【C语言】 知识点汇总--基础知识点梳理(超全超详细)
目录
一、从源代码到exe
二、基本数据类型
三、字符在屏幕上的显示原理
四、溢出现象
五、类型转换规律
六、短路问题
七、指针变量类型的作用
八、指针类型的扩展——多级指针
九、指针类型的扩展——指针数组
十、指针类型的扩展——数组指针
十一、一维数组-名-特性
十二、二维数组-名-特性
十三、大端存储-小端存储
十四、函数在源代码中的三种状态
十五、堆区与栈区的区别
十六、函数的执行原理
十七、枚举类型
十八、typedef
二十、const
二十一、全局/局部变量生命周期与作用域
二十二、static静态变量
二十三、extern
二十四、宏define
二十五、字符串原理
二十六、struct与union结构体联合体
二十七、链式存储与顺序存储
二十八、文件处理模型
二十九、文件复制原理
三十、组件化技术分类
一、从源代码到exe

知识点:
- 从源代码到exe要经过五个时期,分别为预处理期、编译期、汇编期、连接期和执行期。
- 在预处理期,就是程序员在编写代码的过程。编译期中编译器将源代码变为汇编语言,汇编语言是计算机语言的助记符号。汇编期中汇编器将汇编语言变为机器语言.obj,也就是计算机能够识别的01指令,机器最终执行的就是机器语言.obj,也称为目标文件。连接期就是将库函数(头文件)与所有的机器语言进行打包。最终在执行期将打包好的文件变为exe可执行文件。
- 如果出现语法错误,那就是在编译期出现了编译错误。
- 如果产生LNK连接错误就是在连接期出现了问题,可能是找不到头文件造成的,也可能是写错了main函数,或者在一个项目中没有或者出现多个main函数。
二、基本数据类型
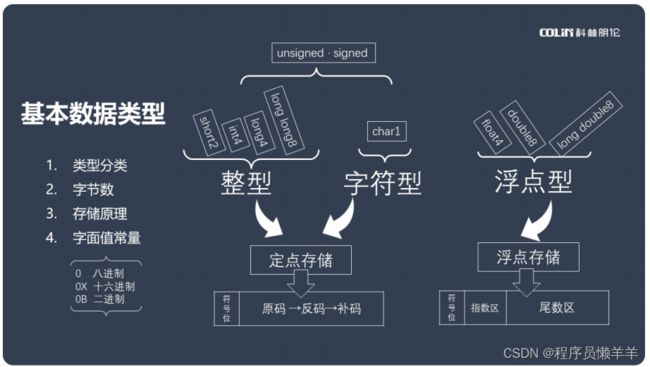
知识点:
- 基本数据类型可以分为整型、字符型和浮点型三大类,其中整型包括short,int,long,long long 4小类;字符型包括char一个小类;浮点型包括float,double,long double 3小类。
- 不同类型的字节数:char 1 short 2 int 4 long 4 long long 8 float 4 double 8 long double 8 单位都为字节。
- 整型与字符型的存储原理是定点存储,它是通过符号位和二进制数的补码来存储的;浮点型的存储原理为浮点存储,它是通过符号位、指数区和尾数区来存储的。
-
字面值常量的前缀,如果是八进制就在常量前加0,如果是十六进制就加0x,如果是二进制就加0b,十进制则不需要前缀。
-
字面值的后缀,因为无符号的后缀为u,所以无符号的int类型后缀为u,正常int类型没有后缀,short类型没有后缀,long类型为l,无符号long类型为ul,long long类型为ll,无符号long long类型为ull,char无后缀。浮点型不区分有无符号,float类型为f,double没有后缀,long double为l,但一般用不到这个类型。
三、字符在屏幕上的显示原理

