使用RNN联合注意力机制实现机器翻译
https://zhuanlan.zhihu.com/p/28834212
具体来自这一篇文章的指导
一、相关使用的查漏补缺:
1.其中的两种神奇的处理字符的操作:


2.关于nn.GRU()的参数解释和用法:
http://t.csdn.cn/30PZL
这篇文章讲得很清楚,需要用来预测的话看这篇也可以http://t.csdn.cn/VseAV
这里重点讲述以下它的参数的含义:

(1)输入参数:
(2)输出参数:

(3)用法示例:

3.关于nn.embedding的用法:
(1)就我看来,简单一点,就是将最里面的那个维度的数据由input_size->转化为 hidden_size,
然而并不是呢,看下面
(2)其他文章都没有chatGPT讲得清楚:




4.encoder 和attn_decoder的传参方式:

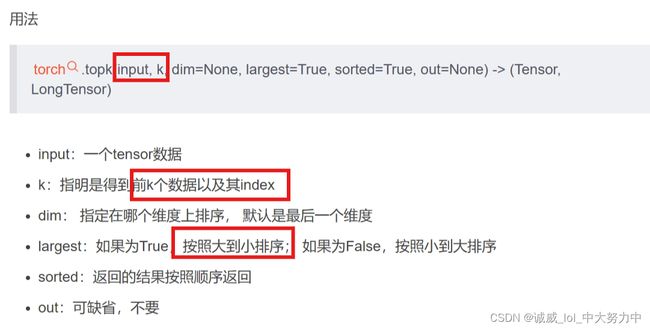
5.torch.data.topk()这个函数的作用:
听名字就知道这个函数是用来求tensor中某个dim的前k大或者前k小的值以及对应的index。
6.nn.nllloss 和 crossEntropyLoss的区别:


二、这是我在kaggle运行的第一个project:-_-
虽然kaggle一周只能用30个小时的GPU P100,但是,只要用的时候开,基本用不完,而且比那个Colab快多了,嘻嘻,重点是不会自动断掉,非常虚浮
1.关于Kaggle的使用经验:
(1)首先,登录之后,点击到code页面,添加新的notebook,就可以开始写代码了
(2)关于上传文件,我这一次是选择的从本地进行上传的方式,建议上传的时候关掉比较快,然后再打开,注意,最好选择拖动的方式,可以直接上传“整个文件夹”,并给整个文件放到一个文件夹目录,这个目录需要自己命名,注意,.ipynb文件没啥用
(3)特别经验,有时候文件路径老是很让人困惑,所以以下tips:
import os
print(os.path.exists('./kaggle/input/main-data/RNN_for_translate/data/eng-fra.txt'))如果文件存在,该命令会输出True;如果文件不存在,会输出False。
2.关于具体的代码和注释:
#引入相关的库内容:
from __future__ import unicode_literals, print_function, division
from io import open # 处理文件
import unicodedata # 处理unicode字符相关事项
import string
import re # 正则表达式相关
import random
import torch
import torch.nn as nn
from torch.autograd import Variable
from torch import optim
import torch.nn.functional as F
use_cuda = torch.cuda.is_available() # 如果您的计算机支持cuda,则优先在cuda下运行
print(use_cuda) #看来本王的笔记本并不支持cuda#下载数据并且对数据进行处理:
#把文本文件一次性读入内存
#对文本中出现的一些特殊字符进行适当处理
#分别建立“英语”、“法语”语料库(词向量),并对两库进行一定的修饰,剔除不常用的词、并剔除两库中使用不常用词的句子。
#提供后续程序需要的一些功能接口
#声明起始和结束占用符
SOS_token = 0
EOS_token = 1
#我们构建一个类Lang,来全权处理文本数据相关的操作:
class Lang: #这个注释挺详细的,而且这个部分的思想和c++的类设计很相似
def __init__(self, name): #初始化函数,传递一个name参数
self.name = name
self.word2index = {} # 单词对应的在字典里的索引号
self.word2count = {} # 记录某一个单词在语料库里出现的次数
self.index2word = {0: "SOS", 1: "EOS"} # 索引对应的单词
self.n_words = 2 # Count SOS and EOS # 语料库里拥有的单词数量
def addSentence(self, sentence): # 往语料库里增加一句话:扩充语料库 ,参数是这句话
for word in sentence.split(' '): # 要增加的一句话是以空格来分割不同的单词
self.addWord(word) # 把单词一个个加入语料库
def addWord(self, word): # 把单词加入到语料库中具体要做的事情
if word not in self.word2index: # 对于语料库中不存在的新词
self.word2index[word] = self.n_words # 索引号依据先来后到的次序分配
self.word2count[word] = 1 # 更新该次的出现次数
self.index2word[self.n_words] = word # 同时更新该字典
self.n_words += 1
else:
self.word2count[word] += 1 # 对于已存在于语料库中的词,仅增加其出现次数。#文中还提供了两个辅助方法,来将unicode字符转化为ascii字符,
#同时对英语、法语句子中存在一些大小写、缩写、连写、特殊字符等现象进行的规范化处理:
# Turn a Unicode string to plain ASCII, thanks to
# http://stackoverflow.com/a/518232/2809427
def unicodeToAscii(s):
return ''.join(
c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn'
)
# Lowercase, trim, and remove non-letter characters
def normalizeString(s):
s = unicodeToAscii(s.lower().strip())
s = re.sub(r"([.!?])", r" \1", s)
s = re.sub(r"[^a-zA-Z.!?]+", r" ", s)
return s#读取文件中的内容,形成一系列语句对,并构建两个Lang对象
def readLangs(lang1, lang2, reverse=False): # lang1,lang2仅是字符串,代表对应的语言
print("Reading lines...")
# Read the file and split into lines
lines = open('data/%s-%s.txt' % (lang1, lang2), encoding='utf-8').\
read().strip().split('\n')
# 把文本文件变为语句对列表
# Split every line into pairs and normalize ,这里的结果是,将英文 和 法文 分开成对pair,然后构建一个元素是pair的列表叫“pairs”
pairs = [[normalizeString(s) for s in l.split('\t')] for l in lines]
# 提供一个反向的操作,即原来是英文->法语,使用reverse后则为法语->英语
# Reverse pairs, make Lang instances
if reverse:
pairs = [list(reversed(p)) for p in pairs]
input_lang = Lang(lang2)
output_lang = Lang(lang1)
else:
input_lang = Lang(lang1)
output_lang = Lang(lang2)
return input_lang, output_lang, pairs #返回一个lang1和lang2对象,以及生成的语句对pairs#以下提供了一些辅助方法,用于从总的文本数据中筛选出感兴趣的数据来进行训练,
#读者可以根据自己的兴趣决定是否使用下面这两个方法:
MAX_LENGTH = 10
eng_prefixes = (
"i am ", "i m ",
"he is", "he s ",
"she is", "she s",
"you are", "you re ",
"we are", "we re ",
"they are", "they re "
)
#过滤pair的函数p[0] 和 p[1]的长度 都要 <10 , 且 p[1]????(我感觉是p[0])必须以上面这些英语句子开头 ,如果reverse了,就没问题
def filterPair(p): # 作者仅对训练数据中句子长度都小于10,且以一定字符串开头的英文句子感兴趣
return len(p[0].split(' ')) < MAX_LENGTH and len(p[1].split(' ')) < MAX_LENGTH and \
p[1].startswith(eng_prefixes)
def filterPairs(pairs): # 从所有pairs中选出作者感兴趣的pair
return [pair for pair in pairs if filterPair(pair)]
#开始准备数据:
def prepareData(lang1, lang2, reverse=False): #传递2个语言的string参数, 以及是否reverse
# 构建两个语料库
input_lang, output_lang, pairs = readLangs(lang1, lang2, reverse) #调用上述的readLangs得到 pairs数组
print("Read %s sentence pairs" % len(pairs)) #输出总共多少个pair对
pairs = filterPairs(pairs) # 筛选感兴趣的语句对
