JVM 问题排查-性能优化
JVM问题排查-性能优化
JVM的性能优化可以分为代码层面和非代码层面。
在代码层面,大家可以结合字节码指令进行优化,比如一个循环语句,可以将循环不相关的代码提取到循环体之外,这样在字节码层面就不需要重复执行这些代码了。
在非代码层面,一般情况可以从内存、gc以及cpu占用率等方面进行优化。
注意,JVM调优是一个漫长和复杂的过程,而在很多情况下,JVM是不需要优化的,因为JVM本身已经做了很多的内部优化操作,所以只有在代码层面没法优化的时候在进行。
内存分配
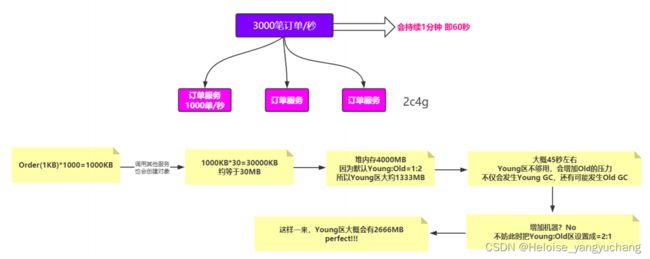
例子:
每台机器配置2c4G,以每秒3000笔订单为例,整个过程持续60秒
内存溢出(OOM):
(1)大并发情况下
(2)内存泄露导致内存溢出
大并发[秒杀]
- 浏览器缓存、本地缓存、验证码
- CDN静态资源服务器
- 集群+负载均衡
- 动静态资源分离、限流[基于令牌桶、漏桶算法]
- 应用级别缓存、接口防刷限流、队列、Tomcat性能优化
- 异步消息中间件
- Redis热点数据对象缓存
- 分布式锁、数据库锁
- 业务层面优化,如10分钟之内没有支付,取消订单、恢复库存等
内存泄露导致内存溢出
1、top命令查看:
top
top -Hp PID
2、jstack查看线程情况,发现没有死锁或者IO阻塞的情况:
jstack PID
java -jar arthas.jar —> thread
3、查看堆内存的使用,发现堆内存的使用率已经高达88.95%:
jmap -heap PID
java -jar arthas.jar —> dashboard
4、此时可以大体判断出来,发生了内存泄露从而导致的内存溢出,那怎么排查呢?
jmap -histo:live PID | more
获取到jvm.hprof文件,上传到指定的工具分析,比如heaphero.io
Thread状态分析

-
NEW
每一个线程,在堆内存中都有一个对应的Thread对象。Thread t = new Thread();当刚刚在堆内存中创建Thread对象,还没有调用t.start()方法之前,线程就处在NEW状态。在这个状态上,线程与普通的java对象没有什么区别,就仅仅是一个堆内存中的对象 -
RUNNABLE
该状态表示线程具备所有运行条件,在运行队列中准备操作系统的调度,或者正在运行。 这个状态的线程比较正常,但如果线程长时间停留在在这个状态就不正常了,这说明线程运行的时间很长(存在性能问题),或者是线程一直得不得执行的机会(存在线程饥饿的问题)。 -
BLOCKED
线程正在等待获取java对象的监视器(也叫内置锁),即线程正在等待进入由synchronized保护的方法或者代码块。synchronized用来保证原子性,任意时刻最多只能由一个线程进入该临界区域,其他线程只能排队等待。 -
WAITING
处在该线程的状态,正在等待某个事件的发生,只有特定的条件满足,才能获得执行机会。而产生这个特定的事件,通常都是另一个线程。也就是说,如果不发生特定的事件,那么处在该状态的线程一直等待,不能获取执行的机会。
比如:A线程调用了obj对象的obj.wait()方法,如果没有线程调用obj.notify或obj.notifyAll,那么A线程就没有办法恢复运行;