知识点:
- 字符型的本质是整型,他的字节数为1个字节,它属于定点存储,是8位的二进制数。
- 字符型常量如果是以影像或者八进制、十六进制的方式表达,那么需要在常量边上加上单引号'',如果是以十进制表达,那么就直接写上对应的十进制ASCII码值即可。
- 转义字符的作用:例如\n可以进行换行,\t可以自动制表,如果想输出\,那么需要在它的前面再加上一个\,还有许多类似的转义字符。
- 字符编码表的规律可以进行字母大小写的转换,因为相同字母的大小写ASCII码值相差32,多以对大写字母+32可以得到对应的小写字母;当然,对小写字母-32可以得到大写字母。如果想要将整型的数字变为字符型,那么在数字后+'0'即可,例如7+'0'='7',反之对字符型的数字-'0'可以得到整型数字。
四、溢出现象

溢出现象中有这么几个问题:
- -1的二进制为什么全1?
答:char类型的-1的原码为1000 0001,因为计算机在存储时存的是补码,所以要对除符号位之外的二进制进行取反变为反码1111 1110,在对其进行+1变为补码1111 1111。
- 什么是整型的溢出现象?
答:以图中这个短整型为例,-1的二进制存储为16个1,在加1的过程中会不断进位变为17位的二进制1 0000 0000 ......,但短整型只能存储16个二进制位,那么最前面的1就会出现溢出舍弃,称这个现象位溢出现象。
- 为什么有符号整型最大值+1反而是最小值?
答:我们知道,有符号的短整型最大值的二进制除符号位为0其他位都为1,对其进行+1就变为符号位为1其他位都为0,因为符号位为1是负数,并且此时为补码,要还原为原码就要对其取反再+1,先取反变为16个1,不看符号位,他的10进制为32767,再+1就是32768,最后补上符号就是最小值-32768。
五、类型转换规律
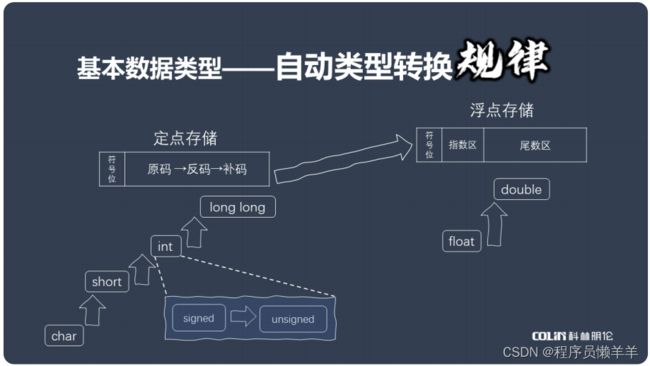
知识点:
- 基本数据类型转换包括两种方式一个是自动类型转换,一个是强制类型转换。
- 在自动类型转换中,如果计算时的存储方式相同,那么字节少的会向字节多的存储;如果是定点存储与浮点存储混合,那么会议浮点存储为主;如果是有符号与无符号混合,有符号的会存储到无符号的。
- 强制类型转换就是人为的将数据转换为其他数据类型,例如(double)7,就是将int类型的7转换为double类型。
六、短路问题

知识点:
- 逻辑与(&&)的运算特点为:有假则假、全真则真。
- 逻辑或(||)的运算特点为:有真则真、全假则假。
- 短路问题:在逻辑与运算中,利用了它有假则假的特点,计算机会对前面的式子进行判定,如果他是假的,那么计算机会判定整个逻辑为假,就不会继续对后面的表达式进行运算和判定了。逻辑或也是一样,如果前面的式子为真,那么不会再进行后续的运算,就像短路一样,所以称这种问题为短路问题。
七、指针变量类型的作用

知识点:
- 指针变量的内存空间大小与操作系统的位数有关。如果是X86 32位操作系统,指针的空间大小为4个字节,如果是X64 64位操作系统,那么指针的空间大小为8个字节。
- 指针变量保留的是所指向空间的地址。
- 内存地址编号的特征:首先内存地址具有唯一性、连续性,且内存地址的编号从小到大。因为字节是最小的存储单位,所以每个字节都有自己的地址编号,在取地址时,取的是变量所占字节的最小地址编号,也就是首地址。
- 指针变量类型的两大作用:一是它决定了指针在得到空间使用权时空间的大小。二是在指针移动时,会根据指针变量的类型不同,移动的步伐也不同,如果是int类型指针,在移动一个单位时会移动四个字节;如果是short类型指针就会移动两个字节;如果是char类型指针就会移动一个字节。
八、指针类型的扩展——多级指针

