Muse: 谷歌基于Transformer的文生图模型
Overview
- Muse
-
- Summary
- Abstract
- 1.Introduction
- 2.Model
-
- 2.1.Pre-trained Text Encoders
- 2.2.Semantic Tokenization using VQGAN
- 2.3.Base Model
- 2.4.Super-Resolution Model
- 2.5.Decoder Finetuning
- 2.6.Variable Masking Rate
- 2.7. Classifier Free Guidance
- 2.8.Iterative Parallel Decoding at Inference
- 3.Results
-
- 3.1. Qualitative Performance
- 3.2 Quantitative Performance
-
- 3.2.1 HUMAN EVALUATION
- 3.2.2 INFERENCE SPEED
- 3.3. Image Editing
Muse
Summary
题目: Muse: Text-To-Image Generation via Masked Generative Transformers
机构:谷歌
论文: https://arxiv.org/pdf/2301.00704.pdf
代码:未开源代码 https://muse-model.github.io
任务: 文生图
特点:
方法:
前置相关工作:Imagen, VQ-GAN,MaskGit
Abstract
提出了Muse这样一种文生图的transformer结果,取得了SOTA的效果,但是相较于diffusion model和自回归模型效率更高,Muse利用离散token空间的掩码建模来进行训练,在给定文本特征(从预训练好的LLM提取)的条件下,Muse被训练用来预测随机掩码的图像token。相较于像素空间的扩散模型,比如Imagen / DALL-2,Muse就显得更加高效了,因为使用的是离散的token以及需要更少的采样步数,相较于自回归模型,比如Parti,Muse也是更加高效的,因为用到了并行解码。预训练的LLM的使用,让模型具备了细粒度语言理解的能力,并且转化为高保真度的图像,充分理解诸如:目标,空间关系,姿势,数量等视觉概念。900M参数的模型,在CC3M上取得了新的FID SOTA结果:6.06。3B参数的Muse模型在COCO上取得了7.88的zero-shot FID结果,CLIP score是0.32。Muse也具备不需要finetune或者invert模型,也能进行系列图像编辑的任务,比如inpainting, outpainting, mask-free editing等等。
1.Introduction
在这篇工作当中,提出了基于MaskGit的文本生成图像模型,其中图像decoder以预训练LLM(T5-XXL)的文本特征为条件。与Imagen一致的是,我们发现,如果想要生成逼真的,高质量的图像,预训练好的LLM是非常有必要的。所提出的Muse模型(除了VQ-GAN之外),都是基于Transformer结构来设计的。
我们训练了一系列大小的Muse模型,模型大小从632M到3B不等(主要是图像decoder的参数量变化),T5-XXL有额外的4.6B参数。每一个模型,都由一系列的子模块组成:
- VQ-GAN Tokenizer encoder/decoder,将一张输入的图像转化为一系列离散的tokens,并且将token序列反向解码为图像
- 两组VQ-GAN,一个处理256 × \times × 256的分辨率(“low-res”),另一个处理512 × \times × 512的分辨率(“high-res”)。
- 基础的掩码图像模型,这占据了模型主要的参数量,以一系列部分掩码的low-res的tokens为输入,然后基于unmasked的tokens以及T5-XXL的文本特征,来预测每一个masked token的边缘分布。
- 超分transformer模型,将(unmasked)的low-res的tokens转化为high-res的tokens,同样也是基于T5-XXL的文本特征。
相比于Imagen或者DALL-E2这些基于像素空间的扩散模型,由于Muse使用的是离散型的编码,所以效率上就会高不少,相较于自回归模型Parti,Muse由于使用了并行解码,也显得更加高效。在TPU-v4上进行测试,Muse比Imagen-3B和Parti-3B快10倍,比SD 1.4快3倍,所有的比较都是在相同的图像尺寸(224 × \times × 224或者 512 × \times × 512)上进行的,尽管与Stable Diffusion一样都是在隐空间上进行的,但是Muse依旧更快,可能的原因是SD 1.4在推理的时候,需要更多的迭代步数。
