SLAM系列——机器人顶刊T-RO!用于关联、建图和高级任务的物体级SLAM框架
系列文章目录
SLAM系列——第一讲 预备知识[2023.1]
SLAM系列——第二讲 初识SLAM[2023.1]
SLAM系列——第三讲 三维空间刚体运动[2023.1]
SLAM系列——第四讲 李群李代数[2023.1]
SLAM系列——第五讲 相机与图像[2023.1]
SLAM系列——第六讲 非线性优化[2023.1]
SLAM系列——第七讲 视觉里程计1[2023.1]
SLAM系列——第八讲 视觉里程计2[2023.1]
SLAM系列——第九讲 后端1[2023.1]
SLAM系列——第十讲 后端2[2023.1]
SLAM系列——第十一讲 回环检测[2023.1]
SLAM系列——第十二讲 建图[2023.1]
SLAM系列——第十三讲 实践:设计SLAM系统[2023.1]
SLAM系列——第十四讲 SLAM:现在与未来[2023.1]
SLAM系列——g2o
SLAM系列——ORB_SLAM2
SLAM系列——ORB_SLAM3
SLAM系列——机器人顶刊T-RO!用于关联、建图和高级任务的物体级SLAM框架
文章目录
- 系列文章目录
- Abstract
-
- 关键词:视觉SLAM、数据关联、语义建图、增强现实、机器人
- Introduction
- II. RELATED WORK
-
- A. 数据关联
- B. 对象表示
- C. 语义场景匹配
- D. 主动感知与基于地图的对象抓取
- III. SYSTEM OVERVIEW
- IV. OBJECT-LEVEL DATA ASSOCIATION
-
- A. Intersection over Union (IoU) Model
- B. Nonparametric Test Model
- C. Single-sample and Double-sample T-test Model
- V. OBJECT PARAMETERIZATION
-
- C. Estimation of orientation(θy)
- D. Object pose optimization
- VI. OBJECT DESCRIPTOR ON THE TOPOLOGICAL MAP
-
- A. Semantic Topological Map
- B. Semantic Descriptor
- VII. OBJECT-DRIVEN ACTIVE EXPLORATION
-
- A. Observation Completeness Measurement
- B. Object-Driven Exploration
- VIII. EXPERIMENT
-
- A. Distributions of Different Statistics
- B. Object-level Data Association Experiments
- C. Qualitative Assessment of Object Parameterization
- D. Object-Oriented Map Building
- E. Augmented Reality Experiment
- F. Object-based Scene Matching and Relocalization
- G. Evaluation of Active Mapping
- H. Object Grasping and Placement
- IX. DISCUSSION AND ANALYZE
- X. CONCLUSION
- REFERENCES
Abstract
Object SLAM被认为对于机器人高层次感知与决策制定越来越重要。本文提出一个综合的object SLAM框架,该框架专注于基于object的感知和面向object的机器人任务。首先,我们提出了一种集成数据关联方法,用于通过结合参数和非参数统计测试来关联复杂条件下的对象。此外,我们提出基于iForest和线对齐的对象建模的离群鲁棒质心和尺度估计算法。然后由估计的通用对象模型表示轻量级和面向对象的地图。考虑到对象的语义不变性,我们将对象图转换为拓扑图以提供语义描述符以实现多图匹配。最后,我们提出了一种对象驱动的主动探索策略,以在抓取场景中实现自主建图。一系列公共数据集和映射、增强现实、场景匹配、重新定位和机器人操作方面的真实结果已被用于评估所提出的object SLAM框架的高效性能。
关键词:视觉SLAM、数据关联、语义建图、增强现实、机器人
这项工作由中国国家自然科学基金(No. 61973066)、辽宁省重大科技专项(No.2021JH1/10400049)、航天系统仿真重点实验室基金会(No.6142002200301)、可靠性装备重点实验室基金会(No.WD2C20205500306)、中央大学基础研究基金会(N2004022)支持。
Yanmin Wu 和 Xin Chen 来自东北大学机器人科学与工程学院,沈阳 110819 (Email: [email protected])
Yunzhou Zhang, Zhiqiang Deng, and Wenkai Sun,东北大学信息科学与工程学院,沈阳 110819。 (通讯作者:Yunzhou Zhang,Email:[email protected])。
Delong Zhu 就职于中国香港特别行政区新界沙田香港中文大学电子工程系。
Jian Zhang (北京大学深圳研究生院电子与计算机工程学院, 深圳 518055)
Introduction
视觉 SLAM 的准确性和效率方面的基本问题在过去二十年中得到了极大的改善,这使得视觉 SLAM 在机器人、自动驾驶和增强现实中得到广泛应用。 下一代 SLAM 将需要以更好的能力支持更智能的任务,我们称之为“几何和语义空间 AI 感知”[1]。 这将极大地扩展传统几何定位和建图的范围。
在几何感知方面(例如,基于点的外观建模和基于手工特征的定位)更多的视觉地标,例如线 [2]、边缘 [3] 和平面 [4],被用来克服环境 和运动挑战。 全向几何感知是通过视觉、热、惯性、LiDAR、GNSS 和 UWB 的多传感器融合实现的 [5]-[7]。 在车载应用中,这些通用且稳健的算法被广泛采用。 然而,由于缺乏语义线索,仅靠几何线索不足以实现智能机器人交互和主动决策,如语义映射、目标导航和目标搜索。 本文重点关注下一代SLAM的另一个方面:语义感知,旨在从语义层面表示和理解环境信息,超越基本的几何外观和位置感知。
在语义 SLAM 中,深度学习技术提供的语义线索在各种子组件中起着至关重要的作用,例如定位、建图、闭环和优化。 在这项工作中,我们专注于语义辅助映射并探索基于语义映射的多个高级应用程序。 流行的语义映射管道 [8]-[10] 将几何 SLAM 工作流和基于学习的语义分割并行化,然后用 2D 图像分割标签标注 3D 点云(或体积、网格)。 最后,将多帧分割结果与概率方法融合以构建全局语义图。 尽管这些基于点云的语义图在视觉上很吸引人,但它们并不详细,并且缺乏足够的实例特定信息来帮助机器人执行细粒度的任务。 因此,本文的第一个见解是,对机器人操作有用的语义映射应该是面向实例和面向对象的。
对象 SLAM 是语义 SLAM 的一个面向对象的分支,专注于以对象为中心实体构建地图,通常以实例级分割或对象检测作为语义网络。 大多数关于稀疏 SLAM [11]、[12] 的研究将点云与物体地标相关联,并将点云的质心作为物体的位置。 其他关于密集 SLAM 的研究 [13]-[16] 通过更密集的点云和更精确的分割/检测来改进映射结果,从而实现对象级重建和对象的密集语义表示。 尽管如此,这些研究侧重于物体位置的准确性,而没有研究物体的方向和大小,这对于操纵和导航等机器人任务来说确实是不可或缺的。 本文提出的第二个观点是,物体在地图中的位置、方向、大小都应该参数化。
对象参数化或表示是对象 SLAM 的主要任务之一。 为了解决这个问题,典型的研究 [17]-[19] 通常包括对象模型作为先验,并且目标对象的点云或形状是已知的。 然后通过模型检索和匹配来实现对象的姿态估计。 先验模型也被集成到地图中并进行对象级束调整。 研究 [20]-[23] 是专注于分类对象模型的示例,它仅采用对象的部分知识,例如结构和形状,因为先验和使用需要一个模型来表示一个类别。 尽管对象参数在先验实例模型或类别模型中得到了很好的编码,但获取先验知识既困难又昂贵。 此外,这些模型的泛化能力有限。 这项工作中的第三个观察是,对象应该由具有高度通用性和低成本先验的通用模型表示,例如立方体、圆柱体和二次曲面。
总而言之,这项工作旨在提出一个对象 SLAM 框架,该框架使用通用模型生成面向对象的地图,该模型可以参数化地图中对象的位置、方向和大小。 此外,我们进一步探索基于面向对象地图的高级应用。 之前的一些研究 [24]、[25] 追求类似的目标,但遇到了以下挑战。 1)数据关联算法在处理涉及各种类别和数量的对象的复杂设置时不够稳健和准确。 2)对象参数化草率,通常依赖于严格的假设或仅实现不完整的建模,这两者在实践中都难以实现。 3) 大多数研究都集中在创建对象或语义图上,但没有探索在下游任务中的应用,也没有展示地图的实用性。 相反,我们不仅讨论对象映射的基本技术,而且还讨论高级和面向对象映射的应用程序。
在本文中,我们提出了一个对象 SLAM 框架来实现预期目标,同时克服上述挑战。 首先,我们将参数和非参数统计检验与传统的基于 IoU 的方法相结合,对数据关联进行模型集成。 与传统方法相比,我们的方法充分利用了不同统计数据的性质,例如高斯、非高斯、2D 和 3D 测量,因此在关联稳健性方面表现出显着优势。 然后,对于对象参数化,我们提供了一种用于质心、大小和方向估计的算法,以及一种基于 iForest(隔离森林)和线对齐的对象姿态初始化方法。 所提出的方法对异常值具有鲁棒性并且表现出高精度,这极大地促进了联合姿势优化过程。 最后,利用以立方体和二次曲面为代表的通用模型构建面向对象的地图。 基于地图,我们开发了一个增强现实系统以实现虚实融合和交互,为机器人手臂移植了一个框架来实现常见物体的建模和抓取,并提出了一种新的用于子场景匹配和重定位的物体描述符。
本文扩展了我们之前的工作 [26]、[27]。 扩展包括基于语义描述符的场景匹配/重定位(Sec.VI 和 Sec.VIII-F)以及扩展和分析(Sec.IX)。 贡献总结如下:
- 我们提出了一种集成数据关联策略,可以有效地聚合对象的不同测量值以提高关联精度
- 我们提出了一种基于 iForest 和线对齐的物体姿态估计框架,该框架对异常值具有鲁棒性,可以准确估计物体的姿态和大小。
- 我们使用通用模型构建了一个轻量级和面向对象的地图,在此基础上我们开发了一个能够感知遮挡和碰撞的增强现实应用程序。
- 我们将对象图扩展为拓扑图,并根据参数化对象信息设计语义描述符,以实现多场景匹配和基于对象的重定位。
- 我们将对象 SLAM 与机器人抓取任务相结合,提出了一种对象驱动的主动探索策略,该策略考虑了对象观察的完整性和姿态估计的不确定性,实现了精确的对象映射和复杂的机器人抓取。
- 我们提出了一个全面的对象 SLAM 框架,探索关键挑战并有力地展示了它在各种场景和任务中的实用性。
II. RELATED WORK
A. 数据关联
数据关联建立了图像帧中对象与全局地图之间的 2D-3D 关系以及连续帧之间对象的 2D-2D 对应关系。 最流行的策略将其视为对象跟踪问题 [11]、[28]、[29]。 李等[30] 将 3D 对象投影到图像平面,然后通过匈牙利对象跟踪算法使用投影的 2D 边界框执行关联。 一些方法 [16]、[31]–[33] 使用联合交集 (IoU) 算法来跟踪帧之间的对象,而基于跟踪的方法很容易在复杂的上下文中产生错误的先验,从而导致错误的关联结果。
一些研究增加了共享信息的利用率。 刘等人[34] 创建一个表示对象之间拓扑关系的描述符,具有最多共享描述符的实例被认为是相同的。 相反,杨等人[24] 建议使用检测到的对象上匹配的地图点的数量作为关联标准。 格林瓦尔德等[15] 预设了语义标签相似性的测量,而 Ok 等人。 [35] 建议利用色调饱和度直方图相关性。 Sunderhauf等人[14] 更直接地比较不同实例之间的距离。 通常,设计的标准不够普遍、详尽或稳健,导致不正确的关联。
在基于学习的研究方面,Xiang 等人[36] 建议利用递归神经网络来实现连续图像之间的语义标签数据关联。 然而,他们只关注像素级关联。 同样,李等人[37] 使用基于注意力的 GNN 来维护检测到的 2D 和 3D 属性。 美林等[38] 提出了一种基于关键点的对象级 SLAM 系统,该系统将 3D 关键点投射到图像上,作为下一帧中对象的先验。但是,此方法未在 SLAM 数据集上进行验证,无法推广到以前未见过的对象。 Xing 等人使用深度图卷积网络。 [39]提取对象特征并进行特征匹配。 然而,这种方法只适用于构建良好的地图,对实时 SLAM 的增量地图具有挑战性。
另一个可行的选择是基于概率的解决方案。 鲍曼等人[20] 使用概率方法对数据关联过程进行建模,并利用 EM 算法来识别观察到的地标之间的对应关系。 随后的研究 [40]、[41] 将概念扩展到关联动态对象或执行密集语义重建。 然而,它们的效率受到 EM 优化器的高成本的限制。 翁等[13] 提出了一个用于语义数据关联的非参数 Dirichlet 过程,它可以解决当统计不遵循高斯分布时出现的挑战。 后来,张等人[42] 和 Ran 等人[43] 介绍了用于降低关联不确定性的分层 Dirichlet 方法的两种变体。 伊克巴尔等人[12] 也展示了非参数数据关联的效率。 然而,这种策略无法正确处理高斯分布的统计数据,因此无法充分利用 SLAM 中的多样化数据。 我们结合参数和非参数方法来执行模型集成,在具有众多对象类别的复杂场景中表现出卓越的关联性能。
B. 对象表示
对象 SLAM 中的对象表示可分为基于形状重建的方法和基于模型的方法。 对于前一类,Sucar 等人[23] 使用变分自动编码器从图像中推断物体体积,然后联合优化物体形状和姿势。 王等[32] 采用 DeepSDF [44] 作为形状嵌入,最小化观察到的点云的表面一致性和深度渲染损失。 同样,Xu 等人[33] 基于预训练的 DeepSDF 训练形状完成网络,以实现部分可见物体的完整形状重建。 然而,这些方法是数据驱动的,并且显着依赖于大规模的形状先验。
基于模型的对象表示大致分为三种类型:先验实例级模型 [17]-[19]、[45]、特定类别模型和通用模型。 先前的实例级模型依赖于完善的或训练有素的数据库,例如详细的点云或 CAD 模型。 由于此类模型必须事先知道,因此其应用场景受到限制。 此外,关于特定类别模型的研究[21]-[23]侧重于识别类别级别的特征。 帕克希亚等人。 [21] 和乔希等人。 [22]通过线段的组合来表示不同的类别,但类别特定的特征不够普遍,无法描述过多的类别。
一般的对象模型由简单的几何元素表示,例如立方体、二次曲面和圆柱体,它们是最有效的模型。 有两种典型的建模方法。 第一种类型从 2D 检测结果推断 3D 姿态。 杨等。 [24] 利用消失点从单个视图中对 3D 立方体提案进行采样,然后使用几何测量优化对象姿势。尼科尔森等人[25] 结合多视图观察将对象地标参数化为受约束的对偶二次曲面。 随后的研究 [35]、[46] 通过结合形状和语义先验以及平面约束来改进二次表示。 然而,这种从 2D 对象推断出来的精度很差,并且有很大的错误。 李等[37] 应用超二次曲面自适应地在 3D 框和二次曲面之间进行调整。 但是,它们依赖于额外的 3D 对象检测。 另一种类型的方法通过 3D 点云测量来解析 3D 对象姿态。 一些研究 [11]-[13] 使用点云中心描绘物体位置,这是表达物体属性的一种不精确的方式。Runz 等人[47] 使用更准确的实例和基于几何的分割获得密集对象重建结果。 虽然对象的位置和大小是可行的,但方向被忽略了。 其他一些涉及方向估计的研究[24]、[48]、[49]利用图像或点云的几何特征进行方向采样和分析。 然而,它们面临着鲁棒性不足的问题。 相比之下,研究[50]、[51]使用基于学习的方法从图像方向回归,但在准确性和泛化方面存在问题。 在这项工作中,基于一般对象模型,我们提出了一种使用 iForest 和线对齐方法的离群鲁棒对象姿态估计算法,以更好地参数化对象大小和方向。
C. 语义场景匹配
场景匹配对于机器人重新定位、闭环和多代理协作至关重要。 传统研究 [52]、[53] 依赖于关键帧和几何特征,当面对视点、光照和外观的变化时,它们很容易失败。 相反,由于语义信息(例如,标签和大小)的时间和空间不变性,基于语义的场景匹配更有效。
加维尔等人[54] 专注于多视图机器人的全局场景匹配,他们提出了一种基于随机游走的语义描述符,以通过语义图匹配实现全局定位。 郭等[55] 研究了大规模场景匹配问题,并提出了一种基于语义直方图的快速图匹配算法,从而实现更准确、更快速的定位和地图合并。 然而,这些方法只考虑了大场景的全局匹配,忽略了局部信息。 此外,语义信息不在对象级别。刘等人[34] 对环境外观变化时的本地化问题感兴趣。 他们建议使用密集的语义拓扑图来表征场景,并通过匹配对象描述符来执行 6-DOF 对象定位。 同样,李等人[30] 关注视角变化的重新定位。 他们使用目标地标建立不同视图之间的对应关系,并通过基于匈牙利算法的图形匹配进行重定位。 然而,考虑到对象数量有限以及它们没有很好地参数化这一事实,他们的方法在具有多个重复对象的复杂设置中是值得怀疑的。为了解决多目标场景中的闭环问题,Qin 等人[56] 建议使用对象的语义标签生成语义子图,然后利用 Kuhn-Munkres 对齐子图以估计转换。 然而,语义线索仅用于确定场景的相似度,而它们之间的翻译仍然是通过几何度量而不是语义度量来计算的。 在这项工作中,我们专注于多个对象的场景匹配和场景转换。 与之前的研究类似,我们创建了一个拓扑图并设计了一个对象描述符。 在地图中,对象被完全参数化,基于对象描述符的匹配策略也得到了改进。
D. 主动感知与基于地图的对象抓取
主动感知是通过分析现有数据主动调整传感器状态以收集更有价值的信息以执行特定任务的过程,这是机器人自主性的关键特征。 张等。 [57] 利用 Fisher 信息来预测最佳传感器位置以减少定位不确定性。 曾等。 [58]利用对象之间的先验知识为主动对象搜索建立语义链接图。 更具体地说,主动建图是一种与自主地图构建有关的特定类型的主动感知任务。 查罗等人。 [59]利用二次互信息来指导 3D 密集映射。王等[60] 还利用互信息在稀疏路线图上执行下一个最佳视图 (NBV) 选择,随后作为语义地标来帮助映射过程。 克里格尔等人[61] 提出了一种针对单个未知物体的表面重建方法。 除了信息增益,他们还将重建质量的度量集成到目标函数中,实现了高精度和完整性。 主动映射的关键是定义引导代理自主移动的度量和策略。 我们提出了基于信息熵的不确定性量化和对象驱动的主动探索策略。 与其他方法的另一个显着区别是我们建议的方法的输出是与复杂机器人操作任务兼容的对象图。
用对象姿势编码的对象图可用于机器人对象操作任务,例如对象放置和排列。 和田等。 [62] 提出通过增量对象级体素映射重建对象。 体素点初始化物体姿态,然后使用ICP算法将初始化物体与CAD模型对齐以进一步优化姿态,这在很大程度上取决于CAD模型的配准精度。 在 NodeSLAM [23] 中,对象被视为地标并参与联合优化以帮助生成准确的对象图。 这种方法的主要缺陷是模型需要对每个对象进行繁琐的类别级训练过程。 Labbe’ 等人。 [19] 提出了一种单视图 6-DoF 对象姿态估计方法,并利用 SLAM 框架中的对象级束调整来优化对象图。但是,此方法仅关注已知对象。 阿尔梅达等。 [63] 利用 SLAM 框架密集映射未知物体以进行准确的抓取点检测,但未估计物体姿态。 在这项工作中,我们使用所提出的 SLAM 框架主动生成对象地图,使全局感知能够帮助机器人自主执行更智能的任务。 此外,与之前的研究不同,我们专注于未知物体的姿态估计。
III. SYSTEM OVERVIEW
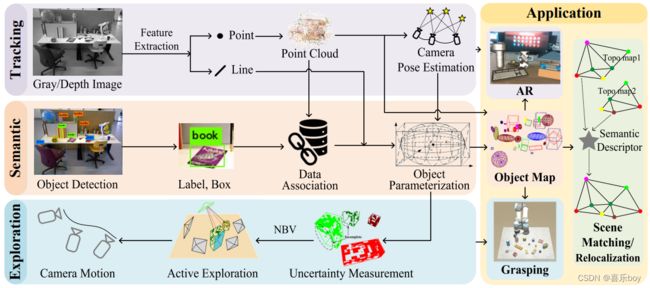
Fig. 1: The proposed object SLAM framework.
所提出的对象 SLAM 框架如图 1 所示,包括四个部分。 跟踪模块建立在 ORB-SLAM2 [52] 的基础上,它生成增量稀疏点云并通过提取和匹配多视图特征来估计相机位姿。 我们的主要贡献在于剩下的三个部分。 语义模块使用 YOLO [64] 作为对象检测器来提供语义标签和边界框,然后将它们与点云测量相结合,将 2D 检测到的对象与 3D 全局对象相关联。 之后,应用 iForest 和线对齐算法对跟踪模块生成的点云和 2D 线进行细化。 基于关联和细化结果,使用立方体和二次模型对对象进行参数化。
对象映射由多个参数化对象组成,实现了环境的轻量级表示,是应用模块的重要组成部分。 对于增强现实应用,虚拟模型的 3D 配准是基于真实世界的物体姿态,而不是传统的基于点的方法。 此外,我们将对象图转换为拓扑图,即对象及其相对位姿的图形表示。 基于该地图,设计了语义描述符以实现多场景匹配和重定位任务。
准确的物体姿态被编码在物体图中,它为机器人抓取应用提供了基本线索(例如,抓取点)。 值得注意的是,对象图是主动创建的,如探索模块中所述。 在这里,我们提出了一个不确定性测量模型来预测下一个最佳探索视图。 机械手然后主动移动以最佳视图扫描桌子,直到建立完整且准确的对象图。
简而言之,所提出的对象 SLAM 利用几何和语义测量来同时实现相机定位和对象地图构建,从而形成一个综合系统来应对该领域的各种挑战,并促进许多智能和迷人的应用。 我们论文的其余部分组织如下:IV 和 V 介绍了数据关联和对象参数化的主要理论。 语义描述符和场景匹配方法在第 VI 节中定义。 第七节介绍了主动勘探策略。 第八节通过综合实验展示了我们系统的性能。 第九节提供讨论和分析,第十节提供结论。
IV. OBJECT-LEVEL DATA ASSOCIATION
图 2 展示了所提出的数据关联策略的流程。 局部对象是在当前单个视图 (t) 中观察到的 3D 实例,其中点云对应于位于 2D 边界框内的 ORB 特征,质心是点的平均值。 全局对象是多帧(t之前)观察到的实体,已经存在于地图上,其中点云和质心也来自于多视图的增量测量。 数据关联的目的是确定地图中的哪个全局对象与当前视图中的局部对象相关联。 如管道所示,相机运动 IoU (M-IoU)、非参数 (NP) 测试、单样本 t (S-t) 测试和项目 IoU (P-IoU) 将用于确定关联是否是 成功的。 实验中,成功案例应满足第四项和前三项中的任意一项。 如果是这样,现有的全局对象将被更新; 否则,将创建一个新的全局对象。 最后,使用双样本-t (D-t) 检验来检查是否存在重复。
在本节中,使用以下符号:
A. Intersection over Union (IoU) Model
如果在前两帧(t-1 和 t-2)中观察到全局对象,则我们基于匀速运动假设预测当前帧(t)中的边界框,并计算预测框之间的 IoU 全局对象的检测框和局部对象的检测框,我们将其定义为 Motion-IoU(见图 2 M-IoU 部分)。 如果 IoU 值足够大,则两个对象之间可能存在潜在关联。 在 NP 和 S-t 之后(参见第 IV-B 和 IV-C 节),Project-IoU 将通过将全局对象的 3D 点云投影到当前帧上的 2D 点并为这些点拟合一个框来验证这种关联。 之后,我们计算投影框和检测框之间的 IoU(见图 2 P-IoU 部分)。

