数据结构3:单向链表实现及图解
目录
链表的概念及结构
链表的分类
1. 单向或者双向
2. 带头或者不带头
3. 循环或者非循环
无头单项非循环链表:
带头双向循环链表:
无头单项非循环链表的实现
增删查改函数的声明:
单链表打印
单链表的动态节点申请
单链表的头插
插入过程的指针问题:
链表的头删
单链表尾插
单链表尾删
单链表查找
单链表的插入
在POS后插入
在POS前插入
单链表的定向删除
在POS后删除
在POS前删除
链表,其实它的数据结构像一节拖着很多节车厢的火车,只需要走进其中一节,就可以去到其他车厢。
链表的概念及结构
概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表
中的指针链接次序实现的 。
逻辑结构上,我们希望一个节点分为两个存储空间,其中一个存放当前节点的数据,另一个存放下一个节点的地址,以实现链式访问。


也就是我们所想象的逻辑结构其实在程序内部并不是这样存储的,但是这样易于理解的逻辑结构可以将链表的每个节点更见具象化,方便我们分析和编写接口。
链表的分类
实际中链表的结构非常多样,以下情况组合起来就有8种链表结构:
1. 单向或者双向

2. 带头或者不带头
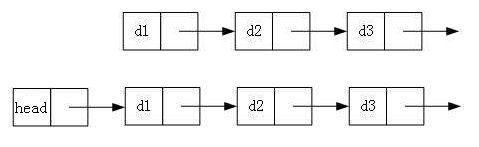
3. 循环或者非循环
虽然有这么多的链表的结构,但是我们实际中最常用还是两种结构:
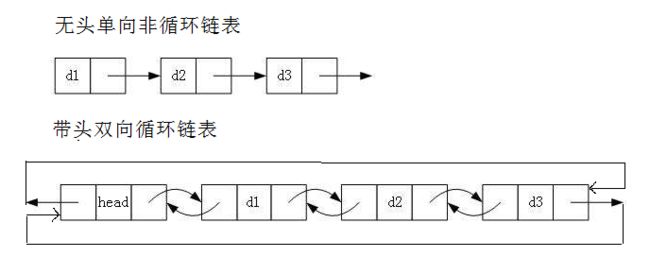
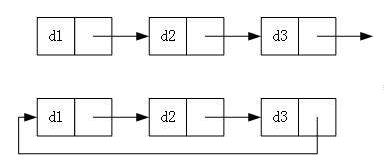
无头单项非循环链表:
作为最简单的链表结构,无头单项非循环链表一般不用来存储数据,而是用来像水泥砖一样支持其他数据结构的子结构。
带头双向循环链表:
作为最复杂的链表结构,无头单项非循环链表一般单独存储数据,虽然结构复杂,但是实现逻辑并不困难,实现完毕之后用起来也很顺手。
无头单项非循环链表的实现
和顺序表一样,为了方便管理我们的项目,我们创建多几个文件。
增删查改函数的声明:
#include
#include
#include
// 1、无头+单向+非循环链表增删查改实现
typedef int SLTDateType;
typedef struct SListNode
{
SLTDateType val;
struct SListNode* next;
}SListNode;
// 动态申请一个结点
SListNode* BuySListNode(SLTDateType x);
// 单链表打印
void SListPrint(SListNode* phead);
// 单链表尾插
void SListPushBack(SListNode** pphead, SLTDateType x);
// 单链表的头插
void SListPushFront(SListNode** pphead, SLTDateType x);
// 单链表的尾删
void SListPopBack(SListNode** pphead);
// 单链表头删
void SListPopFront(SListNode** pphead);
// 单链表查找
SListNode* SListFind(SListNode* pphead, SLTDateType x);
// 在pos之前插入
void SListInsert(SListNode** pphead, SListNode* pos, SLTDateType x);
// 在pos后面插入
void SListInsertAfter(SListNode* pos, SLTDateType x);
// 删除pos位置
void SListErase(SListNode** pphead, SListNode* pos);
// 删除pos后面位置
void SListEraseAfter(SListNode* pos);
单链表打印
先写单链表的打印是因为打印包含了最基本的链表遍历逻辑,那么整个遍历的逻辑是怎么实现的?
为了防止phead在遍历的过程中被更改,创建一个cur来控制遍历。phead指向链表头子。
void SListPrint(SListNode* phead)
{
SListNode* cur = phead;
}
逻辑如下:cur指针先打印当前数据域内部的的数据,然后向后遍历,遍历只需要让cur指针赋值成为自己当前的next,cur就可以成功指向下一个节点。


