微服务回归单体,代码行数减少75%,性能提升1300%
 # 关注并星标腾讯云开发者
# 关注并星标腾讯云开发者
# 每周3 | 谈谈我在腾讯的架构设计经验
# 第5期 | 李浩津:13倍性能重构:搜索内容架构 C++微服务群改造


内容架构是 QQ 浏览器搜索的内容接入和计算层,主要负责腾讯域内的内容接入和处理,当前接入了多个合作方的上千类内容。正如前面《如何避免旧代码成包袱?5步教你接手别人的系统》中提到,这是一套包含 93 个小服务的微服务架构。经过 23 年 Q1 的大力治理,让我们稳住阵脚,进一步对老系统做深入的评估:
▶︎ 研发效率较低:新增一类数据需要在 3~4 个服务上做开发,代码量不多,但很繁琐。
▶︎ 系统性能较差:数据流经多个小服务,且服务内部的实现普遍较差。譬如:核心服务的 CPU 最高只能用到 40%、一条消息从进入到流出需要经过 20 多次的反复 JSON 解析、多处存在多余的字符串拷贝和查找...
从架构和代码层面,我们看到系统存在较多的缺陷,同时我们也多次收到业务同学、上层领导对吞吐性能的投诉反馈,譬如:传输 6 亿的文档需要 12 天,太慢了;内容接入周期太长,成了某项目的瓶颈等等。
作为偏后方的基础架构系统,可靠高效是基本要求, 我们决定对系统做彻底的改造,设计简单的系统、写清晰的代码,提升系统性能和研发效率,为搜索业务提供稳定高效服务。

内容架构主要做内容的接入和计算,支持的内容类型非常多,由于旧系统过度微服务化,且缺乏插件复用设计,使得需求开发人力较高,同时也存在性能缺陷、容灾不足等严重架构缺陷。新系统基于“零基思考”,重新规划设计,架构层面聚焦下面 5 个点:
▶︎ 微服务和单体服务:旧系统由多个细碎的小服务组成,RPC 交互消耗很大,结合“处理量大、计算量小、失败容忍度低”的业务场景,新系统采用单体服务设计,数据在内存间流动,减少消耗。
▶︎ 插件系统:面对繁杂多样的处理流程,旧系统没有插件化设计,代码里全是“if-else”逻辑;新系统我们使用插件化的设计,灵活支持业务需求。
▶︎ 兼顾增量和批量(刷库):老系统应对批量数据处理(刷库)流程非常乏力,没有做流程拆分,使得刷库性能较差;新系统可以为刷库场景做定制化配置,大幅度提升刷库性能。
▶︎ 故障容灾:旧架构几乎没有考虑容器迁移时的数据保障,新架构结合消息中间件实现流量削峰和消息缓存,实现故障时数据不丢。
▶︎ 水平扩容:老系统的消费和计算没有分离,使得 CPU 最高只能用到 40%,且无法水平扩容;新系统将消费线程与处理线程分离,大幅提升单机处理性能,也能水平扩容。
旧系统设计:
新系统设计:


从微服务到单体服务
十多年来微服务在后台系统大行其道,我们接手的老系统也是微服务设计,那么我们要继续微服务吗?
首先来看我们业务的特点:
▶︎ 处理量大:每天有几十亿次内容新增/更新。
▶︎ 计算量小:内容架构主要做接入和计算调度,计算量主要在下游的算子服务或者工厂。
▶︎ 失败容忍度低:内容丢失便无法被搜索到,不能容忍内容丢失。
▶︎ 内容类别多:已有上千种类型,还在持续增加。
▶︎ 需求小且类别单一:所有的需求都是新内容源接入,需求类型较固定。
再来看老系统的设计,以接入系统为例,内网推送、公网推送、HTTP/Kafka 拉取这四类接入的实现,分散在四个服务上,再经过统一接入代理服务、数据处理服务、分发服务处理,一个条内容数据需 6 次 RPC 交互。在实践中带来这些问题:
▶︎ 需要更复杂的容错处理:首先微服务群需要考虑超时时间合理分配;然后每一个微服务都需要考虑失败重试、重试雪崩等容错处理,复杂度随微服务个数成倍数增长。几十亿文档处理叠加上多个微服务,稍有不慎就会导致海量告警轰炸,甚至出现数据丢失。
▶︎ 需求迭代慢:一个需求一般由一个人承接,需要改动多个微服务,整体代码量不多,但分散在多个服务中。
▶︎ 计算浪费:内容数据在多个服务中流动,需要反复地做序列化和反序列化,而服务本身有价值的处理主要是字段转换、简单字符串处理等轻量计算,框架带来的计算消耗比本职计算还高。
最后,我们的新架构采用单体服务设计,在容错处理、迭代效率、计算量等方面都取得不错的效果(见文末数据指标)。
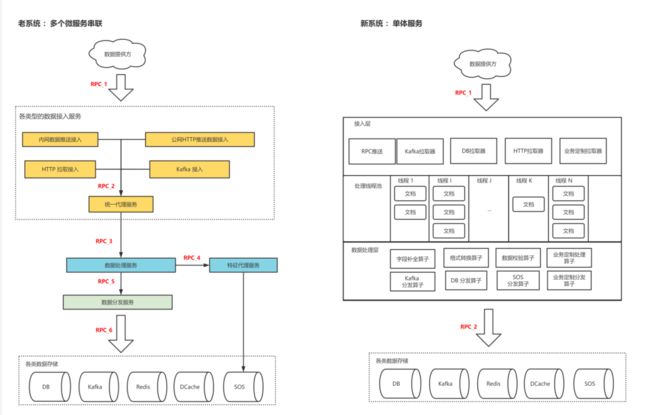
(内容接入系统新老架构对比图)
接入处理流程插件化
内容接入系统需要处理上千类内容,不同的内容通常来自不同的团队,各个团队都有一套对外输出内容的标准协议,因此内容接入系统需要编写大量的对接适配代码,如何更轻便地实现新内容接入,是我们重点关注的。
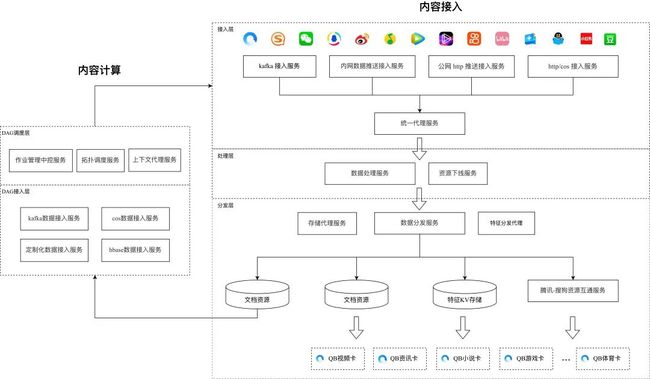
如设计图所示,我们的业务功能整体分为三层:接入层,处理层,分发层。
在接入层,我们需要处理多种途径接入的多种数据格式。途径包括:DB 定时拉取、Kafka 流式拉取、HTTP/COS 拉取、RPC 拉取等;数据格式也多种多样,每个数据方提供的数据格式各不相同。以 Kafka 拉取类接入为例,小说业务推送的是 JSON 格式数据,而小程序业务推送的是 PB 序列化的二进制字节流。
在处理层,不同的业务我们要执行不同的格式校验;有的业务收到数据后,需要再请求其他服务以补全特定属性;有的业务需要我们执行一些字段格式转换;有的业务需要我们对数据中的值进行定制化修改。