知识点:
- 二级指针也称为指向指针的指针。也就是将指针找到的地址再次进行存储
- 多级指针如何得到真正的数据:就拿图中的二级指针为例,因为二级指针存放的是数据地址的地址,所以说对其进行*操作可以得到数据的地址,在对他进行*操作即可得到真正的数据了。其他的多级指针也是一样,是几级指针就对他进行几次*操作就可以得到真正的数据。
- 多级指针所占内存空间的大小:因为多级指针也是指针变量,所以它的内存空间只与操作系统的位数有关。所以说如果是X86 32位操作系统,则指针变量的内存空间为4个字节,如果是X64 64位操作系统,则指针变量的内存空间大小为8个字节。
九、指针类型的扩展——指针数组
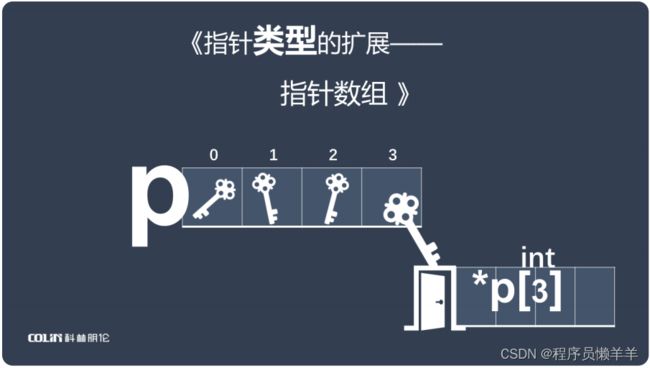
知识点:
- 指针数组就是存放指针的数组。
- 指针数组的每个成员都是指针变量,存储的就是对应空间的地址。
- 如何使用指针数组访问数据:我们知道,指针就像是钥匙,那么指针数组就是存放多个钥匙的数组。要想访问期成员对应的数据其实很简单,就对那个成员进行*操作即可。例如图中所示,想要访问这个指针数组第三个成员指向的数据,对它进行*操作就可以得到对应的空间了。
十、指针类型的扩展——数组指针

知识点:
- 数组指针就是指向数组的指针,它属于是指针类型。
- 数组指针与基本类型指针的区别:在这个图片中,第一行就为基本类型的指针,不难看出,数组指针所指向的空间更大,再看后两行,前边为指针数组,后边为数组指针,因为如果*p不加括号,int就会先与*结合变为int型指针,再通过后边的方括号进行扩展,最终命名为怕,而数组指针是int与方括号结合成为数组,再通过*p指向它。
- 数组指针如何访问数组成员空间?
答:我们知道,p指向的是数组的地址,也就是取地址符加上数组名,那么*p就是对取地址后的数组名再*操作,因为&与*为互逆操作,所以此时*p就等同于数组名,所以通过数组指针访问数组成员空间时,只要将数组名替换为*p即可。例如访问第三行第四列的成员空间正常来写就是 数组名[3][4];换成数组指针的写法就是(*p)[3][4]; 。
十一、一维数组-名-特性