// 单链表打印
void SListPrint(SListNode* phead)
{
SListNode* cur = phead;
while (cur != NULL)
{
printf("%d->", cur->val);
cur = cur->next;
}
printf("NULL\n");
}循环一直执行,直到cur指向空。
注意,链表的打印不需要断言,因为链表很有可能是空的。
单链表的动态节点申请
为了更方便的存储数据,我们依旧需要实现链表的动态扩容,扩容的逻辑同顺序表差不多,不过我们需要返回开辟之后的指针来接入链表。
// 动态申请一个结点
SListNode* BuySListNode(SLTDateType x)
{
SListNode* newnode = (SListNode* )malloc(sizeof(SListNode));
//返回值检查
if (newnode == NULL)
{
perror("malloc fail!");
exit(-1);
}
newnode->val = x;
newnode->next = NULL;
//返回开辟之后的节点指针。
return newnode;
}单链表的头插
头插的逻辑比较简单,我们只需要将新建立的节点的next指针指向当前的链表头子,然后再让指向链表头子的指针指向当前节点即可。
先新建一个节点:
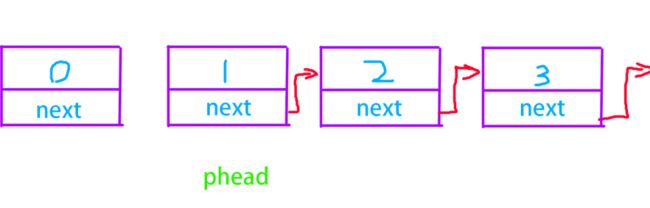
新节点的next指向当前phead指向的节点,链接起来。
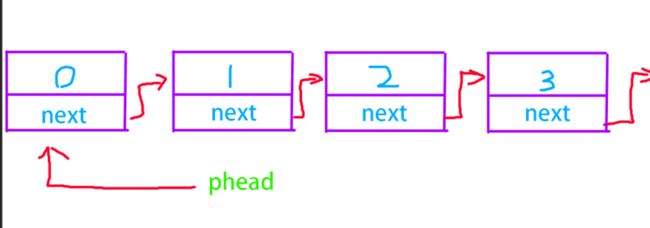
phead指向新节点。

那么,根据上面的逻辑,写一个头插还是很简单的
//错误示范
void SListPushFront(SListNode* pphead, SLTDateType x)
{
assert(pphead);
SListNode* newnode = BuySListNode(x);
newnode->next = pphead;
pphead = newnode;
} 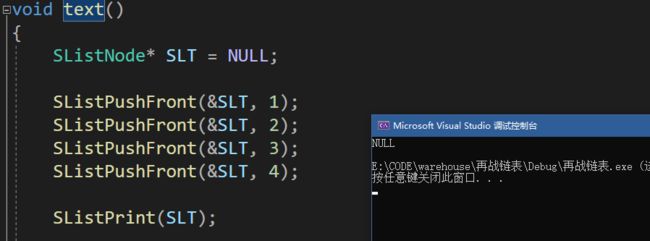
shit bro! 咋啥也妹有啊?这逻辑也没问题吧?
插入过程的指针问题:
这里就牵扯到了一个稍微有些难度的二级指针问题,不过其根本性质与函数传参的区别不大。
我们先回顾一下刚学习C语言时都可能遇到的问题,函数传参时无法直接更改实参的问题。

