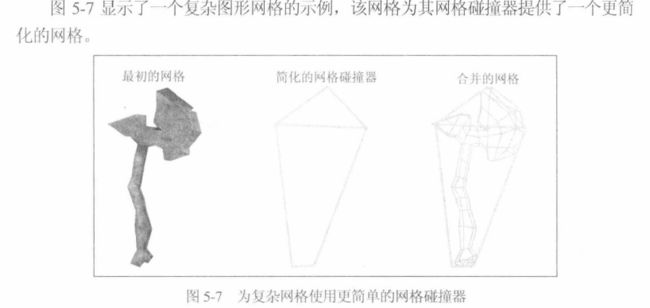
5.2.10 避免复杂的物理组件
特殊物理碰撞器例如TerrainCollider、Cloth、WheelCollider等,如果不会近距离接触,就不要添加。
5.2.11 使物理对象休眠
碰撞频率和活动物体的总累计时间更有可能以指数形式而不是线性形式增加。不要假定使翻倍。
修改Rigidbody的mass、drag等会重新唤醒对象。
对象离得太近,可能产生群岛效应,相互接触同时休眠,同时唤醒,会产生CPU峰值。
5.2.12 修改迭代器迭代次数
对于复杂的关节系统,可以增加迭代次数,有一些可以减少计算量。新建刚体可以Physics.defaultSolverIterations可以运行时修改迭代次数,但不会影响已经存在的刚体。可以在刚体构造后通过Rigidbody.solverIterations来修改Solver Iteration Count
5.2.13 优化布娃娃


- 减少关节碰撞,,只是用七个碰撞体(盆骨、胸部、头部、每个肢体一个碰撞器)
- 避免布娃娃间碰撞。指数级性能成本
- 更换(7关节版)、禁用或移除不活跃的布娃娃,,通过Rigidbody.IsSleeping判断是否休眠
5.2.14 确定何时使用物理
- 避免使用物理:掉入一个杀戮区(水、熔岩等)只需要判断y<0,不需要添加碰撞器
- 使用物理: 通过脚本大量计算的,而物理轻松实现。玩家单机拾取物体,用Physics.OverlapSphere轻松实现
- 确保删除不必要的物理工作
第6章 动态图形(补充)
6.1 渲染管线
第7章 虚拟速度和增强加速度
7.1 XR仿真
- 仿真
- 用户舒适度:晕动症,,,另外如果有依赖加速度的行为可能导致用户为了抵消加速度本能调整平衡从而失去方向感摔倒,,,,电线,,,,,fps,,,避免长时间产生加速度或导致不受控的旋转和水平运动,,,,加速度移动应该与用户的真实移动位移相符,不能感觉移动乐很少但是视角变化了很大,,,以及运动要及时随着用户的停止而停止,,,,不要将2D3D混用。
7.2 性能增强
7.2.1 物尽其用
VR用户最大的威胁是CPU,两眼都要渲染画面,并且AR要时刻解析对象的空间位置,还需要大量的Draw Call来渲染,并且遮挡剔除可能难以设置因为用户会下意识查看周围,,,,如果不使用注视点渲染lod等将毫无意义。
7.2.2 单通道立体渲染和多通道立体渲染

单通道将画面合成一个双倍宽度的texture每只眼镜显示一半,,,,能够降低Draw Call,显著降低CPU在主线程的工作,减少了GPU纹理需要转换的次数,,,当然CPU还是把对象从两个角度渲染了两次。缺点:OpenGl ES3.0以上才能用。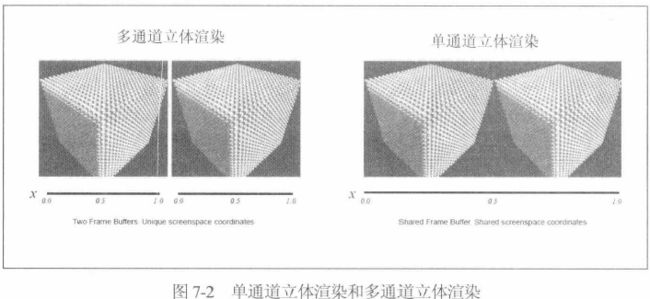
后处理需要针对每只眼镜执行一次,单通道尽管可以减少Draw Call但是不能同时对两个图像同时进行后处理。需要确保后处理的着色器效果,保证渲染到输出纹理的对应那一半上。
7.2.3 应用抗锯齿
抗锯齿提高保真度,减少像素干,提高陈进度,但是会消耗大量的CPU。,,,但是应该尽早启用这个特性。
7.2.4 首选前向渲染