图片解析:
先来看这张图,我们定义了一个一维数组,在这个数组中,他的数组名本质上就是个地址,是这个数组的首地址,我们也可以理解为这个数组第0个元素的地址,那么在这个地址上加上2意思就是向后移动两列,找到的就是这个数组第2各成员的地址。在这里有个公式 *(参考地址+偏移)==参考地址[偏移] 讲的其实就是[]的计算过程,意思就是通过数组名找到第0列的地址,再向后偏移四位就找到了第4列的地址,然后通过*操作就可以得到他的空间。快捷方式就是 参考地址[偏移]。最后要说的是arr与&arr的区别,虽然他们两个的值相同,但是代表的意义不同,arr代表的是数组第0列的地址,向后偏移1位找到的是第1列的地址,而&arr找到的是这个数组的地址,向后偏移1位找到的就是数组后边的地址。
知识点:
- 数组的特征:长度固定、同类型、有编号。
- 数组名是数组整个存储空间的首地址,也是第0个元素的地址,他是一个地址常量,所以是不可以修改的。
- []是空间寻找的快捷方式,他的计算过程是:*(参考地址+偏移) 。
十二、二维数组-名-特性

图片解析:
在图中,我们定义了一个int类型的二维数组。在这个数组中,数组名找到的就是第0行的地址,所以我们在数组名上加1可以找到第1行的地址,再*操作就可以得到第一行的空间。在得到行空间的基础上想要得到这行中某一成员的空间,就要在这个行空间上加上偏移量,找到某一成员的地址,再*操作就可以得到成员的空间了。这其实就是二维数组寻找成员空间的计算过程,化简之后就变成了数组名[][],前面是行后边是列。那么二维数组名取地址找到的就还是二维数组的地址,它加上1找到的就是二维数组后面的地址,并且*操作后得到的空间大小与二维数组的空间大小相等。
知识点:
- 二维数组是存储一维数组的一维数组。在书写两个[]时要遵循先行后列的原则。并且可以不写行数,计算机会根据列数与成员数量自动划分行数,但是列数一定要写。
- 二维数组名代表数组第0行的地址。
- 多维数组的空间访问原理?
答:我认为他就是一个嵌套寻找空间的过程,就是不断利用*(参考地址+偏移)这个公式来逐层寻找空间。如果是访问三维数组中某一成员的空间,那么就是三层嵌套,第一层先利用数组名加偏移找到某一个平面的地址,对他*操作后得到这个平面的空间,再利用这个空间加偏移找到这个平面中某一行的地址,*操作后得到这行的空间,最后利用得到的这个行空间加偏移找到某一个成员的地址,对整体*操作后就可以得到这个三维数组中某个成员的空间了。
十三、大端存储-小端存储

图片知识点解析:
这里我们定义一个int类型的变量,他在内存中所占的空间为4个字节,因为内存中一般以16进制存储。我们知道,两个16进制就相当于8个2进制位,也就是1个字节,所以4个字节就i相当于8个16进制。所以这个9的16进制就是00 00 00 09.那么无论是大端存储还是小端存储,他的左边都是低地址,右边都是高地址。如果是大端存储,那么就是低地址存储高位,高地址存储低位,这与我们平时的思维很像,它通常用于数据传输,而小端存储则与其相反,它是低地址存储低位,高地址存储高位,通常用于内存存储。那么我们如何验证内存存储是否是小端存储呢?我们可以通过定义一个整型1,并且将它的地址强转成字符型指针,然后赋值给char类型的指针p,如果此时p指向的空间为1,则可以证明存储方式是小端存储。
十四、函数在源代码中的三种状态

图片知识点解析:
函数的三种状态包括声明状态,定义状态和调用状态、要定义一个函数,他首先需要有返回值类型,然后加上函数名和括号,括号中写上要定义的形参,再加上{},最后在{}中写入流程结构。在声明函数时,就是将{}和其中的内容去掉,再加上;,如果函数没有进行前置声明,那么就会出现重定义的语法错误。再调用函数时,我们只需在()中写入实参,就可以将实参传入形参,即可进行函数的调用。在我们自定义函数时,最佳的顺序就是先对我们设计好的函数进行声明,然后将调用函数写入到程序中,看逻辑是否正确,最后按照我们的需求对函数进行定义,书写函数的流程结构。
十五、堆区与栈区的区别

知识点:
- 内存区域通常分为5大区域,分别是存储函数的代码区,存储不变常量的常数区,存储全局变量和静态static变量的全局/静态区,还有堆区和栈区。通常来讲,代码区是低地址的,栈区是高地址的。
- 一般临时性的局部变量会存放在栈区,在调用函数时会在栈中创建出临时变量,在执行完毕后会自动回收掉。一般更长久的变量会存放在堆区,并且需要手动回收。
- 从空间大小来看,堆区的空间较大,栈区的空间较小。生长方向他们是相向生长的。分配方式和管理方式:栈区是自动分配和自动回收的。而堆区是手动分配和手动回收的。从分配效率来看,栈区是在调用函数的时候直接自动分配出来的;而堆区是要执行malloc或calloc时分配的,也就相当于手动分配,所以栈区的效率更高。堆区可能会产生碎片,所以需要手动进行回收,而栈区则不会。
- 堆区如果不释放会产生碎片,在堆积到一定程度时可能会导致程序崩溃,所以我们通常会在栈区创建一个指针,来指向堆区中内容的地址。在使用后通过free指针来进行空间释放,并且要使指针指向空(NULL),避免后续的操作问题。
十六、函数的执行原理

图片知识点讲解:
从宏观来看,函数的执行就像阿拉丁神灯一样,在我们调用执行的时候他就会出现,执行完毕就会消失。
从微观来看,在我们执行一个程序时,main函数会首先入栈,之后调用哪个函数哪个函数就入栈,执行完毕后就会pop弹出。这里遵循一个先进后出,后进先出的原则。那么在调用函数时,我们会将局部变量(也就是形式参数和声明变量)存放在栈区,在函数结束调用后会自动回收。
函数名实际就是个地址, 也就是说他代表函数在代码区上的地址,既然是个地址,那么我们就可以创建一个指针来指向它、调用它。所以我们在栈区创建一个要指向函数类型的指针,并指向它,在这里我们要注意的是,我们在指向它时有两种方式,一种是显示方式:就是用p(指针)指向&函数名,那么在调用时就要用(*p)(实参)来调用,另一种方式是隐式方式:也就是直接用指针指向函数名,那么在调用时则可以直接用指针加(实参)来调用。因为第二种方式比较简洁明了,所以在调用执行函数时我们通常选择隐式方式。
十七、枚举类型

图片知识点解析:
枚举类型的全称是enumeration,我们在使用的时候就用enum,它是一种扩展类型,在这之前我们学习过数组,并且在以后还会学到struct结构体以及union联合体。enum可以对数据类型进行扩展,创建自定义的类型,但这个类型的值一定是固定有限的。比如生肖、血型或是方向。他的格式是enum 枚举名称 {内容1,内容2......};他在创建时,会默认给内容赋上编码,从0开始。我们也可以通过内容=整数来手动编码,但编码本身无意义,只是为了增强可读性。在使用我们创建的类型时,格式为:enum 枚举名称 变量名 = 值;enum最主要的功能就是增强代码的可读性。
十八、typedef

图片知识点解析:
type是类型的意思,define是定义,那么typedef就是对类型的重新命名,定义一个新的类型。他的基本格式是typedef+现有类型名+自定义名称。比如图中左侧,将COVID-19重命名为新“新冠”,但是无论是COVID-19还是新冠,指的都是同一种东西。那么我们要想对函数指针或数组指针重命名,我们只需在表达式前面加上typedef,并且将原来的变量名换成自定义名称即可。那么什么是嵌套定义呢,比如说我们先将int类型重定义为Integer,再将Integer重命名为Integer INT,然后还可以将Integer INT在重命名为INT MYint,但是无论多少次重命名,这些自定义类型的本质都是int类型。
模板: typedef 现有类型名 自定义名称
二十、const

