简化转换器:使用您理解的单词进行最先进的 NLP — 第 1 部分 — 输入

一、说明
变形金刚是一种深度学习架构,为人工智能的发展做出了杰出贡献。这是人工智能和整个技术领域的一个重要阶段,但也有点复杂。截至今天,变形金刚上有很多很好的资源,那么为什么要再制作一个呢?两个原因:
- 我精通自学,根据我的经验,能够阅读不同的人如何描述相同的想法极大地增强了理解。
- 我很少读一篇文章,并认为它的解释足够简单。技术内容创作者总是倾向于过度复杂化或解释不足的概念。应该很清楚,没有什么是火箭科学,甚至火箭科学也不是。你可以理解任何事情,你只需要一个足够好的解释。在本系列中,我试图做出足够好的解释。
本系列将尝试为那些对人工智能几乎一无所知的人和那些知道机器学习的人提供一个合理的指导。在本系列中,我打算假设你知道的比我在准备本系列时阅读的变形金刚文章要精炼。
此外,我将结合直觉、数学、代码和可视化,使该系列的设计像糖果店一样——适合每个人。考虑到这是一个相当复杂的领域的高级概念,我会冒着你的想法的风险:“哇,这太慢了,停止解释明显的东西”,但如果你对自己说:“他到底在说什么?
二、变形金刚,值得你花时间吗?
有什么大惊小怪的?真的有那么重要吗?好吧,因为它是世界上一些最先进的人工智能驱动技术工具(例如GPT等)的基础,所以它可能是。
尽管与许多科学进步一样,之前已经描述了一些想法,但对架构的实际深入,完整的描述来自“注意力是你所需要的一切”论文,该论文声称以下内容是“简单的网络架构”。

如果你像大多数人一样,你不会认为这是一个简单的网络架构。因此,我的工作是努力,当你读完这个系列时,你会想:这仍然不简单,但我确实明白了。
那么,这个疯狂的图表,到底是什么?
我们看到的是一个深度学习架构,这意味着这些方块中的每一个都应该被翻译成一段代码,所有这些代码一起将做一些事情,到目前为止,人们真的不知道该怎么做。
变压器可以应用于许多不同的用例,但最著名的可能是自动聊天。一个可以谈论许多主题的软件,就好像它知道很多一样。在某种程度上类似于矩阵。
我想让人们更容易只阅读他们真正需要的东西,这样这个系列就会根据我认为变形金刚故事应该被讲述的方式进行分解。第一部分在这里,它将是关于架构的第一部分 - 输入。
三、输入
龙从蛋中孵化,婴儿从肚子里冒出来,人工智能生成的文本从输入开始。我们都必须从某个地方开始。
什么样的输入?这取决于手头的任务。如果你正在构建一个语言模型,一个知道如何生成相关文本的软件(变形金刚架构在各种场景中很有用),输入是文本。尽管如此,计算机能否接收任何类型的输入(文本、图像、声音)并神奇地知道如何处理它?其实不然。
我相信你认识一些不太擅长文字但擅长数字的人。计算机就是这样。它不能直接在CPU/GPU(计算发生的地方)中处理文本,但它肯定可以处理数字!正如您很快就会看到的,将这些单词表示为数字的方式是秘诀中的关键成分。
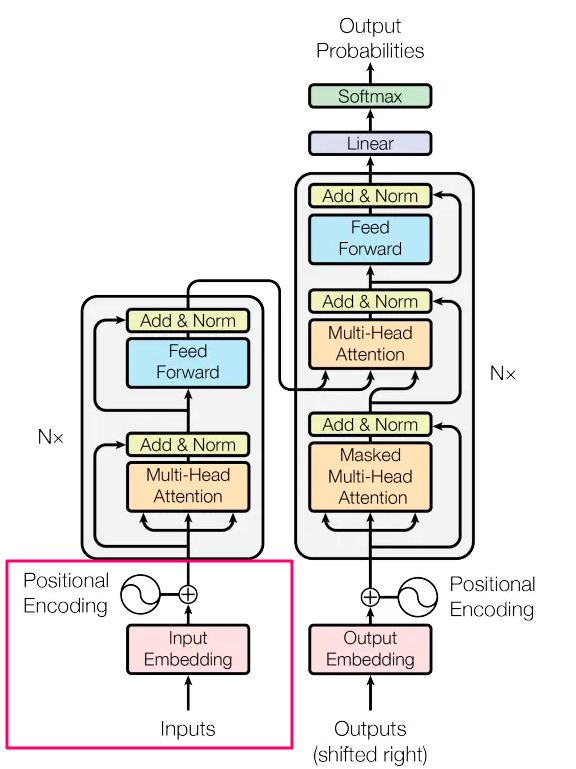
图片来自Vaswani,A.等人的原始论文。
3.1 分词器
标记化是将语料库(您拥有的所有文本)转换为机器可以更好地利用的较小部分的过程。假设我们有一个包含 10,000 篇维基百科文章的数据集。我们获取每个字符并对其进行转换(标记化)。有很多方法可以标记文本,让我们看看OpenAI的标记器如何使用以下文本来实现:
“许多词映射到一个令牌,但有些则不是:不可分割。
像表情符号这样的 Unicode 字符可以拆分为许多包含基础字节的标记:
通常彼此相邻的字符序列可以组合在一起:1234567890"
这是标记化结果:

图片来自OpenAi,取自此处