7.2.5 VR的图像效果
在VR中法线纹理应用的效果容易发生错误。
7.2.6 背面剔除
应该仔细考虑对远处的物体应用背面剔除。要保证摄像机附近的素材是完全封闭的形状
7.2.8 空间化音频
音频数据不再代表特定频道的音频数据,而是包含某些音频谐波数据,运行时合并在一起,创建更可信的音频体验。这会产生CPU活动。
7.2.9 避免摄像机物理碰撞
用户可能视角穿模,,,添加碰撞体不让用户离墙面太近。但可能会导致VR中定向障碍,因为摄像机不会与用户移动一致。我往前走,但是摄像机卡住在画面中没走。。。。因此最好就设置安全的缓冲区,不要离这种地方太近。
7.2.9 避免欧拉角
可能多次旋转后导致不准,最好使用四元数
第8章 掌握内存管理(补充)
第9章 提示与技巧
9.1 编辑器热键提示
9.1.1 GameObject
Ctrl + D赋值
Ctrl + Shift + N新建空GameObject
Ctrl + Shift + A快速打开Add Component
9.1.2 Scene 窗口
Shift + F(双击F)跟踪选中物体,,帮助追踪掉出场景之外的物体
Alt + 左键在Scene让相机环绕转动
Ctrl + 左键移动物体可以让物体移动时对齐到网格
按住V键移动物体,强制对齐顶点到其他对象。
按下右键,WASD控制摄像头飞行,QE起飞和降落
9.1.3 界面
按住Alt键单击Hierarchy窗口的箭头,全部展开
Shift + 空格 快速让当前窗口充满整个屏幕
Ctrl + Shift + P 在play模式下快速暂停
Ctrl + Alt + P 单步执行
9.2 编辑器UI提示
9.2.1 脚本执行顺序
Edit-Project Settings-Script Execution Order,可以指定哪些脚本有限执行
9.2.2 编辑器文件

![]()
使用Editor Log查看构建成功的项目资源,,,查看那个文件大。![]()

9.2.3 Inspector窗口
输入公式计算,例如4*128
Inspector窗口有Debug Mode,打开所有的私有字段也会看见。甚至可以显示ObjectID,可以查看根序列化系统相关的东西


9.2.4 Project窗口
在搜索框输入t:查找特定类型的文件
如果使用Asset Bundle和内建的标签系统,l:也可以搜索标签捆绑的对象
右键选择物体,选择Select Dependencies可以查看此资源以来的所有对象,,如果尝试进行资源清理,这很有用

9.2.5 Hierarchy窗口
输入t:基于组件进行过滤。。。
此功能不区分大小写,并且派生组件也会显示
9.2.6 Scene和Game窗口
从Game窗口看不到Scene窗口相机,但使用热键移动和对齐相机会容易很多。
**编辑器允许将所选对象对齐到相同位置。并通过GameObject-Align with view或Ctrl + Shift + F将选中的物体直接放到当前的相机view位置。**例如选中相机,就对齐到当前view,,,选中物体,物体跑到当前view的位置

GameObject-Align View to Selected将Scene窗口相机与所选对象对齐。可以检查对象指向的方向是否有误。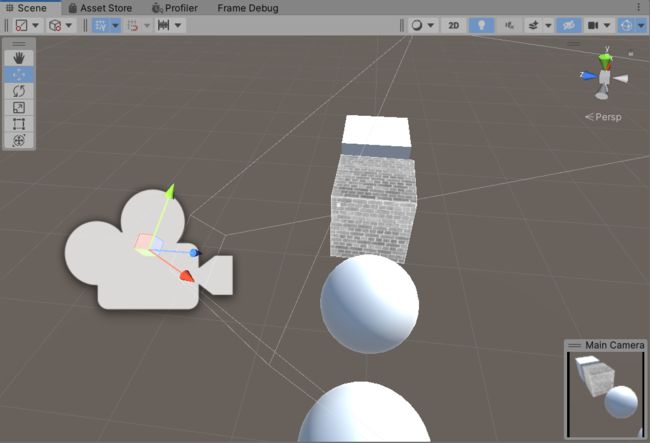

右上角Layer可以直接过滤对象。
9.2.7 Play模式
Play模式下也可以保存预制体,,,如果原始对象来源于预制体,在Play模式中更新了,可以直接拖拽play中的预制体到原始预制体上,强制覆盖。。。。不会弹出对话框,,别覆盖错
Frame Skip按钮Pause右边,一阵一阵迭代,每一次都会调用FixedUpdate和Update,与通常可能不一样。
Play模式开始时按下了Pause,将在第一帧暂停
9.3 脚本提示
9.3.1 一般情况
可以修改新脚本、着色器和Compute Shader文件的不同模板
9.3.2 特性
- **[Range]**用于整型或浮点型字段,该字段在Inspector中变成滑条,可以给定最大最小值限定范围。。。。如果重新命名某变量甚至通过IDE重构,Unity重新编译后变量值将丢失,如果想要保存序列化之前的值,用[FormerlySerializedAs( oldName: “xxx”)]在编译期间将数据从该特性中命名的变量赋值给给定的变量。(**转化完移除[FormerlySerializedAs]并不安全,**除非在包含特性之后,手动更改变量并将其重新保存到每个相关的预制体中,因为.prefab数据文件依然包含旧的变量名,通过特性来指出当下次加载文件时在哪里定位数据)
- 类特性[SelectionBase]特性将组件所附加到的任何GameObject标记为在Scene窗口选择对象时的根。例如选择根节点很多。Parent-node1-node2-Cube,scene则么选都只能点击到Cube,但是如果给node1添加脚本带有[SelectionBase]字段,将在scene窗口中即使选中到了Cube也会定位到node1,,,如果多个添加字段会就近选择在一个根目录下生效一次。[ExecuteInEditMode]将强制在编辑模式下执行对象的Update、OnGUI、OnRenderObject,但是仅当内容发生变化才调用update,OnGUI在Game窗口事件中调用,OnRenderObject在Scene和Game任何重绘事件调用。
9.3.3 日志
Debug.Log()可以添加富文本、粗体、斜体、
Debug.Log(“![]()
9.4 自定义编辑器脚本和菜单提示


9.5 外部提示