图片知识点解析:
const就像是一把锁,如果在定义时表达式前面加上了const,那么所定义的变量就会变为只读状态。在做项目时,我们如果不想让用户改变某个变量的值,那么我们就会在定义变量时加上const。const在指针上的用法有三种,如果在*和p前面都加上const,就相当于将指针锁住并且将它指向的地址也锁住,也就是指向不可改,内容也不可改。如果只在*前面加const,就是将指向的地址锁住,就是指向可改,内容不可改。要是只在p前面加上const,那么就是将指针锁住,但仍可以通过*p改变他指向的空间,也就是指向不可改,内容可改。
- 作用:修饰一个变量使之成为常量。
- 要求:必须初始化。
二十一、全局/局部变量生命周期与作用域
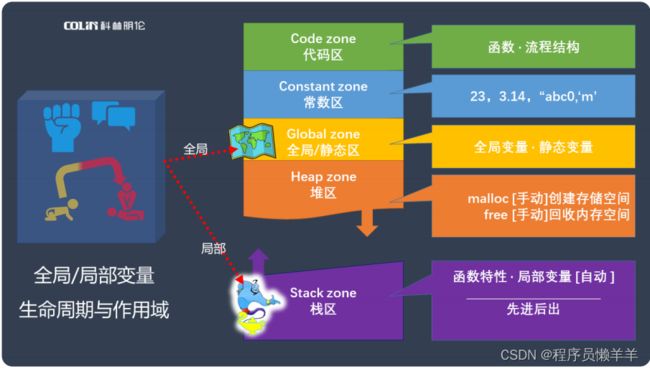
图片知识点解析:
全局变量是在函数外定义的变量,它会被分配到全局/静态区,它的作用域是整个项目内,在项目内任何位置都可以通过extern来对它进行引用,但切记不可以二次赋值,它的生命周期是整个项目 开始到结束。局部变量就是定义在函数内的变量,它会存放在栈区,它的生命周期是从函数入栈到弹出,作用域是所在函数内。当全局变量与局部变量重名时,不会出现重定义的语法错误,而是会将全局变量屏蔽,这里遵循一个临近原则。
二十二、static静态变量
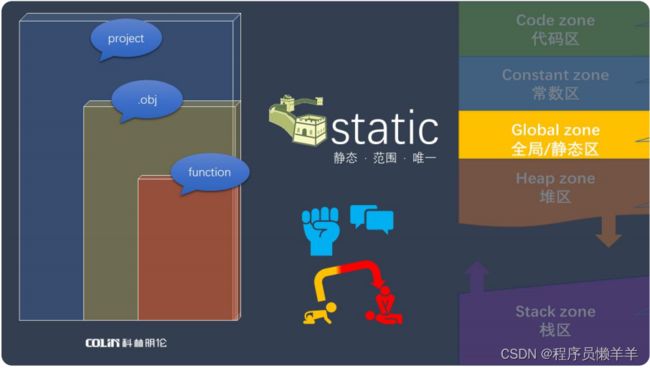
图片知识点解析:
static所定义的是静态唯一变量,他所定义的变量会被存放在全局/静态区。static变量的值只能初始化一次,如果未进行初始值,系统会自动为其赋值0。当我们在调用函数时,函数内的变量会随着执行结束弹出而被栈区自动回收掉,但如果定义的变量为static变量,他将不会被回收。所以他的生命周期是程序开始运行到结束。它的作用域是定义所在的位置,如果是在项目中定义,它的作用域就是整个项目;如果实在目标文件那么作用域就是所在目标文件;如果实在某个函数内定义,那作用域就是这个函数。比如说我们在定义一个全局变量时,在前面加上了static,使其成为了静态全局变量,那么他就是当前源代码的全局变量,不可以在其他源代码中通过extern来引用。
static 理解为局部内的 唯一变量 相当于全局,但全局不可访问
二十三、extern

图片知识点解析:
extern就是外部变量链接,它用于声明来自外部的变量,它可以将全局/静态区中的全局变量在外部进行声明,然后所声明的位置就可以使用被声明的变量了,在声明时要注意的是只能声明,不能赋值定义,否则就会出现重定义的语法错误。所以他的格式是extern 数据类型 变量名; 切记extern声明的变量不能赋值,有extern没赋值,有赋值没extern。
二十四、宏define