我们都知道函数传参时会生成形参,形参是实参的拷贝,所以这样的传值调用无法更改实参,而传递指针则可以解决这个问题。

但其实,我们可能会进入一个思考误区,那就是我传了指针,就可以更改到实参。而事实则是真正其绝对作用的还是解引用。我们传入实参的地址,形参拷贝了实参的地址,解引用了形参的地址,由于实参和形参相同,解引用的地址可以直接访问到实参,更改地址里面的东西,才实现了更改。
那么二级指针的本质其实是套了个马甲,从更改变量的值到更改一个指针,我们拿交换函数套一个马甲试试:
我们借用函数交换两个指针。
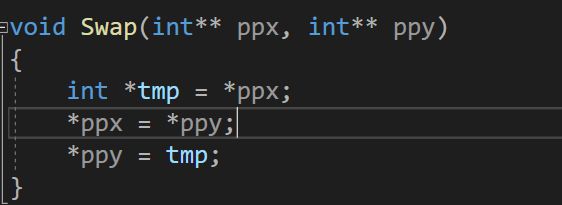
void Swap(int** ppx, int** ppy)
{
int *tmp = *ppx;
*ppx = *ppy;
*ppy = tmp;
}
int main()
{
int x = 1;
int y = 2;
int* px = &x;
int* py = &y;
printf("%d %d ",*px,*py);
Swap(&px, &py);
printf("%d %d ", *px, *py);
return 0;
}
所以根据上面我们的分析,我们需要更改的是phead这个指针所指向的节点,为了成功的更改到这个指针而非其形参,我们需要用二级指针存放它并且解引用以真正的访问到这个指针。
我们在这里需要认清的是我们需要更改的是一个指针,而非一个值
void SListPushFront(SListNode** pphead, SLTDateType x)
{
assert(pphead);
SListNode* newnode = BuySListNode(x);
newnode->next = *pphead;
*pphead = newnode;
}总结:一级指针头插失败的根本原因不仅是没有解引用的过程,更根本的原因是就算解应用了,也没法更改到指针。
链表的头删
头删的逻辑也不算困难,理解了二级指针之后就非常容易了
// 单链表头删
void SListPopFront(SListNode** pphead)
{
assert(pphead);
SListNode* cur = *pphead;
*pphead = cur->next;
free(cur);
cur = NULL;
}
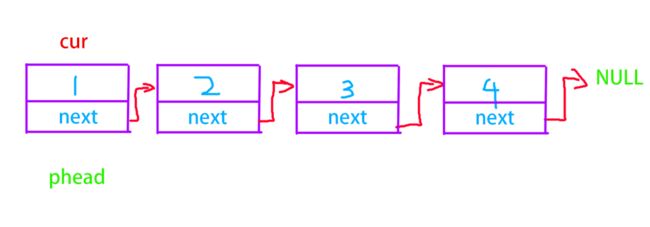

形象点说,留个cur当工具人在头部,phead向后移动一个节点,cur自毁。

单链表尾插
尾插稍微有些麻烦,我们需要遍历整个链表找到尾部然后插入。
// 单链表尾插
void SListPushBack(SListNode** pphead, SLTDateType x)
{
assert(pphead);
SListNode* newnode = BuySListNode(x);
if ((*pphead)->next == NULL)//加上括号,先与*结合解引用
{
*pphead = newnode;
}
else
{
SListNode* cur = *pphead;
while (cur->next != NULL)//如果当前cur的下一个不是空,向后遍历,是空则到尾
{
cur = cur->next;
}
cur->next = newnode;
}
}
单链表尾删
单链表的尾删有两个情况,第一个情况是删到头了,我们就需要将头指针指向的节点释放然后置空,第二种就是普通情况,遍历到尾部然后删除,但是这里有个需要注意的问题,我们删去了尾部,但是尾部前一个节点的next依然指向被删除的节点,所以我们需要额外创建一个prev指针用于将它的next置空。
遍历链表,prev在cur之前,cur找到尾部停止

cur销毁当前所在节点
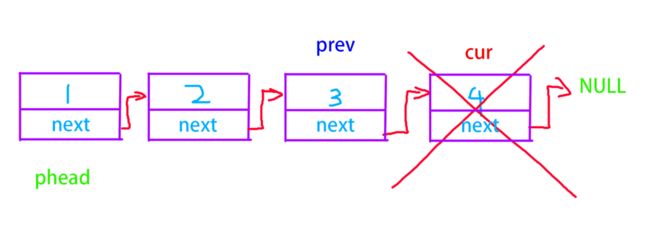
prev的next置空

// 单链表的尾删
void SListPopBack(SListNode** pphead)
{
assert(pphead);
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else
{
SListNode* cur = *pphead;
SListNode* prev = NULL;
while (cur->next != NULL)
{
prev = cur;
cur = cur->next;
}
free(cur);
prev->next = NULL;
cur = NULL;
}
}