如果A线程调用了LockSupport.park(),没有别的线程调用LockSupport.unpark(A),那么A没有办法恢复运行。 -
TIMED_WAITING
意味着线程调用了限时版本的API,正在等待时间流逝。当等待时间过去后,线程一样可以恢复运行。如果线程进入了WAITING状态,一定要特定的事件发生才能恢复运行;而处在TIMED_WAITING的线程,如果特定的事件发生或者是时间流逝完毕,都会恢复运行 -
TERMINATED
线程执行完毕,执行完run方法正常返回,或者抛出了运行时异常而结束,线程都会停留在这个状态。这个时候线程只剩下Thread对象了,没有什么用了。
关键状态分析
- Wait on condition:The thread is either sleeping or waiting to be
notified by another thread
该状态说明它在等待另一个条件的发生,来把自己唤醒,或者干脆它是调用了 sleep(n)。
此时线程状态大致为以下几种:
java.lang.Thread.State: WAITING (parking):一直等那个条件发生;
java.lang.Thread.State: TIMED_WAITING (parking或sleeping):定时的,那个条件不到来,也将定时唤醒自己。
- Waiting for Monitor Entry 和 in Object.wait():The thread is waiting to get the lock for an object (some other thread may be holding the lock). This happens if two or more threads try to execute
synchronized code. Note that the lock is always for an object and not for individual methods.
在多线程的JAVA程序中,实现线程之间的同步,就要说说 Monitor。Monitor是Java中用以实现线程之间的互斥与协作的主要手段,它可以看成是对象或者Class的锁。每一个对象都有,也仅有一个 Monitor 。
下图,描述了线程和 Monitor之间关系,以及线程的状态转换图:
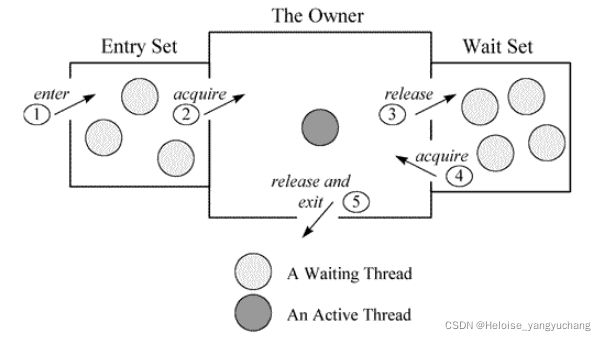
如上图,每个Monitor在某个时刻,只能被一个线程拥有,该线程就是 “ActiveThread”,而其它线程都是 “Waiting Thread”,分别在两个队列“Entry Set”和“Wait Set”里等候。在“Entry Set”中等待的线程状态是“Waiting for monitor entry”,而在“Wait Set”中等待的线程状态是“in Object.wait()”。
“Entry Set”里面的线程。我们称被 synchronized保护起来的代码段为临界区。当一个线程申请进入临界区时,它就进入了“Entry Set”队列。对应的 code就像
synchronized(obj) {
.........
