深入探讨Kubernetes(K8s)在云原生架构中的关键作用和应用

文章目录
- 1. 容器化的应用程序管理
- 2. 自动化扩展和负载均衡
- 3. 容器编排和调度
- 4. 存储管理
- 5. 自动化滚动更新
- 6. 多云和混合云部署
- 7. 监控和日志
- 8. 安全
- 9. 社区支持和生态系统
- 10. 未来展望
- 案例
个人主页:程序员 小侯
CSDN新晋作者
欢迎 点赞✍评论⭐收藏
✨收录专栏:云计算
✨文章内容:Kubernetes(K8s)
希望作者的文章能对你有所帮助,有不足的地方请在评论区留言指正,大家一起学习交流!
随着云原生应用程序的兴起,Kubernetes(通常称为K8s)已经成为云原生架构的核心组件之一。它是一个开源的容器编排平台,旨在简化和自动化容器化应用程序的部署、扩展和管理。本文将深入探讨Kubernetes在云原生架构中的关键作用和应用。
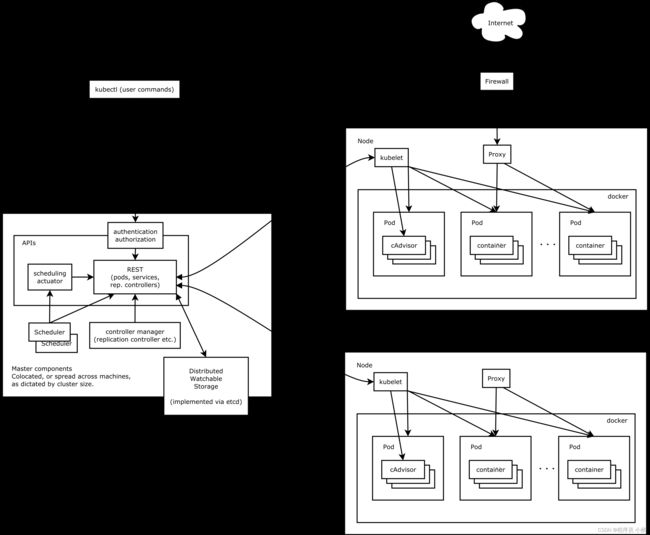
1. 容器化的应用程序管理
Kubernetes的首要作用是管理容器化的应用程序。它允许开发者将应用程序封装在容器中,并提供了一种统一的方式来部署和运行这些容器。K8s管理应用程序的生命周期,包括启动、停止、扩展和更新,从而大大简化了应用程序的管理和维护。
2. 自动化扩展和负载均衡
K8s具有自动化扩展的能力,可以根据负载情况动态调整应用程序的副本数量。当工作负载增加时,K8s可以自动创建新的容器实例,以确保应用程序的性能不受影响。此外,K8s还提供了负载均衡功能,可以将流量分发到不同的容器实例,确保它们均匀地处理请求。
3. 容器编排和调度
Kubernetes具有先进的容器编排和调度功能,可以将容器实例分配到可用的计算节点上。这意味着开发者不需要手动选择在哪个节点上运行容器,K8s会根据资源需求和节点可用性来进行智能调度。这有助于最大化资源利用率,并确保高可用性。
4. 存储管理
K8s还提供了存储管理的能力。它允许应用程序挂载持久卷(Persistent Volumes)以存储数据,这些数据在容器重新启动或迁移时仍然可用。这对于数据库和其他需要持久性存储的应用程序至关重要。
5. 自动化滚动更新
Kubernetes支持自动化滚动更新,使开发者能够无缝地将新版本的应用程序部署到生产环境中。它允许逐步替换旧版本的容器实例,以确保应用程序的稳定性和可用性。
6. 多云和混合云部署
K8s具有多云和混合云部署的能力,这意味着应用程序可以在不同云提供商的环境中运行。这为企业提供了更大的灵活性,可以根据需求选择最适合他们业务的云计算环境。
7. 监控和日志
Kubernetes提供了监控和日志记录工具,帮助开发者跟踪应用程序的性能和健康状况。它集成了多个监控和日志记录解决方案,使开发者能够轻松地监视应用程序的运行情况并识别问题。
8. 安全
K8s具有多层次的安全性措施,包括网络隔离、身份验证和授权、安全策略等。这有助于保护容器化的应用程序免受恶意攻击和数据泄漏。
9. 社区支持和生态系统
Kubernetes拥有庞大的开源社
区,这意味着有数以千计的开发者和组织在积极维护和改进这个项目。此外,有许多第三方工具和服务与Kubernetes集成,扩展了其功能和用途。
10. 未来展望
随着云原生应用程序的普及,Kubernetes在软件开发中的关键作用将继续增强。它将继续演进,以满足不断变化的需求,为开发者提供更多工具和功能,以简化和优化云原生应用程序的构建和管理。
案例
在教育领域,大学和研究机构面临着大量的科学研究和数据分析任务,这些任务需要大规模的计算资源和高度灵活的环境。Kubernetes(K8s)已经成为这些组织的首选工具之一,用于管理科研工作负载,包括高性能计算、分布式计算和数据分析。
以下是详细解释:

当涉及到Kubernetes(K8s)在教育领域的应用时,常常需要创建和管理容器化的科学研究工作负载。以下是一个示例Kubernetes YAML配置,演示如何创建一个简单的科学计算工作负载的Pod:
apiVersion: v1
kind: Pod
metadata:
name: scientific-compute
spec:
containers:
- name: compute-container
image: scientific-image:latest
resources:
limits:
cpu: "2"
memory: "4Gi"
command: ["python", "scientific_script.py"]
restartPolicy: OnFailure
在上述示例中:
metadata部分定义了Pod的名称为 “scientific-compute”。containers部分定义了一个名为 “compute-container” 的容器,该容器使用名为 “scientific-image:latest” 的镜像运行科学计算任务。resources部分指定了容器的资源限制,包括CPU和内存。command部分指定了容器启动时要执行的命令,通常是科学计算的脚本。
通过这个配置文件,可以使用以下命令来创建和部署这个Pod:
kubectl apply -f scientific-compute-pod.yaml
这将在Kubernetes集群中创建一个Pod,其中包含了科学计算任务的容器。K8s会根据资源需求和可用性自动选择节点来运行这个Pod。
请注意,实际的科学计算工作负载可能会更加复杂,并且可能需要更多的资源和配置选项。此外,Kubernetes还提供了更高级的对象,如Job和CronJob,用于管理定期运行的任务。
这个示例仅用于说明Kubernetes如何用于容器化科学计算工作负载。在实际应用中,您可能需要创建更复杂的配置,以满足您的特定需求和任务。
-
高性能计算(HPC):大学和研究机构通常需要进行大规模的高性能计算,以模拟物理过程、分析大规模数据集或进行复杂的数值计算。Kubernetes可以用于管理HPC工作负载,将计算任务划分为多个容器,每个容器运行一个计算任务。这种容器化的方式提供了更好的资源利用率,可以在多个计算节点上同时运行不同的计算任务,从而加速科学研究的进程。
-
分布式计算:分布式计算是处理大规模数据和执行复杂算法的关键。Kubernetes可以自动管理分布式计算集群,确保每个计算节点都具有所需的容器实例,以执行特定的计算任务。这使得研究人员可以轻松地扩展计算资源,以应对不断增长的需求,而无需手动管理计算节点。
-
数据分析:研究机构通常需要对大规模数据集进行分析,以获得有关各种现象和趋势的见解。Kubernetes可以用于容器化数据分析工作负载,包括使用工具如Apache Spark、Hadoop和TensorFlow等进行数据处理和机器学习任务。这种容器化的方法提供了更好的隔离性和可重复性,使得数据分析任务更容易管理和部署。
-
资源管理:Kubernetes提供了高度灵活的资源管理功能,允许研究机构根据需要分配计算、存储和网络资源。这意味着他们可以动态调整资源,以满足不同任务的要求。例如,在进行大规模数据分析时,可以分配更多的计算资源,而在进行模拟实验时,可以分配更多的内存和存储资源。
-
多云和混合云:一些大学和研究机构可能在不同的云提供商之间部署其计算资源。Kubernetes的多云和混合云能力使其成为在不同云环境中管理工作负载的理想选择。研究机构可以轻松地将其工作负载迁移到不同的云提供商,以获得更好的性能或成本效益。
总之,Kubernetes在云原生架构中扮演着关键的角色,它不仅简化了容器化应用程序的管理,还提供了弹性、自动化和安全性,使开发者能够更轻松地构建和部署现代化的应用程序。随着云原生应用程序的持续崛起,Kubernetes将继续引领着云原生技术的发展。
后记 美好的一天,到此结束,下次继续努力!欲知后续,请看下回分解,写作不易,感谢大家的支持!!