print("Trimmed to %s sentence pairs" % len(pairs)) #筛选之后 剩下的pair对数目
print("Counting words...") # 统计词频
for pair in pairs:
input_lang.addSentence(pair[0]) #pair[0]应该是输入的,也就是英文,添加到input_lang这个对象中,之后也处理了word
output_lang.addSentence(pair[1]) #感觉这样的话,句子和句子之间的关系就对不上了,,,???只是挨个将词放进去
print("Counted words:")
print(input_lang.name, input_lang.n_words) #输出input_lang 和 output_lang中的word数目
print(output_lang.name, output_lang.n_words)
return input_lang, output_lang, pairs #返回input_lang和 out_lang对象,以及这个pairs数组
input_lang, output_lang, pairs = prepareData('eng', 'fra', True) #创建lang1,lang2,pairs,原来是进行了reverse反转
print(random.choice(pairs)) #随机输出pairs中的一个pair对#定义RNN类型的 Encoder
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size, n_layers=1):
super(EncoderRNN, self).__init__()
self.n_layers = n_layers # 可以使用多层gru操作,默认只使用一层
self.hidden_size = hidden_size # 隐藏层的尺寸,如何设定参考后续代码
self.embedding = nn.Embedding(input_size, hidden_size) #input_size个词汇,每个词汇用hidden_size维度的向量表示
self.gru = nn.GRU(hidden_size, hidden_size) # 记忆结构
def forward(self, input, hidden):
embedded = self.embedding(input).view(1, 1, -1) #先将输入embedding到embedded。然后调整形状为3维的tensor -1*1*all
output = embedded #将embedded传给output
for i in range(self.n_layers):
output, hidden = self.gru(output, hidden) #通过n_layers层的gru,然后得到输出output 和 状态hidden
return output, hidden #参看那个博客的gru参数以及用法,你就明白了,
#参数embedded 1*1*all , hidden _就是那个h_0 1*1*hidden_size
#参数output 1*1*hidden_size , hidden 1*1*hidden_size
def initHidden(self):
result = Variable(torch.zeros(1, 1, self.hidden_size)) #就是得到上面的那个1*1*hidden_size -?上面没有调用?还是之后调用?下面有说
if use_cuda:
return result.cuda()
else:
return result#Decoder_version1 __普通版本的RNN_decoder_model
class DecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size, n_layers=1):
super(DecoderRNN, self).__init__()
self.n_layers = n_layers
self.hidden_size = hidden_size
self.embedding = nn.Embedding(output_size, hidden_size) #定义embedding函数,词汇表的大小output_size,每个词汇的向量长度hidden_size
self.gru = nn.GRU(hidden_size, hidden_size) #gru的input参数 和 h_0参数
self.out = nn.Linear(hidden_size, output_size) #从hidden_size维度 到 output_size维度的Linear层
# 由于输出是语料库中词语的概率,选最大概率的索引对应的词,
# 所以需要一个类softmax操作
self.softmax = nn.LogSoftmax() #由于是一个多分类问题,最后通过一次softmax(前面还有一个log操作)
def forward(self, input, hidden): #具体的Decoder运行过程
output = self.embedding(input).view(1, 1, -1) #还是将input转化为1*1*all的3维空间
for i in range(self.n_layers): #多少层捏
output = F.relu(output) #通过1个relu
output, hidden = self.gru(output, hidden) #再和h_0一起通过gru
output = self.softmax(self.out(output[0])) #最后对output的有用的那层数据进行Linear+softmax
return output, hidden #返回output 和 h_n
def initHidden(self): #我甚至怀疑这个函数是自动调用的了,产生了一个1*1*hidden_size作为h_0输入量
result = Variable(torch.zeros(1, 1, self.hidden_size))
if use_cuda:
return result.cuda()
else:
return result#加上self_attention版本的RNN_Decoder
class AttnDecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size, n_layers=1, dropout_p=0.1, max_length=MAX_LENGTH):
#对于解码器来说,最重要的两个参数是 隐藏状态的尺寸 和 输出的尺寸大小,这两者主要决定了解码器的参数规模
super(AttnDecoderRNN, self).__init__()
self.hidden_size = hidden_size #先把参数传进去
self.output_size = output_size
self.n_layers = n_layers
self.dropout_p = dropout_p
self.max_length = max_length # 还有一个句子最大长度参数
self.embedding = nn.Embedding(self.output_size, self.hidden_size) #设置embedding函数
self.attn = nn.Linear(self.hidden_size * 2, self.max_length) #设置attn这个linear函数
self.attn_combine = nn.Linear(self.hidden_size * 2, self.hidden_size)#设置attn_combine这个linear函数
self.dropout = nn.Dropout(self.dropout_p) #设置dropout函数
self.gru = nn.GRU(self.hidden_size, self.hidden_size) #设置gru函数
self.out = nn.Linear(self.hidden_size, self.output_size) #设置out输出linear函数
def forward(self, input, hidden, encoder_output, encoder_outputs):#整个Decoder运行过程
embedded = self.embedding(input).view(1, 1, -1) #进行embedding将词汇转换为向量序列后,准换为1*1*all的形状
embedded = self.dropout(embedded) #调用一次dropout
attn_weights = F.softmax(