}
这时有两种可能性:
- 该 monitor不被其它线程拥有, Entry Set里面也没有其它等待线程。本线程即成为相应类或者对象的 Monitor的 Owner,执行临界区的代码。
- 该 monitor被其它线程拥有,本线程在 Entry Set队列中等待
在第一种情况下,线程将处于 “Runnable”的状态,而第二种情况下,线程 DUMP会显示处于 “waiting for monitor entry”。
如下:
"Thread-0" prio=10 tid=0x08222eb0 nid=0x9 waiting for monitor entry [0xf927b000..0xf927bdb8]
at testthread.WaitThread.run(WaitThread.java:39)
- waiting to lock <0xef63bf08> (a java.lang.Object)
- locked <0xef63beb8> (a java.util.ArrayList)
at java.lang.Thread.run(Thread.java:595)
临界区的设置,是为了保证其内部的代码执行的原子性和完整性。但是因为临界区在任何时间只允许线程串行通过,这和我们多线程的程序的初衷是相反的。如果在多线程的程序中,大量使用 synchronized,或者不适当的使用了它,会造成大量线程在临界区的入口等待,造成系统的性能大幅下降。如果在线程 DUMP中发现了这个情况,应该审查源码,改进程序。
“Wait Set”里面的线程。当线程获得了 Monitor,进入了临界区之后,如果发现线程继续运行的条件没有满足,它则调用对象(一般就是被 synchronized 的对象)的 wait() 方法,放弃 Monitor,进入 “Wait Set”队列。只有当别的线程在该对象上调用了 notify() 或者 notifyAll(),“Wait Set”队列中线程才得到机会去竞争,但是只有一个线程获得对象的Monitor,恢复到运行态。在 “Wait Set”中的线程, DUMP中表现为: in Object.wait()。
如下:
"Thread-1" prio=10 tid=0x08223250 nid=0xa in Object.wait() [0xef47a000..0xef47aa38]
at java.lang.Object.wait(Native Method)
- waiting on <0xef63beb8> (a java.util.ArrayList)
at java.lang.Object.wait(Object.java:474)
at testthread.MyWaitThread.run(MyWaitThread.java:40)
- locked <0xef63beb8> (a java.util.ArrayList)
at java.lang.Thread.run(Thread.java:595)
综上,一般CPU很忙时,则关注runnable的线程,CPU很闲时,则关注waiting for monitor entry的线程。
Lock
上面提到如果 synchronized和 monitor机制运用不当,可能会造成多线程程序的性能问题。在 JDK 5.0中,引入了 Lock机制,从而使开发者能更灵活的开发高性能的并发多线程程序,可以替代以往 JDK中的 synchronized和 Monitor的 机制。但是,要注意的是,因为 Lock类只是一个普通类,JVM无从得知 Lock对象的占用情况,所以在线程 DUMP中,也不会包含关于 Lock的信息, 关于死锁等问题,就不如用 synchronized的编程方式容易识别。
GC-G1
目前建议使用G1,所以以G1垃圾收集器调优为例
是否选用G1,官网建议:
(1)50%以上的堆被存活对象占用
(2)对象分配和晋升的速度变化非常
(3)垃圾回收时间比较长
G1调优
(1)使用G1GC垃圾收集器: -XX:+UseG1GC
修改配置参数,获取到gc日志,使用GCViewer分析吞吐量和响应时间

(2)调整内存大小再获取gc日志分析
比如设置堆内存的大小,获取到gc日志,使用GCViewer分析吞吐量和响应时间

(3)调整最大停顿时间
-XX:MaxGCPauseMillis=200 设置最大GC停顿时间指标
比如设置最大停顿时间,获取到gc日志,使用GCViewer分析吞吐量和响应时间

(4)启动并发GC时堆内存占用百分比
-XX:InitiatingHeapOccupancyPercent=45 G1用它来触发并发GC周期,基于整个堆的使用率,而不只是某一代内存的使用比例。值为 0 则表示“一直执行 GC循环)'. 默认值为 45 (例如, 全部的 45% 或者使用了45%).