在分发层,每个业务要分发的目的地也不同:有的业务只需发往 Kafka,有的业务需要存入 DB、 Redis、DCache 等,有的业务需发送 HTTP / RPC 请求至特定服务通知更新。其中,Kafka 的 Topic、 DB 的存储表、目标服务的地址、协议也各有不同。
面对这样复杂的业务功能,老系统建设了一套数据处理流程,然后在主流程中通过 if-else 判断来走不同的处理流程,可以明显看到“堆代码”的痕迹,其源码组织的清晰度、功能的可插拔性都较差。
在新的接入系统中,我们将接入、处理、分发中的各个关键功能点实现为插件架构,每一个子功能都是一个插件,同时按照业务粒度的处理流配置组合使用插件。
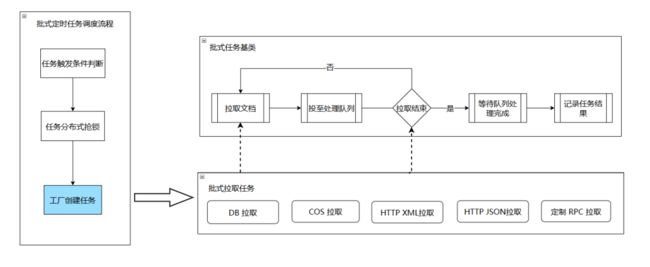
例:批式接入任务执行流程
例:文档处理流程
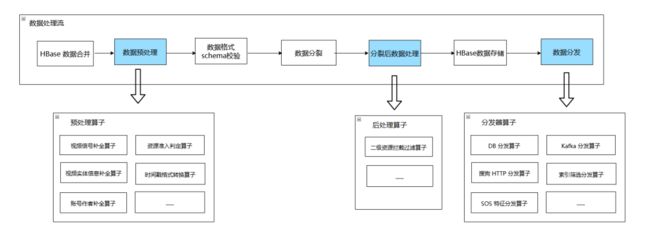
当有新增的定制化业务需求时,我们只需要在相关环节增加插件,开发插件时,只需实现关键函数,如拉取任务插件只需实现拉取和拉取任务是否结束这两个接口。分发插件只需要实现分发逻辑;其余部分在框架层实现并统一调度,开发者无需了解。如果新业务只用到现有的功能,我们则只需要在 DB 中配置插件组合序列,无需代码开发。
通过此插件化设计,让业务接入更轻便,大幅降低业务需求的 LeadTime(见文末数据指标)。另外,老系统在各服务代码中各种硬编码 if 业务 ID == 指定 ID,则执行/不执行指定逻辑,排查业务问题时需要跨多个服务看代码,效率极低。而新系统只看配置便可清楚了解一个业务的接入处理全流程执行过程,极大地提升了运维排查效率。
兼顾增量更新和批量刷库
接入系统经常收到“刷库”类的需求:将指定业务的全部数据经过某个处理后发给某个指定下游。因老系统没有插件化设计,在组件组合使用上缺乏弹性,使得刷库需求不得不通过增量更新流程满足,因而做了大量无效计算。
新系统兼顾增量更新和批量刷库。我们结合接入系统的输入特点,将数据流配置分为了四种:数据源更新处理流、特征更新处理流、数据源刷库处理流和特征刷库处理流。
在数据源/特征更新的处理流中,我们需要配置业务线上数据处理的各类算子及分发算子。而在刷库处理流中,数据来源于我们的底表 HBase ,实际未发生变更,不需要重新计算。并且,在常见的刷库场景中,一个业务数据正常更新时需要分发给多个下游,刷库时只有部分下游需要重刷,此时我们只需要配置目标地的分发算子即可。