Fig. 2: The pipeline of object-level data association.
B. Nonparametric Test Model
m-IoU 模型提供了一种直接有效的方法来处理连续帧的情况。 但是,当 1) 物体被检测器遗漏,2) 物体被遮挡,或 3) 物体从相机视野中消失时,它将发生故障。
Nonparametric test model不需要连续观察物体,可以直接应用于处理两组点云P和Q(见图2 NP部分),基于点云服从非高斯分布的假设 (这将在第 VIII-A 节中进行演示)。 理论上,如果 P 和 Q 代表同一个对象,它们应该服从相同的分布,即 f P = f Q f_P = f_Q fP=fQ。 我们使用 Wilcoxon 秩和检验 [65] 来验证原假设是否成立。
我们首先混合两个点云 X = [ P ∣ Q ] = [ x 1 , x 2 , . . . , x ∣ X ∣ ] ∈ R 3 × ( ∣ P ∣ + ∣ Q ∣ ) X=[P|Q]=[x_1,x_2,...,x_{|X|}] \in \R^{3\times(|P|+|Q|)} X=[P∣Q]=[x1,x2,...,x∣X∣]∈R3×(∣P∣+∣Q∣) , 然后将 X 按三个维度分类。 定义 W P ∈ R 3 × 1 W_P\in \R^{3\times1} WP∈R3×1 如下,
W p = { ∑ k = 1 ∣ X ∣ R ( 1 { x k ∈ P } − ∣ P ∣ ( ∣ P ∣ + 1 ) 2 ) } , W_p=\{\sum_{k=1}^{|X|}\mathcal{R}(1\{x_k\in P\}-\frac{|P|(|P|+1)}{2})\}, Wp={k=1∑∣X∣R(1{xk∈P}−2∣P∣(∣P∣+1))},
和 W Q W_Q WQ是同一个公式。 Mann-Whitney 统计量为 W = m i n ( W P , W Q ) W= min(W_P , W_Q) W=min(WP,WQ),证明其渐近服从高斯分布 [66]、[67]。 在这里,我们本质上是使用非高斯点云构建高斯统计。 计算W的均值和方差:
m ( W ) = ( ∣ P ∣ ∣ Q ∣ ) / 2 , m(W)=(|P||Q|)/2, m(W)=(∣P∣∣Q∣)/2,
σ ( W ) = ∣ P ∣ ∣ Q ∣ Δ + 12 − ∣ P ∣ ∣ Q ∣ ( Σ i τ i 3 − Σ i τ i ) 12 ( ∣ P ∣ + ∣ Q ∣ ) Δ − , \sigma(W)=\frac{|P||Q|\Delta^+}{12} - \frac{|P||Q|(\Sigma_i\tau_i^3-\Sigma_i\tau_i)}{12(|P|+|Q|)\Delta^-}, σ(W)=12∣P∣∣Q∣Δ+−12(∣P∣+∣Q∣)Δ−∣P∣∣Q∣(Σiτi3−Σiτi),
其中 Δ + = ∣ P ∣ + ∣ Q ∣ + 1 , Δ − = ∣ P ∣ + ∣ Q ∣ − 1 \Delta^+ = |P| + |Q| + 1, \Delta^− = |P| + |Q| − 1 Δ+=∣P∣+∣Q∣+1,Δ−=∣P∣+∣Q∣−1, 且 τ ∈ P ∩ Q τ ∈ P ∩ Q τ∈P∩Q。 τ τ τ 表示两个对象之间的共享点数; 因为它的值很小,方程式中复杂且贡献低的第二项。 (3) 在我们的实施中被忽略。
为使原假设成立,W 应满足以下约束条件:
f ( W ) ≥ f ( r r ) = f ( r l ) = α / 2 , f(W) ≥ f (r_r) = f (r_l) = α/2, f(W)≥f(rr)=f(rl)=α/2,
其中 α 是显着性水平,1−α 是置信水平, [ r l , r r ] ≈ [ m − s σ , m + s σ ] [r_l, r_r] ≈ [m − s\sqrtσ, m + s\sqrtσ ] [rl,rr]≈[m−sσ,m+sσ] 定义置信区域。 标量 s > 0 在归一化高斯分布 N ( s ∣ 0 , 1 ) = α \mathcal N (s|0, 1)=α N(s∣0,1)=α上定义。 总之,如果两个点云P和Q的Mann-Whitney统计量W满足Eq。 (4)、我们暂时假设它们来自同一个对象。
C. Single-sample and Double-sample T-test Model
单样本 t 检验用于处理在不同视图中观察到的对象质心(参见图 2 S-t 部分),其通常遵循高斯分布(参见第 VIII-A 节)。 假设原假设是C和c来自同一个对象,定义t统计量如下,
t = m ( C ) − c σ ( C ) / ∣ C ∣ ∼ t ( ∣ C ∣ − 1 ) . t=\frac{m(C)-c}{\sigma(C)/\sqrt{|C|}}\sim t(|C|-1). t=σ(C)/∣C∣m(C)−c∼t(∣C∣−1).
为了使零假设成立,t 应该满足:
f ( t ) ≥ f ( t α / 2 , v ) = α / 2 , f(t)\ge f(t_{\alpha/2,v})=\alpha/2, f(t)≥f(tα/2,v)=α/2,
其中 t α / 2 , v t_{α/2,v} tα/2,v 是 v 自由度的 t 分布的上 α/2 分位数,v = |C|−1。 如果t统计量满足(6),我们暂时假设c和C来自同一个对象。
由于上述严格的数据关联策略、不良的观察视图或错误的对象检测,某些现有对象可能会被错误识别为新对象,从而导致重复。 因此,利用双样本 t 检验通过分析两个对象的历史质心来确定是否合并两个对象(见图 2 D-t 部分)。
如下构造 C 1 C_1 C1 和 C 2 C_2 C2 的 t 统计量,
t = m ( C 1 ) − m ( C 2 ) σ d ∼ t ( ∣ C 1 ∣ + ∣ C 2 ∣ − 2 ) , t=\frac{m(C_1)-m(C_2)}{\sigma_d}\sim t(|C_1|+|C_2|-2), t=σdm(C1)−m(C2)∼t(∣C1∣+∣C2∣−2),
σ d = ( ∣ C 1 ∣ − 1 ) σ 1 2 + ( ∣ C 2 ∣ − 1 ) σ 2 2 ∣ C 1 ∣ + ∣ C 2 ∣ − 2 ( 1 ∣ C 1 ∣ + 1 ∣ C 2 ∣ ) , \sigma_d=\sqrt{\frac{(|C_1|-1)\sigma_1^2+(|C_2|-1)\sigma_2^2}{|C_1|+|C_2|-2}(\frac{1}{|C_1|}+\frac{1}{|C_2|})}, σd=∣C1∣+∣C2∣−2(∣C1∣−1)σ12+(∣C2∣−1)σ22(∣C1∣1+∣C2∣1),
其中 σ d σ_d σd是两个对象的合并标准差。 同样,如果 t 满足(6),则 v = ∣ C 1 ∣ + ∣ C 2 ∣ − 2 v = |C_1| + |C_2| − 2 v=∣C1∣+∣C2∣−2,表示 C 1 C_1 C1和 C 2 C_2 C2属于同一个对象,则合并。

Fig. 3: (a-c) Demonstration of object parameterization. (d-e) Demonstration of iForest.
V. OBJECT PARAMETERIZATION
数据关联为全局对象提供多视图测量,确保更多观察参数化以有效地建模对象。 在本节中,使用以下符号:
- t = [ t x , t y , t z ] T t=[t_x,t_y,t_z]^T t=[tx,ty,tz]T - 目标坐标系在世界坐标系中的平移(位置)。
- θ = [ θ r , θ y , θ p ] T \theta=[\theta_r,\theta_y,\theta_p]^T θ=[θr,θy,θp]T - 目标坐标系w.r.t.旋转到世界坐标系。 R(θ) 是矩阵表示。
- T = { R ( θ ) , t } T=\{R(\theta),t\} T={R(θ),t} - 目标坐标系w.r.t.到世界坐标系的转移矩阵。
- s = [ s l , s w , s h ] T s=[s_l,s_w,s_h]^T s=[sl,sw,sh]T - 3D框的半边长度,例如,目标的尺寸。
- P o , P w ∈ R 3 × 8 P_o,P_w\in\R^{3\times8} Po,Pw∈R3×8 - 对应立方体的八个顶点在对象和世界坐标系中的坐标。
- Q o , Q w ∈ R 4 × 4 Q_o,Q_w\in\R^{4\times4} Qo,Qw∈R4×4 - 分别由其在对象和世界坐标系中的半轴参数化的二次曲面,其中 Q o = d i a g { s l 2 , s w 2 , s h 2 , − 1 } Q_o=diag\{s_l^2,s_w^2,s_h^2,-1\} Qo=diag{sl2,sw2,sh2,−1}
- α ( ∗ ) \alpha(*) α(∗) - 计算图像中线段的角度。
- K , T c K,T_c K,Tc - 相机内外参。
- p ∈ R 3 × 1 p\in\R^{3\times1} p∈R3×1 - 世界坐标系中一个点的坐标。
A. 对象表示
在这项工作中,我们利用立方体和二次曲面/圆柱体来表示对象,而不是复杂的实例级或类别级模型。 对于具有规则形状的对象,例如书本、键盘和椅子,我们使用立方体(由它们的顶点 P o P_o Po 编码)来表示它们。 对于球、瓶、杯等没有明确方向的非规则物体,采用二次/圆柱(由其半轴 Q o Q_o Qo编码)表示,忽略其方向参数。 这里, P o P_o Po 和 Q o Q_o Qo 在对象框架中表示,仅取决于尺度 s。 为了将这些元素注册到全局地图,我们还需要估计它们的平移 t 和方向 θ w.r.t。 全局框架。 全局坐标系中的立方体和二次曲面表示如下:
P w = R ( θ ) P o + t , P_w=R(\theta)P_o+t, Pw=R(θ)Po+t,
Q w = T Q o T T . Q_w=TQ_oT^T. Qw=TQoTT.
这两种模型可以方便地切换,如图3©所示。 假设物体与地面平行放置,如在其他作品 [68]、[69] 中,即 θr=θp=0,我们只需要估计立方体的 [θy, t, s] 和 [t, s ] 对于二次曲面。
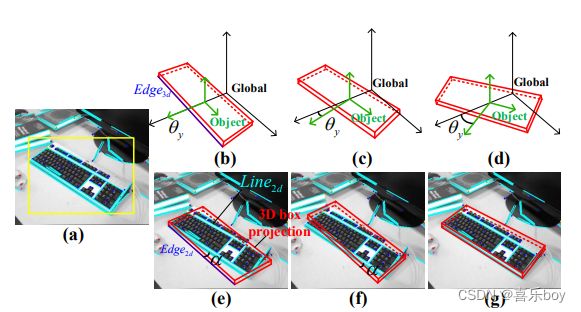
Fig. 4: Line alignment to initialize object orientation. (a) Object and line detection in 2D image. (b-d) Angle sampling in 3D space; (e-g) Projection of angle sampling process in 2D images.
B. Estimation of translation(t) and scale(s)
Assuming that the object point clouds X are in the global frame, we follow conventions and denote its mean by t, based on which the scale can be calculated by s = (max(X) − min(X))/2, as shown in Fig.3(a). The main challenge here is that X is typical with many outliers, which will introduce a substantial bias to t and s. One of our major contributions in this paper is the development of an outlier-robust centroid and scale estimation algorithm based on the iForest [70] to improve the estimation accuracy. The detailed procedure of our algorithm is presented in Alg. 1.
假设目标点云X在全局坐标系中,我们按照约定将其均值表示为t,据此可以计算尺度s = (max(X) − min(X))/2,如图所示 在图 3(a) 中。 这里的主要挑战是 X 是具有许多异常值的典型值,这会给 t 和 s 带来很大的偏差。 我们在本文中的主要贡献之一是开发了一种基于 iForest [70] 的离群鲁棒质心和尺度估计算法,以提高估计精度。 我们算法的详细过程在算法中给出。 1.
The key idea of the algorithm is to recursively separate the data space into a series of isolated data points, and then take the easily isolated ones as outliers. The philosophy is that, normal points are typically located more closely and thus need more steps to isolate, while the outliers usually scatter sparsely and can be easily isolated with fewer steps. As indicated by the algorithm, we first create t isolated trees (the iForest) using the point cloud of an object (lines 2 and 14-33), and then identify the outliers by counting the path length of each point x ∈ X (lines 3-9), in which the score function is defined as follows:
该算法的核心思想是递归地将数据空间分离成一系列孤立的数据点,然后将容易孤立的数据点作为异常值。 原理是,正常点通常位于更近的位置,因此需要更多的步骤来隔离,而离群点通常分散得很稀疏,可以用更少的步骤轻松隔离。 如算法所示,我们首先使用对象的点云(第 2 行和第 14-33 行)创建 t 个孤立树(iForest),然后通过计算每个点 x ∈ X 的路径长度来识别异常值(第 2 行) 3-9),其中评分函数定义如下:
s ( x ) = 2 e x p − E ( h ( x ) ) C , s(x)=2exp\frac{-E(h(x))}{C}, s(x)=2expC−E(h(x)),
C = 2 H ( ∣ X ∣ − 1 ) − 2 ( ∣ X ∣ − 1 ) ∣ X ∣ , C=2H(|X|-1)-\frac{2(|X|-1)}{|X|}, C=2H(∣X∣−1)−∣X∣2(∣X∣−1),
where C is a normalization parameter, H is a harmonic number H(i) = ln (i) + 0.5772156649, h(x) is the height of point x in the isolated tree, and E is the operation to calculate the average height. As demonstrated in Fig. 3(d)-(e), the yellow point is isolated after four steps; hence its path length is 4, whereas the green point has a path length of 8. Therefore, the yellow point is more likely to be an outlier. In our implementation, points with a score greater than 0.6 are removed and the remaining are used to calculate t and s (lines 10-12). Based on s, we can initially construct the cubics and quadratics in the object frame, as shown in Fig. 3(a)-©.
其中C为归一化参数,H为调和数H(i) = ln(i) + 0.5772156649,h(x)为孤立树中点x的高度,E为计算平均高度的操作。 如图 3(d)-(e) 所示,黄色点经过四步分离; 因此它的路径长度为 4,而绿色点的路径长度为 8。因此,黄色点更可能是异常值。 在我们的实现中,分数大于 0.6 的点被删除,剩余的点用于计算 t 和 s(第 10-12 行)。 基于s,我们可以初步构造目标坐标系中的三次和二次,如图3(a)-©所示。
C. Estimation of orientation(θy)
The estimation of θy is divided into two steps, namely, to find a good initial value for θy first and then conduct numerical optimization based on the initial value. Since pose estimation is a non-linear process, a good initialization is very important to help improve the optimality of the estimation result. Conventional methods [30], [47] usually neglect the initialization process, which typically yields inaccurate results.
θy的估计分为两步,即先为θy找到一个好的初值,然后根据初值进行数值优化。 由于姿态估计是一个非线性过程,因此良好的初始化对于帮助提高估计结果的最优性非常重要。 传统方法 [30]、[47] 通常忽略初始化过程,这通常会产生不准确的结果。
Algorithm 1 Centroid and Scale Estimation Based on iForest
| Input: X - The point cloud of an object, t - The number of | |
| iTrees in iForest, ψ - The subsampling size for an iTree. | |
| Output: F - The iForest, a set of iTrees, t - The origin of | |
| local frame, s - The initial scale of the object. | |
| 1: procedure PARAOBJECT(X, t, ψ) | |
| 2: F ← BUILDFOREST(X, t, ψ) | |
| 3: for point x in X do | |
| 4: E(h) ← averageDepth(x, F) | |
| 5: s ← score(E(h), C) . Eq. (11) and (12) | |
| 6: if s > 0.6 then . an empirical value | |
| 7: remove(x) . remove x from X | |
| 8: end if | |
| 9: end for | |
| 10: t ← meanValue(X) | |
| 11: s ← (max(X) - min(X)) / 2 | |
| 12: return F, t, s | |
| 13: end procedure | |
| 14: procedure BUILDFOREST(X, t, ψ) | |
| 15: F ← φ | |
| 16: l ← ceiling(log2 ψ) . maximum times of iterations | |
| 17: for i = 1 to t do | |
| 18: X(i) ← randomSample(X, ψ) | |
| 19: F ← F ∪ BUILDTREE(X(i) | |
| , 0, l) | |
| 20: end for | |
| 21: return F | |
| 22: end procedure | |
| 23: procedure BUILDTREE(X, e, l) | |
| 24: if e ≥ l or | X |
| 25: return exNode{ | X |
| 26: end if | |
| 27: i ← randomDim(1, 3) . get one dimension | |
| 28: q ← randomSpitPoint(X[i]) | |
| 29: Xl | |
| , Xr ← split(X[i], q) | |
| 30: L ←BUILDTREE(Xl | |
| , e + 1, l) . get child pointer | |
| 31: R ←BUILDTREE(Xr, e + 1, l) | |
| 32: return inNode{L, R, i, q} | |
| 33: end procedure |
The detail of orientation initialization algorithm is presented in Alg. 2. The inputs are obtained as follows: 1) LSD (Line Segment Detector [71]) segments are extracted from t consecutive images, and those falling in the bounding boxes are assigned to the corresponding objects (see Fig. 4(a)); 2) The initial pose of an object is assumed to be consistent with the global frame, i.e., θ0=0 (see Fig. 4b). In the algorithm, we first uniformly sample thirty angles within [−π/2, π/2] (line 2). For each sample, we then evaluate its score by calculating the accumulated angle errors between LSD segments Zlsd and the projected 2D edges of 3D edges Z of the cube (lines 3-12). The error is defined as follows:
方向初始化算法的细节在算法中给出。 2.输入如下: 1)从t个连续图像中提取LSD(Line Segment Detector [71])线段,将落在边界框内的线段分配给相应的对象(见图4(a)) ; 2)假设物体的初始姿态与全局框架一致,即θ0=0(见图4b)。 在该算法中,我们首先在 [−π/2, π/2] 内均匀采样三十个角度(第 2 行)。 对于每个样本,我们然后通过计算 LSD 段 Zlsd 和立方体的 3D 边 Z 的投影 2D 边之间的累积角度误差来评估其分数(第 3-12 行)。 错误定义如下:
e ( θ ) = ∣ ∣ α ( Z ^ ( θ ) ) − α ( Z l s d ) ∣ ∣ 2 , Z ^ ( θ ) = K T c ( R ( θ ) Z + t ) . e(\theta)=||\alpha(\hat Z(\theta))-\alpha(Z_{lsd})||^2, \hat Z(\theta)=KT_c(R(\theta)Z+t). e(θ)=∣∣α(Z^(θ))−α(Zlsd)∣∣2,Z^(θ)=KTc(R(θ)Z+t).
| Algorithm 2 Initialization for Object Pose Estimation | |
| Input: Z1, Z2, . . . , Zt - Line segments detected by LSD in t | |
| consecutive images, θ0 - The initial guess of yaw angel. | |
| Output: θ - The estimation result of yaw angel, e - The | |
| estimation errors. | |
| 1: S, E ← φ | |
| 2: Θ ← sampleAngles(θ0, 30) . see Fig. 4 (b)-(d) | |
| 3: for sample θ in Θ do | |
| 4: sθ, eθ ← 0 | |
| 5: for Z in {Z1, Z2, . . . , Zt} do | |
| 6: s, e ← score(θ, Z) . Eq. (13) and (14) | |
| 7: sθ ← sθ + s | |
| 8: eθ ← eθ + e | |
| 9: end for | |
| 10: S ← S ∪ {sθ} | |
| 11: E ← E ∪ {eθ} | |
| 12: end for | |
| 13: θ | |
| ∗ ← argmax(S) | |
| 14: return θ | |
| ∗ | |
| , eθ | |
| ∗ |
The demonstration of the calculation of e(θ) is visualized in Fig. 4(e)-(g). The score function is defined as follows:
e(θ) 的计算演示如图 4(e)-(g) 所示。 得分函数定义如下:
S c o r e = N P N a ( 1 + 0.1 ( ξ − E ( e ) ) ) , Score=\frac{N_P}{N_a}(1+0.1(ξ-E(e))), Score=NaNP(1+0.1(ξ−E(e))),
where Na is the total number of line segments of the object in the current frame, Np is the number of line segments that satisfy e < ξ, ξ is a manually defined error threshold (five degrees here), and E(e) is the average error of these line segments with e < ξ. After evaluating all the samples, we choose the one that achieves the highest score as the initial yaw angle for optimization (line 13).
其中Na为当前帧中物体的线段总数,Np为满足e < ξ的线段数,ξ为手动定义的误差阈值(此处为五度),E(e)为 这些线段的平均误差,其中 e < ξ。 在评估所有样本后,我们选择得分最高的样本作为初始偏航角进行优化(第 13 行)。
D. Object pose optimization
After obtaining the initial s and θy, we then jointly optimize object and camera poses:
在获得初始 s 和 θy 之后,我们然后联合优化对象和相机位姿:
{ O , T c } ∗ = arg min { θ y , s } ∑ ( e ( θ ) + e ( s ) ) + arg min { T c } ∑ e ( p ) , \{O,T_c\}^*=\argmin_{\{\theta_y,s\}}\sum(e(\theta)+e(s))+\argmin_{\{T_c\}}\sum e(p), {O,Tc}∗={θy,s}argmin∑(e(θ)+e(s))+{Tc}argmin∑e(p),
where the first term is the object pose error defined in Eq. (13) and the scale error e(s) is defined as the distance between the projected edges of a cube and their nearest parallel LSD segments. The second term e§ is the commonly-used reprojection error in the traditional SLAM framework.
其中第一项是等式中定义的物体位姿误差。 (13) 和尺度误差 e(s) 被定义为立方体的投影边缘与其最近的平行 LSD 段之间的距离。 第二项 e§ 是传统 SLAM 框架中常用的重投影误差。
VI. OBJECT DESCRIPTOR ON THE TOPOLOGICAL MAP
After the step of object parameterization, we obtain the label, size, and pose information of a single object. To present the relationship between objects and that between objects and the scene, we create a topological map. The map is then used to generate an object descriptor for scene matching.
在对象参数化步骤之后,我们获得了单个对象的标签、大小和位姿信息。 为了呈现对象之间以及对象与场景之间的关系,我们创建了一个拓扑图。 该地图随后用于生成用于场景匹配的对象描述符。
A. Semantic Topological Map
The topological map is an abstract representation of the scene. In this work, to construct the semantic topological map, the 3D object centroid is used to represent the node N that encodes the semantic label l and the object parameters t, θ, s. Then, under the distance and number constraints, we generate the undirected edge E between objects, which includes the distance d and angle α of two objects:
拓扑图是场景的抽象表示。 在这项工作中,为了构建语义拓扑图,使用 3D 对象质心表示编码语义标签 l 和对象参数 t、θ、s 的节点 N。 然后,在距离和数量约束下,我们生成对象之间的无向边 E,它包括两个对象的距离 d 和角度 α:
N = < l , t , θ , s > , E = < d , α > . N=
Fig. 5(a) presents a real-world scene with multiple objects. Fig. 5(b) shows the object modeling result by the method of Section V, which is then used to create a semantic topological map (Fig. 5©) that expresses the scene in an abstract way and shows the connection relationship between objects as symbolized in Eq. (16).
图 5(a) 展示了一个具有多个对象的真实世界场景。 图5(b)展示了通过Section V的方法得到的对象建模结果,然后用它来创建一个语义拓扑图(Fig. 5©),以抽象的方式表达场景并显示之间的连接关系 等式中符号化的对象。 (16).
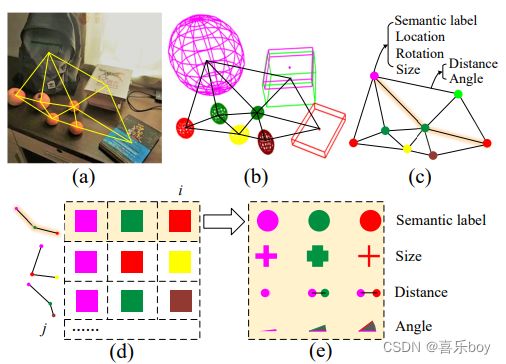
Fig. 5: (a) Real-world scene. (b) Object-level map. © Semantic topological map. (d) Random walk descriptor. (e) 3D matrix visualization of a single descriptor.
B. Semantic Descriptor
Since the object information, including semantic label, position, and scale, is not unique, the computation for undirected graph matching, an NP problem [72], is extremely high. To reduce the computational complexity and enhance the matching accuracy, we introduce a random-walk descriptor that weights multi-neighborhood measurements to describe an object, improving object uniqueness and the relationship with the scene.
由于对象信息(包括语义标签、位置和比例)不是唯一的,因此无向图匹配(NP 问题 [72])的计算量非常大。 为了降低计算复杂度并提高匹配精度,我们引入了一种随机游走描述符,该描述符对多邻域测量进行加权以描述对象,从而提高对象的唯一性和与场景的关系。
The random-walk descriptor is represented by a 2D matrix, as shown in Fig. 5(d), with each row storing a walking route that starts at the described object, and randomly points to the next object. It is worth noting that each object only appears once in a route and the process ends when reaching a certain depth i or time j limit.
随机游走描述符由一个二维矩阵表示,如图 5(d) 所示,每一行存储一条步行路线,该路线从所描述的对象开始,并随机指向下一个对象。 值得注意的是,每个对象在一条路线中只出现一次,当达到一定的深度 i 或时间 j 限制时,该过程结束。
The previous work [54] only considers the semantic label l = (l1, l2, · · · , li) as the descriptor. Benefiting from the above accurate object parameterization, we add three additional measurements, object size s = (s1, s2, · · · , si), distance d = (d11, d12, · · · , d1i), and angle α = (α11, α12, · · · , α1i), to improve the robustness of the descriptor. As shown in Fig. 5(e), thus we transfer the random-walk descriptor to a 3D matrix form:
之前的工作[54]只考虑语义标签l = (l1, l2,···,li)作为描述符。 受益于上述精确的对象参数化,我们添加了三个额外的测量值,对象大小 s = (s1, s2, · · · , si),距离 d = (d11, d12, · · · , d1i),角度 α = ( α11,α12,····,α1i),提高描述符的鲁棒性。 如图 5(e) 所示,我们将随机游走描述符转换为 3D 矩阵形式:
v = ( r 1 , r 2 , ⋅ ⋅ ⋅ , r j ) T , r j = ( l , s , d , α ) T . v=(r_1,r_2,···,r_j)^T,r_j=(l,s,d,\alpha)^T. v=(r1,r2,⋅⋅⋅,rj)T,rj=(l,s,d,α)T.

