RealBasicVSR模型转成ONNX以及用c++推理
文章目录
-
- 安装RealBasicVSR的环境
-
- 1. 新建一个conda环境
- 2. 安装pytorch(官网上选择合适的版本)版本太低会有问题
- 3. 安装 mim 和 mmcv-full
- 4. 安装 mmedit
- 下载RealBasicVSR源码
- 下载模型文件
- 写一个模型转换的脚步
- 测试生成的模型
- 用ONNX Runtime c++推理
- 效果:
安装RealBasicVSR的环境
1. 新建一个conda环境
conda create -n RealBasicVSR_to_ONNX python=3.8 -y
conda activate RealBasicVSR_to_ONNX
2. 安装pytorch(官网上选择合适的版本)版本太低会有问题
conda install pytorch==1.12.1 torchvision==0.13.1 torchaudio==0.12.1 cudatoolkit=11.6 -c pytorch -c conda-forge
3. 安装 mim 和 mmcv-full
pip install openmim
mim install mmcv-full
4. 安装 mmedit
pip install mmedit
下载RealBasicVSR源码
git clone https://github.com/ckkelvinchan/RealBasicVSR.git
下载模型文件
模型文件下载 (Dropbox / Google Drive / OneDrive) ,随便选一个渠道下载就行
cd RealBasicVSR
#然后新建文件夹model
将模型文件放在model文件夹下
写一个模型转换的脚步
import cv2
import mmcv
import numpy as np
import torch
from mmcv.runner import load_checkpoint
from mmedit.core import tensor2img
from realbasicvsr.models.builder import build_model
def init_model(config, checkpoint=None):
if isinstance(config, str):
config = mmcv.Config.fromfile(config)
elif not isinstance(config, mmcv.Config):
raise TypeError('config must be a filename or Config object, '
f'but got {type(config)}')
config.model.pretrained = None
config.test_cfg.metrics = None
model = build_model(config.model, test_cfg=config.test_cfg)
if checkpoint is not None:
checkpoint = load_checkpoint(model, checkpoint)
model.cfg = config # save the config in the model for convenience
model.eval()
return model
def main():
model = init_model("./configs/realbasicvsr_x4.py","./model/RealBasicVSR_x4.pth")
src = cv2.imread("./data/img/test1.png")
src = torch.from_numpy(src / 255.).permute(2, 0, 1).float()
src = src.unsqueeze(0)
input_arg = torch.stack([src], dim=1)
torch.onnx.export(model,
input_arg,
'realbasicvsr.onnx',
training= True,
input_names= ['input'],
output_names=['output'],
opset_version=11,
dynamic_axes={'input' : {0 : 'batch_size', 3 : 'w', 4 : 'h'}, 'output' : {0 : 'batch_size', 3 : 'dstw', 4 : 'dsth'}})
if __name__ == '__main__':
main()
这里报错:
ValueError: SRGAN model does not support `forward_train` function.
直接将这个test_mode默认值改为Ture,让程序能走下去就行了。

测试生成的模型
这里已经得到了 realbasicvsr.onnx 模型文件了.
import onnxruntime as ort
import numpy as np
import onnx
import cv2
def main():
onnx_model = onnx.load_model("./realbasicvsr.onnx")
onnxstrongmodel = onnx_model.SerializeToString()
sess = ort.InferenceSession(onnxstrongmodel)
providers = ['CPUExecutionProvider']
options = [{}]
is_cuda_available = ort.get_device() == 'GPU'
if is_cuda_available:
providers.insert(0, 'CUDAExecutionProvider')
options.insert(0, {'device_id': 0})
sess.set_providers(providers, options)
input_name = sess.get_inputs()[0].name
output_name = sess.get_outputs()[1].name
print(sess.get_inputs()[0])
print(sess.get_outputs()[0])
print(sess.get_outputs()[0].shape)
print(sess.get_inputs()[0].shape)
img = cv2.imread("./data/img/test1.png")
img = np.expand_dims((img/255.0).astype(np.float32).transpose(2,0,1), axis=0)
imgs = np.array([img])
print(imgs.shape)
print(imgs)
output = sess.run([output_name], {input_name : imgs})
print(output)
print(output[0].shape)
output = np.clip(output, 0, 1)
res = output[0][0][0].transpose(1, 2, 0)
cv2.imwrite("./testout.png", (res * 255).astype(np.uint8))
if __name__ == '__main__':
main()
至此模型转换部分就成功完成了
用ONNX Runtime c++推理
根据cuda版本选择合适的onnxruntime版本
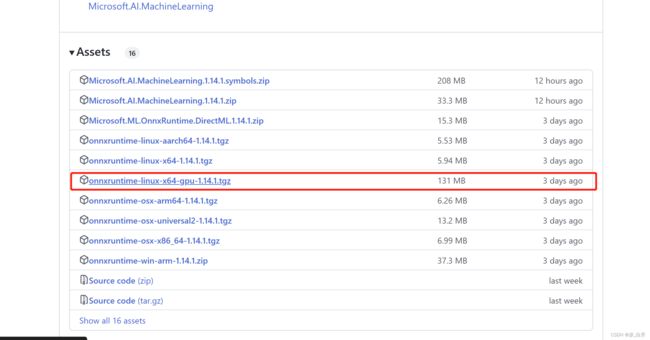
下载onnx runtime的运行环境 onnxruntime
我这里下载这个:
#include #include "ONNX/liangbaikai_RealBasicVSR_onnx.hpp"
int main(){
ONNX_RealBasicVSR orbv;
orbv.Init("../realbasicvsr.onnx");
cv::Mat img = cv::imread("../img/test1.png");
unsigned inputid = 0;
unsigned outputid = 1;
int W = img.cols, H = img.rows;
if(W > H){
cv::copyMakeBorder(img,img,0,W - H,0,0,cv::BORDER_REFLECT_101);
}else if(H > W){
cv::copyMakeBorder(img,img,0,0,0,H-W,cv::BORDER_REFLECT_101);
}
cv::Mat res = orbv.Run(img,inputid,outputid,true);
if(outputid == 1){
res = res(cv::Rect(0,0,W * 4,H * 4));
}else{
res = res(cv::Rect(0,0,W,H));
}
cv::imwrite("./tttttttfin.png",res);
return 0;
}
效果:

