YOLO-NAS | YOLO新高度,引入NAS,出于YOLOv8而优于YOLOv8
编辑 | Happy
首发 | AIWalker
链接 | https://mp.weixin.qq.com/s/FsWSRguAn2WZKtmPhMbc6g
亮点在哪里?
- 参考QARepVGG,该方案引入了QSP与QCI模块以同时利用重参数与8-bit量化的优化;
- 该方案采用 AutoNAC搜索最优尺寸、每个stage的结构,含模块类型、数量以及通道数;
- 采用 混合量化机制进行模型量化,既考虑了每一层对精度与延迟的影响,也考虑了8-bit与16-bit之间切换对整体延迟的影响;
- 预训练方案:automatically labeled data, self-distillation, and large datasets
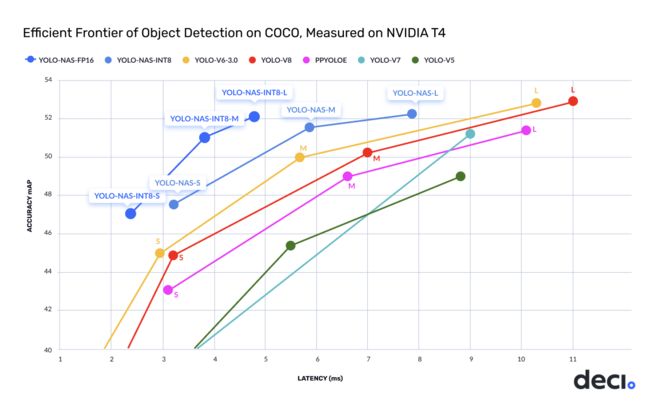
总而言之,YOLO-NAS达成目标检测任务新高度,取得了最佳的精度-延迟均衡。值得一提的事,YOLO-NAS与TensorRT推理引擎完全兼容,且支持INT8量化,达成前所未有的运行时性能。
| Model | mAP | Latency (ms) |
|---|---|---|
| YOLO-NAS S | 47.5 | 3.21 |
| YOLO-NAS M | 51.55 | 5.85 |
| YOLO-NAS L | 52.22 | 7.87 |
| YOLO-NAS S INT-8 | 47.03 | 2.36 |
| YOLO-NAS M INT-8 | 51.0 | 3.78 |
| YOLO-NAS L INT-8 | 52.1 | 4.78 |
方案简介
受启发于YOLOv6、YOLOv7以及YOLOv8,DECI的研究人员采用AutoNAC搜索比YOLOv8更优的架构,即"We used machine learning to find a new deep learning architecture!"
为什么要用AutoNAC呢? 这是因为手工寻找"正确"结构过于低效且乏味,因此DECI的研究人员采用AutoNAC搜索新的目标检测模型,同时最小化在NVIDIA T4上的推理延迟。
为构建YOLO-NAS,作者构建了一个深不可测的搜索空间(1014)以探索精度-延迟上限。最终,作者从中三样三个"前沿观察点"构建了YOLO-NAS-S,YOLO-NAS-M,YOLO-NAS-L。
训练简介
YOLO-NAS采用了多阶段训练方式,包含(1)预训练:Object365+COCO伪标签数据;(2)知识蒸馏;(3) DFL,即Distribution Focal Loss.

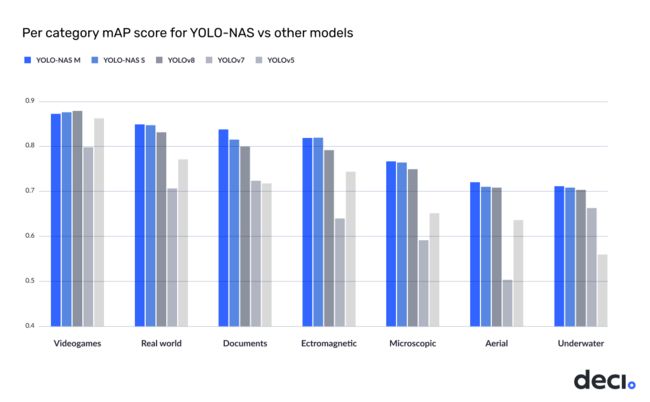
在训练数据方面,作者基于RoboFlow100(由100个不同领域的数据集构成)进行训练以验证其处理复杂检测任务的能力。

下图对比了YOLO-NAS与YOLOv8、YOLOv5、YOLOv7在Roboflow100数据集上的性能。

量化感知
YOLO-NAS采用了量化感知模块与Selective量化以达成最优性能,即基于延迟-精度均衡考虑在特定层进行了"Skipping量化"。当转换为INT8量化模型后,YOLO-NAS具有更少的精度损失(L-M-S的损失分别为0.45,0.65,0.51mAP)。
YOLO-NAS架构和预训练权重定义了低延迟推理的新领域,也是微调下游任务的绝佳起点。
上手体验
看完上面的介绍有没有“一头雾水”的感觉,哈哈,上手体验一把。
Step 1. 安装super-gradients
conda create -n sg python=3.7
conda activate sg
pip install super-gradients
Step 2. 命令行测试
from super_gradients.training import models
from super_gradients.common.object_names import Models
net = models.get(Models.YOLO_NAS_S, pretrained_weights='coco')
net.predict("bus.jpg").show()
不出意外的话,你就可以看到下面的输出结果了。
当然,如果出了意外,可以试试用ONNX推理,导出只需一行代码。
models.convert_to_onnx(model=net, input_shape=(3, 640, 640), out_path='yolo-nas-s.onnx')
相关推理code可参考"YOLOv8-TensorRT"中的推理微调一下即可。需要注意以下两点,通过官方工具导出的"bboxes"已经是"xyxy"格式了,所以不需要再执行make_grid, distance2bbox等操作了,直接进行"NMS"即可。但是,OpenCV的NMS要求输入的BBOXES格式为xywh,所以还需要再改一下,^^哈哈哈^^
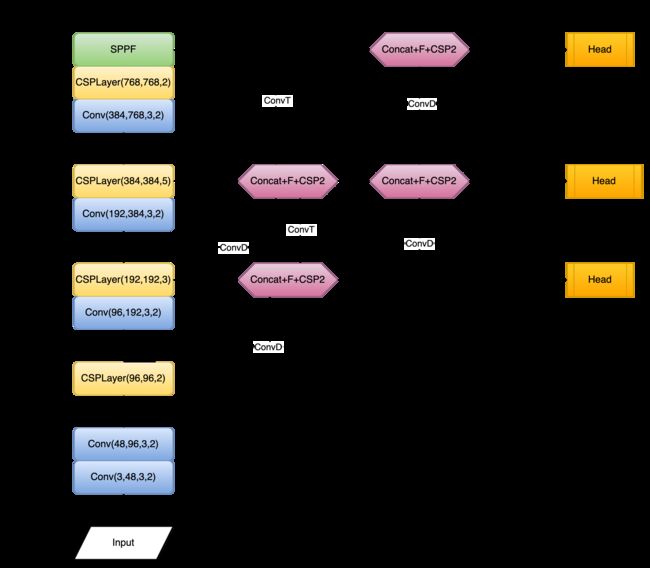
最后,附上YOLO-NAS的网络结构示意图,这里仅给出了YOLO-NAS-S的示意图,另外两个跟这个整体类似,区别在于Block改为了YOLOv7的ELAN且通道数更多。
最后的最后,如果只想体验,不想去安装super_gradients,可以在公众号后台回复"YOLO-NAS"获取资源(ONNX模型、ORT+OCV推理脚本)。
本文由 mdnice 多平台发布