Python自动化测试-Selenium-网页中元素定位最全详解
使用selenium框架实现web自动化测试
在搭建部署好环境后
我们需要了解怎么在网页中定位元素
因为代码不像人可以肉眼直接定位到不同的元素,我们需要通过特定的方式告诉程序操作的元素在哪里,再对元素进行操作,这就是元素的定位
目录
-
- 一. 元素定位
-
- 1.根据元素标签或元素属性进行定位
- 2.根据超链接的文本进行定位
- 3.xpath 元素路径定位
- 4.css选择器定位
- 5. By 方式定位
- 6. 下拉列表定位
-
- 6.1 对于 Select+Option方式
- 6.2 对于 ul+li 方式
- 二. 元素组定位
- 三. 元素的常用属性和方法
一. 元素定位
selenium的webdriver中提供了8种元素定位的方式,接下来分为6大类进行详细解释
1.根据元素标签或元素属性进行定位
使用 id name class_name tag_name
注意:前提是元素中包含有所需的属性,并且是唯一的, 这样才可以准确地定位到元素
在网页中选择所需定位的元素,右键检查或者查看元素
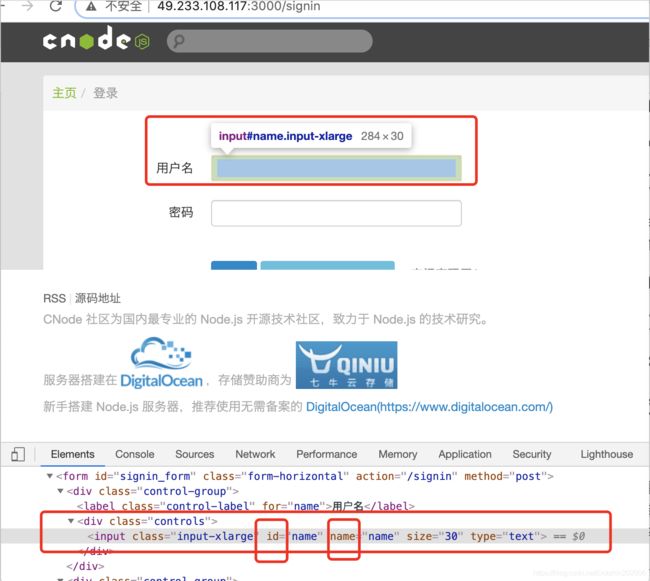
下段代码展示了在登录页面输入用户名和密码
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://49.233.108.117:3000/signin")
#在用户名中输入test28
ele_user = driver.find_element_by_id("name")
ele_user.send_keys("test28")
#在密码中输入123456
ele_pass = driver.find_element_by_id("pass")
ele_pass.send_keys("123456")
找到可以唯一标识该元素的属性后可以使用下列方法进行定位
driver.find_element_by_id()
driver.find_element_by_name()
driver.find_element_by_class_name()
driver.find_element_by_tag_name()
driver.find_elements_by_id()可以定位到一组元素,并且存放到列表中
2.根据超链接的文本进行定位
使用link_text 和 partitial_link_text 定位
同样的右键检查元素

在首页中下想要点击登录这个链接跳转到登录页面可以使用如下代码
driver = webdriver.Chrome()
driver.get("http://49.233.108.117:3000/")
driver.find_element_by_link_text("登录")
driver.find_element_by_link_text()可以使用超链接的文本定位
driver.find_element_by_patitial_link_text()
可以使用模糊匹配的超链接文本定位,避免文本过长
3.xpath 元素路径定位
有了前两种定位方式,为什么我们还需要使用xpath和css定位呢?
一方面有的元素可能没有id name 等属性
另一方面有的元素属性标签可能是动态值,随着刷新而变化
所以需要xpath和css来辅助定位
使用driver.find_element_by_xpath()方法
xpath: xml path
xml中指定元素路径的方式
获取元素的xpath也很简单
选中元素右键检查,再在开发者工具中右键选择复制XPath
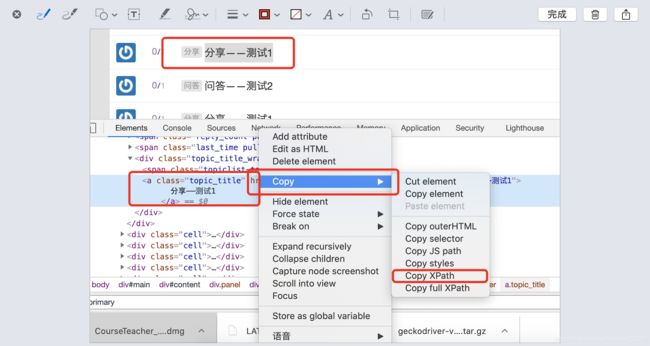
这里有两个选择
Copy XPath定位的是相对路径
//*[@id=“topic_list”]/div[4]/div/a
Copy full XPath定位的是绝对路径
/html/body/div[2]/div[2]/div/div[2]/div[1]/div[4]/div/a
这两种定位方式都可以进行定位
一般而言,更推荐使用相对路径
一是以为绝对路径写在代码中会很长
二是因为前端代码变更时,绝对路径可能会发生变化
代码示例
...
