FPN网络结构+源码讲解
前言
这几天在读CVPR2021的中稿论文YOLOF(You Only Look One-level Feature),文章回顾了单阶段的特征金字塔网络(FPN),指出FPN的成功的原因在于它对目标检测中优化问题的分而治之的解决策略,而不是多尺度特征融合。之前虽然经常看到特征金字塔相关结构,却也没有深入研究过,今天借着YOLOF把FPN的网络结构特征简要总结一下。
01
特征金字塔是多尺度(muiti-scale) 目标检测领域中的重要组成部分,但是由于此方法对计算和内存的需求,在FPN之前的深度学习任务都刻意回避了这类模型。在这篇文章中,作者利用深度神经网络固有的多尺度、多层级的金字塔结构,使用一种 自上而下的侧边连接 在所有尺度上构建出高级语义特征图,构造了特征金字塔的经典结构。
具体做法其实并不难理解:
把低分辨率、高语义信息的高层特征和高分辨率、低语义信息的低层特征自上而下进行融合,使得所有尺度下的特征都有丰富的语义信息。

02
当然,FPN并非只有上图所示的一种结构,下面大体介绍一下特征金字塔网络:
Featurized image pyramid
一种比较笨的多尺度方法,对输入图像设置不同的缩放比例实现多尺度。这样可以解决多尺度,但是相当于训练了多个模型(假设要求输入大小固定),即便允许输入大小不固定,但是也增加了存储不同尺度图像的内存空间。

Single feature map
其实就是早期的CNN模型,通过卷积层不断学习图像的高级语义特征。

Pyramidal feature hierarchy
SSD较早尝试了使用CNN金字塔形的层级特征,重用了前向过程计算出的多尺度特征图,因此这种形式是不消耗额外的资源的。但是SSD为了避免使用low-level的特征,放弃了浅层的特征图信息,直接从conv4_3开始建立金字塔,并且加入了一些新的层,但是这些低层级、高分辨率的特征图信息对检测小目标是非常重要的。

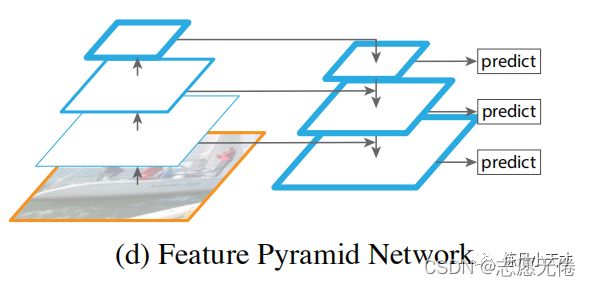
Feature Pyramid Network
FPN为了能够自然地利用CNN层级特征的金字塔形式,同时生成在所有尺度上都具有强语义信息的特征金字塔,便以此为目的设计了top-down结构和lateral connection。这种金字塔结构以此融合具有高分辨率的浅层feature和具有丰富语义信息的深层feature。这样就实现了从单尺度的单张输入图像,快速构建在所有尺度上都具有强语义信息的特征金字塔,同时不产生明显的代价。
03
那么,如何做到top-down和
lateral connection呢?
top-down
def _upsample_add(self, x, y):
_,_,H,W = y.size()
return F.upsample(x, size=(H,W), mode='bilinear') + y
也就是说,这里的实现使用的是最简单的上采样,没有使用线性插值,没有使用反卷积,而是直接复制。
lateral connection
# init Lateral layers,其实就是做通道匹配任务
self.latlayer1 = nn.Conv2d(1024, 256, kernel_size=1, stride=1, padding=0)
self.latlayer2 = nn.Conv2d( 512, 256, kernel_size=1, stride=1, padding=0)
self.latlayer3 = nn.Conv2d( 256, 256, kernel_size=1, stride=1, padding=0)
# forward
p4 = self._upsample_add(p5, self.latlayer1(c4))
p3 = self._upsample_add(p4, self.latlayer2(c3))
p2 = self._upsample_add(p3, self.latlayer3(c2))

结合上图我们可以理解这篇文章的核心思路:
通过2xup-sample,我们得到了上层传递下来的高层语义特征,其尺寸大小与lateral connection过程中的低层特征图尺寸相同;
通过1x1 conv,将高层特征通道数与低层特征通道数统一,解决了融合(sum)过程中channel数不匹配的问题。
04
FPN自上而下的网络结构代码怎么实现?
'''FPN in PyTorch.
See the paper "Feature Pyramid Networks for Object Detection" for more details.
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, in_planes, planes, stride=1):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(in_planes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, self.expansion*planes, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(self.expansion*planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != self.expansion*planes:
self.shortcut = nn.Sequential(
nn.Conv2d(in_planes, self.expansion*planes, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(self.expansion*planes)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = F.relu(self.bn2(self.conv2(out)))
out = self.bn3(self.conv3(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class FPN(nn.Module):
def __init__(self, block, num_blocks):
super(FPN, self).__init__()
self.in_planes = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
# Bottom-up layers
self.layer1 = self._make_layer(block, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(block, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(block, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(block, 512, num_blocks[3], stride=2)
# Top layer
self.toplayer = nn.Conv2d(2048, 256, kernel_size=1, stride=1, padding=0) # Reduce channels
# Smooth layers
self.smooth1 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.smooth2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.smooth3 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
# Lateral layers
self.latlayer1 = nn.Conv2d(1024, 256, kernel_size=1, stride=1, padding=0)
self.latlayer2 = nn.Conv2d( 512, 256, kernel_size=1, stride=1, padding=0)
self.latlayer3 = nn.Conv2d( 256, 256, kernel_size=1, stride=1, padding=0)
def _make_layer(self, block, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def _upsample_add(self, x, y):
'''Upsample and add two feature maps.
Args:
x: (Variable) top feature map to be upsampled.
y: (Variable) lateral feature map.
Returns:
(Variable) added feature map.
Note in PyTorch, when input size is odd, the upsampled feature map
with `F.upsample(..., scale_factor=2, mode='nearest')`
maybe not equal to the lateral feature map size.
e.g.
original input size: [N,_,15,15] ->
conv2d feature map size: [N,_,8,8] ->
upsampled feature map size: [N,_,16,16]
So we choose bilinear upsample which supports arbitrary output sizes.
'''
_,_,H,W = y.size()
return F.upsample(x, size=(H,W), mode='bilinear') + y
def forward(self, x):
# Bottom-up
c1 = F.relu(self.bn1(self.conv1(x)))
c1 = F.max_pool2d(c1, kernel_size=3, stride=2, padding=1)
c2 = self.layer1(c1)
c3 = self.layer2(c2)
c4 = self.layer3(c3)
c5 = self.layer4(c4)
# Top-down
p5 = self.toplayer(c5)
p4 = self._upsample_add(p5, self.latlayer1(c4))
p3 = self._upsample_add(p4, self.latlayer2(c3))
p2 = self._upsample_add(p3, self.latlayer3(c2))
# Smooth
p4 = self.smooth1(p4)
p3 = self.smooth2(p3)
p2 = self.smooth3(p2)
return p2, p3, p4, p5
05
总之,FPN最主要的意图就是把高层的特征传下来,补充低层的语义,这样就可以在具有高分辨率的底层网络中获得强语义的高层特征,有利于小目标的检测。