目标检测two-stage系列发展
目标检测two-stage系列发展
- two-stage目标检测发展
-
- 1.模型发展
- 2.模型介绍
-
- 2.1 RCNN
-
- 2.1.1 流程:
- 2.1.2 创新
- 2.1.3 不足
- 2.2 SPP-Net(Spatial Pyramid Pooling)
-
- 2.2.1 流程:
- 2.2.2 创新:
- 2.2.4 备注
- 2.3 Fast-RCNN
-
- 2.3.1 流程:
- 2.3.2 创新:
- 2.3.3 不足
- 2.4 Faster-RCNN
-
- 2.4.1 流程:
- 2.4.2 创新:
- 2.4.3 不足
- 2.5 R-FCN(Region-based Fully Convolutional Networks)
-
- 2.5.1 流程:
- 2.5.2 创新:
- 2.5.3 FCN详解
- 2.5.4 参考链接
- 2.6 FPN
-
- 2.6.1 流程:
- 2.6.2 创新:
- 2.6.3 备注
- 2.6.4 链接
- 2.7 Mask-RCNN
-
- 2.7.1 流程:
- 2.7.2 创新:
- 2.7.3 备注:
- 2.7.4 链接
- 2.8 Cascade-RCNN
-
- 2.8.1 流程:
- 2.8.2 创新:
- 2.8.3 备注
- 3.总结
- 相关链接:
two-stage目标检测发展
1.模型发展
RCNN(2013)->SPP-Net(ECCV14)->Fast-RCNN(ICCV15)->Faster-RCNN(NIPS15)->R-FCN(NIPS16)->FPN(CVPR17)->Mask-RCNN(ICCV17)->Cascade-RCNN(CVPR18)
2.模型介绍
2.1 RCNN
2.1.1 流程:
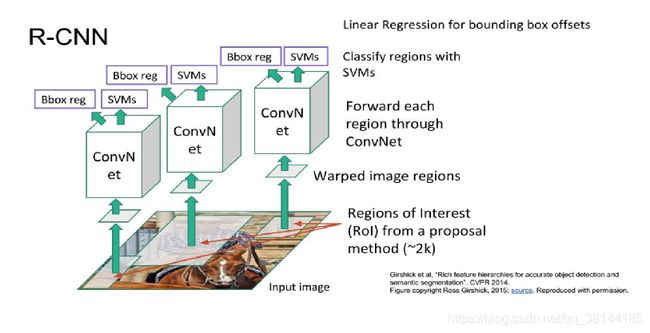
- 输入图片
- 用selective search从下到上搜索2000个候选区域(Regions of Interest【ROI】 from a proposal method)。获取候选窗口的方式是通过纹理,边缘,颜色等信息,候选框之间可以相互重叠,相互包含。
- 由于选区的区域大小各不相同,需要将每个候选框缩放成统一的大小(227x227)
- 将缩放后的块放到CNN中提取特征。
- 将提取的特征放入SVM中分类。
- 使用回归模型修正候选框的位置。
对每一个类训练一个线性回归模型,判定候选框是否完美,如果不够完美,用线性回归模型修正。
2.1.2 创新
其创新在于首次将CNN用于目标检测,以CNN提取到的深度特征代替传统HOG,SIFT等特征,极大提升了目标检测性能。其中提取特征的CNN先在imgnet上预训练,再在检测数据上finetune。
2.1.3 不足
训练速度慢:
对原始图片搜索的候选框多达2000个,每个候选框都要通过CNN进行特征提取。然后再由SVM分类。计算量非常大。
2.2 SPP-Net(Spatial Pyramid Pooling)
2.2.1 流程:
- 输入图片
- 搜索2000个候选区域(Regions of Interest【ROI】 from a proposal method)。
- 将整个图片放入CNN中提取特征,得到feature maps
- 在feature maps上找到各个候选框的区域,将这些区域通过金字塔空间池化,得到固定长度的特征向量。
- 将提取的特征放入SVM中分类。
- 使用回归模型修正候选框的位置。
对每一个类训练一个线性回归模型,判定候选框是否完美,如果不够完美,用线性回归模型修正。