单链表查找
查找逻辑同数组没啥区别,遍历找相等,返回当前节点的指针,虽然简单,但是是很重要的组件,在接下来的定向查改中有很大作用。
SListNode* SListFind(SListNode* pphead, SLTDateType x)
{
SListNode* cur = pphead;
while (cur->next !=NULL )
{
if (cur->val == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}单链表的插入
由于我们并不知道一个数据在整个链表中的确切位置,我们配合刚才写好的find函数来帮助我们锁定需要查找数据的位置。
单链表的插入有两种方式,一种为在POS前插入,另一种在POS后插入,在这里POS后面插入的逻辑会简单很多,因为免去了遍历的过程。
在POS后插入
由于直接借助了find函数拿到了查找数据的位置,我们直接在POS位置后面插入即可,不要忘记插入后和后面的链表相连接。
// 在pos后面插入
void SListInsertAfter(SListNode* pos, SLTDateType x)
{
SListNode* newnode = BuySListNode(x);
newnode->next = pos->next;
pos->next = newnode;
}



在POS前插入
在POS前插入就比较麻烦了,毕竟我们没法访问POS前一个节点,还需要遍历一遍链表。
// 在pos之前插入
void SListInsert(SListNode** pphead, SListNode* pos, SLTDateType x)
{
assert(pphead);
SListNode* newnode = BuySListNode(x);
SListNode* cur = *pphead;
while (cur->next != pos)
{
cur = cur->next;
}
newnode->next = pos;
cur->next = newnode;

单链表的定向删除
同插入,删除也有在POS前后之分,POS后删除依然优于POS前
在POS后删除
删完别忘了将前后节点链接起来。
// 删除pos后面位置
void SListEraseAfter(SListNode* pos)
{
assert(pos);
//当POS后面没有节点直接返回
if (pos->next == NULL)
{
return;
}
else
{
SListNode* cur = pos->next;
pos->next = pos->next->next;
free(cur);
}
}
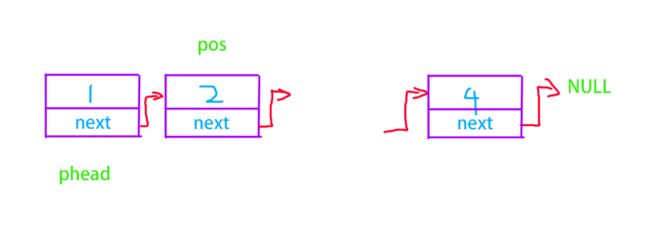

在POS前删除
// 删除pos位置
void SListErase(SListNode** pphead, SListNode* pos)
{
assert(pphead);
assert(pos);
if (*pphead == pos)
{
SListPopFront(pphead);
}
SListNode* cur = *pphead;
while (cur->next != pos)
{
cur = cur->next;
assert(cur);
}
cur->next = pos->next;
free(pos);
pos = NULL;
}单链表OJ题:
1.移除链表元素
链接:力扣
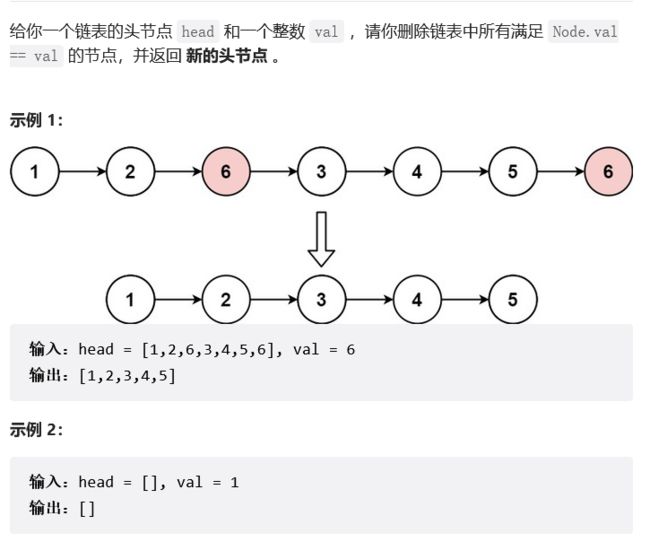
struct ListNode* removeElements(struct ListNode* head, int val){
struct ListNode* cur = head;
struct ListNode* prev = NULL;
while (cur)
{
if(cur-> val == val)
{
if(cur == head)
{
head = head->next;
free(cur);
cur = head;
}
else
{
prev->next = cur->next;
cur = cur ->next;
}
}
else
{
prev = cur;
cur = cur ->next;
}
}
return head;
}注意:其实整体逻辑同删除链表元素没什么太大的差别,需要注意的地方就是头删的额外处理。
2.反转链表:
链接:力扣