driver.find_element_by_xpath("//*[@id="topic_list"]/div[4]/div/a")
在具体使用中还可以使用多种方式相结合来定位
例如
xpath相对路径+元素属性
层级与属性结合——先定位父级元素,再用属性定位子元素(例如子元素没有唯一标识的特征时,可以这样定位)
属性与逻辑相结合定位
当元素的属性值重复时,只用该属性无法准确定位,我们可以用 and逻辑与 来同时用两个属性进行定位
driver.find_element_by_xpath("//*[@id="topic_list" and @title="分享——测试1"]/div[4]/div/a")
xpath的定位方式可以说是很方便也很强大啦~~
4.css选择器定位
使用driver.find_element_by_css_selector()方法
和xpath类似,在开发者工具中选中元素,右击复制css 选择器获取css selector
css选择器也有好几种
- id选择器 : #id的属性值 eg: #topic_list
- class选择器: .class的属性值 eg: .span_primary
- 元素选择器:使用元素标签名直接 标签名 eg: div (标签名对单个元素很少用)
- 属性选择器:[属性名=“属性值”] eg: [value=“登录”]
- 层级选择器:使用父级元素找到当前元素,语法是用> 或者空格代替
eg: #topic_list > div:nth-child(1) > div > a
...
driver.find_element_by_css_selector("#topic_list > div:nth-child(1) > div > a")
5. By 方式定位
driver.find_elements()
要另外导入By
from selenium.webdriver.common.by import By
这种方式在关键字封装时要经常用到
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Firefox()
driver.get("http://49.233.108.117:3000/signin")
driver.find_element(By.ID, 'name').send_keys('admin')
driver.find_element(By.NAME, 'pass').send_keys('123456')
driver.find_element(By.CLASS_NAME, 'span_primary').click()
6. 下拉列表定位
下拉列表的前端表现方式有两种
一种是 Select+Option
一种是 ul+li
两种表现方式的定位方式也有所不同
6.1 对于 Select+Option方式
这种常见于对日期的选择
步骤:
- 导包
- 定位到select元素
- 使用select类提供的方法进行列表的选择
示例代码
from selenium import webdriver
from selenium.webdriver.support import select
driver = webdriver.Firefox()
driver.get("https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc")
# 先定位到selector元素
ele_select = driver.find_element_by_id("cc_start_time")
# 用select类实例化
s = select.Select(ele_select)
#用文本选择
s.select_by_visible_text("18:00--24:00")
# 使用index选择
s.select_by_index(0)
# 用value选择
s.select_by_value("06001200")
6.2 对于 ul+li 方式
步骤:
- 先定位到ul,赋给变量a
- 再通过a定位到li选项
定位ul和li的方式可以使用xpath
二. 元素组定位
find_elements_by_xxx
定位一组元素,并存放到列表中
其他的和元素定位是一样的
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://49.233.108.117:3000/signin")
#定位标签为input的一组元素
eles = driver.find_elements_by_tag_name('input')
user = eles[1]
passwd = eles[2]
三. 元素的常用属性和方法
- size 获取元素的大小(控件的长和宽)
- location 获取元素位置坐标
- text 获取元素的文本值(但是该方法只能获取一对 a label p div标签里的值,对于value属性的值无法获取)
- get_attribute 获取元素的属性值
其他常用方法:
获取当前页面的url:
driver.current_url
获取当前页面的title:
driver.title
这两种方法可以用来验证打开的网页是否为期望的网页
示例代码:
...
ele = driver.find_element_by_id("cc_start_time")
# 获取元素大小
size = ele.size
width = size['width']
height = size['height']
# 获取元素坐标
location = ele.location
# 获取元素文本值,但是只能获取一对 a label p div标签里的值,对于value属性的值无法获取
label = ele.text
# 获取元素的属性值
attribute = ele.get_attribute("value")
# 获取当前页面的url
url = driver.current_url
# 获取当前页面的title
title = driver.title
...
以上就是元素定位的各种招式了,也是web自动化的基本操作
还需要在实践中灵活运用~
继续加油~