又一个轻量级 ViT:Lite Vision Transformer with Enhanced Self-Attention
Lite Vision Transformer with Enhanced Self-Attention

[pdf]

Figure 1. Mobile COCO panoptic segmentation. The model needs to recognize, localize, and segment both objects and stuffs at the same time. All the methods have less than 5.5M parameters with same training and testing process under panoptic FPN framework. The only difference is the choice of encoder architecture. Lite Vision Transformer (LVT) leads to the best results with significant improvement over the accuracy and coherency of the labels.
目录
Lite Vision Transformer with Enhanced Self-Attention
Abstract
1. Introduction
3. Lite Vision Transformer
3.1. Convolutional Self-Attention (CSA)
3.2. Recursive Atrous Self-Attention (RASA)
3.3. Model Architecture
Abstract
Despite the impressive representation capacity of vision transformer models, current light-weight vision transformer models still suffer from inconsistent and incorrect dense predictions at local regions.
We suspect that the power of their self-attention mechanism is limited in shallower and thinner networks.
We propose Lite Vision Transformer (LVT), a novel light-weight transformer network with two enhanced self-attention mechanisms to improve the model performances for mobile deployment. For the low-level features, we introduce Convolutional Self-Attention (CSA). Unlike previous approaches of merging convolution and selfattention, CSA introduces local self-attention into the convolution within a kernel of size 3×3 to enrich low-level features in the first stage of LVT. For the high-level features, we propose Recursive Atrous Self-Attention (RASA), which utilizes the multi-scale context when calculating the similarity map and a recursive mechanism to increase the representation capability with marginal extra parameter cost.
The superiority of LVT is demonstrated on ImageNet recognition, ADE20K semantic segmentation, and COCO panoptic segmentation.
尽管 vision transformer 模型的表示能力令人惊叹,但目前的轻量级 vision transformer 模型仍然存在局部区域密集预测不一致和不正确的问题。
作者认为目前的自注意力机制的能力在较浅和较薄的网络中是有限的。
本文提出了 Lite Vision Transformer (LVT),一种新型的轻量级 transformer 网络,具有两种增强的自注意力机制,以改善移动部署的模型性能。对于底层特征,本文引入了卷积自注意力 (Convolutional Self-Attention, CSA)。与以往融合卷积和自注意力的方法不同,CSA 将局部自注意引入到大小为 3 x 3 的核内的卷积中,以丰富 LVT 第一阶段的低级特征。对于高级特征,本文提出了递归 Atrous 自注意力 (RASA),利用多尺度上下文计算相似性映射,并采用递归机制以增加额外的参数代价的表示能力。
LVT 在 ImageNet 识别、ADE20K 语义分割、COCO 全景分割等方面的优势得到了验证。
1. Introduction
Transformer-based architectures have achieved remarkable success most recently, they demonstrated superior performances on a variety of vision tasks, including visual recognition [63], object detection [36, 54], semantic segmentation [8, 58] and etc [30, 52, 53].
Inspired by the success of the self-attention module in the Natural Language Processing (NLP) community [51], Dosovitskiy [16] first propose a transformer-based network for computer vision, where the key idea is to split the image into patches so that it can be linearly embedded with positional embedding. To reduce the computational complexity introduced by [16], Swin-Transformer [36] upgrades the architecture by limiting the computational cost of selfattention with local non-overlapping windows. Additionally, the hierarchical feature representations are introduced to leverage features from different scales for better representation capability. On the other hand, PVT [54, 55] proposes spatial-reduction attention (SRA) to reduce the computational cost. It also removes the positional embedding by inserting depth-wise convolution into the feed forward network (FFN) which follows the self-attention layer in the basic transformer block. Both Swin-Transformer and PVT have demonstrated their effectiveness for downstream vision tasks. However, when scaling down the model to a mobile friendly size, there is also a significant performance degradation.