比如设置该百分比参数,获取到gc日志,使用GCViewer分析吞吐量和响应时间
G1调优最佳实战
(1)不要手动设置新生代和老年代的大小,只要设置整个堆的大小
G1收集器在运行过程中,会自己调整新生代和老年代的大小 其实是通过adapt代的大小来调整对象晋升的速度和年龄,
从而达到为收集器设置的暂停时间目标 如果手动设置了大小就意味着放弃了G1的自动调优
(2)不断调优暂停时间目标
一般情况下这个值设置到100ms或者200ms都是可以的(不同情况下会不一样),但如果设置成50ms就 不太合理。
暂停时间设置的太短,就会导致出现G1跟不上垃圾产生的速度。最终退化成Full GC。
所以 对这个参数的调优是一个持续的过程,逐步调整到最佳状态。暂停时间只是一个目标,并不能总是得到 满足。
(3)使用-XX:ConcGCThreads=n来增加标记线程的数量
IHOP如果阀值设置过高,可能会遇到转移失败的风险,比如对象进行转移时空间不足。如果阀值设置过低,
就会使标记周期运行过于频繁,并且有可能混合收集期回收不到空间。
IHOP值如果设置合理,但是在并发周期时间过长时,可以尝试增加并发线程数,调高 ConcGCThreads。
(4)MixedGC调优
-XX:InitiatingHeapOccupancyPercent
-XX:G1MixedGCLiveThresholdPercent
-XX:G1MixedGCCountTarger
-XX:G1OldCSetRegionThresholdPercent
(5)适当增加堆内存大小
(6)不正常的Full GC
有时候会发现系统刚刚启动的时候,就会发生一次Full GC,但是老年代空间比较充足,一般是由 Metaspace区域引起的。可以通过MetaspaceSize适当增加
JVM问题场景总结
CPU飙高,load高,响应很慢
一个请求过程中多次dump;
对比多次dump文件的runnable线程,如果执行的方法有比较大变化,说明比较正常。如果在执行同一个方法,就有一些问题了;
查找占用CPU最多的线程
(1)top
(2)top -Hp PID
(3)查看进程中占用CPU高的线程id,即tid
(4)jstack PID | grep tid
使用命令:top -H -p pid(pid为被测系统的进程号),找到导致CPU高的线程ID,对应thread dump信息中线程的nid,只不过一个是十进制,一个是十六进制;
在thread dump中,根据top命令查找的线程id,查找对应的线程堆栈信息;
CPU使用率不高但是响应很慢
进行dump,查看是否有很多thread struck在了i/o、数据库等地方,定位瓶颈原因;
请求无法响应
多次dump,对比是否所有的runnable线程都一直在执行相同的方法,如果是的,恭喜你,锁住了!
死锁
死锁经常表现为程序的停顿,或者不再响应用户的请求。从操作系统上观察,对应进程的CPU占用率为零,很快会从top或prstat的输出中消失。
线程 Dump中可以直接报告出 Java级别的死锁
"Thread-1" prio=5 tid=0x00acc490 nid=0xe50 waiting for monitor entry [0x02d3f000
..0x02d3fd68]
at deadlockthreads.TestThread.run(TestThread.java:31)
- waiting to lock <0x22c19f18> (a java.lang.Object)
- locked <0x22c19f20> (a java.lang.Object)
"Thread-0" prio=5 tid=0x00accdb0 nid=0xdec waiting for monitor entry [0x02cff000
..0x02cff9e8]
at deadlockthreads.TestThread.run(TestThread.java:31)
- waiting to lock <0x22c19f20> (a java.lang.Object)
- locked <0x22c19f18> (a java.lang.Object)
Found one Java-level deadlock:
=============================
"Thread-1":
waiting to lock monitor 0x0003f334 (object 0x22c19f18, a java.lang.Object),
which is held by "Thread-0"