图片知识点解析:
define就是宏替换,宏是整体的意思,那么宏替换就是整体替换,它发生在预处理期,它有两种替换方式。一种是#define 宏名 替换内容,这是内容没有可变部位的方式,而如果内容中有可变的部位,他就是#define 宏名(可变部位) 内容模板,其中包括可变部位和不变内容,可变的一般为数组名或数据类型。它也可以进行宏的嵌套定义,将D替换为C,将C替换为B,再将B换成A。宏替换最大的意义也是增强代码的可读性。它是一个纯复制粘贴的过程,而typedef是真正的重新命名,定义了一个新的类型。
二十五、字符串原理

图片知识点解析:
首先来看字符,字符用char来表示,他代表1个字节的字符,只能表示ASCII码值,不能表示汉字字符,他的赋值方式可以是影像赋值,也可以是十进制、八进制或是十六进制的形式。它存储的是字符的编码,并以影像的方式呈现出来。
那么字符数组和字符串有什么区别呢?首先他们都是表示若干个字符的组合,但是字符串要有字符的结束标记'\0',有了'\0'的字符数组才能叫作字符串,但是我们手动来赋'\0'太过于麻烦,所以我们在定义字符串时通常用" "来初始化,因为他会在字符串的结尾自动赋上'\0'(注意'\0'也会占一个字符空间),那么在初始化后我们将这个字符数组称之为字符串,将" "中的内容称之为字符串常量。只要是常量,就会放在常数区。在代码中,字符串常量可以理解为一个地址,就是字符串所在常量区的首地址。
由于str1[]是局部变量,所以会在栈区被创建,在初始化时,后面的字符串会被在常数区先创建出来,而后在栈区对其进行复制。p1和p2也在栈区被创建,由于Hello\0之前已经在常数区被创建出来了,所以p1、p2可以直接来指向Hello\0。
在这里面,我们尤其要搞懂哪些值是常量,先来看左下角这几个bug出在哪里。由于p1和p2是指向常数区的地址,所以用指针当作数组名不可以对他的成员进行更改,只可以改变指针的指向,这里就像const *p一样,指针的指向可改而指向的内容不可以改。下面这个错误是因为str1是数组名,而我们知道数组名是地址常量,并且右面的内容是字符串常量,将一个常量赋给另一个常量,会出现左值不可更改的错误。但是由于str1创建的字符串是在栈区内,所以它的成员的值是可以被修改的。
二十六、struct与union结构体联合体

图片知识点:
- 扩展类型包括我们学过的数组和enum枚举类型还有即将要学的struct结构体和union联合体。
- struct与union的区别?
答:struct是存储多个类型对象的内存块,并且这些对象不重叠。而union是一块内存,他的大小等于数据对象最大的空间大小,他的对象会重叠,因此在任何时候只能存储一个数据对象。struct占用的内存大小等于所有成员占用的内存总和,而union占用的内存大小等于他成员占用最大的内存大小。
- 结构体对齐补齐指什么及意义?
答:在结构体创建时会有一个对齐不齐的准则,他会选出所使用的数据类型中字节数最大的类型作为标准,并以它的字节数为一个单位,在创建空间时,如果某类型小于单位剩余字节数,那可以直接将这个类型在该单位的空间中创建,如果大于剩余字节数,那么就会再创建一个单位空间对其进行存储。要注意的是,数组的字节数是以它其中一个成员的字节数为标准的。对齐补齐的意义就是可以节省空间,提高空间使用效率。比如图中这个,这些数据类型最大字节数为4,所以一个单位空间就是四个字节,那么我们可以看到第二排剩余一个字节的空间,而最后一排只使用一个字节,如果将最后一排的char类型放在第二排进行创建,那么就会节省四个字节的空间。
- union联合体使用时要注意每个时间只有一个成员在使用空间。
二十七、链式存储与顺序存储