这题看着比较头疼,但是其实巧妙的使用三个指针就可以很快的解决这道题。
我们先创建3个指针

然后让next指向当前cur的下一个节点
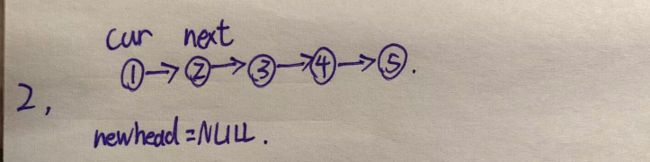
然后让cur的next指向newhead
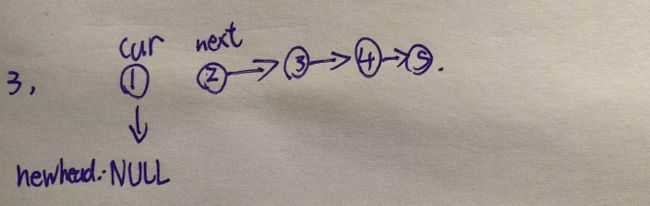
然后让newhead移动到当前cur的位置
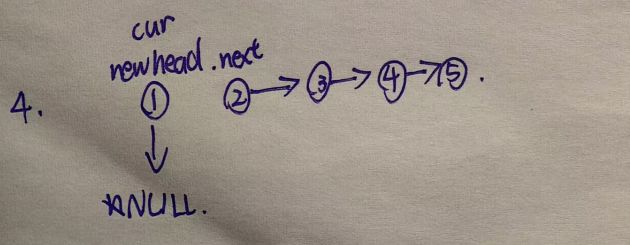
cur再移动到next的位置

再让当前cur的节点的next指向newhead
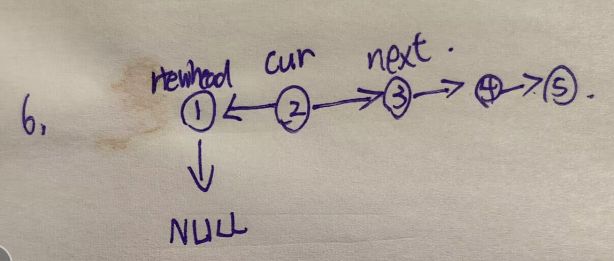
整个过程总结起来很像牵线搭桥,因为我们的链表是单向的,所以需要这样子做,如果是双向循环链表就要简单的多。
struct ListNode* reverseList(struct ListNode* head){
struct ListNode* cur = head;
struct ListNode* next = NULL;
struct ListNode* newhead = NULL;
while (cur)
{
next = cur->next;
cur -> next = newhead;
newhead = cur ;
cur = next;
}
return newhead;
}3.返回链表的中间节点
链接:力扣