2.2.2 创新:
- 对整个图片进行一次CNN操作,提取特征,相比R-CNN对2000个区域进行CNN提取特征的操作,要快很多
- 使用金字塔空间池化操作,得到最后的特征向量,不需要对每个候选框进行缩放操作,提升了精度和速度。
2.2.4 备注
先来回顾下R-CNN中的几个操作。
一个是通过selective search获取了2000个proposal区域后,由于每个区域通过纹理,边缘,颜色等信息获取,所以候选框大小不一。需要统一缩放。缩放在一定程度上导致图片信息的丢失和变形,限制了识别精确度。
为什么需要将图片统一到相同的像素呢?
卷积层的参数和输入大小无关,它仅仅是一个卷积核在图像上滑动,不管输入图像多大都没关系,只是对不同大小的图片卷积出不同大小的特征图。
但是全连接层的参数就和输入图像大小有关,因为它要把输入的所有像素点连接起来,需要指定输入层神经元个数和输出层神经元个数,所以需要规定输入的feature的大小。
因此,固定长度的约束仅限于全连接层。以下图为例说明:
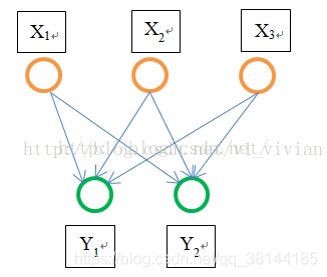
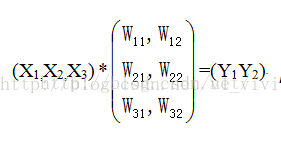
作为全连接层,如果输入的x维数不等,那么参数w肯定也会不同,因此,全连接层是必须确定输入,输出个数的。
SPP-Net的做法,是使用金字塔池化的方法来实现的。
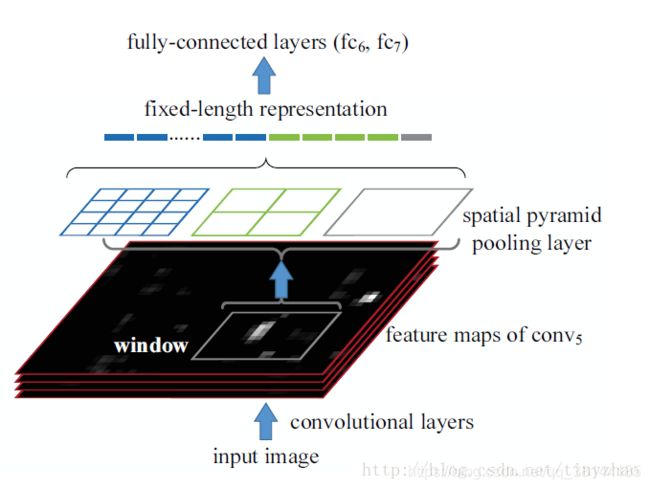
如上图所示,某个候选框,在特征图上的区域如图中window所示。将次区域划分为4x4,2x2,1x1三部分。然后通过最大值池化或者均值池化,得到(4x4+2x2+1x1)=21个特征值。从而实现无论输入的图片像素如何,最终都得到相同长度特征值的结果。
2.3 Fast-RCNN
2.3.1 流程:
- Selective Search生成region proposals
- 整个图像输入CNN生成特征图
- region proposals映射到特征图上,获取对应的ROI windows(step2,step3其实是同时完成的)
- ROI windows所表示的特征图区域输入到作者设计的ROI pooling layer,所有ROI 特征均转化为固定大小的特征图。
(ROI Pooling layer和Spatial Pyramid Pooling类似,只是ROI Pooling只将特征图分成一个7x7的区域,并在每个区域进行最大值池化,获得7x7=49的特征向量) - 特征图经过一系列FCs转换为特征向量
- 特征向量同时输入到两个分支,一个分支为softmax用于分类,一个分支为回归层输出4维向量表示回归的bbox与原始proposal的offset
2.3.2 创新:
- 相较于R-CNN,添加了ROI Pooling层,相较于SPP-Net,修改SPP-Net的SPP层为ROI Pooling层。
- 不再使用SVM,而使用sofmax进行分类。使得selective search生成候选框之后的所有步骤,都是端到端训练。并且不需要额外的空间来存储中间特征。
- 最后采用多任务损失函数。边框回归也假如CNN网络训练中,使分类和bbox回归可以同时优化。
损失函数的定义是将分类的loss和回归的loss整合在一起,其中分类采用log loss,即对真实分类(下图中的pu)的概率取负log,而回归的loss和R-CNN基本一样。分类层输出K+1维,表示K个类和1个背景类。
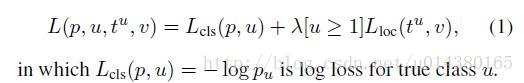

这是回归的loss,其中t^u表示预测的结果,u表示类别。v表示真实的结果,即bounding box regression target
bbox回归为什么要用smooth L1 Loss.
2.3.3 不足
仍然使用selective search获取2000个候选框,这个步骤也很耗时,如何快速找出候选框,是优化的一个方向。
2.4 Faster-RCNN
2.4.1 流程:
- 图像输入到CNN backbone中得到特征图
- 将特征图和预设的anchor输入到RPN中得到2000个region proposals。
RPN的具体流程:
2.1. 对于特征图(40×60)设定anchor,一共20000个(40×60×9)
2.2. 根据回归分支的预测结果(4×20000),对20000个anchor进行校正
2.3.裁剪超边界anchor,删掉w或者h太小的anchor
2.4.根据分类预测结果(2×20000),按照前景score进行由大到小排序,保留前12000个anchor
2.5.使用阈值0.7的NMS去重
2.6.剩下的anchor保留前2000个,即为RPN最终输出的proposals - 之后的步骤和Fast-RCNN一样
- region proposals和特征图输入到ROI pooling layer中,所有proposal获得固定尺寸的特征图。
- 固定尺寸的特征图经过一些列FC得到特征向量,再同时通过两个分支进行分类和回归。

Faster R-CNN流程示意图
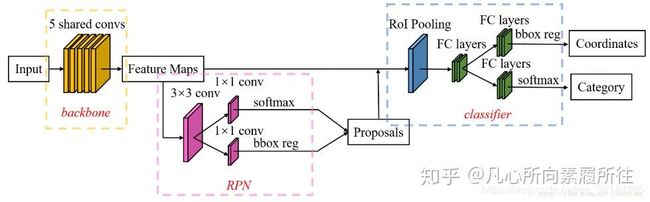
Faster R-CNN框架示意图

RPN示意图
RPN网络特点:
RPN网络是Faster-RCNN的核心创新,有必须要说明一下其特点
a:全卷积网络(用3×3卷积提取特征,用两个分支的1×1卷积代替全连接)
b:先单独训练(只区分anchor是前景/背景2分类+回归修正anchor),再和整个Fast-RCNN检测网络一起finetune
c:和检测网络共享特征图
d:训练RPN时控制正负样本比例
2.4.2 创新:
- 不再需要selective search,提出RPN网络来生成region proposals(也同时提出了anchor的概念),至此整个算法才真正算是“基于深度学习的目标检测算法”
- RPN网络和检测网络共享卷积特征,大大减少了proposal生成代价。
- 整个目标检测流程可以端到端训练。
2.4.3 不足
2.5 R-FCN(Region-based Fully Convolutional Networks)
2.5.1 流程:
- 使用ResNet101的前100层卷积+一层自己的卷积(1024个1×1卷积核),构成backbone,生成1024通道的卷积特征图。
- 对卷积特征图再卷积(k×k×(c+1)个卷积核),生成位置敏感的分数图position-sensitive socre maps(k×k×(c+1)通道),socre maps的每个通道表示1个位置(论文里k=3,一共9个位置),有c类,外加1个背景类的(c+1)类别的分数图。
- 在step2的同时,将backbone生成的特征图输入到RPN网络进行卷积,生成region proposals。
- proposals和position-sensitive score maps一起输入到position-sensitive ROI pooling层中,对每个proposal都生成一个k×k的位置敏感的类别socre map(C+1@3×3),然后对该map进行投票(平均池化)得到长度为C+1的向量,输入到softmax里进行分类。
2.5.2 创新:
使用卷积生成position-sensitive socre maps,编码了目标的位置信息,使得所有的Rengion proposals可以共享全部的参数,极大提高了算法效率。
2.5.3 FCN详解
算法提出的背景:
在Faster R-CNN中,已经做到RPN网络和检测网络共享卷积特征。而在ROI Pooling之后的操作,需要再进行多层FC+softmax来进行分类。每个proposal的特征图都要进行多层FC,所以假设提取了128个RoI,那么就要使用FC layer进行128次的回归和分类,而且大家也都知道FC layer的计算量是非常大的,所以这部分的计算就拖慢了Faster R-CNN的检测速度。
而当时的图像分类网络(如VGG-Net, ResNet)都已经是全卷积网络了,所有的可训练参数对所有的输入图像都是共享的,效率很高。那为什么目标检测就不行呢?作者认为是因为图像分类任务是位置平移不变的,而目标检测任务是位置敏感的。
位置不敏感性(分类):简单来说,对于一个分类问题,我们强调的是其位移不变性,即一只小狗,不管它在图像中如何移动,变换,我们都希望网络可以准确的区分其类别,实验也证明,像Resnet-101和GoogLeNets这种深层的全卷积网络都具有这样的性质。
位置敏感性(检测):做目标检测时。当物体发生平移时,检测结果也应该随着物体的变化而变化,这就是平移可变性。但是当卷积网络变深后,输出的feature map就变小,所以在原图上的一些物体的偏移,在经过N层pooling后得到的小feature map上会感知不到,所以网络变深使得平移可变性变差。(比如平移后的窗口,经过N层Pooling后,平移前后窗口都在同一个特征点上,那么此时得到的结果是一样的,但是其实窗口发生了变化,并没有反映出来)
所以为了解决这个问题,首先想到的是将RoI pooling层往前移动,因为在浅层的feature map上进行RoI pooling更能提取一些位置比较精确的proposal,然后这些proposal再进行卷积就能给深层的conv来平移可变性。对于这个改进,作者也给出了试验结果来证明:RoI放在ResNet-101的conv5后,mAP是68.9%;RoI放到conv4和conv5之间的mAP是76.4%,所以证明RoI能够给深层网络带来平移可变性,同时平移可变性对于目标检测也相当重要。**但是实验结果也表明,在conv5之后放RoI还是没有很好的效果,因此需要其他的方法来使得网络对于位置比较敏感,因此就提出了position-sensitive score map来达到这个目的,使得网络变深的同时,准确率也能和Faster R-CNN相媲美。