如您所见,大约有 40 个单词(取决于您的计数方式(标点符号)。在这 40 个单词中,生成了 64 个令牌。有时标记是整个单词,如“Many,words,map”,有时它是一个单词的一部分,如“Unicode”。为什么我们要把整个单词分成更小的部分?为什么还要分句?我们本可以让他们保持联系。最后,无论如何它们都会转换为数字,那么如果令牌的长度是 3 个字符还是 30 个字符,计算机的观点有什么区别?
令牌有助于模型学习,因为文本是我们的数据,所以它们是数据的特征。设计这些功能的不同方法将导致性能变化。例如,在句子“滚出去!!!!!!”中,我们需要确定多个“!”是否与一个不同,或者它是否具有相同的含义。从技术上讲,我们可以将句子作为一个整体,但是想象一下,单独观察人群与每个人,在哪种情况下你会得到更好的见解?
现在我们有了令牌,我们可以构建一个查找字典,使我们能够摆脱单词并使用索引(数字)。例如,如果我们的整个数据集是句子:“上帝在哪里”。我们可以构建这种词汇表,它只是单词的键:值对和表示它们的单个数字。我们不必每次都使用整个单词,我们可以使用数字。例如:{其中:0,是:1,上帝:
2}。 每当我们遇到“是”这个词时,我们都会用1代替它。有关更多代币化器的示例,您可以查看Google开发的令牌器或使用OpenAI的TikToken玩更多内容。
3.2 从字到矢量
直觉
我们在将单词表示为数字的旅程中取得了很大进展。下一步是从这些标记生成数字语义表示。为此,我们可以使用一种名为Word2Vec的算法。细节目前不是很重要,但主要思想是你取一个向量(我们现在将简化,考虑一个常规列表)任何大小的数字(论文的作者使用了512),这个数字列表应该代表一个单词的语义含义。想象一个数字列表,如[-2,4,-3.7,41...-0.98],它实际上保存了一个单词的语义表示。它应该以这样的方式创建,如果我们在 2D 图上绘制这些向量,则相似项将比不同项更接近。
正如你在图片中看到的(从这里拍摄),“婴儿”接近“aw”和“睡着”,而“公民”/“州”/“美国”也在某种程度上组合在一起。
*2D词向量(又名2个数字的列表)即使对于一个单词也无法保持任何准确的含义,如前所述,作者使用了512个数字。由于我们无法绘制具有 512 个维度的任何内容,因此我们使用一种称为 PCA 的方法将维度数量减少到两个,希望保留大部分原始含义。在本系列的第 3 部分中,我们将深入了解这种情况是如何发生的。

Word2Vec 2D演示文稿 - 图片来自Piere Mergret。
它有效!您实际上可以训练一个模型,该模型将能够生成具有语义意义的数字列表。计算机不知道婴儿是一个尖叫的,剥夺睡眠的(超级甜蜜的)小人,但它知道它通常会在“aw”周围看到婴儿这个词,比“国家”和“政府”更常见。我会写更多关于这种情况是如何发生的,但在那之前,如果你有兴趣,这可能是一个查看的好地方。
这些“数字列表”非常重要,因此它们在 ML 术语中有自己的名称,即嵌入。为什么要嵌入?因为我们正在执行嵌入(如此有创意),这是将术语从一种形式(单词)映射到另一种形式(数字列表)的过程。这些是很多()。
从这里开始,我们将调用单词,嵌入,正如所解释的那样,它们是数字列表,这些数字包含它被训练表示的任何单词的语义含义。
3.3 使用 Pytorch 创建嵌入
我们首先计算我们拥有的唯一代币的数量,为简单起见,假设为 2。嵌入层的创建是 Transformer 体系结构的第一部分,就像编写以下代码一样简单:
*一般代码备注 — 不要将此代码及其约定视为良好的编码风格,它是专门为使其易于理解而编写的。
代码:
import torch.nn as nn
vocabulary_size = 2
num_dimensions_per_word = 2
embds = nn.Embedding(vocabulary_size, num_dimensions_per_word)
print(embds.weight)
---------------------