In our implementation, the additional measurement does not increase the computation. Instead, it accelerates the matching process by eliminating irrelevant candidates with more clues, such as label and size.
在我们的实现中,额外的测量不会增加计算量。 相反,它通过消除具有更多线索(例如标签和大小)的不相关候选者来加速匹配过程。
Alg. 3 describes the procedure for scene matching. Firstly, each object’s semantic descriptor is generated in two independent sub-topological maps (lines 3-4, 10-17). Then find the best matching object-pair by scoring the similarity of each element (l, s, d, α) (lines 5-7, 18-21). Finally, the transformation between two scenes is solved by singular value decomposition (SVD) according to the multiple object pairs (line 8).
藻类。 图 3 描述了场景匹配的过程。 首先,在两个独立的子拓扑图中生成每个对象的语义描述符(第 3-4、10-17 行)。 然后通过对每个元素 (l, s, d, α) 的相似性进行评分来找到最佳匹配对象对(第 5-7、18-21 行)。 最后,根据多个对象对(第 8 行),通过奇异值分解 (SVD) 解决两个场景之间的转换。
There are some points worth mentioning: 1) Scale ambiguity: Two maps are initialized with different depths resulting in distinct scales. While object size, like Li et al. [50], provides a scale by length, width, and height, it is insufficiently robust. Instead, we find the matched object pair between two maps, then calculate the scale factor by averaging the ratio of the distance d. 2) Anomalous object: The mismatch resulting from the error object or novel object may cause a considerable inaccuracy in the resolution of the translation; therefore, the RANSAC algorithm is used to eliminate the disturbance caused by anomalous objects.
有几点值得一提: 1)比例模糊:两张地图初始化为不同的深度,导致不同的比例。 虽然对象大小,如 Li 等人。 [50],提供了长度、宽度和高度的比例,它不够稳健。 相反,我们找到两个地图之间的匹配对象对,然后通过平均距离 d 的比率来计算比例因子。 2)异常对象:由错误对象或新对象引起的不匹配可能导致翻译的分辨率出现相当大的不准确; 因此,采用RANSAC算法来消除异常物体引起的干扰。
VII. OBJECT-DRIVEN ACTIVE EXPLORATION
Object parameterization is good for quantifying the incompleteness of the object or map, and the incompleteness provides a driving force for active exploration. We consider the robotic grasping scene as an example. As shown in Fig. 6, the robot arm is fitted with a camera, the motion module controls the robot to execute observation commands. The perception module parametrized the object map by Section IV and Section V. The analysis module measures object uncertainty and predicts different camera views’ information gains. The view with the greatest information gain is selected as the Next Best View (NBV) and passed to the motion module to enable active exploration. We aim to incrementally build a global object map with the minimum effort and the maximum accuracy for robotic grasping.
对象参数化有利于量化对象或地图的不完整性,不完整性为主动探索提供动力。 我们以机器人抓取场景为例。 如图6所示,机器人手臂上装有摄像头,运动模块控制机器人执行观察指令。 感知模块通过第四节和第五节对对象图进行参数化。分析模块测量对象的不确定性并预测不同相机视图的信息增益。 具有最大信息增益的视图被选为下一个最佳视图 (NBV),并传递给运动模块以启用主动探索。 我们的目标是以最小的努力和最大的机器人抓取精度逐步构建全局对象图。
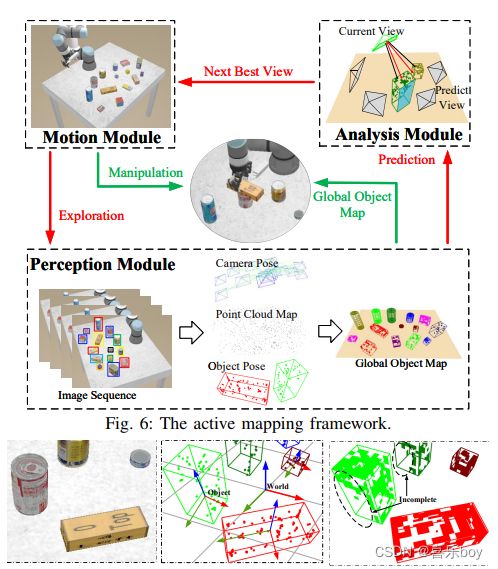
Fig. 7: Illustration of observation completeness measurement. Left: Raw image. Center: Objects with point cloud. Right: Objects with surface grids.
A. Observation Completeness Measurement
We focus on active map building and regard the incompleteness of the map as a motivating factor for active exploration. Existing studies usually take the entire environment as the exploration target [59], [73] or focus on reconstructing a single object [61], [74], neither of which is ideal for building the object map required by robotic grasping. The reasons are as follows: 1) The insignificant environmental regions will interfere with the decisions made for exploration and misguide the robot into the non-object area; 2) it will significantly increase the computational cost and thus reduce the efficiency of the whole system. We propose an object-driven active exploration strategy for building the object map incrementally. The strategy is designed based on the observation completeness of the object, which is defined as follows.
我们专注于主动地图构建,并将地图的不完整性视为主动探索的激励因素。 现有研究通常将整个环境作为探索目标 [59]、[73] 或专注于重建单个对象 [61]、[74],这两种方法都不是构建机器人抓取所需对象图的理想选择。 原因如下:1)无关紧要的环境区域会干扰探索决策,误导机器人进入非目标区域; 2) 会显着增加计算成本,从而降低整个系统的效率。 我们提出了一种对象驱动的主动探索策略,用于逐步构建对象图。 该策略是基于对象的观察完整性设计的,其定义如下。
As demonstrated in Fig. 7, the point clouds of an object are translated from the world frame to the object frame and then projected onto the five surfaces of the estimated 3D cube. Here, the bottom face is not considered. Each of the five surfaces is discretized into a surface occupancy grid map [75] with cell size m ∗ m (m = 1cm in our implementation). Each grid cell can be in one of three states:
如图 7 所示,对象的点云从世界框架转换到对象框架,然后投影到估计的 3D 立方体的五个表面上。 这里不考虑底面。 五个表面中的每一个都被离散化为表面占用网格图 [75],单元格大小为 m * m(在我们的实现中 m = 1cm)。 每个网格单元可以处于三种状态之一:
-
unknown: the grid is not observed by the camera;
-
occupied: the grid is occupied by the point clouds;
-
free: the grid can be seen by the camera but is not occupied by the point clouds.
-
unknown:相机没有观察到网格;
-
occupied:网格被点云占据;
-
free:网格可以被相机看到但不被点云占据
We use information entropy [76] to determine the completeness of observations based on the occupancy grid map, as information entropy has the property of symptomatizing uncertainty. The entropy of each grid cell is defined by a binary entropy function:
我们使用信息熵[76]来确定基于占用网格图的观察的完整性,因为信息熵具有表征不确定性的特性。 每个网格单元的熵由二元熵函数定义:
H g r i d ( p ) = − p l o g ( p ) − ( 1 − p ) l o g ( 1 − p ) , H_{grid}(p)=-p log(p)-(1-p)log(1-p), Hgrid(p)=−plog(p)−(1−p)log(1−p),
where p is the probability of a grid cell being occupied and its initial value before exploration is set to 0.5. The total entropy is therefore defined as
其中 p 是网格单元被占用的概率,其探索前的初始值设置为 0.5。 因此,总熵定义为
H o b j = ∑ o ∈ O H o + ∑ f ∈ F H f + ∑ u ∈ U H u , H_{obj}=\sum_{o\in \mathbb O}H_o+\sum_{f \in \mathbb F}H_f+\sum_{u \in \mathbb U}H_u, Hobj=o∈O∑Ho+f∈F∑Hf+u∈U∑Hu,
and the normalized total entropy is
H ‾ o b j = H o b j / ( ∣ O ∣ + ∣ F ∣ + ∣ U ∣ ) , \overline H_{obj}=H_{obj}/(|\mathbb O|+|\mathbb F|+|\mathbb U|), Hobj=Hobj/(∣O∣+∣F∣+∣U∣),
where Ho, Hf , Hu are the entropy of occupied, free, and unknown grids, O , F , U \mathbb O, \mathbb F, \mathbb U O,F,U are sets of the occupied, free, and unknown grid cells, respectively. ∣ X ∣ |\mathbb X| ∣X∣ represents the size of X. As objects continue to be explored, the number of unknown grid cells is gradually reduced, making all grids’ normalized entropy H ‾ g r i d \overline H_{grid} Hgrid a smaller value. The lower the H ‾ g r i d \overline H_{grid} Hgrid is, the higher the observation completeness is. The exploration objective is to minimize H ‾ g r i d \overline H_{grid} Hgrid.
其中 Ho, Hf , Hu 是占用、空闲和未知网格的熵, O , F , U \mathbb O, \mathbb F, \mathbb U O,F,U 分别是占用、空闲和未知网格单元的集合。 ∣ X ∣ |\mathbb X| ∣X∣表示X的大小。随着物体的不断探索,未知网格单元的数量逐渐减少,使得所有网格的归一化熵 H ‾ g r i d \overline H_{grid} Hgrid成为一个更小的值。 H ‾ g r i d \overline H_{grid} Hgrid 越低,观测完整性越高。 探索目标是最小化 H ‾ g r i d \overline H_{grid} Hgrid。
B. Object-Driven Exploration
Information Gain Definition: As illustrated in Fig. 8(b), object-driven exploration aims to predict the information gain of different candidate camera views and then select the one to explore that maximizes the information gain, i.e., the NBV. The information in this work is defined as the uncertainty of the map, as mentioned in Section VII-A. The information gain is thus defined as the measurement of uncertainty reduction and accuracy improvement after the camera is placed at a specific pose. Conventionally, information gain is defined based on the area of unknown regions of the environment, e.g., the black holes in the medium subfigure of Fig. 8(a), which may mislead the object map building. Compared with the conventional one, our proposed information gain is built on the observation completeness measurement of the object, shown in the right subfigure of Fig. 8(a), and incorporates the influence on object pose estimation.
信息增益定义:如图8(b)所示,对象驱动的探索旨在预测不同候选相机视图的信息增益,然后选择一个最大化信息增益的探索,即NBV . 本工作中的信息被定义为地图的不确定性,如第 VII-A 节所述。 因此,信息增益被定义为相机放置在特定姿势后不确定性降低和精度提高的度量。 通常,信息增益是根据环境中未知区域的面积来定义的,例如,图 8(a) 中子图中的黑洞,这可能会误导对象图的构建。 与传统方法相比,我们提出的信息增益建立在物体的观察完整性测量之上,如图 8(a)的右子图所示,并结合了对物体姿态估计的影响。
Information Gain Modeling: As indicated by the definition, information gain is contingent on many factors; thus, we create a utility function to model the information gain by manually designing a feature vector to parameterize those factors. The following is the design of the feature vector used to characterize the object x,
信息增益建模:如定义所示,信息增益取决于许多因素; 因此,我们创建了一个效用函数,通过手动设计一个特征向量来参数化这些因素,从而对信息增益进行建模。 下面是用来表征对象x的特征向量的设计,
x = ( H o b j , H ‾ o b j , R o , R I o U , V ‾ o b j , s ) , x=(H_{obj},\overline H_{obj},R_o,R_{IoU},\overline V_{obj},s), x=(Hobj,Hobj,Ro,RIoU,Vobj,s),
where H o b j H_{obj} Hobj , and H ‾ o b j \overline H_{obj} Hobj are defined by Eq. (18) - (20), R o R_o Ro is the ratio of occupied grids to the total grids of the object, which indicates the richness of its surface texture, R I o U R_{IoU} RIoU is the 2D mean IoU with adjacent objects used for modeling occlusion under a specific camera view, V ‾ o b j \overline V_{obj} Vobj is the current volume of the object, and s is a binary value used for indicating whether the object is fully explored.
其中 H o b j H_{obj} Hobj 和 H ‾ o b j \overline H_{obj} Hobj 由等式定义。 (18) - (20), R o R_o Ro是被占用的网格占物体总网格的比例,表示其表面纹理的丰富程度, R I o U R_{IoU} RIoU是与相邻物体的二维平均IoU,用于 在特定相机视图下建模遮挡, V ‾ o b j \overline V_{obj} Vobj 是对象的当前体积,s 是用于指示对象是否被完全探索的二进制值。
The utility function for NBV selection then is defined as:
NBV 选择的效用函数定义为:
f = ∑ x ∈ I ( ( 1 − R o ) H o b j + λ ( H I o U + H V ) ) s ( x ) , f=\sum_{x\in I}((1-R_o)H_{obj}+\lambda(H_{IoU}+H_V))s(x), f=x∈I∑((1−Ro)Hobj+λ(HIoU+HV))s(x),
where I is the predicted camera view, λ is a weight coefficient (λ = 0.2 in our implementation), and H I o U H_{IoU} HIoU , H V H_V HV share the same formula,
其中 I 是预测的相机视图,λ 是权重系数(在我们的实现中 λ = 0.2), H I o U H_{IoU} HIoU 和 H V H_V HV 共享相同的公式,
H = − p l o g ( p ) . H=-plog(p). H=−plog(p).
The first item ∑ x ∈ I ( 1 − R o ) H o b j \sum_{x∈I}(1 − R_o)H_{obj} ∑x∈I(1−Ro)Hobj in Eq. (22) is used to model the total weighted uncertainty of the object map under the predicted camera view. Here we give more weight to the unknown grids and the free ones by using 1−Ro. The reason is to encourage more explorations in free regions to find more image features that are neglected by previous sensing.
等式中的第一项 ∑ x ∈ I ( 1 − R o ) H o b j \sum_{x∈I}(1 − R_o)H_{obj} ∑x∈I(1−Ro)Hobj (22) 用于在预测的摄像机视图下对对象图的总加权不确定性进行建模。 在这里,我们通过使用 1−Ro 给未知网格和自由网格更多的权重。 原因是鼓励在自由区域进行更多探索,以找到更多被先前感知忽略的图像特征。
The second item ∑ x ∈ I H I o U \sum_{x∈I}H_{IoU} ∑x∈IHIoU in Eq. (22) defines the uncertainty of object detection, which is one of the critical factors affecting object pose estimation. The uncertainty is essentially caused by occlusions between objects. We use this item to encourage a complete observation of the object. The variable in Eq. (23) is the rescaled 2D IoU, i.e., p = R I o U / 2 p = R_{IoU}/2 p=RIoU/2.
等式中的第二项 ∑ x ∈ I H I o U \sum_{x∈I}H_{IoU} ∑x∈IHIoU。 (22) 定义了物体检测的不确定性,这是影响物体姿态估计的关键因素之一。 不确定性本质上是由对象之间的遮挡引起的。 我们使用这个项目来鼓励对对象的完整观察。 方程式中的变量。 (23) 是重新缩放的 2D IoU,即 p = R I o U / 2 p = R_{IoU}/2 p=RIoU/2。
The third item ∑ x ∈ I H V \sum_{x∈I} H_V ∑x∈IHV in Eq. (22) models the uncertainty of object pose estimation. Under different camera views, the estimated object poses are usually different and induce the changes in object volume. Here, we first fit a standard normal distribution using the normalized history volumes { V ‾ o b j ( 0 ) , V ‾ o b j ( 1 ) , . . . , V ‾ o b j ( t ) } \{\overline V_{obj}^{(0)}, \overline V_{obj}^{(1)}, ..., \overline V_{obj}^{(t)}\} {Vobj(0),Vobj(1),...,Vobj(t)} of each object, and then take the probability density of V ‾ o b j ( t ) \overline V_{obj}^{(t)} Vobj(t) as the value p in Eq. (23). This item essentially encourages the camera view that can converge the pose estimation process.
方程式中的第三项 ∑ x ∈ I H V \sum_{x∈I} H_V ∑x∈IHV。 (22) 模拟物体姿态估计的不确定性。 在不同的相机视图下,估计的物体姿态通常不同,并引起物体体积的变化。 在这里,我们首先使用归一化历史卷 { V ‾ o b j ( 0 ) , V ‾ o b j ( 1 ) , . . . , V ‾ 拟 合标准正态分布 o b j ( t ) } \{\overline V_{obj}^{(0)}, \overline V_{obj}^{(1)}, ..., \overline V_ 拟合标准正态分布 {obj}^{(t)}\} {Vobj(0),Vobj(1),...,V拟合标准正态分布obj(t)},然后取 V ‾ o b j ( t ) \overline V_{obj}^{(t)} Vobj(t)的概率密度作为等式中的值p。 (23). 该项目本质上鼓励可以收敛姿势估计过程的相机视图。
The s(x) in Eq. (22) indicates whether the object should be considered during the calculation of the utility function. Set s(x)=0, if the following condition is satisfied: ( H ‾ g r i d < 0.5 ⋁ R o > 0.5 ) ⋀ p ( V ‾ o b j ( t ) ) > 0.8 (\overline H_{grid} < 0.5 \bigvee R_o >0.5) \bigwedge p(\overline V_{obj}^{(t)}) > 0.8 (Hgrid<0.5⋁Ro>0.5)⋀p(Vobj(t))>0.8. If this condition holds for all the objects, or the maximum tries are achieved (10 in this work), the exploration will be finished.
方程式中的 s(x)。 (22) 表示在计算效用函数时是否应该考虑对象。 设s(x)=0,若满足以下条件: $(\overline H_{grid} < 0.5 \bigvee R_o >0.5) \bigwedge p(\overline V_{obj}^{(t)}) > 0.8 $。 如果此条件适用于所有对象,或者达到最大尝试次数(在本工作中为 10 次),则探索将结束。
Based on the utility function, the NBV that maximizes f is continuously selected and leveraged to guide the exploration process, during which the global object map is also incrementally constructed, as depicted in Fig. 6
基于效用函数,不断选择和利用使 f 最大化的 NBV 来指导探索过程,在此过程中也逐步构建全局对象图,如图 6 所示
VIII. EXPERIMENT
The experiment will demonstrate the performance of essential techniques such as data association, object parameterization, and active exploration. In addition, the proposed object SLAM framework will be evaluated by various applications, such as object mapping, augmented reality, scene matching, relocalization, and robotic grasping, .
该实验将演示数据关联、对象参数化和主动探索等基本技术的性能。 此外,拟议的对象 SLAM 框架将通过各种应用程序进行评估,例如对象映射、增强现实、场景匹配、重定位和机器人抓取。
A. Distributions of Different Statistics
For data association, the adopted 3D statistics for statistical testing include the point clouds and their centroids of an object. To verify our hypothesis about the distributions of different statistics, we analyze a large amount of data and visualize their distributions in Fig. 9.
对于数据关联,统计测试采用的 3D 统计包括对象的点云及其质心。 为了验证我们关于不同统计数据分布的假设,我们分析了大量数据并在图 9 中可视化了它们的分布。
Fig. 9 (a) shows the distributions of the point clouds from 13 objects during the data association in the TUM RGB-D fr3 long office sequence [77]. Obviously, these statistics do not follow a Gaussian distribution. The distributions are related to specific characteristics of the objects, and do not show consistent behaviors. Fig. 9 (b) shows the error distribution of object centroids, which typically follow the Gaussian distribution. This error is computed between the centroids of objects detected in each frame and the object centroid in the final, well-constructed map. This result verifies the reasonability of applying the nonparametric Wilcoxon Rank-Sum test for point clouds and the t-test for object centroids.
图 9(a)显示了 TUM RGB-D fr3 长办公室序列中数据关联期间来自 13 个对象的点云分布 [77]。 显然,这些统计数据不服从高斯分布。 分布与对象的特定特征有关,并没有表现出一致的行为。 图 9(b)显示了对象质心的误差分布,通常服从高斯分布。 该误差是在每个帧中检测到的对象的质心与最终构建良好的地图中的对象质心之间计算的。 该结果验证了对点云应用非参数 Wilcoxon Rank-Sum 检验和对对象质心应用 t 检验的合理性。