上图就是R-FCN的网络结构图,其主要设计思想就是“位置敏感得分图position-sensitive score map”。现在就对着这张图来解释其设计思路。如果一个RoI含有一个类别c的物体,那么作者将该RoI划分为 kk个区域,分别表示该物体的各个部位,比如假设该RoI中含有人这个物体,k=3,那么就将“人”划分为了9个子区域,top-center区域毫无疑问应该是人的头部,而bottom-center应该是人的脚部(如下图例子中所示),而将RoI划分为 [3x3] 个区域是希望这个RoI在其中的每一个区域都应该含有该类别c的物体的各个部位,即如果是人,那么RoI的top-center区域就必须含有人的头部。而当这所有子区域都含有各自对应的该物体的相应部位后,那么分类器才会将该RoI判断为该类别。物体的各个部位和RoI的这些子区域是“一一映射”的对应关系。


好了,现在我们知道了一个RoI必须是kk个子区域都含有该物体的相应部位,才能判断该RoI属于该物体,如果该物体的很多部位都没有出现在相应的子区域中,那么就判断该RoI为背景类别。那么现在的问题就是“网络如何判断一个RoI的k*k个子区域都含有相应部位呢?”前面我们是假设知道每个子区域是否含有物体的相应部位,那么我们就能判断该RoI是否属于该物体还是属于背景。那么现在的任务就是“判断RoI子区域是否含有物体的相应部位”。
这就是position-sensitive score map设计的核心思想了。R-FCN会在共享卷积层的最后再接上一层卷积层,而该卷积层就是“位置敏感得分图position-sensitive score map”,该score map是什么意义呢?首先它就是一层卷积层,它的height和width和共享卷积层的一样,但是它的channels=kk(c+1),如上图所示。那么C表示物体类别种数再加上1个背景类别,每个类别都有kk个score maps。现在我们先只针对其中的一个类别来讨论,假设是人这个类别,那么其有kk个score maps,每一个score map表示“原图image中的哪些位置含有人的某个一个部位”,而该score map会在含有“该score map对应的人体的某个部位”的位置有“高响应值”,也就是说每一个score map都是用来“描述人体的其中一个部位出现在该score map的何处,而在出现的地方就有高响应值”。那么好了既然是这样,那么我们只要将RoI的各个子区域对应到“属于人的每一个score map”上然后获取它的响应值不就好了。对,就是这样。但是要注意,由于一各score map都是只属于“一个类别的一个部位”的,所以RoI的第 i 个子区域一定要到第 i张score map上去找对应区域的响应值,因为RoI的第i 的子区域需要的部位和第i张score map关注的部位是一样的,所以就是这样的对应关系。那么现在该RoI的kxk个子区域都已经分别到“属于人的k*k个score maps”上找到其响应值了,那么如果这些响应值都很高,那么就证明该RoI是人呀~对吧。不过,当然这有点不严谨,因为我们只是在“属于人的kxk个score maps”上找响应值,我们还没有到属于其它类别的score maps上找响应值呢,万一该RoI的各个子区域在属于其它类别的上的score maps的响应值也很高,那么该RoI就也有可能属于其它类别呢?是吧,万一2个类别的物体本身就长的很像呢?所以呢,当然就是看那个类别的响应值更高了。
ResNet卷积层
在R-FCN中采用的是ResNet-101的网络结构,ResNet-101主要包括5个conv块,其中包括100个的conv layer和1个FC layer,在文中去掉了最后一层FC layer,只使用了前5个conv块,共100层卷积。

2.5.4 参考链接
链接:
https://blog.csdn.net/qq_34063988/article/details/102894655.
链接:
https://arxiv.org/abs/1605.06409.
链接:
https://zhuanlan.zhihu.com/p/52512760.
链接:
https://zhuanlan.zhihu.com/p/30867916.
2.6 FPN
2.6.1 流程:
作者在文中将FPN用于Fast-RCNN和Faster-RCNN检测框架中,因为我在这里以Faster-RCNN为例说明使用FPN的流程。
- 图像输入CNN提取特征的down-top过程。
- 使用FPN的横向连接和top-down构建多尺度特征。
- 对于每个尺度的特征图,分别使用RPN生成proposals,再分别输入到ROI pooling层得到固定大小特征图,进行后续的FCs和分类。
2.6.2 创新:
基于CNN本身的down-top path,提出特征金字塔网络FPN,利用横向连接和top-down path来提取、利用多尺度的更优特征,改进目标检测效果。
2.6.3 备注
以前的检测任务,在使用CNN提取特征时,都是使用最后一层提取到的特征。比如R-FCN,就是用conv5_x提取到的特征,进行后续的RPN以及其他操作。
利用单个高层特征,有一个明显的缺陷,即小物体本身具有的像素信息较少,在下采样的过程中极易被丢失,为了处理这种物体大小差异十分明显的检测问题,经典的方法是利用图像金字塔的方式进行多尺度变化增强,但这样会带来极大的计算量。所以这篇论文提出了特征金字塔的网络结构,能在增加极小的计算量的情况下,处理好物体检测中的多尺度变化问题。
也就是说,以前通过喂给CNN不同像素的图片(比如有个小物体,多次pooling后检测不到,可以将图片放大后,喂给CNN,这样放大的图片小物体也变大,对位置也相对敏感),得到不同像素通过CNN处理后的高层特征。变为了现在,只喂给CNN一个图片。而将底层特征保留下来,也用在检测上。底层特征还没有进行那么多次的pooling,对位置还相对敏感。
(1). Bottom-up pathway
前馈Backbone的一部分,每一级往上用step=2的降采样。
输出size相同的网络部分叫一级(stage),选择每一级的最后一层特征图,作为Up-bottom pathway的对应相应层数,经过1 x 1卷积过后element add的参考。
例如,下图是fasterRCNN的网络结构,左列ResNet用每级最后一个Residual Block的输出,记为{C1,C2,C3,C4,C5}。
FPN用2~5级参与预测(因为第一级的语义还是太低了),{C2,C3,C4,C5}表示conv2,conv3,conv4和conv5的输出层(最后一个残差block层)作为FPN的特征,分别对应于输入图片的下采样倍数为{4,8,16,32}。

(2). Top-down pathway and lateral connections
自顶向下的过程通过上采样(up-sampling)的方式将顶层的小特征图。放大到上一个stage的特征图一样的大小。
上采样的方法是最近邻插值法:

使用最近邻值插值法,可以在上采样的过程中最大程度地保留特征图的语义信息(有利于分类),从而与bottom-up 过程中相应的具有丰富的空间信息(高分辨率,有利于定位)的特征图进行融合,从而得到既有良好的空间信息又有较强烈的语义信息的特征图。