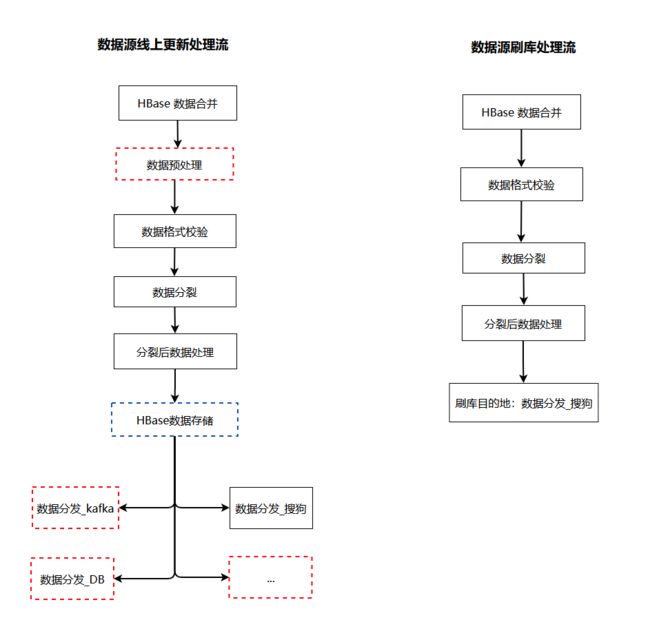
通过区分四类处理场景的数据处理配置,同一个业务在正常处理时和刷库时,新接入系统可执行不同的数据处理流,进而移除了刷库场景下的不必要计算和分发逻辑,单核刷库 QPS 提升了 16 倍。
数据接入服务故障容灾
数据不丢是内容架构的核心指标,无论数据是怎么来的,只要进入了我们系统,就应该保证不丢失。
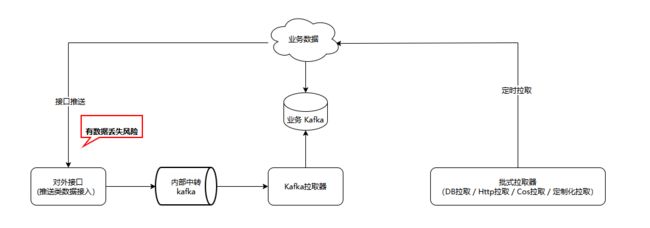
接入系统的各类接入方式可归为三类:接口推送类、Kafka 通道类和定时任务批式拉取类。这三类接入方式中,Kafka 通道类自带数据备份,数据未处理完时不执行 Offset Commit,即可保证该数据不会丢失;批式定时拉取类的任务是可重入的,若拉取任务运行过程中进程退出,新节点重启任务即可恢复,数据不会丢失;只有接口推送类的数据可能在进程退出时未处理完,导致丢数据。
老系统对接口推送类数据没有做任何的保护,也就意味着进程异常退出、容器故障迁移等接入服务故障场景没有有效处理,数据可能丢失。
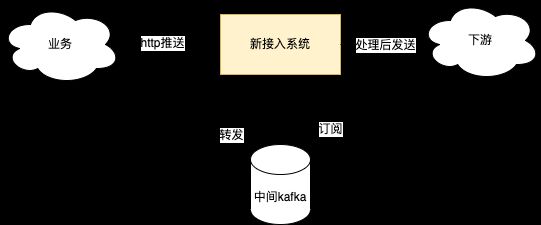
我们在新架构上增加了消息中间件 Kafka 实现数据容灾。对于 HTTP / trpc 接口推送进来的更新数据,接口层直接将其发进 Kafka,并返回给业务成功。此中间 Kafka 由指定的分区 (set) 进行异步消费处理,消息处理完成后才会执行 Offset Commit。如在消费处理过程中,部分节点进程崩溃/退出,其他健康节点会通过接手消费处理对应分区的文档消息,最大限度保证数据不会丢失,同时消息中间件也带来削峰的效果。
消费与处理线程分离
老接入系统处理性能较差的重要原因在于:未将 Kafka 消费和文档处理线程分离。某业务配置 N 个线程处理,则这些线程先从 Kafka 拉取文档,再按照配置执行各环节的处理,处理完一批消息再去 Kafka 拉取,消费线程同时是处理线程,重计算的业务无法充分利用 CPU。同时,一个 Kafka 分区最多只能被一个线程消费,集群最大处理并发数受限于 Kafka 总分区数,无法实现水平扩容。
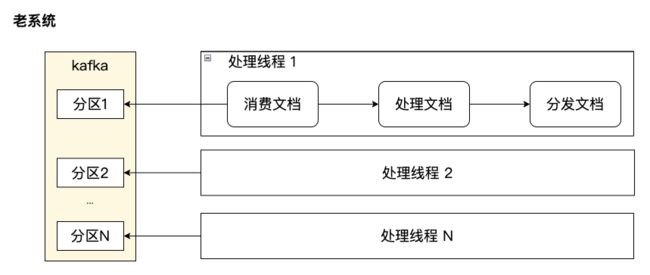
新系统设计了一个基于无锁队列的文档计算工作线程池,每个 Kafka 分区可以被一个线程消费,并被多个计算线程处理。通过消费和计算线程分离,充分利用 CPU,大幅提高了 CPU 利用率和处理性能。同时,计算线程数量不再局限于 Kafka 总分区数量,可以水平扩容。


整个系统有 15 种分发出口,这些出口分散在老系统的多个服务。如果基于机器本地日志去比较 diff,显然零散且费力。因此,我们搭建了一个 diff 校验服务。同时,在多个服务的分发出口进行埋点,并上报分发内容至 diff 校验服务,从而对分散的 diff 日志进行统一收集并分析。整个数据流如下所示:

比较 diff 的过程中,我们发现分发数据格式复杂,存在多种类型。例如,分发数据 Json Member Value 为一个 JSON 字符串,而 JSON 字符串 Member 的顺序是不固定的。为解决该问题,我们实现了一个递归的 JSON 对比工具,来校验多种类型数据的 diff。

更少的代码
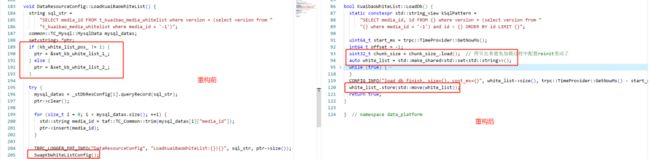
表驱动编程。如下图所示,重构后使用数据遍历替代冗长的 if 判断。

针对数据动态加载,使用 C++20 的std::atomic
更高的性能
用迭代器代替查找和括号取值。RapidJSON 的查找和中括号取值都需要遍历 member list,对于先查找后中括号取值的场景,可以先保存查找 member 获得的迭代器,然后通过迭代器来获取 member value,减少一次 member list 的遍历。
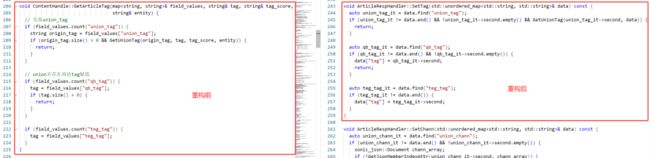
减少 JSON 反序列化。老代码的函数参数是 JSON 序列化后的 string, JSON 对象需要反复的反序列化和序列化,存在性能浪费。我们重构后,将需要多轮处理的 JSON 数据定义成 rapidjson::Document 对象并置于上下文中,消除了反复的序列化和反序列化。这不仅能提升数据处理的性能,还能减少重复的解析 JSON 代码片段。