基于 Transformer 的架构取得了显著的成功,它们在各种视觉任务中表现出了卓越的性能。Dosovitskiy 受到自然语言处理 (NLP) 中自注意力模块成功的启发,首次提出了一种基于 Transformer 的计算机视觉网络,其关键思想是将图像分割成小块,从而通过位置嵌入实现线性嵌入。为了降低引入的计算复杂度,Swin-Transformer 通过使用局部非重叠窗口限制自注意的计算代价来升级体系结构。此外,引入分层特征表示来利用来自不同尺度的特征以获得更好的表示能力。另一方面,PVT 提出了spatial-reduction attention (SRA) 来降低计算成本。它还通过在基本变压器块的自注意层之后的前馈网络(FFN)中插入深度卷积来消除位置嵌入。Swin-Transformer 和 PVT 都证明了它们对于下游视觉任务的有效性。然而,当将模型缩小到移动友好的大小时,也会出现显著的性能下降。
In this work, we focus on designing a light yet effective vision transformer for mobile applications [45]. More specifically, we introduce a Lite Vision Transformer (LVT) backbone with two novel self-attention layers to pursue both the performance and compactness. LVT follows a standard four-stage structure [19, 36, 55] but has similar parameter size to existing mobile networks such as MobileNetV2 [45] and PVTv2-B0 [54].
本工作专注于设计一个轻而有效的 Vision Transformer 能够在移动端应用。更具体地说,本文引入了一个 Lite Vision Transformer (LVT) backbone,它具有两个新颖的自注意力层,以追求性能和紧凑性。LVT 遵循标准的四阶段结构,但具有与现有移动网络类似的参数大小,如MobileNetV2 和 PVTv2-B0。
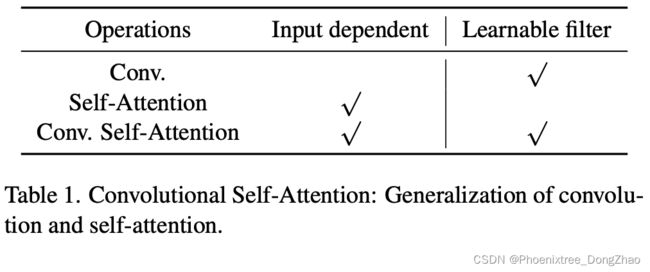
Our first improvement of self-attention is named Convolutional Self-Attention (CSA). The self-attention layers [1, 22, 42, 56, 64] are the essential components in vision transformer, as self-attention captures both short- and longrange visual dependencies.
However, identifying the locality is another significant key to success in vision tasks. For example, the convolution layer is a better layer to process low-level features [14]. Prior arts have been proposed to combine convolution and self-attention with the global receptive field [14, 57]. Instead, we introduce the local selfattention into the convolution within the kernel of size 3×3. CSA is proposed and used in the first stage of LVT. As a result of CSA, LVT has better generalization ability as it enriches the low-level features over existing transformer models. As shown in Fig 1, compared to PVTv2-B0 [54], LVT is able to generate more coherent labels in local regions.
本文的第一个核心技术:
本文对自注意力的第一个改进是卷积自注意力 (Convolutional self-attention, CSA)。自注意力层是 vision transformer 的基本组件,因为自注意力捕获了短距离和长距离的视觉依赖。
然而,识别位置是视觉任务成功的另一个重要关键。例如,卷积层是处理底层特征的较好层。已有技术提出将卷积和自注意力与全局感受野结合起来。
相反,本文将局部自注意力引入到大小为 3x3 的核内的卷积中。CSA 应用于 LVT 的第一阶段。由于 CSA 的存在,LVT 比现有的 transformer 模型更丰富了底层特征,具有更好的泛化能力。如图 1 所示,与 PVTv2-B0 相比,LVT 能够在局部区域生成更多的连贯的标签。
On the other hand, the performances of lite models are still limited by the parameter number and model depth [58]. We further propose to increase the representation capacity of lite transformers by Recursive Atrous Self-Attention (RASA) layers. As shown in Fig 1, LVT results have better semantic correctness due to such effective representations. Specifically, RASA incorporates two components with weight sharing mechanisms. The first one is Atrous Self-Attention (ASA). It utilizes the multi-scale context with a single kernel when calculating the similarities between the query and key. The second one is the recursion pipeline. Following standard recursive network [17,26], we formalize RASA as a recursive module with ASA as the activation function. It increases the network depth without introducing additional parameters.