output:
Parameter containing:
tensor([[-1.5218, -2.5683],
[-0.6769, -0.7848]], requires_grad=True) 我们现在有一个嵌入矩阵,在这种情况下是一个 2 x 2 矩阵,由从正态分布 N(0,1) 派生的随机数生成(例如,均值为 0 且方差为 1 的分布)。
请注意requires_grad=True,这是Pytorch语言,表示这4个数字是可学习的权重。它们可以并且将在学习过程中进行自定义,以更好地表示模型接收的数据。
在更现实的情况下,我们可以期待更接近 10k x 512 的矩阵,它以数字表示我们的整个数据集。
vocabulary_size = 10_000
num_dimensions_per_word = 512
embds = nn.Embedding(vocabulary_size, num_dimensions_per_word)
print(embds)
---------------------
output:
Embedding(10000, 512) *有趣的事实(我们可以想到更有趣的事情),你有时会听到语言模型使用数十亿个参数。这个初始的,不太疯狂的层,包含 10_000 x 512 个参数,即 5 万个参数。这个LLM(大语言模型)是困难的东西,它需要大量的计算。
这里的参数是这些数字(-1.525 等)的一个花哨的词,只是它们可能会发生变化,并且在训练期间会发生变化。
这些数字是机器的学习,这就是机器正在学习的。稍后,当我们给它输入时,我们将输入与这些数字相乘,我们希望得到一个好的结果。你知道什么,数字很重要。当你很重要时,你会得到自己的名字,所以这些不仅仅是数字,这些是参数。
为什么使用多达 512 而不是 5?因为更多的数字意味着我们可以产生更准确的含义。太好了,别想小了,那就用一百万吧!为什么不呢?因为更多的数字意味着更多的计算,更多的计算能力,更高的训练成本等等,512被发现是中间的好地方。
3.4 序列长度
在训练模型时,我们将把一大堆单词放在一起。它的计算效率更高,并且有助于模型学习,因为它将更多的上下文放在一起。如前所述,每个单词都将由一个 512 维向量(包含 512 个数字的列表)表示,每次我们将输入传递给模型(也称为正向传递)时,我们将发送一堆句子,而不仅仅是一个。例如,我们决定支持 50 个单词的序列。这意味着我们将在一个句子中取 x 个单词,如果 x > 50 我们拆分它并只取前 50 个,如果 x < 50,我们仍然需要大小完全相同(我很快就会解释为什么)。为了解决这个问题,我们在句子的其余部分添加了填充,这是特殊的虚拟字符串。例如,如果我们支持一个 7 个单词的句子,并且我们有句子“上帝在哪里”。我们添加 4 个填充,因此模型的输入将是“上帝在哪里
* 为什么所有输入向量的大小必须相同?因为软件有“期望”,矩阵有更严格的期望。你不能做任何你想要的“数学”计算,它必须遵守某些规则,其中一个规则是足够的向量大小。
3.5 位置编码
直觉
我们现在有一种方法可以在我们的词汇表中表示(和学习)单词。让我们通过对单词的位置进行编码来使其变得更好。为什么这很重要?因为如果我们取这两句话:
1. 男人玩我的猫
2.猫和我的男人一起玩
我们可以使用完全相同的嵌入来表示这两个句子,但句子的含义不同。我们可以想到这样的数据,其中顺序无关紧要。如果我计算某事的总和,我们从哪里开始并不重要。在语言中——顺序通常很重要。嵌入包含语义含义,但没有确切的顺序含义。它们在某种程度上确实保持了秩序,因为这些嵌入最初是根据某种语言逻辑创建的(婴儿看起来更接近睡眠,而不是状态),但同一个词本身可以有多个含义,更重要的是,当它处于不同的上下文中时,它的含义不同。