更好的基础库
修复 rapidjson::Document 引发的内存泄漏假象,降低内存使用。为了减少重复解析,我们在 DB 拉取模块拉取到字符串后,就将其解析为 rapidjson::Document,然后存起来。
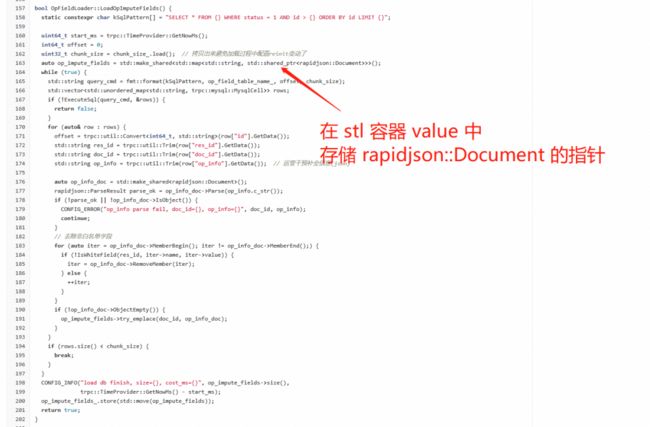
然而,执行上述优化后,我们发现 DB 每加载一轮,容器的内存就会显著上涨一截,加载 5-6 轮后,进程内存用满,发生 OOM。经过 Valgrind 工具分析和本地多种测试,我们确定实际内存未泄露,内存不断上涨是因为:使用 RapidJSON 基于内存池 MemoryPoolAllocator 分配器构造 Document 对象,在对象释放后,空闲内存不会立刻归还给操作系统。
系统分析后发现这和 RapidJSON 没有关系,是操作系统的内存策略设计如此。对此类内存释放不及时的问题,我们调研发现有两种解决方案:
▶︎ 在服务启动时用 mallocopt(M_TRIM_THRESHOLD) 调低内存释放阈值,并在对象释放后,调用 malloc_trim(0) 强制其释放内存;
▶︎ 通过过引入 jemalloc 等内存分配器。本项目采用链接 jemalloc 库解决。
此外,我们还引入开源的 Sonic-JSON 库。基于我们内容数据的评测,Sonic-JSON 比 RapidJSON 快 40%,因此我们引入了 Sonic-JSON 代替 RapidJSON ,在新接入系统的压测中显示,Sonic-JSON 可以提升 15% 的吞吐,或者降低 17% 的 CPU 开销。
更好的可读性
函数遵循单一职责原则。如下图所示,针对不同的订阅类型,老代码中职责不清晰,在函数中通过 if 判断来使得不同的订阅类型走不同的特殊处理逻辑。重构后,我们使用多态设计,不同的订阅类型派生类继承基础类,并针对自己的特殊逻辑进行泛化,从而使得每一个类只处理一种订阅类型。

将 switch-case 转换为工厂。如下图所示,应用插件设计和查表法,提高代码的可维护性和扩展性。

插件化和配置化。功能组件可以自由组合,从而避免频繁出现 trick 代码。如下图所示,在老代码中,通过硬编码实现对指定资源类型做指定的处理。重构后,不同资源可配置不同的处理流程,实现功能热插拔和组件复用。


整体流程
研发流程上,我们沿用开发搜索中台技术产品时积累的 CICD 建设经验,包括以下措施:
▶︎ 需求确认和启动,约定 TAPD 必填字段、TAPD 扭转流程。
▶︎ 开发者资质,只有获得开发者资质认证,才能输出生产线代码。
▶︎ 编码和注释规范,统一采用腾讯编码规范和 doxygen 注释。
▶︎ 代码评审,制定可按步骤执行的流程,并提供学习案例。
▶︎ 基础库规则,统一第三方库、工具库使用规范,消除项目依赖混乱。
▶︎ 流水线,统一 MR 模板,严格约束静态代码质量检查红线、单测覆盖红线等。
▶︎ 版本规范,统一版本命名和使用规范:MAJOR.MINOR.PATCH。
▶︎ 发布流程,腾讯域采用 XAC 发布。
需求管理
在需求规划时,我们按大模块(或功能)划分大需求(EPIC),并把大需求分发给不同的开发人员。开发人员在梳理出模块的详细实现后,再自行划分出不同的小需求(feature),并调整对应的开发耗时。开发过程中使用甘特图,可以方便确定项目开发进度。
多人协作,难免会出现工作量分布不均匀或者需要延长工期,所以我们在每周三早上有一个十几分钟的晨会:确定需求进展,可能风险则及时调整开发人力,保障团队目标达成。