本文的第二个核心技术:
另一方面,lite 模型的性能仍然受到参数数量和模型深度的限制。
因此,本文进一步提出通过递归 Atrous 自注意力 (RASA) 层来提高 lite transformer 的表示能力。如图 1 所示,LVT 结果的语义正确性较好,这是因为这种有效的表示方式。
具体来说,RASA 包含了两个具有权重共享机制的组件。
第一个是 Atrous 自注意力 (ASA)。在计算 query 和 key 之间的相似度时,它利用了具有单个内核的多尺度上下文。
第二个是递归 pipeline。按照标准的递归网络,本文将 RASA 形式化为一个递归模块,其中 ASA 作为激活函数。它在不引入额外参数的情况下增加了网络深度。
Experiments are performed on ImageNet [44] classification, ADE20K [67] semantic segmentation and COCO [34] panoptic segmentation to evaluate the performance of LVT as a generalized vision model backbone. Our main contributions are summarized in the following:
• We propose Convolutional Self-Attention (CSA). Unlike previous methods of merging global self-attention with convolution, CSA integrates local self-attention into the convolution kernel of size 3 × 3. It is proposed to process low-level features by including both dynamic kernels and learnable filters.
• We propose Recursive Atrous Self-Attention (RASA). It comprises two parts. The first part is Atrous SelfAttention (ASA) that captures the multi-scale context in the calculation of similarity map in self-attention. The other part is the recursive formulation with ASA as the activation function. RASA is proposed to in crease the representation ability with marginal extra parameter cost.
• We propose Lite Vision Transformer (LVT) as a lightweight transformer backbone for vision models. LVT contains four stages and adopts CSA and RASA in the first and last three stages, respectively. The superior performances of LVT are demonstrated in ImageNet recognition, ADE20K semantic segmentation, and COCO panoptic segmentation.
本文贡献:
在 ImageNet 分类、ADE20K 语义分割和 COCO 全景分割上进行实验,以评估 LVT 作为广义视觉模型主干的性能。主要贡献总结如下:
• 提出了卷积自注意力 (Convolutional Self-Attention, CSA)。与以往融合全局自注意力和卷积的方法不同,CSA 将局部自注意力集成到大小为 3 × 3 的卷积核中。该算法通过包含动态核和可学习滤波器来处理底层特征。
• 提出递归 Atrous 自注意力 (RASA)。它由两部分组成。第一部分是 Atrous自注意力 (ASA),它捕捉了自注意力相似性映射计算中的多尺度语境。另一部分是用 ASA 作为激活函数的递归公式。提出了 RASA 算法,在增加微乎其微额外参数的前提下提高算法的表示能力。
• 提出 Lite Vision Transformer (LVT) 作为视觉模型的轻量级 Transformer backbone。LVT 包含四个阶段,前三个阶段分别采用 CSA 和 RASA。LVT 在 ImageNet 识别、ADE20K 语义分割和 COCO 全景分割等方面的性能都得到了验证
3. Lite Vision Transformer
We propose Lite Vision Transformer (LVT), which is shown in Fig 2. As a backbone network for multiple vision tasks, we follow the standard four-stage design [19, 36, 55]. Each stage performs one downsampling operation and consists of a series of building blocks. Their output resolutions are from stride-4 to stride-32 gradually. Unlike previous vision transformers [16, 36, 55, 63], LVT is proposed with limited amount of parameters and two novel self-attention layers. The first one is the Convolutional Self-Attention layer which has a 3 × 3 sliding kernel and is adopted in the first stage. The second one is the Recursive Atrous SelfAttention layer which has a global kernel and is adopted in the last three stages.
方法总览:
本文提出了Lite Vision Transformer (LVT),如图 2 所示。作为多视觉任务的 backbone,本文遵循标准的四阶段设计。每个阶段执行一次下采样操作,并由一系列构建块组成。他们的输出决议从 stride-4 逐步到 stride-32。与以往的 vision transformers 不同,LVT 是在参数有限的情况下提出的,它具有两个新的自注意力层。第一个是卷积自注意力层,第一阶段采用了 3x3 滑动核。第二个是递归的 Atrous 自注意力层,它有一个全局内核,在最后三个阶段被采用。
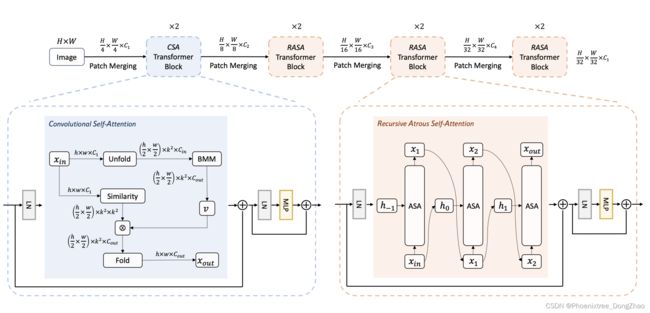