将单词表示为没有顺序的文本是不够的,我们可以改进这一点。作者建议我们在嵌入中添加位置编码。我们通过计算每个单词的位置向量并将其相加(求和)两个向量来做到这一点。位置编码向量必须具有相同的大小,以便可以添加它们。位置编码的公式使用两个函数:正弦表示偶数位置(例如第 0 个单词、2d 单词、第 4 个、第 6 个等)和余弦表示奇数位置(例如第 1、3、5 个等)。
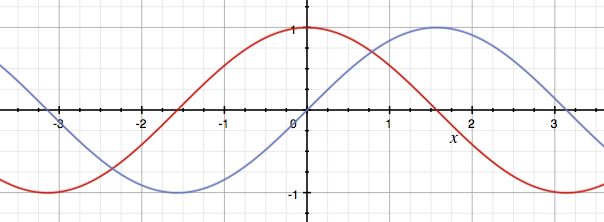
可视化
通过查看这些函数(红色的sin,蓝色的余弦),你也许可以想象为什么特别选择这两个函数。函数之间存在一些对称性,就像单词和它前面的单词之间存在对称性一样,这有助于建模(表示)这些相关位置。此外,它们输出从 -1 到 1 的值,这是非常稳定的数字(它们不会变得超大或超小)。

Formula image from the original paper by Vaswani, A. et al.
在上面的公式中,上行表示从 0 (i = 0) 开始的偶数,并继续为偶数 (2*1、2*2、2*3)。第二行以相同的方式表示奇数。
每个位置向量都是一个 number_of_dimensions(在我们的例子中为 512)向量,数字从 0 到 1。
代码
from math import sin, cos
max_seq_len = 50
number_of_model_dimensions = 512
positions_vector = np.zeros((max_seq_len, number_of_model_dimensions))
for position in range(max_seq_len):
for index in range(number_of_model_dimensions//2):
theta = pos / (10000 ** ((2*i)/number_of_model_dimensions))
positions_vector[position, 2*index ] = sin(theta)
positions_vector[position, 2*index + 1] = cos(theta)
print(positions_vector)
---------------------
output:
(50, 512)如果我们打印第一个单词,我们看到我们只能互换得到 0 和 1。
print(positions_vector[0][:10])
---------------------
output:
array([0., 1., 0., 1., 0., 1., 0., 1., 0., 1.])第二个数字已经更加多样化。
print(positions_vector[1][:10])
---------------------
output:
array([0.84147098, 0.54030231, 0.82185619, 0.56969501, 0.8019618 ,
0.59737533, 0.78188711, 0.62342004, 0.76172041, 0.64790587])*代码灵感来自这里。
我们已经看到,不同的位置导致不同的表示。为了将部分输入作为一个整体(下图中以红色平方),我们将位置矩阵中的数字添加到输入嵌入矩阵中。我们最终得到一个与嵌入大小相同的矩阵,只是这次数字包含语义+顺序。

图片来自Vaswani,A.等人的原始论文。
四、总结
本系列的第一部分(红色矩形)到此结束。我们讨论了模型获取其输入。我们看到了如何将文本分解为其特征(标记),将它们表示为数字(嵌入)以及为这些数字添加位置编码的智能方法。
下文将将重点介绍编码器块(第一个灰色矩形)的不同机制,每个部分描述一个不同颜色的矩形(例如多头注意力,添加和规范等)。陈玛格丽特