B. Object-level Data Association Experiments
We compare our method with the commonly-used Intersection over Union (IoU) method, nonparametric test (NP), and t-test. Fig. 10 shows the association results of these methods in the TUM RGB-D fr3 long office sequence. It can be seen that some objects are not correctly associated in (a)-©. Due to the lack of association information, existing objects are often misrecognized as new ones by these methods once the objects are occluded or disappear in some frames, resulting in many unassociated objects in the map. In contrast, our method is much more robust and can effectively address this problem (see Fig. 10(d)). The results of other sequences are shown in Table I, and we use the same evaluation metric as [12], [78], which measures the number of objects that are finally present in the map. The GT represents the ground-truth object number. As we can see, our method achieves a high success rate of association, and the number of objects in the map goes closer to GT, which significantly demonstrates the effectiveness of the proposed method.
我们将我们的方法与常用的并集交集 (IoU) 方法、非参数检验 (NP) 和 t 检验进行了比较。 图 10 显示了这些方法在 TUM RGB-D fr3 长办公室序列中的关联结果。 可以看出(a)-(c)中有些对象没有正确关联。 由于缺乏关联信息,一旦对象在某些帧中被遮挡或消失,这些方法往往会将现有对象误识别为新对象,从而导致地图中出现许多未关联的对象。 相比之下,我们的方法更加稳健,可以有效地解决这个问题(见图 10(d))。 其他序列的结果如表一所示,我们使用与 [12]、[78] 相同的评估指标,它衡量最终出现在地图中的对象数量。 GT 表示地面实况对象编号。 正如我们所看到的,我们的方法实现了很高的关联成功率,并且地图中的对象数量更接近 GT,这显着证明了所提出方法的有效性。
The results of our comparison with [12], [78], which is based on the nonparametric test, are reported in II. As indicated, our method can significantly outperform [12], [78]. Especially in the TUM dataset, the number of successfully associated objects by our method is almost twice that by [12], [78]. The advantage in Microsoft RGBD [79] and Scenes V2 [80] is not apparent since the number of objects is limited. Reasons for the inaccurate association of [12], [78] lie in two folds: 1) The method does not exploit different statistics and only uses non-parametric statistics, thus resulting in many unassociated objects; 2) A clustering algorithm is leveraged to tackle the abovementioned problem, but it removes most of the candidate objects.
我们与基于非参数检验的 [12]、[78] 的比较结果在 II 中报告。 如前所述,我们的方法可以显着优于 [12]、[78]。 特别是在 TUM 数据集中,我们的方法成功关联对象的数量几乎是 [12]、[78] 的两倍。 Microsoft RGBD [79] 和 Scenes V2 [80] 的优势并不明显,因为对象数量有限。 [12]、[78]关联不准确的原因有两个:1)该方法没有利用不同的统计信息,仅使用非参数统计信息,从而导致许多未关联的对象; 2)利用聚类算法来解决上述问题,但它删除了大部分候选对象。
C. Qualitative Assessment of Object Parameterization
To demonstrate the accuracy of object parameterization, We superimpose the cubes and quadrics of objects on semi-dense maps for qualitative evaluation. Fig. 11 is the 3D top view of a keyboard (Fig. 4(a)) where the cube characterizes its pose. Fig. 11(a) is the initial pose with large-scale error; Fig. 11(b) is the result after using iForest; Fig. 11© is the final pose after our joint pose estimation. Fig. 12 presents the pose estimation results of the objects in 14 sequences of the three datasets, in which the objects are placed randomly and in different directions. As is shown, the proposed method achieves promising results with a monocular camera, which demonstrates the effectiveness of our pose estimation algorithm.
为了证明对象参数化的准确性,我们将对象的立方体和二次曲面叠加在半稠密图上以进行定性评估。 图 11 是键盘的 3D 顶视图(图 4(a)),其中立方体表征了它的姿势。 图 11(a) 是具有大尺度误差的初始位姿; 图11(b)是使用iForest后的结果; 图 11© 是我们联合姿态估计后的最终姿态。 图 12 给出了三个数据集的 14 个序列中物体的姿态估计结果,其中物体随机放置在不同的方向。 如图所示,所提出的方法使用单目相机取得了可喜的结果,这证明了我们的姿态估计算法的有效性。

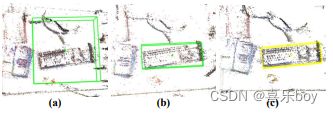
Fig. 11: Visualization of the pose estimation. (a): Initial object pose and size. (b): Object pose and size after iForest. ©: object pose and size after iForest and line alignment.

Fig. 12: Results of object pose estimation. Odd columns: original RGB images. Even column: estimated object poses.
D. Object-Oriented Map Building
Then, we build the object-oriented semantic maps based on the robust data association algorithm, the accurate object pose estimation algorithm and a semi-dense mapping system [81]. Fig. 13 shows three examples of TUM fr3 long office and fr2 desk, where (d) and (e) show semi-dense semantic and object-oriented maps built by our object SLAM. Compared with the sparse map of ORB-SLAM2, our maps can express the environment much better. Moreover, the object-oriented map shows superior performance in environment understanding than the semi-dense map.
然后,我们基于稳健的数据关联算法、准确的对象姿态估计算法和半密集映射系统构建面向对象的语义图[81]。 图 13 显示了 TUM fr3 长办公室和 fr2 办公桌的三个示例,其中(d)和(e)显示了由我们的对象 SLAM 构建的半密集语义和面向对象的地图。 与 ORB-SLAM2 的稀疏地图相比,我们的地图可以更好地表达环境。 此外,面向对象地图在环境理解方面表现出优于半稠密地图的性能。
The mapping results of other sequences in TUM, Microsoft RGB-D, and Scenes V2 datasets are shown in Fig. 14. It can be seen that the system can process multiple classes of objects with different scales and orientations in complex environments. Inevitably, there are some inaccurate estimations. For instance, in the fire sequence, the chair is too large to be well observed by the fast-moving camera, thus yielding an inaccurate estimation. We also conduct the experiment in a real scenario (Fig. 15). It can be seen that even if the objects are occluded, they can be accurately estimated, which further verifies the robustness and accuracy of our system.
TUM、Microsoft RGB-D 和 Scenes V2 数据集中其他序列的映射结果如图 14 所示。可以看出,该系统可以处理复杂环境中具有不同尺度和方向的多类对象。 难免会有一些不准确的估计。 例如,在火灾序列中,椅子太大而无法被快速移动的摄像机很好地观察到,从而产生不准确的估计。 我们还在真实场景中进行了实验(图 15)。 可以看出,即使物体被遮挡,也能准确估计,进一步验证了我们系统的鲁棒性和准确性。
E. Augmented Reality Experiment
Early augmented reality used QR codes, 2D manual features, or image temples to register virtual 3D models, resulting in a restricted range of motion and poor tracking. The sparse point cloud map created by SLAM enables large-scale tracking and high-robust registration for AR. Geometric SLAM-based AR, however, is only concerned with accuracy and robustness, not authenticity. Conversely, our object SLAM-based AR provides complete environment information, thus a more realistic immersive experience can be achieved.
早期的增强现实使用 QR 码、2D 手动功能或图像镜腿来注册虚拟 3D 模型,导致运动范围受限且跟踪效果差。 SLAM 创建的稀疏点云图可以实现 AR 的大规模跟踪和高鲁棒性配准。 然而,基于几何 SLAM 的 AR 只关心准确性和鲁棒性,而不关心真实性。 相反,我们基于对象 SLAM 的 AR 提供了完整的环境信息,从而可以实现更逼真的沉浸式体验。
In the case of the desk scene in Fig. 16(a), we use the method described above to construct an object map, as shown in Fig. 16(b), in which we model objects such as the book, keyboard, and bottles.
对于图 16(a) 中的办公桌场景,我们使用上述方法构建对象图,如图 16(b) 所示,其中我们对书籍、键盘和 瓶子。
3D Registration: We present an object-triggered virtual model registration method, instead of 3D registration triggered by a plane or position humanly specified. As shown in Fig. 18(a), the top row represents three raw frames from the video stream, while the bottom row represents the corresponding real-virtual integration scene. Virtual models can be seen registered on the desk to replace real objects based on the object semantics, pose, and size encoded in the object map.
3D 配准:我们提出了一种对象触发的虚拟模型配准方法,而不是人为指定的平面或位置触发的 3D 配准。 如图 18(a) 所示,顶行代表来自视频流的三个原始帧,而底行代表相应的实-虚融合场景。 可以看到虚拟模型已注册在桌面上,以根据对象映射中编码的对象语义、姿势和大小来替换真实对象。
Occlusion and collision: Physical occlusion and collision between the actual scene and virtual models is the crucial reflection of augmented reality. The top row, as seen in Fig. 18(b), is the result of common augmented reality, where virtual models are registered on the top layer of the image, resulting in an unrealistic separation of real and virtual scenes. The bottom row of Fig. 18(b) shows the outcome of our object SLAM-based augmented reality, in which the foreground and background are distinguished, and the real object obscures a portion of the virtual model, where the virtual and physical worlds are fused together. Similarly, Fig. 18© depicts the collision effect. The virtual model in the top row falls on the desk without colliding with the bottle. Contrarily, the bottom row shows the outcome of our object SLAM-based augmented reality, in which the virtual model falls and collides with the real bottle, with the dropping propensity changing.
遮挡与碰撞:真实场景与虚拟模型之间的物理遮挡与碰撞是增强现实的重要体现。 如图 18(b) 所示,第一行是普通增强现实的结果,其中虚拟模型被注册在图像的顶层,导致真实场景和虚拟场景的分离不切实际。 图 18(b) 的底行显示了我们基于对象 SLAM 的增强现实的结果,其中前景和背景被区分,真实对象遮挡了虚拟模型的一部分,其中虚拟世界和物理世界是 融合在一起。 类似地,图 18© 描绘了碰撞效果。 顶行的虚拟模型落在桌子上,没有与瓶子发生碰撞。 相反,底行显示了我们基于对象 SLAM 的增强现实的结果,其中虚拟模型掉落并与真实瓶子碰撞,掉落倾向发生变化。
Semantic interaction: Interaction, cascading user command with the real scene and virtual models, plays a crucial role in augmented reality applications. As shown in Fig. 17, clicking different real-world objects produces different virtual interactive effects.
语义交互:交互,将用户命令与真实场景和虚拟模型进行级联,在增强现实应用中起着至关重要的作用。 如图17所示,点击不同的现实世界对象会产生不同的虚拟交互效果。
The above functions, object-triggered 3D registration, occlusion, collision, and interaction, rely on accurate object perception of the proposed object SLAM framework. The experimental results demonstrate that object SLAM-based augmented reality has a fascinating benefit in areas such as gaming, military training, and virtual decorating.
上述功能,对象触发的 3D 注册、遮挡、碰撞和交互,依赖于所提出的对象 SLAM 框架的准确对象感知。 实验结果表明,基于对象 SLAM 的增强现实在游戏、军事训练和虚拟装饰等领域具有令人着迷的优势。

Fig. 13: Different map representations. (a) the RGB images. (b) the sparse map. © semi-dense map. (d) our semi-dense semantic map. (e) our lightweight and object-oriented map. (d) and (e) are build by the proposed method.

Fig. 14: Mapping results on the three datasets. Top: raw images. Bottom: simi-dense object-oriented map.

Fig. 15: Mapping results in a real scenario. Top: raw images. Middle: semi-dense object-oriented map. Bottom: lightweight and object-oriented map.

Fig. 16: The raw image and the corresponding object map.

Fig. 17: The demonstration of interaction. Reactions are visualized as a series of augmented reality events.
F. Object-based Scene Matching and Relocalization
Scene Matching. In this experiment, we evaluate the performance of the proposed object descriptor-based scene matching, which is crucial for multi-agent collaboration, scene reidentification, and multi-maps merging at different periods. We acquire two separate trajectories and their associated object maps in the same scene, then utilize the suggested method to figure out their relationship. Fig. 19 illustrates the map-matching results in three settings.
场景匹配。 在这个实验中,我们评估了所提出的基于对象描述符的场景匹配的性能,这对于多代理协作、场景重新识别和不同时期的多地图合并至关重要。 我们在同一场景中获取两个独立的轨迹及其关联的对象图,然后利用建议的方法找出它们之间的关系。 图 19 说明了三种设置下的地图匹配结果。
The results of the TUM and Microsoft sequences are shown in Fig. 19(a) and Fig. 19(b). The two maps with different scales and numbers of objects match accurately, and the translation between them is also resolved. The match is not based on point clouds or BoW (Bag of Words) of keyframes, but the semantic object descriptor constructed by the object topological map. Additionally, the scale inconsistency of the two maps is also eliminated. Fig. 19© shows a real-world example of the matched result. Apart from the previous features, what is worth noting is that the two maps were recorded under different illumination. With this scenario, the traditional appearance-based method is trends to fail, demonstrating the robustness of the proposed object descriptor with the semantic level invariance property.
TUM 和 Microsoft 序列的结果如图 19(a) 和图 19(b) 所示。 两张不同比例尺和物体数量的地图匹配准确,它们之间的平移也解决了。 匹配不是基于点云或关键帧的BoW(Bag of Words),而是基于对象拓扑图构建的语义对象描述符。 此外,还消除了两张地图比例尺不一致的情况。 图 19© 显示了匹配结果的真实示例。 除了之前的特征,值得注意的是这两张地图是在不同光照下记录的。 在这种情况下,传统的基于外观的方法往往会失败,证明了所提出的具有语义级不变性的对象描述符的鲁棒性。
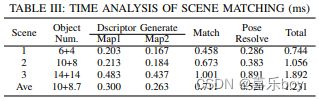
Table III analyzes the performance time of the algorithm. The matching duration is found to be the primary cost, and the time is positively related to the number of objects. The average total duration is approximately 1.23ms, which is both practical and economical in various robot applications.
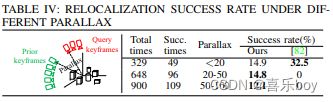
Relocalization. We perform relocalization experiments with parallax to demonstrate the robustness of the proposed matching method to viewpoint changes. As illustrated in the figure in Tab. IV, we first construct a prior map with a set of prior keyframes and then utilize query keyframes for relocalization, which do not overlap the trajectories of prior keyframes and have parallax. We conduct several repeated experiments under different parallax conditions and compare the success rate of relocalization with ORB-SLAM3 [82]. When the parallax is less than 20%, as shown in Tab. IV, ORB-SLAM3 achieves a relocalization success rate of 32.5%; however, the rate drops sharply to 0 when the parallax is greater than 20%, which demonstrates that the appearance-based descriptor represented by ORB-SLAM3 is extremely sensitive to parallax. Conversely, our method is robust to parallax and achieves a success rate of over 12% even under challenging large parallax.
重新定位。 我们使用视差进行重新定位实验,以证明所提出的匹配方法对视点变化的鲁棒性。 如表中的图所示。 IV,我们首先用一组先验关键帧构建先验图,然后利用查询关键帧进行重定位,这些关键帧不与先验关键帧的轨迹重叠并且具有视差。 我们在不同的视差条件下进行了多次重复实验,并比较了 ORB-SLAM3 的重定位成功率 [82]。 当视差小于 20% 时,如表 1 所示。 IV、ORB-SLAM3实现了32.5%的重定位成功率; 然而,当视差大于 20% 时,该比率急剧下降到 0,这表明以 ORB-SLAM3 为代表的基于外观的描述符对视差极其敏感。 相反,我们的方法对视差具有鲁棒性,即使在具有挑战性的大视差下也能达到超过 12% 的成功率。
However, the accuracy of 14.9% is still unsatisfactory. We found that the primary reason is that the observations of the two sets of keyframes are incomplete, thus resulting in inaccurate object modeling. To prove our hypothesis, we manually generate a scene with objects and divide it into a prior map and query map, assuming that prior and query keyframes generate them, respectively, and that the poses of the objects are obtained from the ground truth. As depicted in the figure in Tab. V, we adjust the proportion of shared objects across the two maps and measure the success rate of relocalization. As demonstrated in Tab. V, we obtain a 100% success rate with a public object ratio of over 50% and retain over 80% accuracy with a ratio of 33%. The result demonstrates the effectiveness of our proposed object descriptor and matching algorithm. It also illustrates its sensitivity to object pose and suggests that more accurate object modeling methods can improve its performance.
但是,14.9%的准确率还是差强人意。 我们发现主要原因是两组关键帧的观察不完整,从而导致对象建模不准确。 为了证明我们的假设,我们手动生成一个包含对象的场景并将其分为先验图和查询图,假设先验关键帧和查询关键帧分别生成它们,并且对象的姿势是从地面实况中获得的。 如表中的图所示。 V,我们调整了两个地图共享对象的比例并测量了重定位的成功率。 如表中所示。 V,我们获得了 100% 的成功率,公共对象比例超过 50%,保留了 80% 以上的准确率,比例为 33%。 结果证明了我们提出的对象描述符和匹配算法的有效性。 它还说明了它对物体姿态的敏感性,并表明更准确的物体建模方法可以提高其性能。

G. Evaluation of Active Mapping
To validate the effectiveness of the active map building and the viability of robot manipulation led by the map, we conduct extensive evaluations in both simulation and real-world environments. The simulated robotic manipulation scene is set in Sapien [83], shown in Fig. 20, where the number of objects and the scene complexities vary in different scenes.
为了验证主动地图构建的有效性和地图引导的机器人操作的可行性,我们在模拟和现实环境中进行了广泛的评估。 Sapien [83] 中设置了模拟的机器人操作场景,如图 20 所示,在不同的场景中,物体的数量和场景的复杂度各不相同。
The accurate position estimate is critical for successful robotic manipulation operations such as grasping, placing, arranging, and planning. However, precision is difficult to ensure when the robot estimates autonomously. To quantify the effect of active exploration on object pose estimation, like previous studies [74], [84], we compare our object-driven method with two typically used baseline strategies, i.e., randomized exploration (Random.) and coverage exploration (Cover.). As indicated in Fig. 20, for randomized exploration, the camera pose is randomly sampled from the reachable set relative to the manipulator, while for coverage exploration, a coverage trajectory based on Boustrophedon decomposition [85] is leveraged to scan the scene. At the beginning of all the explorations, an initialization step (Init.), in which the camera is sequentially placed over the four desk corners from a top view, is applied to start the object mapping process. The simulator provides the ground truth of object position, orientation, and size. Correspondingly, the accuracy of pose estimation is evaluated by the Center Distance Error (CDE, cm), the Yaw Angle Error (YAE, degree), and the IoU (including 2D IoU from the top view and 3D IoU) between the ground truth and our estimated results.
准确的位置估计对于机器人操作的成功至关重要,例如抓取、放置、排列和规划。 然而,机器人自主估计时,精度难以保证。 为了量化主动探索对物体姿态估计的影响,就像之前的研究[74]、[84]一样,我们将我们的对象驱动方法与两种通常使用的基线策略进行比较,即随机探索(Random.)和覆盖探索(Cover .). 如图 20 所示,对于随机探索,相机姿态是从相对于操纵器的可达集合中随机采样的,而对于覆盖探索,利用基于 Boustrophedon 分解 [85] 的覆盖轨迹来扫描场景。 在所有探索的开始,应用初始化步骤(Init.),其中相机从顶视图顺序放置在四个桌子角上,以启动对象映射过程。 模拟器提供对象位置、方向和大小的基本事实。 相应地,姿态估计的准确性通过中心距离误差(CDE,cm),偏航角误差(YAE,度),以及ground truth和ground truth之间的IoU(包括俯视图的2D IoU和3D IoU)来评估。 我们估计的结果。

(a) Object-triggered 3D registration. Top: raw images of the scene. Bottom: augmented reality scene with registered virtual models in place of the original objects. (b) The demonstration of occlusion. Top:
the standard AR without occlusion. Bottom: our object SLAM-based AR. © The demonstration of collision. Top: the standard augmented reality. Bottom: our object-SLAM-based augmented reality with the awareness of collision.
Fig. 18: 3D registration, occlusion, and collision in object SLAM-based augmented reality.