具体过程为:C5层先经过1 x 1卷积,改变特征图的通道数(文章中设置d=256,与Faster R-CNN中RPN层的维数相同便于分类与回归)。M5通过上采样,再加上(特征图中每一个相同位置元素直接相加)C4经过1 x 1卷积后的特征图,得到M4。这个过程再做两次,分别得到M3,M2。M层特征图再经过3 x 3卷积(减轻最近邻近插值带来的混叠影响,周围的数都相同),得到最终的P2,P3,P4,P5层特征。
另外,和传统的图像金字塔方式一样,所有M层的通道数都设计成一样的,本文都用d=256。
FPN应用于RPN层
Faster RCNN中的RPN是通过最后一层的特征来做的。最后一层的特征经过3x3卷积,得到256个channel的卷积层,再分别经过两个1x1卷积得到类别得分和边框回归结果。这里将特征层之后的RPN子网络称之为网络头部(network head)。对于特征层上的每一个点,作者用anchor的方式预设了9个框。这些框本身包含不同的尺度和不同的长款比例。
FPN针对RPN的改进是将网络头部应用到每一个P层。由于每个P层相对于原始图片具有不同的尺度信息,因此作者将原始RPN中的尺度信息分离,让每个P层只处理单一的尺度信息。具体的,对{322、642、1282、2562、512^2}这五种尺度的anchor,分别对应到{P2、P3、P4、P5、P6}这五个特征层上。每个特征层都处理1:1、1:2、2:1三种长宽比例的候选框。P6是专门为了RPN网络而设计的,用来处理512大小的候选框。它由P5经过下采样得到。
另外,上述5个网络头部的参数是共享的。作者通过实验发现,网络头部参数共享和不共享两种设置得到的结果几乎没有差别。这说明不同层级之间的特征有相似的语义层次。这和特征金字塔网络的原理一致。
2.6.4 链接
链接:
https://zhuanlan.zhihu.com/p/92005927.
2.7 Mask-RCNN
2.7.1 流程:
step1:图像输入backbone生成卷积特征图 。
step2:卷积特征图和预设的anchor输入到RPN网络,输出2000个候选框region proposals
step3:proposals和卷积特征图输入到ROI Align层,每个proposal得到对应的相同大小的特征图 。
step4:每个proposal的特征图输入到FC层并分为两个分支,一个用于softmax分类,一个用于边框offset回归 。
step5:与step4同时,proposals的固定长度特征图输入到第三个分支,用于mask每个像素点的分类,该分支是一个Res-FPN网络。
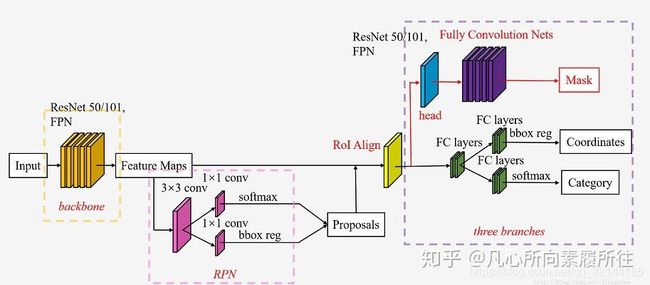
2.7.2 创新:
a:检测、分割多任务集成。
b:使用ROI Align代替之前的ROI pooling,解决特征不对齐问题。
2.7.3 备注:
相对于原来的Faster_RCNN主干框架,它在网络的头上引入了另外一条FCN并行分支用来检测ROI的mask map信息。这样最终它的头部共有三条并行的分支分别用来处理ROI区域的类别识别、目标框位置回归及相应的mask map回归。
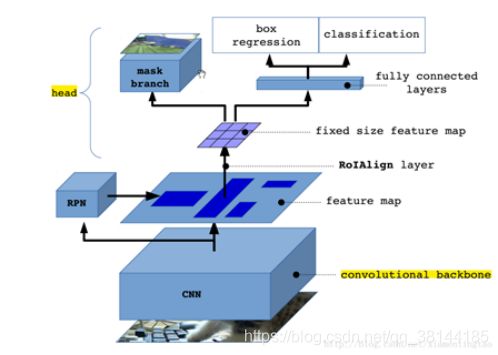
算法动机:
在当时(2017),大家趋向于研究集成的多任务网络模型。而Mask-RCNN就是在Faster-RCNN目标检测的基础上又集成了实例分割~ 但是在集成实例分割的时候,发现了Faster-RCNN目标检测中ROI pooling存在的问题:原图ROI与提取到的ROI特征不对齐问题,这个问题对目标检测任务影响不大,但是对于逐像素分类的mask任务来说影响就很大了。
(1)不对齐问题1:ROI pooling的第一步 根据原图ROI从特征图上获取对应的ROI feature的时候,进行了四舍五入round。(比如原图ROI尺寸为280×480,那么经过stride=16之后的特征图上ROIfeature的尺寸就是17.5×30,四舍五入成18×30)
(2)不对齐问题2:ROI pooling的第二步 将ROI feature转换为固定大小的特征图的时候,进行了取整操作。(比如ROIfeature尺寸为20×30,需要pooling成6×6大小的输出特征图,在w维度就需要平分6份分别量化取整)
ROIAlign理解:
原图ROI到feature map的ROI feature不进行四舍五入量化(这一步也不取特征图上的值,所以浮点数就浮点数);
ROI feature池化时使用双线性插值获取浮点数索引的元素值,更精确地找到其对应的特征值(反传的时候必须得要把梯度传播到整数值位置索引处,此时将梯度传播到所有与该浮点值距离<1的整数值处)。
ROIpooling