"Thread-0":
waiting to lock monitor 0x0003f314 (object 0x22c19f20, a java.lang.Object),
which is held by "Thread-1"
活锁
其表现特征为:由于多个线程对临界区,或者锁的竞争,可能出现:
- 频繁的线程的上下文切换:从操作系统对线程的调度来看,当线程在等待资源而阻塞的时候,操作系统会将之切换出来,放到等待的队列,当线程获得资源之后,调度算法会将这个线程切换进去,放到执行队列中。
- 大量的系统调用:因为线程的上下文切换,以及热锁的竞争,或者临界区的频繁的进出,都可能导致大量的系统调用。
- 大部分CPU开销用在“系统态”:线程上下文切换,和系统调用,都会导致 CPU在 “系统态 ”运行,换而言之,虽然系统很忙碌,但是CPU用在 “用户态 ”的比例较小,应用程序得不到充分的 CPU资源。
- 随着CPU数目的增多,系统的性能反而下降。因为CPU数目多,同时运行的线程就越多,可能就会造成更频繁的线程上下文切换和系统态的CPU开销,从而导致更糟糕的性能。
从整体的性能指标看,由于线程热锁的存在,程序的响应时间会变长,吞吐量会降低。
解决方法:
- 一个重要的方法是结合操作系统的各种工具观察系统资源使用状况
- 以及收集Java线程的DUMP信息,看线程都阻塞在什么方法上,了解原因,才能找到对应的解决方法。
JVM性能优化方向
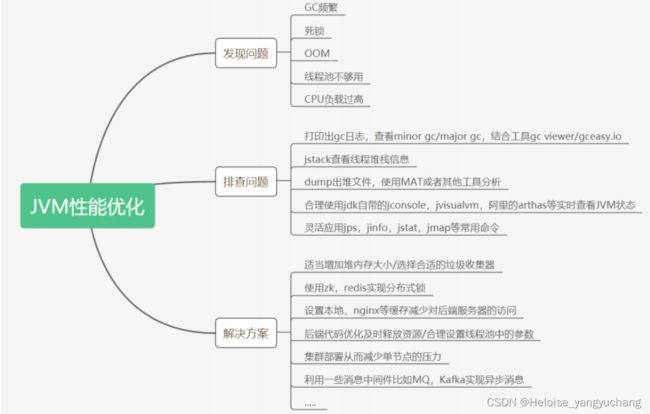
JVM常见面试题
(1)内存泄漏与内存溢出的区别
- 内存泄漏是指不再使用的对象无法得到及时的回收,持续占用内存空间,从而造成内存空间的浪费。
- 内存泄漏很容易导致内存溢出,但内存溢出不一定是内存泄漏导致的。
(2)Young GC会有stw吗?
- 不管什么GC,都会发送 stop‐the‐world,区别是发生的时间长短,主要取决于不同的垃圾收集器。
(3)Major gc和Full gc的区别
- 一般情况下,一次 Full GC 将会对年轻代、老年代、元空间以及堆外内存进行垃圾回收。
触发Full GC的原因其实有很多:
- 当年轻代晋升到老年代的对象大小,并比目前老年代剩余的空间大小还要大时,会触发 Full GC;
- 当老年代的空间使用率超过某阈值时,会触发 Fu ll GC;
- 当元空间不足时(JDK1.7永久代不足),也会触发 Full GC;
- 当调用 System.gc() 也会安排一次 Full GC。
(4)聊聊Minor GC、Major GC、Full GC发生的时机
- Minor GC:Eden或S区空间不足或发生了Major GC
- Major GC:Old区空间不足
- Full GC:Old空间不足,元空间不足,手动调用System.gc())
(5)为什么要区分新生代和老年代
- 当前虚拟机的垃圾收集都采用分代收集算法
- 一般将 java 堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法
- 如在新生代中,每次收集都会有大量对象死去,所以可以选择复制算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。
- 而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记‐清除”或“标记‐整理”算法进行垃圾收集。
(6)为什么需要Survivor区
- 如果没有Survivor,Eden区每进行一次Minor GC,存活的对象就会被送到老年代
- 这样一来,老年代很快被填满,触发Major GC
- 老年代的内存空间远大于新生代,进行一次Full GC消耗的时间比Minor GC长得多。执行时间长有什么坏处?频发的Full GC消耗的时间很长,会影响 大型程序的执行和响应速度。
(7)为什么需要两个Survivor区
- 最大的好处就是解决了内存碎片问题
假设现在只有一个Survivor区,我们来模拟一下流程: 刚刚新建的对象在Eden中,一旦Eden满了,触发一次Minor GC,Eden中的存活对象就会被移动到Survivor区。 这样继续循环下去,下一次Eden满了的时候,问题来了,此时进行Minor GC,Eden和Survivor各有一些存活对象, 如果此时把Eden区的存活对象硬放到Survivor区,很明显这两部分对象所占有的内存是不连续的,也就导致了内存碎片化。 永远有一个Survivor是空的,另一个非空的Survivor无碎片。
(8)什么样的情况下对象会进入Old区?