尽管效率更高,但并不意味着质量有所损失,在多种评价标准下,诸如CLIP得分(评价图文相关性),FID(评价图像质量和多样性), 3B的Muse模型在COCO zero-shot benchmark上取得了0.32的CLIP得分以及7.88的FID得分,在CC3M以及人类打分等benchmark或者评价方式上,也与各种对比方法进行了对比。
Muse的结果也反映了模型在名词,动词,形容词上的表现能力,也具备多目标理解能力(诸如组合,数量等概念)以及风格的理解能力,除此之外,还具备zero-shot的图像编辑能力,比如in-painting, out-painting,mask-free editing等。
主要贡献:
- 效果好,CLIP得分,FID等取得SOTA文生图效果
- 效率高,离散编码,并行解码
- zero-shot图像编辑能力
2.Model
模型的整体框架如下图所示:
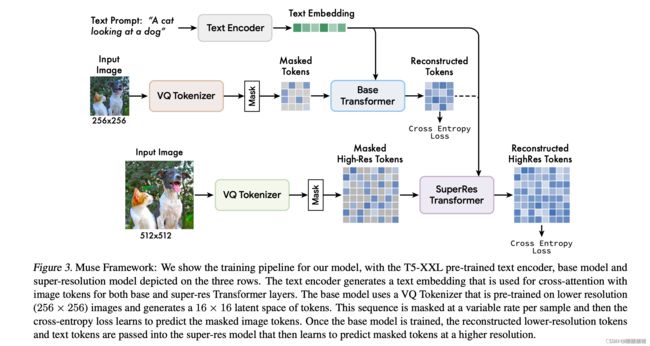
注意是先训练好base model,然后再训练超分model。
2.1.Pre-trained Text Encoders
对于给定的文本caption输入,将其经过冻住参数的T5-XXL,提取得到4096维度的特征,并且线性映射到base和super-res transformer对应的hidden size大小。
2.2.Semantic Tokenization using VQGAN
VQ-GAN的思路,这儿不赘叙,对于VQ-GAN里面的encoder和decoder模块,用全卷积来实现,用以支持不通的分辨率,给定一张H × W的输入图像,encoder进行下采样,编码的token尺寸是 H/f × W/f ,即下采样的倍率是f。训练了两个VQ-GAN模型,一个f=16,另一个f=8。对于base model而言,采用的是f=16,输入256×256的图像,能够得到的token的空间大小是16×16。对于超分模型,采用的是f=8,输入512×512的图像,能够得到的token的空间大小是64×64,这些离散的编码捕获的是高层语义而忽略浅层的噪声。并且用离散的编码形式,能够在预测掩码时,使用交叉墒损失。
2.3.Base Model
base model是一个masked trasformer结构,输入文本特征以及随机掩码部分图像tokens(将其替换为特殊的[MASK]token),在transformer的输出层,用一个MLP来将每一个掩码的特征转化为一系列的logits(与VQ-GAN的codebook尺寸一致),然后用gt的token label与logit算交叉熵。在训练的时候,base model在每一步同时预测所有的掩码token,但是在推理的时候,掩码的预测,是用一种迭代的方式来进行,这种操作,极大地提高了图像生成的质量。
2.4.Super-Resolution Model
我们发现直接预测512 × 512高分辨率的图像,会导致模型关注low-level的细节而不是语义,然而用一种级联的方式能有所裨益,一个base model生成16 × 16的latent map(与256 × 256 的图像相对应),然后接着一个超分模型,上采样base latent map到64 × 64的latent map(与512 × 512 的图像相对应)。在base model训练好之外,超分模型再进行训练。
超分模块学习将低分辨率的latent map翻译为高分辨率的latent map,具体实现的方式是,将text embedding信息和base latent map信息都concat,作为key, value,注入进cross-attention,得到high-res latent map,然后再解码为高分辨率的图像。
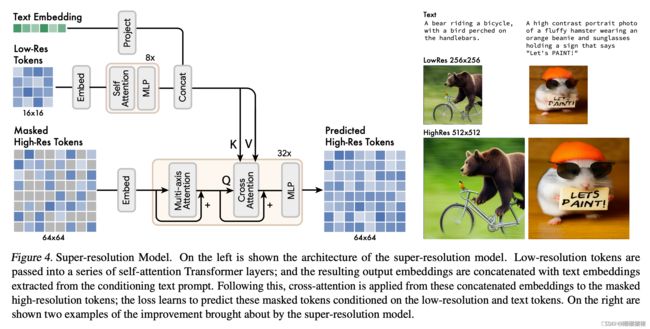
2.5.Decoder Finetuning
为了进一步提高模型生成细节的能力,我们增加了VQ-GAN decoder的能力,即保持encoder固定,但是让decoder增加额外的residual layer以及channels。然后finetune新的decoder layer,保持encoder, codebook和transformer(base model以及超分model)参数不变。这能够让我们在提高视觉质量的时候,却不必重新训练任何模型组件。
2.6.Variable Masking Rate
