GaussDB数据库SQL系列-数据去重
目录
一、前言
二、数据去重应用场景
三、数据去重案例(GaussDB)
1、示例场景描述
2、定义重复数据
3、制定去重规则
4、创建测试数据(GaussDB)
5、编写去重方法(GaussDB)
6、附:全字段去重
四、数据去重效率提升建议
五、总结
一、前言
数据去重在数据库中是比较常见的操作。复杂的业务场景、多业务线的数据来源等等,都会带来重复数据的存储。本文以GaussDB数据库为实验平台,将为大家详细讲解如何去重。
二、数据去重应用场景
- 数据库管理(含备份):在数据库中进行数据去重可以避免数据重复存储、备份,提高数据库的存储效率、降低备份的存储成本。
- 数据集成:在数据集成的过程中,需要合并多个数据源的数据,去重可以避免重复的数据对合并结果的影响。
- 数据分析(或挖掘):在进行数据分析或数据挖掘时,去重可以避免重复的数据对分析或挖掘结果的干扰,提高分析的准确性。
- 电商平台:在电商平台上进行商品去重可以避免重复上架相同的商品,提高平台的用户体验。
- 金融风控:在金融风控领域,去重可以避免重复的数据对风控模型的影响,提高风控的准确性。
三、数据去重案例(GaussDB)
实战业务场景 + GaussDB数据库
1、示例场景描述
以保险行业的客户信息除重为例,为防止坐席重复联系客户(容易造成客户投诉),需要将客户进行唯一身份识别。存在以下两种情况,需要将其识别成一个人(唯一),这时候就需要进行数据去重的动作。
- 情况一:同一个客户有不同的来源渠道:客户即购买了寿险、又购买了产险(两个不同的来源系统);
- 情况二:同一个客户多次回流:客户在同一个渠道多次购买(续保或者购买同一险种的不同产品)。
2、定义重复数据
通过“姓名+证件类型+证件号”将其识别为一个人,即只要这三个字段重复,就认为这些数据行为重复数据。 (当然还有更复杂的场景,例如,“姓名+证件类型+证件号+手机号+车牌号”等,本次不做详细介绍)。

3、制定去重规则
1)多选一
- 随机:根据去重规则,随机保留一条数据。
- 优先级:根据去重规则 + 业务逻辑,保留优先需要的一条数据。例如优先保留“是否有房、是否有车”。
2)多合一
- 将重复数据合并成一条数据,合并规则根据业务逻辑确定。
4、创建测试数据(GaussDB)
客户信息字段主要包含“姓名、性别、出生年月日、证件类型、证件号、来源、是否有车、是否有房、婚姻状态、手机号、……”等信息。
--创建客户信息表
CREATE TABLE customer(
name VARCHAR(20)
,sex INT
,birthday VARCHAR(10)
,ID_type INT
,ID_number VARCHAR(20)
,source VARCHAR(10)
,IS_car INT
,IS_house INT
,marital_status INT
,tel_number VARCHAR(15)
);
--插入测试数据
INSERT INTO customer VALUES('张三','1','1988-01-01','1','61010019880101****','寿险','1','1','1','');
INSERT INTO customer VALUES('张三','1','1988-01-01','1','61010019880101****','车险','1','0','1','');
INSERT INTO customer VALUES('张三','1','1988-01-01','1','61010019880101****','','','','','186****0701');
INSERT INTO customer VALUES('李四','1','1989-01-02','1','61010019890102****','寿险','1','1','1','');
INSERT INTO customer VALUES('李四','1','1989-01-02','1','61010019890102****','车险','1','0','1','');
INSERT INTO customer VALUES('李四','1','1989-01-02','1','61010019890102****','','','','','186****0702');
--查看结果
SELECT * FROM customer;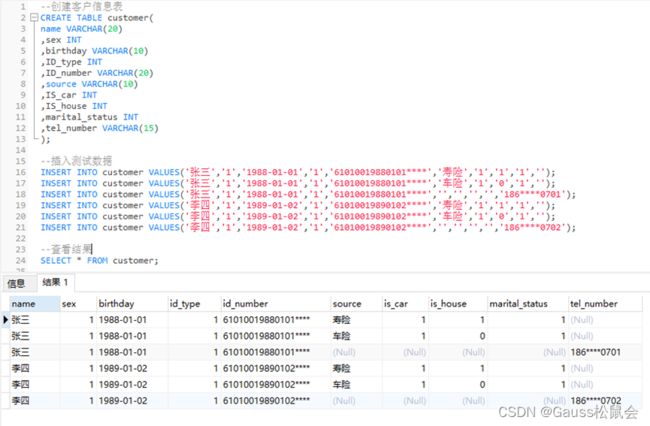
Tip: 部分为INT类型的字段值取字典表的值,此处省。
5、编写去重方法(GaussDB)
以下示例中不包含过多的数据清洗、数据脱敏、业务逻辑等的处理,这些步骤均建议进行“前置”处理。本次示例重点描述去重的过程。
1)随机保留:根据业务逻辑,随机保留一条记录。
SELECT *
FROM (SELECT *
,ROW_NUMBER() OVER (PARTITION BY name,id_type,id_number ) as row_num
FROM customer)
WHERE row_num = 1;
说明:
- ROW_NUMBER(): 从第一行开始,依次为每一行分配一个唯一且连续的编号。
- PARTITION BY col1[, col2...]: 指定分区的列,例如去重的键“姓名、证件类型、证件号码”。
- WHERE row_num = 1:取ROW_NUMBER()生成的编号1。
2)按优先级保留:根据业务逻辑,优先保留有手机号的一条记录,如果有多条记录含有手机号或有没有手机号,则在此基础上随机保留。
--保留含有手机号的记录行
SELECT t.*
FROM (SELECT *
,ROW_NUMBER() OVER (PARTITION BY name,id_type,id_number ORDER BY tel_number ASC) as row_num
FROM customer) t
WHERE t.row_num = 1;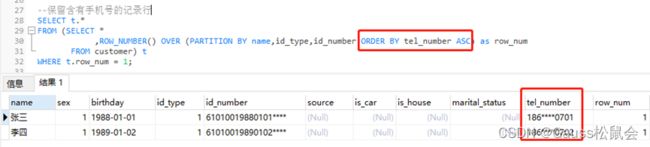
说明:
- ROW_NUMBER(): 从第一行开始,依次为每一行分配一个唯一且连续的号码。
- PARTITION BY col1[, col2...]: 指定分区的列,例如去重的键“姓名、证件类型、证件号码”。
- ORDER BY col [asc|desc]: 指定排序的列。升序( ASC )排列指只保留第一行,而降序排列( DESC )则指保留最后一行。
- WHERE row_num = 1:取ROW_NUMBER()生成的编号1。
3)合并保留:根据业务逻辑,合并完整性高、准确性高的字段信息。例如优先将含有手机号的记录行进行补齐,需要补齐的字段有“是否有车、是否有房、婚姻状况”,其取值是来源为“车险”的对应记录。
--合并保留
SELECT t1.name
,t1.sex
,t1.birthday
,t1.id_type
,t1.id_number
,t1.source
,t2.is_car
,t2.is_house
,t2.marital_status
,t1.tel_number
FROM
(SELECT t.*
FROM (SELECT *
,ROW_NUMBER() OVER (PARTITION BY name,id_type,id_number ORDER BY tel_number ASC) as row_num
FROM customer) t
WHERE t.row_num = 1) t1
LEFT JOIN
(SELECT *
FROM customer
WHERE source ='车险' and is_car IS NOT NULL AND is_house IS NOT NULL AND marital_status IS NOT NULL) t2
ON t1.name =t2.name
and t1.id_type=t2.id_type
and t1.id_number=t2.id_number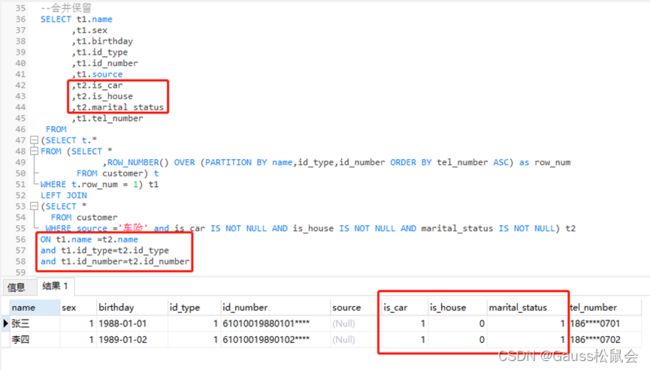
说明:
t1 表是优先保留含有手机的记录行(去重),并作为主表,t2表是需要补齐的字段来源表。两张表通过“姓名+证件类型+证件号码”进行关联,然后合并需要的信息。
6、附:全字段去重
在数据库应用时,例如,重复误操作、数据翻倍等原因造成的全字段重复,此时也要进行去重。 那除了前面介绍的3种方式外,大家还可以使用关键字DISTINCT、UNION 进行去重,但需要注意其数据量及SQL 性能。 (大家自行测试)
1) DISTINCT (假设全部有如下三个字段)
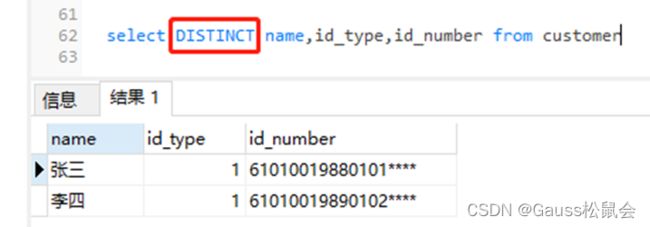
2) UNION(假设全部有如下三个字段)

四、数据去重效率提升建议
最好的去重其实是在数据源头就进行“拦截”。当然了, 因业务流转也不可能完全避免,但是我们可以提高去重的效率:
- 选择合适的去重算法:根据数据集的特点和规模,选择适合的去重算法,可以大大提高去重效率。
- 优化数据存储结构:采用合适的数据存储结构,如哈希表、B+树等,可以加快数据的查找和比较速度,从而提高去重效率。
- 并行化处理:采用并行化处理的方式,将数据集分成多个子集,分别进行去重处理,最后合并结果,可以大大加快去重速度。
- 使用索引加速查找:对数据集中的关键字段建立索引,可以加速查找和比较速度,从而提高去重效率。
- 前置过滤:采用前置过滤的方式,先对数据集进行一些简单的筛选和处理,如去除空值、去除无效字符等,可以减少比较次数,从而提高去重效率。
- 去重结果缓存(临时表):对去重结果进行缓存,可以避免重复计算,从而提高去重效率。
- 不建议重写(备份):涉及一些分区表,等不建议直接将去重后的结果集重写到生产表,创建临时换成,或进行备份后操作。
五、总结
数据去重涉及到的面非常广,包括重复数据的发现、去重规则的定义、去重的方法与效率、去重的困难与挑战等等。但是,去重原则只有一个,那就是以业务为导向。根据业务需求去定义重复数据、制定去重规则和方案。在GaussDB数据库的使用过程,我们同样会遇到去重的场景。本文从应用背景、案例、去重方案等方面给大家做了介绍,欢迎测试、交流。
——结束