图片知识点:
- 线性表是具有n个相同特性的数据元素的有限序列,他的数据结构包括链式存储和顺序存储。
- 顺序存储就是把线性表中的所有元素按照某种逻辑顺序,依次存储到从指定位置开始的一块连续的存储空间,比如我们学过的数组就是顺序存储。他的优点是可以快速的查找出表中任意位置的元素,缺点是插入和删除操作中需要移动大量的元素,那么效率就会很低。
- 链式存储又称为链表,他用一组任意存储单元存储线性表中的数据元素,包括数据域和指针域,数据域存数据,指针域指示其后继的信息。他的优点是插入和删除很方便,只需要修改数据邻节点的指向即可,缺点是查询代价较高,在查询任一元素时都需要从头节点开始遍历。
二十八、文件处理模型
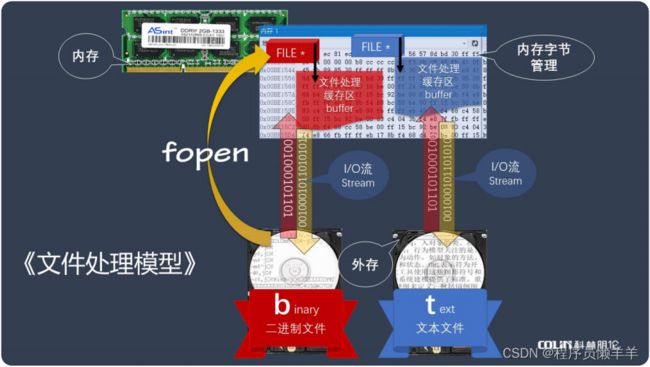
图片知识点:
- 内存存储属于临时存储,如果不保存就会丢失,存储速度较快但存储容量较小,而外存存储属于长期存储,存储速度较慢但是容量较大。
- 文件存储类别包括二进制文件和文本文件,二进制文件是按照数据在内存中存储的原样存放的,而文本文件时通过字符编码进行存储。因此二进制文件的存储效率更高。
- fopen函数在内存中开辟一个文件处理缓存区,我们可以定义一个文件类型的指针(FILE*)来指向缓存区,通用对缓存区的操作实现对内存中文件的读写和修改。我们通过fopen函数打开文件流,再通过fclose函数关闭文件流。
二十九、文件复制原理
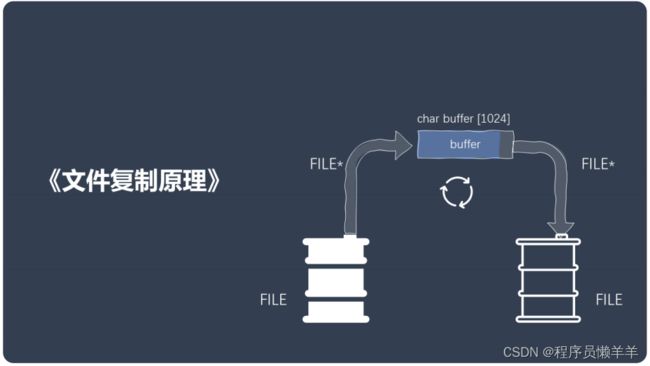
图片知识点解析:
文件复制我们先用fopen函数打开被复制文件和目标文件的缓冲区,在创建from和to两个文件类型的指针指向他们,我们还需创建一个buffer数组来当作中间的缓冲区。而后我们通过fread函数将在被复制文件中的数据先读到buffer数组中,然后再通过fwrite函数将buffer数组中的数据写入到目标文件,直至被复制文件内的光标到达尾部。
三十、组件化技术分类

图片知识点解析:
静态库需要放到项目中,他会跟随项目一同打包为exe文件,所以如果exe用到的组件较多,那么他的文件体积会很大,并且每个程序的代码区都会有一份静态库,会造成空间浪费。他还不易更新,在更新时要将所有程序都更新一遍,他的优点就是移植方便。动态链接库是独立在exe外边的,它属于资源共享,谁想用谁就调用它即可,并且升级也很简单,只要更新自己就行,因为不需要打包在exe文件内,所以文件体积也会较小。