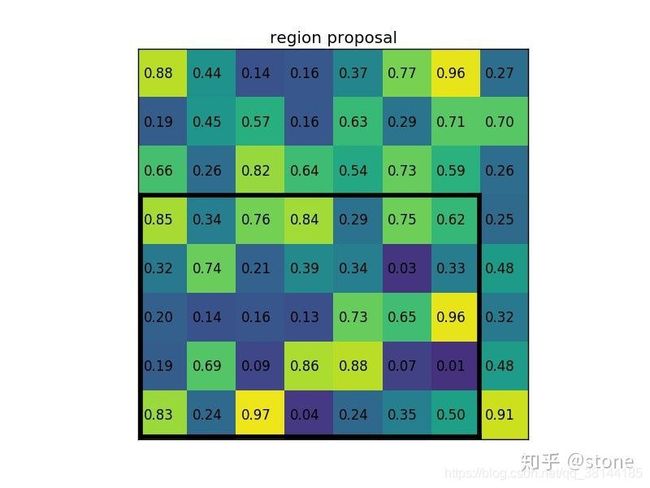

在实际划分时,roi中有一些特征点是被重复使用的,最终得到RoI Pooling结果应该是:

ROIAlign
双线性插值本质上就是在两个方向上做线性插值。
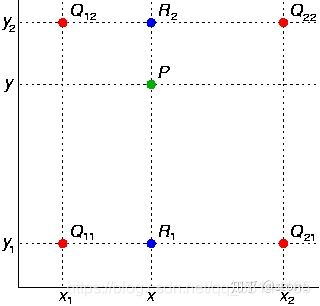
首先在 x 方向进行线性插值,得到

然后在 y 方向进行线性插值,得到
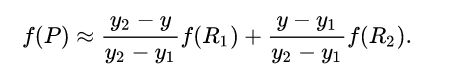
这样就得到所要的结果
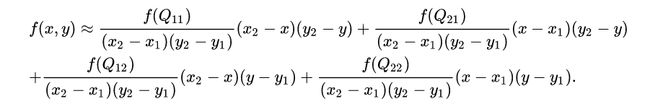