Fig. 19: The quantitative analysis of scene matching.
Table VI shows the evaluation results in seven scenes (Fig. 20). We can see our proposed object-driven exploration strategy achieves a 3D IoU of 45.3%, which is 15.53%, 8.85%, and 13.3% higher than that of the randomized exploration, the coverage exploration, and the initialization, respectively. For 2D IoU, our method achieves an accuracy of 64.83%, which is 15.14%, 10.64%, and 13.12% higher than baseline methods. In terms of CDE, our method reaches 1.62cm, significantly less than other methods. For YAE, all exploration strategies achieve an error of approximately 3◦, which verifies the robustness of our line-alignment-based yaw angle optimization method. The level of above precision attained is sufficient for robotic manipulation [86]. Moreover, we also find that randomized exploration sometimes performs worse than the initialization result (rows 2, 5, and 7), which indicates that increasing observations do not necessarily result in more accurate pose estimation, and purposeful exploration is necessary.
表 VI 显示了七个场景的评估结果(图 20)。 我们可以看到我们提出的对象驱动探索策略实现了 45.3% 的 3D IoU,分别比随机探索、覆盖探索和初始化高 15.53%、8.85% 和 13.3%。 对于 2D IoU,我们的方法达到了 64.83% 的准确率,比基线方法高出 15.14%、10.64% 和 13.12%。 在 CDE 方面,我们的方法达到 1.62cm,明显小于其他方法。 对于 YAE,所有探索策略都实现了大约 3° 的误差,这验证了我们基于线对齐的偏航角优化方法的稳健性。 达到的上述精度水平足以进行机器人操作 [86]。 此外,我们还发现随机探索有时比初始化结果(第 2、5 和 7 行)表现更差,这表明增加观察并不一定会导致更准确的姿态估计,有目的的探索是必要的。
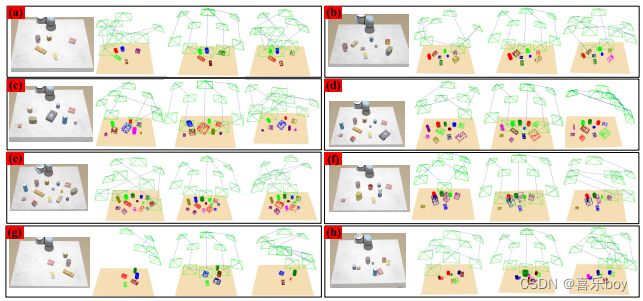
Fig. 20: Comparison of mapping results. The first column in the sub-picture: the scene image; the second column: the result of our object-driven exploration; the third column: the result of the coverage exploration; the fourth column: the result of the randomized exploration.
The mapping results are shown in Fig. 20. The cubes and cylinders are used to model the objects, including poses and scales (analyzed above), based on their semantic categories. The following characteristics are present: 1) The system can accurately model various objects as the number of objects increases, as shown in Fig. 20(a)-(e), demonstrating its robustness. 2) Among objects of various sizes, our method focuses more on large objects with lower observation completeness (see Fig. 20(f)). 3) When objects are distributed unevenly, our proposed strategy can swiftly concentrate the camera on object regions, thus avoiding unnecessary and time-consuming exploration (see Fig. 20(g). 4) For scenes with objects close to each other, our method can focus more on regions with fewer occlusions (see Fig. 20(h)). These behaviors verify the effectiveness of our exploration strategy. Additionally, our method has a shorter exploration path yet produces a more precise object posture.
映射结果如图 20 所示。立方体和圆柱体用于根据对象的语义类别对对象进行建模,包括姿势和比例(如上分析)。 具有以下特点: 1)随着对象数量的增加,系统可以准确地对各种对象进行建模,如图20(a)-(e)所示,证明了其鲁棒性。 2)在各种大小的物体中,我们的方法更侧重于观察完整性较低的大物体(见图20(f))。 3)当物体分布不均匀时,我们提出的策略可以迅速将相机集中在物体区域,从而避免不必要且耗时的探索(见图 20(g))。4)对于物体彼此靠近的场景,我们的方法 可以更多地关注遮挡较少的区域(见图 20(h))。 这些行为验证了我们探索策略的有效性。 此外,我们的方法具有较短的探索路径,但会产生更精确的物体姿态。
H. Object Grasping and Placement
This experiment uses the incrementally generated object map to perform object grasping. Fig. 21(a) and Fig. 21(b) illustrate the grasping process in simulated and real-world environments, with the object map included. After extensive testing, we obtained a grasping success rate of approximately 86% in the simulator and 81% in the real world, which may be affected by environmental or manipulator noises. It is found that the center and direction of the objects have a significant influence on grasping performance. The proposed method performs well regarding these two metrics, thus ensuring high-quality grasping. Overall, our object SLAM-based pose estimation results can satisfy the requirements of grasping.
本实验使用增量生成的对象图来执行对象抓取。 图 21(a) 和图 21(b) 说明了在模拟和真实环境中的抓取过程,包括对象图。 经过大量测试,我们在模拟器中获得了大约 86% 的抓取成功率,在现实世界中获得了 81% 的抓取成功率,这可能会受到环境或机械手噪音的影响。 发现物体的中心和方向对抓取性能有显着影响。 所提出的方法在这两个指标方面表现良好,从而确保了高质量的抓取。 总体而言,我们基于对象 SLAM 的姿态估计结果可以满足抓取的要求。
We argued that the proposed object map level perception outperforms object pose-only perception and provides information for more intelligent robotics decision-making tasks in addition to grasping. Such include avoiding collisions with other objects, updating the map after grasping, object arrangement and placement based on object properties, and object delivery requested by the user. We design the object placement experiments to verify the global perception capabilities introduced by object mapping. As shown in Fig. 22, the robot is required to manipulate the original scene (see Fig. 22(a)) to the target scene (see Fig. 22©) according to object sizes and classes encoded in the object map.
我们认为,所提出的对象地图级别感知优于仅对象姿势感知,并为除了抓取之外的更智能的机器人决策任务提供信息。 这包括避免与其他对象发生碰撞、抓取后更新地图、基于对象属性的对象排列和放置以及用户请求的对象传递。 我们设计了对象放置实验来验证对象映射引入的全局感知能力。 如图 22 所示,机器人需要根据对象图中编码的对象大小和类别,将原始场景(见图 22(a))操纵到目标场景(见图 22(c))。
The global object map is shown in Fig. 22(b), which contains the semantic labels, size, and pose of the objects. The two little blocks are picked up and placed in the large cup (Fig. 22(d)), while the cups are ordered by volume (Fig. 22(e)) and the bottles by height (Fig. 22(f)). This task is challenging for the conventional grasping approach since lacking global perception such as object’s height on the map, its surroundings, and could interact with which objects.
全局对象图如图 22(b) 所示,其中包含对象的语义标签、大小和姿态。 两个小块被拿起并放在大杯子中(图 22(d)),而杯子按体积排序(图 22(e)),瓶子按高度排序(图 22(f)) . 这项任务对于传统的抓取方法来说是具有挑战性的,因为它缺乏全局感知,例如物体在地图上的高度、它的周围环境,以及可以与哪些物体相互作用。
IX. DISCUSSION AND ANALYZE
In this section, we analyze the limitations and implementation details of our method and provide potential solutions for the object SLAM community.
在本节中,我们分析了我们方法的局限性和实现细节,并为对象 SLAM 社区提供了潜在的解决方案。
1) Data association. Experiments revealed that the two primary reasons for the failure of data association could be summed up as follows: i) Long-tailed distribution. In some cases, object centroids are located in the tail of the distribution, which violates the Gaussian distribution assumption and causes the association to fail. Although our multiple association strategy alleviates this to some extent. ii) Detected semantic label mistakes. Even if the IoU-based or distribution-based method determines an association between two objects, the association will fail if the labels are inconsistent. Error in label recognition is one of the most common issues with detectors. More generalized, accurate detectors or fine-turning on specific datasets are potential alternatives.
1) 数据关联。 实验表明,数据关联失败的两个主要原因可以归纳如下: i) 长尾分布。 在某些情况下,对象质心位于分布的尾部,这违反了高斯分布假设并导致关联失败。 尽管我们的多重关联策略在一定程度上缓解了这一点。 ii) 检测到语义标签错误。 即使基于 IoU 或基于分布的方法确定了两个对象之间的关联,如果标签不一致,关联也会失败。 标签识别错误是检测器最常见的问题之一。 更通用、更准确的检测器或对特定数据集进行微调是潜在的替代方案。
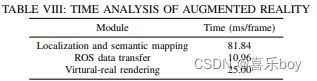
The running time of data association is shown in the first two columns of Tab. VII. Distribution-based methods include non-parametric and t-tests, while IoU-based methods include motion IoU and project IoU, where projecting 3D points to 2D images takes most of the time. Note that the total duration of data association is less than the sum in the table, approximately 8 ms per frame, because sometimes some strategies can be skipped. We perform data association on every frame, which would be more time-efficient if simply performed on keyframes, as CubeSLAM does.
数据关联的运行时间显示在Tab的前两列。 七。 基于分布的方法包括非参数和 t 检验,而基于 IoU 的方法包括运动 IoU 和投影 IoU,其中将 3D 点投影到 2D 图像需要花费大部分时间。 请注意,数据关联的总持续时间小于表中的总和,每帧大约 8 毫秒,因为有时可以跳过某些策略。 我们在每一帧上执行数据关联,如果像 CubeSLAM 那样简单地在关键帧上执行,这会更省时。

Fig. 21: The demonstration of grasping process.

Fig. 22: Object placement according to the global object map.