3.1. Convolutional Self-Attention (CSA)
The global receptive field benefits the self-attention layer in feature extraction. However, convolution is preferred in the early stages of vision models [14] as the locality is more important in processing low-level features. Unlike previous methods of combining convolution and large kernel (global) self-attention [14, 57], we focus on designing a windowbased self-attention layer that has a 3 × 3 kernel and incorporates the representation of convolution.
全局感受野有利于自注意力层的特征提取。然而,在视觉模型的早期阶段,由于局域性在处理低层次特征时更为重要,因此首选卷积。与以往将卷积和大核 (全局) 自注意力相结合的方法不同,本文专注于设计一个基于窗口的自注意力层,该层具有 3 × 3 核,并包含卷积的表示。
Analyzing Convolution
Let
be the input and output feature vectors where d represents the channel number. Let
index the spatial locations. Convolution is computed by sliding windows. In each window, we can write the formula of convolution as:
where N(i) represents the spatial locations in this local neighborhood that is defined by the kernel centered at location i. |N(i)| = k × k where k is the kernel size. i → j represents the relative spatial relationship from i to j.
is the projection matrix. In total, there are |N(i)| Ws in a kernel. A 3 × 3 kernel consists of 9 such matrices W_s.

关于卷积的分析:
设 ![]() 为输入和输出特征向量,其中 d 表示通道数。设
为输入和输出特征向量,其中 d 表示通道数。设![]() 索引空间位置。卷积是通过滑动窗口计算的。在每个窗口中,可以将卷积公式写为(1)。
索引空间位置。卷积是通过滑动窗口计算的。在每个窗口中,可以将卷积公式写为(1)。
其中 N(i) 表示由以位置 i 为中心的核定义的局部邻域中的空间位置。|N(i)| = k × k,其中 k 为核大小。i→j 表示i到j的相对空间关系, 为投影矩阵。一个核中总共有 |N(i)| Ws。一个 3 × 3 核由 9 个这样的矩阵 W_s 组成。
Analyzing Self-Attention
Self-Attention needs three projection matrices
to compute query, key and value. In this paper, we consider sliding window based self-attention. In each window, we can write the formula of self-attention as
where
is a scalar that controls the contribution of the value in each spatial location in the summation. α is normalized by softmax operation such that
1. Compared with convolution with the same kernel size k, the number of learnable matrices is three rather than k^2. Recently, Outlook Attention [63] is proposed to predict α instead of calculating it by the dot product of query and key, and shows superior performances when the kernel size is small. We employ this calculation, and it can be written as:
where
and [j] means j-th element of the vector.
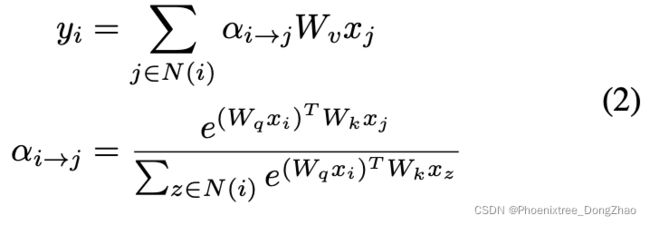
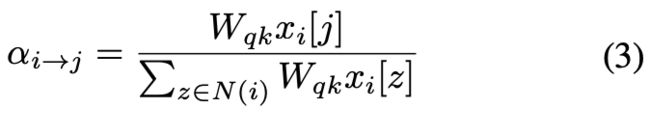
关于自注意力的分析:
Self-Attention 需要三个投影矩阵 来计算 query, key and value。本文考虑了基于滑动窗口的自注意力问题。在每个窗口中,可以写出自注意力的公式为(2)。其中,是一个标量,它控制着该值在每个空间位置对求和的贡献。采用 softmax 运算对 α 进行归一化,使 1。与相同核大小 k 的卷积相比,可学习矩阵数为 3,而不是 k^2。最近,Outlook Attention 提出了预测 α,而不是通过 query 和 key 的点积来计算 α,并且在内核尺寸较小时表现出了优越的性能。本文采用这样的计算,可以写成(3)。其中 和 [j] 表示向量的第 j 个元素。
Outlook Attention: VOLO: Vision outlooker for visual recognition. 2021.
[GitHub]