代码评审
代码质量对项目的长期发展有至关重要。我们团队要求每位开发者都必须通过代码安全考试和规范考试,生产线的每一行代码都需要经过 CR,同时鼓励全员提升代码品味,写出一手好代码。这里推荐一篇腾讯技术 Leader 总结的 Code Review 指南,非常有参考性:《腾讯 13 年,我所总结的 Code Review 终极大法》
文档协同
文档可以跨越时间限制,是一种高效的异步沟通工具。在接手内容架构系统后,我们补充了大量文档,包括资源接入现状、系统链路、日常运维和各种排查文档,为稳定性维护提供了重要保障。
在系统重构过程中,我们也积累了各类文档,存放在小组各个方向目录中。同时在代码仓库里,一些复杂的业务逻辑或者复杂的模块,目录下维护着 README.md,说明模块功能、设计、实现和使用方法。

流水线加速
蓝盾流水线是实现 CICD (持续集成持续部署) 的核心工具,我们在代码发起 MR 后设置了MR流水线,代码合入主干后设置了主干构建流水线。
MR 流水线是代码开始 CR 前必须通过的红线,所以 MR 流水线的执行耗时会影响到整个 MR 耗时和需求开发耗时。针对重构期间多人协作出现大量并发检查任务,以及对流水线关键路径的耗时分析,我们做了如下优化。
减小流水线锁粒度
MR 流水线包含了代码安全扫描、代码规范扫描、单元测试、接口测试等多个步骤。接口测试需要共享特性环境作为部署和测试环境,存在资源竞争。之前限制整个流水线只能有一个构建在执行,其他都要等待。通过配置蓝盾流水线模板的互斥组,可以实现 stage 级别的锁,多个构建可以并行执行,仅接口测试 stage 互斥,使得流水线构建可以加快 25% 以上 。

使用 GitHub 镜像提速
我们有一个公共仓库专门存放各类外部依赖,通过 genrule 生成可被 bazel 直接导入的规则,外部依赖需要通过 tar 或者 git 获取源码数据。在实际执行过程中,发现部分外部依赖拉取异常缓慢,卡在 analyzing 步骤,甚至造成编译失败。在分析 log 后发现部分含有二进制依赖的第三方库,直接从 GitHub 拉取会 QPS 出现卡顿,因此我们修改了 bazel genrule 的生成规则,全部使用镜像代理。实测中,发现部分任务卡顿会超过 3 分钟,优化后不再卡顿。

性能收益
性能提升指标概览
内容接入系统:
| 指标 | 改造前 | 改造后 | 对比 |
| 平均单核处理 QPS | 13 | 172 | 提升 13 倍 |
| 平均单核刷库 QPS | 13 | 230 | 提升 17 倍 |
| 集群刷库 QPS | 500~1000 | 10000(受限于外部存储) | 提升 10 倍 |
| 平均处理延迟 | 2.7 秒 | 0.8 秒 | 降低 71% |
| p99处理延迟 | 17 秒 | 1.9 秒 | 降低 88% |
| p999处理延迟 | 19 秒 | 3.7 秒 | 降低 80% |
| CPU 利用率 | 不超过40% | 可达到100% | 提升 2.5 倍 |
内容计算系统:
| 指标 | 改造前 | 改造后 | 对比 |
| 单核处理 QPS | 243 | 398 | 提升 64% |
| 平均处理延迟(含重试延迟) | 19 秒 | 2 秒 | 降低 89% |
| p99处理延迟(含重试延迟) | 91 秒 | 6 秒 | 降低 93% |
| p999处理延迟(含重试延迟) | 1166 秒 | 7.1 秒 | 降低 99% |
| CPU 利用率 | 最高 90% | 可达到 100% | 提升 10% |
处理性能 - 提升13倍
新系统单核性能从 13 QPS 提升到 172 QPS,处理性能提升了 13 倍。
以视频业务为例,旧接入系统处理峰值为 33465/min,总核数为 40 核,平均单核处理 QPS 为 13。