在这里我们可以使用快慢指针
快慢指针,打比方说假如有一段100M长的路,A走的比较快,他的速度是2M/S,而B的速度则是1M/S那么当A走到终点时,B一定正好在50米处。
我们利用这个思想,使用快慢指针,也就是一个指针走得快,一次跨越两个节点,另一个走得慢一次跨越一个节点。
struct ListNode* middleNode(struct ListNode* head){
struct ListNode* slow = head;
struct ListNode* fast = head;
while (fast&&fast->next)
{
fast = fast->next->next;
slow = slow->next;
}
return slow;
}注意:fast本身和它的下一个节点都不能为空。
4.链表中倒数第k个结点
链接:链表中倒数第k个结点_牛客题霸_牛客网
本题有两种解题方法:
1.计数循环
struct ListNode* FindKthToTail(struct ListNode* pListHead, int k ) {
// write code here
int count = 0;
struct ListNode* end = pListHead;
struct ListNode* cur = pListHead;
while (end)
{
count ++;
end = end -> next;
}
int num = count - k;
if(num<0)
return NULL;
for (int i = 0 ;i< num;i++)
{
cur = cur->next;
}
return cur;
}时间复杂度O(2N)
2.快慢指针
我们分析会发现一个规律,倒数其实是一种偏差,假如说倒数第K位,整个链表长度是N,我们求的就是N-K,我们希望走到N的时候就是倒数的那个位置,我们就需要修正K个位置,修正就可以使用快慢指针。
我们先让快指针走K步,然后再让slow和fast一同行动,这个时候的slow的终点就是被修正之后的值,也就是N-K。
struct ListNode* FindKthToTail(struct ListNode* pListHead, int k ) {
// write code here
if (!pListHead || k <= 0)
return NULL;
struct ListNode* fast = pListHead;
struct ListNode* slow = pListHead;
while (k--)
{
if(fast)
fast = fast->next;
//避免整个链表长度小于K的情况发生
else
return NULL;
}
while (fast)
{
fast = fast->next;
slow = slow->next;
}
return slow;
}5.两个升序链表合并为一个新的升序链表
链接:力扣
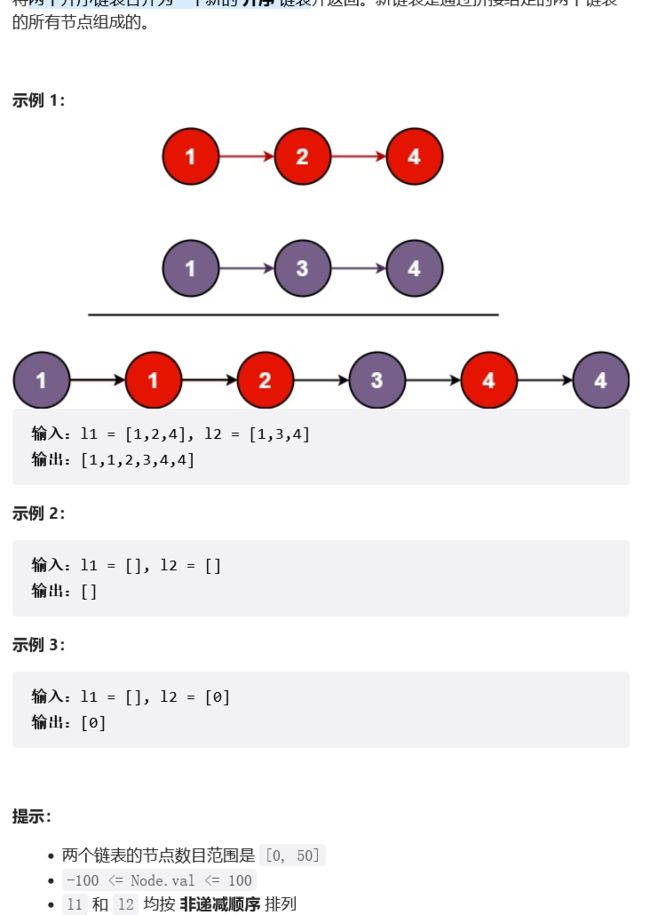
struct ListNode* mergeTwoLists(struct ListNode* list1, struct ListNode* list2){
struct ListNode* gurad =(struct ListNode*)malloc(sizeof(struct ListNode));
gurad->next=NULL;
struct ListNode* cur1 =list1;
struct ListNode* cur2 =list2;
struct ListNode* newlist = gurad;
while(cur1 && cur2)
{
if(cur1->val <= cur2->val)
{
newlist->next = cur1;
cur1=cur1->next;
}
else
{
newlist->next = cur2;
cur2=cur2->next;
}
newlist= newlist->next;
}
//尾插完毕后,把剩余的一股脑全尾插即可,不用往下迭代的代码,因为其本身剩下的都是正序的。
if(cur1)
{
newlist->next = cur1;
}
if(cur2)
{
newlist->next = cur2;
}
//malloc的空间记得释放以防内存泄漏
//free之前记得把哨兵位指向的链表头子给了
struct ListNode* head = gurad->next;
free(gurad);
return head;
}至此,记述结束,感谢阅读!希望对你有点帮助!