Convolutional Self-Attention (CSA)
We generalize selfattention and convolution into a unified convolutional selfattention as shown in Fig 3. Its formulation is shown in the following:
Both SA and CSA have the output of size k × k for a local window. When
where all the weights are the same, CSA is the convolution for the output center. When
where all the projection matrices are the same, CSA is self-attention. As we employ the dynamic α predicted by the input, as shown in Eqn. (3), Outlook Attention [63] is a special case of CSA. CSA has a bigger capacity than Outlook Attention. We summarize its property in Tab. 1. By this generalization, CSA has both input-dependent kernel and learnable filter. It is designed for stronger representation capability in first stage of vision transformers.

卷积自注意力:
本文将自注意力和卷积推广为统一的卷积自注意力,如图 3 所示。其公式如(4)。


SA 和 CSA 都有大小为 k × k 的局部窗口输出。当 ![]() 且所有权值相同时,CSA 为输出中心的卷积。当 且所有投影矩阵相同时,CSA 为自注意力。当使用输入预测的动态 α 时,如等式 (3) 所示。Outlook Attention 是 CSA 的一个特例。CSA 的容量比 Outlook Attention 大。在表 1 中总结了它的性质。通过这种推广,CSA 既具有输入相关的核,又具有可学习的滤波器。CSA 是为增强 vision transformers 第一阶段的表现能力而设计的。
且所有权值相同时,CSA 为输出中心的卷积。当 且所有投影矩阵相同时,CSA 为自注意力。当使用输入预测的动态 α 时,如等式 (3) 所示。Outlook Attention 是 CSA 的一个特例。CSA 的容量比 Outlook Attention 大。在表 1 中总结了它的性质。通过这种推广,CSA 既具有输入相关的核,又具有可学习的滤波器。CSA 是为增强 vision transformers 第一阶段的表现能力而设计的。

CSA Transformer
3.2. Recursive Atrous Self-Attention (RASA)
Light-weight models are more efficient and more suitable for on-device applications [45]. However, their performances are limited by the small number of parameters even with advanced model architecture [58]. For light-weight models, we focus on enhancing their representation capabilities with marginal increase in the number of parameters.
轻量化模型更高效,更适合于设备上的应用程序。然而,即使采用先进的模型体系结构,其性能也受到参数数量较少的限制。对于轻量级模型,本文将重点放在通过略微增加参数数量来增强它们的表示能力。
Atrous Self-Attention (ASA)
Multi-scale features are beneficial in detecting or segmenting the objects [33, 65]. Atrous convolution [5, 6, 39] is proposed to capture the multi-scale context with the same amount of parameters as standard convolution. Weights sharing atrous convolution [40] is also demonstrated in boosting model performances. Unlike convolution, the feature response of selfattention is a weighted sum of the projected input vectors from all spatial locations. These weights are determined by the similarities between the queries and keys, and represent the strength of the relationship among any pair of feature vectors. Thus we add multi-scale information when generating these weights shown in Fig 4. Specifically, we upgrade the calculation of the query from a 1 × 1 convolution to the following operation:
are the feature maps, and
is the kernel weight. H, W are the spatial dimensions. d is the feature channels. k, r and g represent the kernel size, dilation rate, and group number of the convolution. We first use the 1 × 1 convolution to apply linear projection. Then we apply three convolutions that have different dilation rates but a shared kernel to capture the multiscale contexts. The parameter cost is further reduced by setting the group number equal to the feature channel number. The parallel features of different scales are then weighted summed. We employ a self-calibration mechanism that determines the weights for each scale by their activation strength. This can be implemented by the SiLU [20, 43]. By this design, the similarity calculation of the query and key between any pair of spatial locations in self-attention uses the multi-scale information.