迁移到新接入系统后,处理峰值为 32119/min,总核数 6 核,平均单核处理 QPS 为 90。下图可以看到调大并发处理的线程数后,处理性能会等比例提升。当 CPU 压到 100% 时处理 QPS 峰值可达 162。

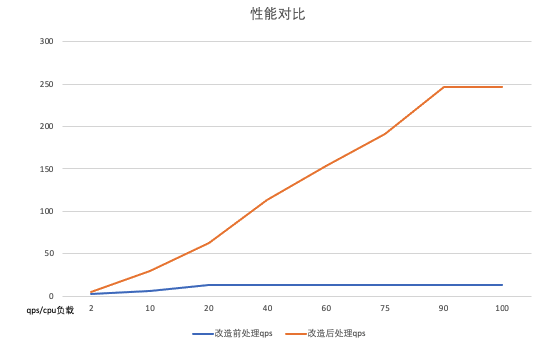
刷库性能 - 提升10倍
通过拆分增量数据更新、批量刷库的处理流,我们为刷库场景做定制化配置,大幅度提升刷库性能,集群刷库性能从 1000QPS 提升到 10000QPS(受限于外部存储性能),提升 10 倍。性能对比如下图所示:
处理延迟 - 降低70%+
平均处理延时从 2.7 秒降低到 0.8 秒。以视频业务为例,旧接入系统处理一条消息需要经过 5 个系统。每个子系统的性能又较差,p999 处理延迟达到十几秒。

新接入系统处理一条消息仅需经过 3 个,且系统性能较高,p999 处理延迟为秒级。
研发效率收益
研发效率提升指标概览
| 指标 | 改造前 | 改造后 | 对比 |
| 业务需求P80 leadtime | 5.72 天 | <= 1 天 | 降低 82% |
| 代码质量 - codecc 问题数 | 568 | 0 | 降低 100% |
| 代码质量 - 单测覆盖率 | 0 | 0.77 | 提升 77% |
| 代码质量 - 平均圈复杂度 | 24 | 2.31 | 降低 90% |
| 代码总行数 | 11.3 万行 | 2.8 万行 | 降低 75% |
| 关键链路服务数量 | 15 | 3 | 减少 80% |
业务需求 P80 leadtime - 下降82%
得益于代码质量提升、单测覆盖率提升、微服务合并为单体服务、插件化的设计,在新接入系统下开发新功能或者业务定制化功能,开发难度和开发成本大幅下降,从 5.72 天降低到 1 天。
代码总行数 - 减少75%
重构后,业务代码量从 11.3 万行降低到 2.8 万行,下降 75%。主要由下面几点带来:
▶︎ 微服务合并为单体服务。多个微服务小仓合并成大仓后,消除重复的功能代码。例如旧系统不同业务 Kafka 接入时,都拷贝了相同的一套实现。
▶︎ 优雅的系统设计。譬如:插件化设计,消除大量的 if-else;序列化对象传参代替字符串传参,消除大量的 JSON 解析。
▶︎ 现代 C++语法的大规模使用,让代码更精简,譬如:必要的 auto、for-range、emplace 等。
-End-
原创作者|QQ 浏览器搜索-基础架构组
微服务改造令你最头疼的点是什么?有什么比较好的解决方法吗?欢迎留言。我们将挑选一则最有意义的评论,为其留言者送出腾讯定制-毛毯1个(见下图)。9月6日中午12点开奖。

欢迎加入腾讯云开发者社群,社群专享券、大咖交流圈、第一手活动通知、限量鹅厂周边等你来~

(长按图片立即扫码)





关注并星标腾讯云开发者
第一时间看鹅厂架构设计经验