- a‐大对象
- b‐到了GC年龄阈值
- c-动态对象年龄判断
- d-担保机制
(9)堆内存中的对象都是所有线程共享的吗?
- JVM默认为每个线程在Eden上开辟一个buffer区域,用来加速对象的分配,称之为TLAB,全称:Thread Local
Allocation Buffer。 - 对象优先会在TLAB上分配,但是TLAB空间通常会比较小,如果对象比较大,那么还是在共享区域分配。
(10)Java虚拟机栈的深度越大越好吗?
- 线程栈的大小是个双刃剑,如果设置过小,可能会出现栈溢出,特别是在该线程内有递归、大的循环时出现溢出的可能性更大
- 如果该值设置过大, 就有影响到创建栈的数量,如果是多线程的应用,就会出现内存溢出的错误
(11)方法区中的类信息会被回收吗?
- 方法区主要回收的是无用的类
“无用的 类”的条件则相对苛刻许多。类需要同时满足下面 3 个条件才能算是 “无用的类”
- a‐该类所有的实例都已经被回收,也就是 Java 堆中不存在该类的任何实例。
- b‐加载该类的 ClassLoader 已经被回收。
- c‐该类对应的 java.lang.Class 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
(12)CMS与G1的区别
- CMS 主要集中在老年代的回收,而 G1 集中在分代回收,包括了年轻代的 Young GC 以及老年代的 Mixed GC。
- G1 使用了 Region 方式对堆内存进行了划分,且基于标记整理算法实现,整体减少了垃圾碎片的产生。
- G1可以设置一个期望的停顿时间。
- 在初始化标记阶段,搜索可达对象使用到的 Card Table,其实现方式不一样。
(13)垃圾收集器一般如何选择
- a‐用默认的
- b‐关注吞吐量:使用Parallel
- c‐关注停顿时间:使用CMS、G1
- d‐内存超过8GB:使用G1
- e‐内存很大或希望停顿时间几毫秒级别:使用ZGC
不过目前主流的还是jdk8和jdk11,一般情况下建议优先现在G1
(14)什么是方法内联?
正常调用方法时,会不断地往Java虚拟机栈中存放新的栈帧,这样开销比较大,其实jvm虚拟机内部为了节省这样开销,可以把一些方法放到同一个 栈帧中执行。
(15)不可达的对象一定要被回收吗?
即使在可达性分析法中不可达的对象,也并非是“非死不可”的,这时候它们暂时处于“缓刑阶段”,要真 正宣告一个对象死亡,至少要经历两次标记过程;可达性分析法中不可达的对象被第一次标记并且进行 一次筛选,筛选的条件是此对象是否有必要执行 finalize 方法。当对象没有覆盖 finalize 方法,或 finalize 方法已经被虚拟机调用过时,虚拟机将这两种情况视为没有必要执行。
如果对象被判定为有必要执行 finalize() 方法,则会被放入 F-Queue 队列中,并在稍后由一条 由虚拟机自动创建、低调度优先级的Finalizer线程去 “执行” 他们的 finalize() 方法,收集器稍后会对 F-Queue 队列中的对象进行第二次小规模的标记,如果此时该对象重新与引用链上任何一个对象建立了关联,则该对象就可以逃脱死亡的命运,即可以不用被 GC 回收,否则就会被真的回收。
(16)什么是直接内存
Java的NIO库允许Java程序使用直接内存。直接内存是在java堆外的、直接向系统申请的内存空间。通 常访问直接内存的速度会优于Java堆。因此出于性能的考虑,读写频繁的场合可能会考虑使用直接内存。由于直接内存在java堆外,因此它的大小不会直接受限于Xmx指定的最大堆大小,但是系统内存是 有限的,Java堆和直接内存的总和依然受限于操作系统能给出的最大内存。