像MaskGit那样,我们用一种变量的掩码率来进行训练。对于一个训练样本,我们从从 p ( r ) = 2 π ( 1 − r 2 ) − 1 2 p(r)=\frac{2}{\pi} (1-r^2)^{-\frac{1}{2}} p(r)=π2(1−r2)−21分布中采样掩码率 r r r,其中 r ∈ [ 0 , 1 ] r\in[0,1] r∈[0,1],这个分布关于 r r r的期望是0.64,那么意味着倾向于得到更高的掩码率,当然这也让掩码预测这个任务会变得更难一些,相比于自回归方式,在给定固定顺序的token学习条件分布 P x i ∣ x < i P{x_i|x_{
2.7. Classifier Free Guidance
我们采用了classifier-free guidance来提高生成的质量以及图文的对齐。在训练的时候,我们随机去除10%样例的文本条件,这样能够只关注图像tokens,在测试的时候,对于每一个masked token我们计算了一个条件logit l c l_c lc以及一个无条件的logit l u l_u lu,最终logits l g l_g lg通过如下的guidance scale t t t来实现:
l g = ( 1 + t ) l c − t l u l_g = (1+t)l_c - t l_u lg=(1+t)lc−tlu
直观上看来,CFG在多样性和保真度之间做了平衡,不同于之前的方法,我们通过采样过程线性增加引导标度t来减少对多样性的影响。这允许在低引导或无引导的情况下更自由地对早期token进行采样,但增加了条件提示对后期token的影响。
我们同样也探索了 negative prompting机制,通过替换无条件logit l u l_u lu为logit (基于negative prompt”.),能够使得生成的图像拥有与 positive prompt l c l_c lc更相关的特征,但是剔除掉与 negative prompt l u l_u lu相关的特征。
2.8.Iterative Parallel Decoding at Inference
我们的Muse模型能取得很好的推理性能,其中关键的原因是使用了并行解码来预测在一个forward pass预测多个输出tokens。==之所以能用并行解码的关键性假设是在于:马尔可夫性质,即在给定其它tokens的条件下,多个tokens彼此之间是条件独立的。==具体来说,解码是基于一种cosine schedule的策略,即首先在当前step选择固定比例的高置信度掩码tokens,这些tokens在接下来的steps过程中被置为unmasked的状态,这样masked tokens的集合就会适当减少。通过这样的方式,我们在base model里面能够仅用24步就能推理256个tokens,在超分模型里面,仅用8个decoding steps就能推理4096个tokens。(这样相较于自回归模型,就能从256 -> 24,4096 -> 8)极大地减少了推理的迭代解码次数。
3.Results
我们训练了多个参数量的模型(从600M到3B参数),每一个模型都被T5-XXL(4.6B参数)的文本编码作为输入,最大3B参数的base model拥有48层transformer层,(其中图文之间使用了cross-attention,图像tokens之间使用了self-attention),所有的base model都共享相同的图像tokenizer。我们使用19个ResNet blocks的CNN模型,以及8192的codebook来做离散编码。更大的codebook并不会带来效果上的提升。超分模型包含,32 multi-axis Transformer layers (Zhao et al., 2021) ,利用high resolution image和concatenated text and image embedding 做cross-attention,在high resolution image tokens内部做self-attention。模型将16 × 16 tokens的latent space转换到64 × 64 tokens的latent space。接着再把高分辨率的latent space转化到高分辨率的图像空间。
一些实验的设置如下:
Imagen dataset consisting of 460M text-image pairs
1M steps
batch size of 512 on 512-core TPU-v4 chips
This takes about 1 week of training time.