2) Object Parameterization. Two factors typically cause failure situations of object pose estimation: i) Object surfaces lack texture, or objects are only partially seen due to occlusion or camera viewpoint. In this case, few object point clouds are collected, significantly reducing the pose estimation performance. ii) Too many outliers lead the object to be estimated too large, or the modeled object is extremely small since the iForest algorithm falls into a local optimum. In the alternatives, the 3D detector [87] based on the complete point cloud may not be optimal due to the incremental characteristic of SLAM; image-based 6-DOF pose estimation [19], [88] is limited by the scale of the training data, resulting in poor generalization [51]. Conversely, incremental detection/segmentation [89] and joint point cloud-image multimodal RGB-D 3D object detection [90], [91] are potentially feasible.
2) 对象参数化。 两个因素通常会导致对象姿态估计的失败情况:i)对象表面缺乏纹理,或者由于遮挡或相机视点而只能部分看到对象。 在这种情况下,收集到的对象点云很少,从而显着降低了姿态估计性能。 ii) 离群点太多导致被估计的对象太大,或者建模的对象非常小,因为iForest算法陷入了局部最优。 在备选方案中,由于 SLAM 的增量特性,基于完整点云的 3D 检测器 [87] 可能不是最优的; 基于图像的 6-DOF 姿态估计 [19]、[88] 受训练数据规模的限制,导致泛化能力较差 [51]。 相反,增量检测/分割 [89] 和联合点云图像多模式 RGB-D 3D 对象检测 [90]、[91] 可能是可行的。
The runtime of object parameterization is shown in the last two columns in Tab. VII, which takes around 6.5 ms per frame on average. The full SLAM system (for camera tracking and semantic mapping) runs at about 10 fps.
对象参数化的运行时间显示在 Tab 的最后两列中。 VII,平均每帧大约需要 6.5 毫秒。 完整的 SLAM 系统(用于摄像机跟踪和语义映射)以大约 10 fps 的速度运行。
3) Augmented Reality. Augmented reality performance depends on object modeling, camera localization accuracy, and the rendering effect. Here we provide detailed engineering implementations for SLAM developers to migrate their algorithms to augmented reality applications. The AR system comprises three modules: i) The Localization and Semantic Mapping (LSM) modules provide camera position, point cloud, and object parameters. Sections IV and V introduce the techniques. ii) ROS [92] data transfer module: send images captured by the camera to the LSM module and then publish the estimated camera pose and map elements. iii) Virtual-real rendering module: Use the Unity3D engine to subscribe to topics published by ROS, construct a virtual 3D scene, and render it to a 2D image plane. Tab. VIII details the duration of each module, which is executed in parallel.
3) 增强现实。 增强现实性能取决于对象建模、相机定位精度和渲染效果。 在这里,我们为 SLAM 开发人员提供详细的工程实现,以将他们的算法迁移到增强现实应用程序。 AR 系统包括三个模块:i) 定位和语义映射 (LSM) 模块提供相机位置、点云和对象参数。 第四节和第五节介绍了这些技术。 ii) ROS [92] 数据传输模块:将相机拍摄的图像发送到 LSM 模块,然后发布估计的相机位姿和地图元素。 iii) 虚实渲染模块:使用Unity3D引擎订阅ROS发布的主题,构建虚拟3D场景,渲染到2D图像平面。 标签。 VIII 详细说明了并行执行的每个模块的持续时间。
4) Scene Matching. The principal causes for the failure of scene matching and relocalization are: i) There are few common objects between the two maps, resulting in a significant difference in the descriptors of the same object in the two maps, leading to matching fails. ii) The parallax of the trajectories of the two maps is excessively large, and the observation is insufficient, which affects the accuracy of object modeling and the construction of descriptors. Regarding the first issue, other non-object-level landmarks, such as planes and structural components, can be considered for descriptor construction. For the second challenge, more accurate object modeling techniques can improve the performance of matching and relocalization, as demonstrated by our experiments.
4) 场景匹配。 场景匹配和重定位失败的主要原因是:i)两张地图之间的共同物体很少,导致两张地图中同一物体的描述符存在显着差异,导致匹配失败。 ii) 两张图的轨迹视差过大,观测不足,影响物体建模的准确性和描述子的构建。 关于第一个问题,可以考虑其他非对象级地标,例如平面和结构组件,来构建描述符。 对于第二个挑战,更准确的对象建模技术可以提高匹配和重新定位的性能,正如我们的实验所证明的那样。
5) Object Grasping. There are two limitations to the object grasping task: i) Textured objects and tabletops are required for point-based SLAM tracking to succeed. ii) Objects are all regular cube and cylinder shapes in our experiments. Complex irregular objects may necessitate more detailed shape reconstruction and grasp point detection. Nonetheless, we demonstrate the potential of object SLAM for grasping tasks without object priors. Model-free and unseen object grasping will be the future trend. In terms of running time, the speed is even faster than 10fps because, in this setting, the data association is more straightforward, and more time is spent on the active mapping analysis process.
5) 对象抓取。 对象抓取任务有两个限制:i)基于点的 SLAM 跟踪成功需要纹理对象和桌面。 ii) 在我们的实验中,物体都是规则的立方体和圆柱体。 复杂的不规则物体可能需要更详细的形状重建和抓取点检测。 尽管如此,我们展示了对象 SLAM 在没有对象先验的情况下掌握任务的潜力。 无模型和看不见的物体抓取将是未来的趋势。 在运行时间上,速度甚至超过了 10fps,因为在这种设置下,数据关联更直接,更多时间花在主动映射分析过程上。
X. CONCLUSION
We presented an object mapping framework that aims to create an object-oriented map using general models that parameterize the object’s position, orientation, and size. First, we investigated related fundamental techniques for object mapping, including multi-view data association and object pose estimation. We then center on the object map and validate its potential in multiple high-level tasks such as augmented reality, scene matching, and object grasping. Finally, we analyzed the limitations and failure instances of our method and gave possible alternatives to inspire the development of related fields. The following points will be given significant consideration in future work: 1) Dynamic objects data association, tracking, and trajectory prediction; 2) Irregular and unseen object modeling and tightly coupled optimization with SLAM; 3) Object-level relocalization and loop closure; 4) Omnidirectional perception with multi-sensor and multiple semantic networks to realize spatial AI.
我们提出了一个对象映射框架,旨在使用参数化对象的位置、方向和大小的通用模型来创建面向对象的映射。 首先,我们研究了对象映射的相关基础技术,包括多视图数据关联和对象姿态估计。 然后,我们以对象图为中心,验证其在增强现实、场景匹配和对象抓取等多个高级任务中的潜力。 最后,我们分析了我们方法的局限性和失败实例,并给出了可能的替代方案,以启发相关领域的发展。 以下几点将在未来的工作中得到重要考虑: 1)动态对象数据关联、跟踪和轨迹预测; 2)不规则和看不见的物体建模和与SLAM的紧耦合优化; 3)对象级重定位和闭环; 4)多传感器多语义网络全方位感知,实现空间人工智能。
REFERENCES
[1] A. J. Davison, “Futuremapping: The computational structure of spatial ai systems,” arXiv preprint arXiv:1803.11288, 2018.
[2] Q. Wang, Z. Yan, J. Wang, F. Xue, W. Ma, and H. Zha, “Line flow based simultaneous localization and mapping,” IEEE Transactions on Robotics, vol. 37, no. 5, pp. 1416–1432, 2021.
[3] Y. Zhou, H. Li, and L. Kneip, “Canny-vo: Visual odometry with rgb-d cameras based on geometric 3-d–2-d edge alignment,” IEEE Transactions on Robotics, vol. 35, no. 1, pp. 184–199, 2018.
[4] R. Yunus, Y. Li, and F. Tombari, “Manhattanslam: Robust planar tracking and mapping leveraging mixture of manhattan frames,” in Proceedings of 2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 6687–6693.
[5] S. Zhao, P. Wang, H. Zhang, Z. Fang, and S. Scherer, “Tp-tio: A robust thermal-inertial odometry with deep thermalpoint,” in Proceedings of 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 4505–4512.
[6] S. Cao, X. Lu, and S. Shen, “Gvins: Tightly coupled gnss–visual–inertial fusion for smooth and consistent state estimation,” IEEE Transactions on Robotics, vol. 38, no. 4, pp. 2004–2021, 2022.
[7] T.-M. Nguyen, S. Yuan, M. Cao, T. H. Nguyen, and L. Xie, “Viral slam: Tightly coupled camera-imu-uwb-lidar slam,” arXiv preprint arXiv:2105.03296, 2021.
[8] J. McCormac, A. Handa, A. Davison, and S. Leutenegger, “Semanticfusion: Dense 3d semantic mapping with convolutional neural networks,” in Proceedings of 2017 IEEE International Conference on Robotics and automation (ICRA). IEEE, 2017, pp. 4628–4635.
[9] S. Yang, Y. Huang, and S. Scherer, “Semantic 3d occupancy mapping through efficient high order crfs,” in Proceedings of 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2017, pp. 590–597.
[10] A. Rosinol, M. Abate, Y. Chang, and L. Carlone, “Kimera: an open-source library for real-time metric-semantic localization and mapping,” in Proceedings of 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 1689–1696.
[11] D. Frost, V. Prisacariu, and D. Murray, “Recovering stable scale in monocular slam using object-supplemented bundle adjustment,” IEEE Transactions on Robotics, vol. 34, no. 3, pp. 736–747, 2018.
[12] A. Iqbal and N. R. Gans, “Localization of classified objects in slam using nonparametric statistics and clustering,” in Proceedings of 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 161–168.
[13] B. Mu, S.-Y. Liu, L. Paull, J. Leonard, and J. P. How, “Slam with objects using a nonparametric pose graph,” in Proceedings of 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2016, pp. 4602–4609.
[14] N. Sunderhauf, T. T. Pham, Y. Latif, M. Milford, and I. Reid, “Meaningful maps with object-oriented semantic mapping,” in Proceedings of 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2017, pp. 5079–5085.
[15] M. Grinvald, F. Furrer, T. Novkovic, J. J. Chung, C. Cadena, R. Siegwart, and J. Nieto, “Volumetric instance-aware semantic mapping and 3d object discovery,” IEEE Robotics and Automation Letters, vol. 4, no. 3, pp. 3037–3044, 2019.
[16] A. Sharma, W. Dong, and M. Kaess, “Compositional and scalable object slam,” in Proceedings of 2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 11 626–11 632.
[17] R. F. Salas-Moreno, R. A. Newcombe, H. Strasdat, P. H. Kelly, and A. J. Davison, “Slam++: Simultaneous localisation and mapping at the level of objects,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2013, pp. 1352–1359.
[18] S. Choudhary, L. Carlone, C. Nieto, J. Rogers, Z. Liu, H. I. Christensen, and F. Dellaert, “Multi robot object-based slam,” in Proceedings of International Symposium on Experimental Robotics. Springer, 2016, pp. 729–741.
[19] Y. Labbe, J. Carpentier, M. Aubry, and J. Sivic, “Cosypose: Consistent multi-view multi-object 6d pose estimation,” in Proceedings of European Conference on Computer Vision. Springer, 2020, pp. 574–591.
[20] S. L. Bowman, N. Atanasov, K. Daniilidis, and G. J. Pappas, “Probabilistic data association for semantic slam,” in Proceedings of 2017 IEEE international conference on robotics and automation (ICRA). IEEE, 2017, pp. 1722–1729.
[21] P. Parkhiya, R. Khawad, J. K. Murthy, B. Bhowmick, and K. M. Krishna, “Constructing category-specific models for monocular object-slam,” in Proceedings of 2018 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2018, pp. 4517–4524.
[22] N. Joshi, Y. Sharma, P. Parkhiya, R. Khawad, K. M. Krishna, and B. Bhowmick, “Integrating objects into monocular slam: Line based category specific models,” in Proceedings of the 11th Indian Conference on Computer Vision, Graphics and Image Processing, 2018, pp. 1–9.
[23] E. Sucar, K. Wada, and A. Davison, “Nodeslam: Neural object descriptors for multi-view shape reconstruction,” in 2020 International Conference on 3D Vision (3DV). IEEE, 2020, pp. 949–958.
[24] S. Yang and S. Scherer, “Cubeslam: Monocular 3-d object slam,” IEEE Transactions on Robotics, vol. 35, no. 4, pp. 925–938, 2019.
[25] L. Nicholson, M. Milford, and N. Sunderhauf, “Quadricslam: Dual quadrics from object detections as landmarks in object-oriented slam,” IEEE Robotics and Automation Letters, vol. 4, no. 1, pp. 1–8, 2018.
[26] Y. Wu, Y. Zhang, D. Zhu, Y. Feng, S. Coleman, and D. Kerr, “Eao-slam: Monocular semi-dense object slam based on ensemble data association,” in Proceedings of 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2020, pp. 4966–4973.
[27] Y. Wu, Y. Zhang, D. Zhu, X. Chen, S. Coleman, W. Sun, X. Hu, and Z. Deng, “Object slam-based active mapping and robotic grasping,” in Proceedings of 2021 International Conference on 3D Vision (3DV). IEEE, 2021, pp. 1372–1381.
[28] K. Chen, J. Liu, Q. Chen, Z. Wang, and J. Zhang, “Accurate object association and pose updating for semantic slam,” IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 12, pp. 25 169–25 179, 2022.
[29] Y. Zhang, C. Wang, X. Wang, W. Zeng, and W. Liu, “Fairmot: On the fairness of detection and re-identification in multiple object tracking,” International Journal of Computer Vision, vol. 129, no. 11, pp. 3069–3087, 2021.
[30] J. Li, D. Meger, and G. Dudek, “Semantic mapping for view-invariant relocalization,” in Proceedings of 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 7108–7115.
[31] J. McCormac, R. Clark, M. Bloesch, A. Davison, and S. Leutenegger, “Fusion++: Volumetric object-level slam,” in Proceedings of 2018 international conference on 3D vision (3DV). IEEE, 2018, pp. 32–41.
[32] J. Wang, M. Runz, and L. Agapito, “Dsp-slam: Object oriented slam with deep shape priors,” in Proceedings of 2021 International Conference on 3D Vision (3DV). IEEE, 2021, pp. 1362–1371.
[33] B. Xu, A. J. Davison, and S. Leutenegger, “Learning to complete object shapes for object-level mapping in dynamic scenes,” in Proceedings of 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022, pp. 2257–2264.
[34] Y. Liu, Y. Petillot, D. Lane, and S. Wang, “Global localization with object-level semantics and topology,” in Proceedings of 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 4909–4915.
[35] K. Ok, K. Liu, K. Frey, J. P. How, and N. Roy, “Robust object-based slam for high-speed autonomous navigation,” in Proceedings of 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 669–675.
[36] Y. Xiang and D. Fox, “Da-rnn: Semantic mapping with data associated recurrent neural networks,” in Proceedings of Robotics: Science and Systems (RSS), 2017.
[37] K. Li, D. DeTone, Y. F. S. Chen, M. Vo, I. Reid, H. Rezatofighi, C. Sweeney, J. Straub, and R. Newcombe, “Odam: Object detection, association, and mapping using posed rgb video,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp.
5998–6008.
[38] N. Merrill, Y. Guo, X. Zuo, X. Huang, S. Leutenegger, X. Peng, L. Ren, and G. Huang, “Symmetry and uncertainty-aware object slam for 6dof object pose estimation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 14 901–14 910.
[39] C. Xing, X. Sun, A. Cramariuc, S. Gull, J. J. Chung, C. Cadena, R. Siegwart, and F. Tschopp, “Descriptellation: Deep learned constellation descriptors for slam,” arXiv preprint arXiv:2203.00567, 2022.
[40] M. Strecke and J. Stuckler, “Em-fusion: Dynamic object-level slam with probabilistic data association,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 5865–5874.
[41] S. Yang, Z.-F. Kuang, Y.-P. Cao, Y.-K. Lai, and S.-M. Hu, “Probabilistic projective association and semantic guided relocalization for dense reconstruction,” in Proceedings of 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 7130–7136.
[42] J. Zhang, M. Gui, Q. Wang, R. Liu, J. Xu, and S. Chen, “Hierarchical topic model based object association for semantic slam,” IEEE transactions on visualization and computer graphics, vol. 25, no. 11, pp. 3052–3062, 2019.
[43] T. Ran, L. Yuan, J. Zhang, L. He, R. Huang, and J. Mei, “Not only look but infer: Multiple hypothesis clustering of data association inference for semantic slam,” IEEE Transactions on Instrumentation and Measurement, vol. 70, pp. 1–9, 2021.
[44] J. J. Park, P. Florence, J. Straub, R. Newcombe, and S. Lovegrove, “Deepsdf: Learning continuous signed distance functions for shape representation,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 165–174.
[45] M. Han, Z. Zhang, Z. Jiao, X. Xie, Y. Zhu, S.-C. Zhu, and H. Liu, “Reconstructing interactive 3d scenes by panoptic mapping and cad model alignments,” in Proceedings of 2021 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2021, pp. 12 199–12 206.
[46] Z. Cao, Y. Zhang, R. Tian, R. Ma, X. Hu, S. Coleman, and D. Kerr, “Object-aware slam based on efficient quadric initialization and joint data association,” IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 9802–9809, 2022.
[47] M. Runz, M. Buffier, and L. Agapito, “Maskfusion: Real-time recognition, tracking and reconstruction of multiple moving objects,” in Proceedings of 2018 IEEE International Symposium on Mixed and Augmented Reality (ISMAR). IEEE, 2018, pp. 10–20.
[48] S. Lin, J. Wang, M. Xu, H. Zhao, and Z. Chen, “Topology aware object-level semantic mapping towards more robust loop closure,” IEEE Robotics and Automation Letters, vol. 6, no. 4, pp. 7041–7048, 2021.
[49] J. Lu, B. Tian, H. Shen, and X. Zhang, “Real-time instance-aware segmentation and semantic mapping on edge devices,” IEEE Transactions on Instrumentation and Measurement, vol. 72, pp. 1–9, 2022.
[50] J. Li, K. Koreitem, D. Meger, and G. Dudek, “View-invariant loop closure with oriented semantic landmarks,” in Proceedings of 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 7943–7949.
[51] Y. Ming, X. Yang, and A. Calway, “Object-augmented rgb-d slam for wide-disparity relocalisation,” in Proceedings of 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2021, pp. 2203–2209.
[52] R. Mur-Artal and J. D. Tardos, “Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras,” IEEE Transactions on Robotics, vol. 33, no. 5, pp. 1255–1262, 2017.
[53] P. Schmuck and M. Chli, “Ccm-slam: Robust and efficient centralized collaborative monocular simultaneous localization and mapping for robotic teams,” Journal of Field Robotics, vol. 36, no. 4, pp. 763–781, 2019.
[54] A. Gawel, C. Del Don, R. Siegwart, J. Nieto, and C. Cadena, “Xview: Graph-based semantic multi-view localization,” IEEE Robotics and Automation Letters, vol. 3, no. 3, pp. 1687–1694, 2018.
[55] X. Guo, J. Hu, J. Chen, F. Deng, and T. L. Lam, “Semantic histogram based graph matching for real-time multi-robot global localization in large scale environment,” IEEE Robotics and Automation Letters, 2021.
[56] C. Qin, Y. Zhang, Y. Liu, and G. Lv, “Semantic loop closure detection based on graph matching in multi-objects scenes,” Journal of Visual Communication and Image Representation, vol. 76, p. 103072, 2021.
[57] Z. Zhang and D. Scaramuzza, “Beyond point clouds: Fisher information field for active visual localization,” in Proceedings of 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 5986–5992.
[58] Z. Zeng, A. Rofer, and O. C. Jenkins, “Semantic linking maps for active visual object search,” in Proceedings of 2020 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2020, pp. 1984–1990.
[59] B. Charrow, G. Kahn, S. Patil, S. Liu, K. Goldberg, P. Abbeel, N. Michael, and V. Kumar, “Information-theoretic planning with trajectory optimization for dense 3d mapping.” in Proceedings of Robotics: Science and Systems, vol. 11. Rome, 2015, pp. 3–12.
[60] C. Wang, D. Zhu, T. Li, M. Q. . Meng, and C. W. de Silva, “Efficient autonomous robotic exploration with semantic road map in indoor environments,” IEEE Robotics and Automation Letters, vol. 4, no. 3, pp. 2989–2996, July 2019.
[61] S. Kriegel, C. Rink, T. Bodenmuller, and M. Suppa, “Efficient next-best-scan planning for autonomous 3d surface reconstruction of unknown objects,” Journal of Real-Time Image Processing, vol. 10, no. 4, pp. 611–631, 2015.
[62] K. Wada, E. Sucar, S. James, D. Lenton, and A. J. Davison, “Morefusion: Multi-object reasoning for 6d pose estimation from volumetric fusion,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 14 540–14 549.
[63] D. Almeida, E. Ataer-Cansizoglu, and R. Corcodel, “Detection, tracking and 3d modeling of objects with sparse rgb-d slam and interactive perception,” in Proceedings of 2019 IEEE-RAS 19th International Conference on Humanoid Robots (Humanoids). IEEE, 2019, pp. 1–8.
[64] J. Redmon and A. Farhadi, “Yolov3: An incremental improvement,” arXiv preprint arXiv:1804.02767, 2018.
[65] F. Wilcoxon, “Individual comparisons by ranking methods,” in Break throughs in statistics. Springer, 1992, pp. 196–202.
[66] S. Sidney, “Nonparametric statistics for the behavioral sciences,” The Journal of Nervous and Mental Disease, vol. 125, no. 3, p. 497, 1957.
[67] E. L. Lehmann and H. J. D’Abrera, Nonparametrics: statistical methods based on ranks. Holden-day, 1975.
[68] S. Yang and S. Scherer, “Monocular object and plane slam in structured environments,” IEEE Robotics and Automation Letters, vol. 4, no. 4, pp. 3145–3152, 2019.
[69] T. Pire, J. Corti, and G. Grinblat, “Online object detection and localization on stereo visual slam system,” Journal of Intelligent & Robotic Systems, vol. 98, no. 2, pp. 377–386, 2020.
[70] F. T. Liu, K. M. Ting, and Z.-H. Zhou, “Isolation-based anomaly detection,” ACM Transactions on Knowledge Discovery from Data (TKDD), vol. 6, no. 1, pp. 1–39, 2012.
[71] R. G. Von Gioi, J. Jakubowicz, J.-M. Morel, and G. Randall, “Lsd: A line segment detector,” Image Processing On Line, vol. 2, pp. 35–55, 2012.
[72] S. A. Cook, “The complexity of theorem-proving procedures,” in Proceedings of the third annual ACM symposium on Theory of computing, 1971, pp. 151–158.
[73] G. Kahn, P. Sujan, S. Patil, S. Bopardikar, J. Ryde, K. Goldberg, and P. Abbeel, “Active exploration using trajectory optimization for robotic grasping in the presence of occlusions,” in Proceedings of 2015 IEEE International Conference on Robotics and Automation (ICRA). IEEE,
2015, pp. 4783–4790.
[74] E. Arruda, J. Wyatt, and M. Kopicki, “Active vision for dexterous grasping of novel objects,” in Proceedings of 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2016, pp. 2881–2888.
[75] A. Elfes, “Using occupancy grids for mobile robot perception and navigation,” Computer, vol. 22, no. 6, pp. 46–57, 1989.
[76] C. E. Shannon, “A mathematical theory of communication,” The Bell system technical journal, vol. 27, no. 3, pp. 379–423, 1948.
[77] J. Sturm, N. Engelhard, F. Endres, W. Burgard, and D. Cremers, “A benchmark for the evaluation of rgb-d slam systems,” in Proceedings of 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems. IEEE, 2012, pp. 573–580.
[78] A. Iqbal and N. R. Gans, “Data association and localization of classified objects in visual slam,” Journal of Intelligent & Robotic Systems, vol. 100, pp. 113–130, 2020.
[79] J. Shotton, B. Glocker, C. Zach, S. Izadi, A. Criminisi, and A. Fitzgibbon, “Scene coordinate regression forests for camera relocalization in rgb-d images,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2013, pp. 2930–2937.
[80] K. Lai, L. Bo, and D. Fox, “Unsupervised feature learning for 3d scene labeling,” in Proceedings of 2014 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2014, pp. 3050–3057.
[81] S. He, X. Qin, Z. Zhang, and M. Jagersand, “Incremental 3d line segment extraction from semi-dense slam,” in Proceedings of 2018 24th International Conference on Pattern Recognition (ICPR). IEEE, 2018, pp. 1658–1663.
[82] C. Campos, R. Elvira, J. J. G. Rodr´ıguez, J. M. Montiel, and J. D. Tardos, “Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam,” IEEE Transactions on Robotics, vol. 37, no. 6, pp. 1874–1890, 2021.
[83] F. Xiang, Y. Qin, K. Mo, Y. Xia, H. Zhu, F. Liu, M. Liu, H. Jiang, Y. Yuan, H. Wang et al., “Sapien: A simulated part-based interactive environment,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11 097–11 107.
[84] D. Morrison, P. Corke, and J. Leitner, “Multi-view picking: Next-best view reaching for improved grasping in clutter,” in Proceedings of 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 8762–8768.
[85] D. Kaljaca, B. Vroegindeweij, and E. van Henten, “Coverage trajectory planning for a bush trimming robot arm,” Journal of Field Robotics, vol. 37, no. 2, pp. 283–308, 2020.
[86] C. Wang, D. Xu, Y. Zhu, R. Mart´ın-Mart´ın, C. Lu, L. Fei-Fei, and S. Savarese, “Densefusion: 6d object pose estimation by iterative dense fusion,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 3343–3352.
[87] Z. Liu, Z. Zhang, Y. Cao, H. Hu, and X. Tong, “Group-free 3d object detection via transformers,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 2949–2958.
[88] H. Wang, S. Sridhar, J. Huang, J. Valentin, S. Song, and L. J. Guibas, “Normalized object coordinate space for category-level 6d object pose and size estimation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 2642–2651.
[89] S.-C. Wu, J. Wald, K. Tateno, N. Navab, and F. Tombari, “Scenegraph-fusion: Incremental 3d scene graph prediction from rgb-d sequences,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 7515–7525.
[90] Y. Wang, X. Chen, L. Cao, W. Huang, F. Sun, and Y. Wang, “Multimodal token fusion for vision transformers,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12 186–12 195.
[91] H. Yang, C. Shi, Y. Chen, and L. Wang, “Boosting 3d object detection via object-focused image fusion,” arXiv preprint arXiv:2207.10589, 2022.
[92] M. Quigley, K. Conley, B. Gerkey, J. Faust, T. Foote, J. Leibs, R. Wheeler, A. Y. Ng et al., “Ros: an open-source robot operating system,” in Proceedings of ICRA workshop on open source software. Kobe, Japan, 2009.