Atrous 自注意力:
多尺度特征有利于检测或分割目标。Atrous 卷积提出,用与标准卷积相同数量的参数来捕获多尺度上下文。权值共享的 atrous 卷积也证明了提高模型性能。与卷积不同,自注意力的特征响应是来自所有空间位置的投影输入向量的加权和。这些权重由查询和键之间的相似度决定,并表示任何一对特征向量之间的关系强度。因此,在生成如图 4 所示的权重时,本文添加了多尺度信息。


具体来说,将 query 的计算从 1 × 1 的卷积升级为(5),(6)和(7)的操作。
为特征图,  为核权值。H, W 是空间维度。D 为特征通道。K、r、g 表示卷积的核大小、膨胀速率和群数。
为核权值。H, W 是空间维度。D 为特征通道。K、r、g 表示卷积的核大小、膨胀速率和群数。
首先使用 1 × 1 卷积来应用线性投影。
然后,应用三种具有不同膨胀率但共享内核的卷积来捕获多尺度上下文。通过将组数设置为特征通道数,进一步降低了参数开销。
最后,将不同尺度的并行特征加权求和。
本文采用了一种自校准机制,通过激活强度来确定每个刻度的重量。这可以由 SiLU 实现。在本设计中,自注意力中任意一对空间位置之间的 query 和 key 的相似度计算采用了多尺度信息。
Resursive Atrous Self-Attention (RASA)
For lightweight models, we intend to increase their depths without increasing the parameter usage. Recursive methods have been proposed in many vision tasks for Convolutional Neural Networks (CNNs) including [27, 31, 40, 48]. Unlike these methods, we propose a recursive method for selfattention. The design follows the pipeline of the standard recurrent networks [17, 26]. Together with atrous selfattention (ASA), we propose recursive atrous self-attention (RASA), and its formula can be written in the following:
where t is the step and
the hidden state. We take ASA as the non-linear activation function. The initial hidden state
is the linear function combining the input and hidden state.
are the projection weights. However, we empirically find that setting
provides the best performances and avoids introducing extra parameters. We set the recursion depth as two in order to limit the computation cost.
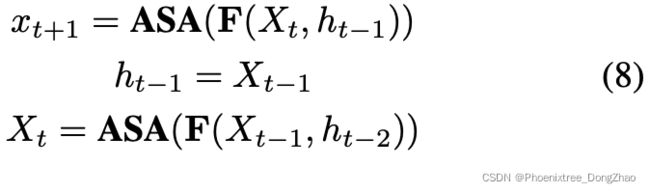
对于轻量级模型,本文打算在不增加参数使用的情况下增加它们的深度。
递归方法在卷积神经网络的许多视觉任务中被提出。与这些方法不同,本文提出了一种自注意力的递归方法。设计遵循标准循环网络的流水线。与 Atrous 自注意力 (ASA)d相结合,提出递归 Atrous 自我注意力 (RASA),其公式可以写成(8)。
其中 t 为步长,为隐状态。

以 ASA 作为非线性激活函数。初始隐藏状态 ![]() 是输入状态和隐藏状态相结合的线性函数。
是输入状态和隐藏状态相结合的线性函数。![]() 是投影权值。
是投影权值。
然而,经验发现,设置 提供了最好的性能,并避免引入额外的参数。
本文将递归深度设置为 2,以限制计算成本。
3.3. Model Architecture
The architecture of LVT is shown in Tab. 2. We adopt the standard four-stage design [19]. Four Overlapped Patch Embedding layers [58] are employed. The first one downsamples the image into stride-4 resolution. The other three downsample the feature maps to the resolution of stride8, stride-16, and stride-32. All stages comprise the transformer blocks [16]. Each block contains the self-attention layer followed by an MLP layer. CSA is embedded in the stage-1 while RASA in the other stages. They are enhanced self-attention layers proposed to process local and global features in LVT.
LVT 的架构如表 2 所示。本文采用标准的四阶段设计。采用四层重叠的 Patch embedding 层。第一个将图像采样到 stride-4 分辨率。另外三个样本将特征映射为 stride-8、stride-16 和 stride-32 的分辨率。所有级均由 transformer 块组成。每个块包含自注意力层,后面跟着一个 MLP 层。CSA 嵌入在第 1 阶段,RASA 嵌入在其他阶段。它们是增强的自注意力层,用于处理 LVT 中的局部和全局特征。