Adafactor optimizer to save on memory consumption which allowed us to fit a 3B parameter model without model parallelization
EMA
3.1. Qualitative Performance
3.2 Quantitative Performance

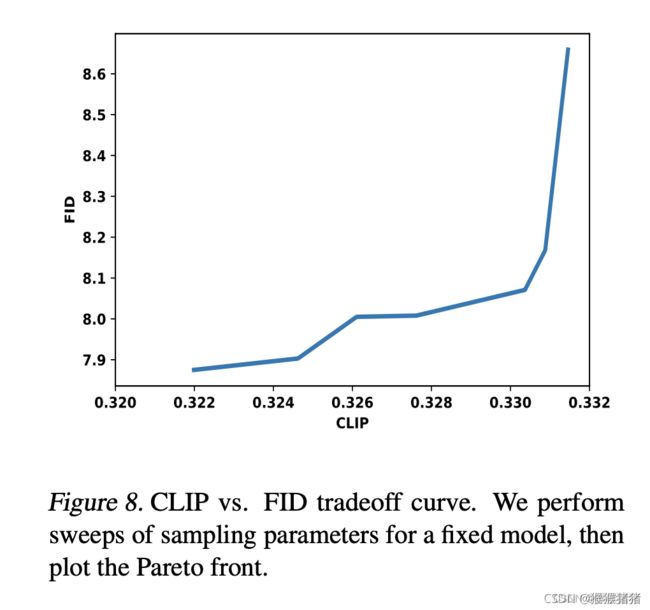
3.2.1 HUMAN EVALUATION
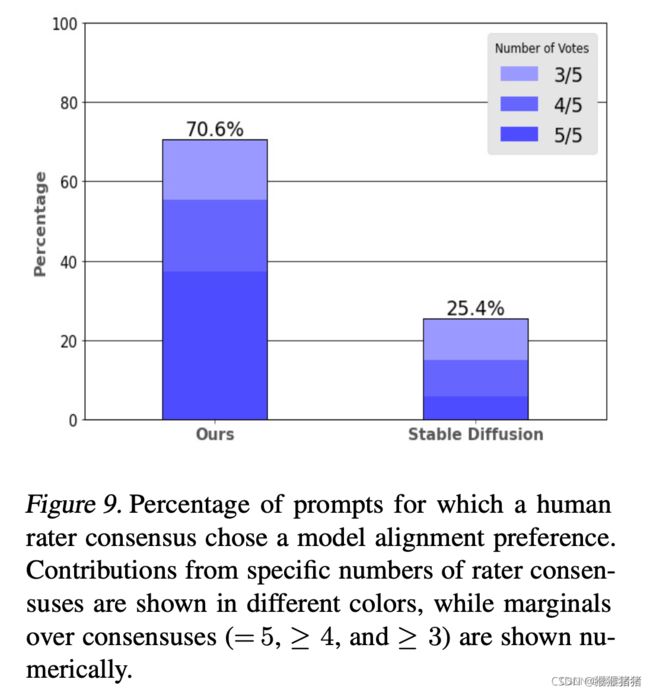
3.2.2 INFERENCE SPEED

3.3. Image Editing
其余的一些editing的实验,详见原文,在此不再赘述。