坐标值服从(x1,y1,x2,y2)。这里有一点需要注意的是(0,0,0,0)代表图像由一个像素点组成。
整个图的bbox是(0,0,3,2),RoI的bbox是(0.5,0,2.5,2)。
这里每个bin的输出值采用4个采样点通过avg或者max得到。
如上图对于(0.75, 0.25)这个采样点的特征值由(0,0),(0,1),(1,0),(1,1)四个点做双线性插值得到:
F(0.75, 0.25)=0.250.75F(0,0)+0.250.25F(0,1)+0.750.75F(1,0)+0.750.25F(1,1)
每个bin的采样点集做avg或者max得到每个bin的特征值。
②mask掩码分类
在ROI 对齐操作中mask分支对齐成14*14大小的feature map,并且在‘生成RCNN网络数据集’操作中知道每个正样本mask掩码区域对应的class_id
i) 前向传播:将1414大小feature map通过反卷积变换为[2828*num_class],即每个类别对应一个mask区域,称之为预测mask
ii) 与‘生成RCNN网络数据集’操作中的返回的mask也是28*28,并且知道每个mask区域的真实类别class_id,称之为真实mask
iii) 通过当前得到的真实mask中的类别class_id,遍历所有的预测mask,找到class_id类别所对应的预测mask(前向传播中介绍过每个类别都有一个预测mask),比较真实mask与预测mask每个像素点信息,用的是binary_cross_entropy二分类交叉熵损失函数
iv) binary_cross_entropy是二分类的交叉熵,实际是多分类softmax_cross_entropy的一种特殊情况,当多分类中,类别只有两类时,即0或者1,因为28*28大小的mask中只有0和1,即是像素和不是像素
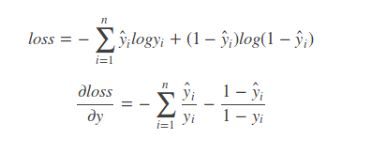
这个是针对概率之间的损失函数,你会发现只有(预测概率)和(真实标签)是相等时,loss才为0,否则loss就是为一个正数。而且,概率相差越大,loss就越大,根据Loss值更改权重实现反向传播
2.7.4 链接
链接:
https://www.cnblogs.com/wangyong/p/10614898.html.
链接:
https://zhuanlan.zhihu.com/p/37998710.
链接:
https://zhuanlan.zhihu.com/p/73662410.
链接:
https://zhuanlan.zhihu.com/p/66151355.
2.8 Cascade-RCNN
2.8.1 流程:

2.8.2 创新:
设计多个级联的R-CNN网络,设置逐级提高的IOU阈值来训练各级检测器,有效提升基于region proposals的two-stage检测器性能。
2.8.3 备注
算法动机:
在基于anchor的目标检测算法中(R-CNN系列),训练时会根据一定的IOU阈值对RPN输出的proposals进行正负样本的划分并采样合适数量的proposals用于后续训练;在Inference时RPN输出的所有proposals都会被认为是正样本,然后根据不同的IOU阈值计算AP。
a:作者认为训练时的正样本和Inference时正样本的分布是不同的,因为训练时的样本经过IOU阈值判定并采样,质量更高,这导致了训练和Inference的mismatch问题(Inference时不同质量proposal的回归效果不同)。
b:训练时IOU>0.5作为正样本,阈值取0.5是最好的吗?作者实验发现该阈值越高,网络对质量越高的proposal的回归效果越好;同时不论阈值取多少,网络对输入的proposal都有校正作用,输出的结果都比原proposal质量更高,IOU更大。
c:如果单纯地直接提高IOU阈值来使用高质量的proposal来训练R-CNN,效果会下降,因为RPN输出的proposal中高质量的很少(容易过拟合)。
如果是单个R-CNN网络,0.5阈值确实是最佳的,但是能不能设计多个级联的R-CNN网络呢?
因此作者设计级联的R-CNN网络,每一级网络训练时的IOU阈值越来越高,并将上一级网络回归输出的bbox作为当前级网络的proposals,使得每一级网络都有足够数量的对应质量的proposals样本。逐步提升网络输出的准确度。
3.总结
R-CNN首次将CNN用于目标检测,用CNN网络提取2000个候选框的特征,再做边框回归以及用SVM做分类.
SPP-Net只对全图做一次CNN卷积操作,用SPP层使不同尺度的proposals得到相同尺度的特征向量。
Fast-Rcnn用ROI层将不同尺度proposal得到相同尺度的特征向量。不使用SVM分类,而用softmax。多任务loss,分类和bbox回归可以同时优化。
Faster-Rcnn不再使用selective search而是通过RPN网络得到候选框。RPN网络和检测网络共享卷积特征。
R-FCN通过卷积生成position-sensitive score maps,编码了目标的位置信息,所有的region proposals可以共享参数。不再需要对每个候选框做回归,分类。
FPN使用不同层的特征信息,解决多尺度检测的问题。特别使提升检测小目标的能力。
Mask-RCNN
相关链接:
链接: https://zhuanlan.zhihu.com/p/100823629.
链接: https://blog.csdn.net/briblue/article/details/82012575.
链接: https://blog.csdn.net/v1_vivian/article/details/73275259.
链接: https://www.cnblogs.com/chaofn/p/9305374.html.
链接: https://blog.csdn.net/qq_34063988/article/details/102894655.