self.attn(torch.cat((embedded[0], hidden[0]), 1))) #attn_weights得到的过程:通过embedded和h_n的cat后通过attn线性层+softmax
attn_applied = torch.bmm(attn_weights.unsqueeze(0),
encoder_outputs.unsqueeze(0)) #通过bmm对attn_weights 和 encoder_outputs这2批矩阵进行对应相乘
output = torch.cat((embedded[0], attn_applied[0]), 1) #将embedded和attn_applied相连
output = self.attn_combine(output).unsqueeze(0) #通过线性层
for i in range(self.n_layers):
output = F.relu(output)
output, hidden = self.gru(output, hidden) #通过n_layers次的relu和gru
output = F.log_softmax(self.out(output[0])) #通过log_softmax
return output, hidden, attn_weights #返回output 和 h_n 还有attn_weights
def initHidden(self): #自动生成h_0,嘻嘻
result = Variable(torch.zeros(1, 1, self.hidden_size))
if use_cuda:
return result.cuda()
else:
return result#数据准备部分:
def indexesFromSentence(lang, sentence): #这里应该是输入一个lang的句子,然后返回这个句子的index序列
return [lang.word2index[word] for word in sentence.split(' ')]
def variableFromSentence(lang, sentence):
indexes = indexesFromSentence(lang, sentence) #调用上面那个函数,获得这个句子的序列
indexes.append(EOS_token) #在这个句子的最后加上EOS_token(1还是0来着。。。)这个值
result = Variable(torch.LongTensor(indexes).view(-1, 1)) #将这个indexes序列转换为all*1维的数据
if use_cuda:
return result.cuda()
else:
return result
def variablesFromPair(pair): #输入pair对,一个句子 -vs- 一个句子的那种
input_variable = variableFromSentence(input_lang, pair[0])
target_variable = variableFromSentence(output_lang, pair[1])
return (input_variable, target_variable) #调用上面的那个函数,返回该种数据对#模型训练部分的代码- 阅读详细的注释:
teacher_forcing_ratio = 0.5 #解释见后
def train(input_variable, target_variable, encoder, decoder, encoder_optimizer, decoder_optimizer, criterion, max_length=MAX_LENGTH):
# 初始化编码器的隐藏层状态
encoder_hidden = encoder.initHidden() #果然,这个函数是用来初始化h_0的,嘻嘻
# 清除编码器、解码器的梯度数据,准备接受下一次的梯度数据
encoder_optimizer.zero_grad()
decoder_optimizer.zero_grad()
# 待翻译句子和已翻译句子的长度(即组成句子的词语的数量)
input_length = input_variable.size()[0]
target_length = target_variable.size()[0]
# 建立一个编码器输出的PyTorch变量,注意命名是-s结尾,表示
# 该变量保存了Encoder每一次中间状态数据,而不是最后一次中间状态。
encoder_outputs = Variable(torch.zeros(max_length, encoder.hidden_size))
# 如果使用cuda,则再包装一下
encoder_outputs = encoder_outputs.cuda() if use_cuda else encoder_outputs
loss = 0
# 编码器的编码过程
for ei in range(input_length):
encoder_output, encoder_hidden = encoder(
input_variable[ei], encoder_hidden)
encoder_outputs[ei] = encoder_output[0][0]
# 通过编码过程,得到了编码器的每一次中间状态数据
# 给解码器准备最初的输入,是一个开始占位符
decoder_input = Variable(torch.LongTensor([[SOS_token]]))
decoder_input = decoder_input.cuda() if use_cuda else decoder_input
# 解码器初始的输入就是编码器最后一次中间层状态数据
decoder_hidden = encoder_hidden
#终于明白下面的这个过程了,就是李宏毅上课讲到的,如果decoder中某个字符翻译错了,
#到底下一次是用 正确的作为token输入呢 还是将错就错用 这个错误的输出作为输入呢?
#下面是按照概率进行分2种进行的
# 该变量表明是否在每一次输出时都是用目标正确输出来计算损失
use_teacher_forcing = True if random.random() < teacher_forcing_ratio else False
if use_teacher_forcing:
# 条件为真时,使用正确的输出作为下一时刻解码器的输入来循环计算
# Teacher forcing: Feed the target as the next input
for di in range(target_length): #反正就是1个词的翻译,然后指导这个target这个label的长度 或者 输出得到EOS_token才退出decoder
# decoder解码器具体实施的过程,确定其输出、隐藏层状态、以及注意力数据
# decoder的forward方法会动态的确定decoder_attention数据
decoder_output, decoder_hidden, decoder_attention = decoder(
decoder_input, decoder_hidden, encoder_output, encoder_outputs)
# 更新损失
loss += criterion(decoder_output, target_variable[di])
# 确定下一时间步的解码器输入
decoder_input = target_variable[di] # Teacher forcing -这里就是用target作为下一次decoder的输入了
else:
# 条件不为真时,使用解码器自身预测的输出来作为下一时刻解码器的输入来循环计算
# Without teacher forcing: use its own predictions as the next input
for di in range(target_length):
decoder_output, decoder_hidden, decoder_attention = decoder(
decoder_input, decoder_hidden, encoder_output, encoder_outputs)
#这里肯定就是获取到最大的概率的那个 位置的索引值
topv, topi = decoder_output.data.topk(1) #获取前k个(前1)个元素的数值和位置索引
ni = topi[0][0] #得到这个位置索引就是预测的词汇
decoder_input = Variable(torch.LongTensor([[ni]])) #这里就是利用这次的预测 输出 作为下一次decoder的输入了
decoder_input = decoder_input.cuda() if use_cuda else decoder_input
loss += criterion(decoder_output, target_variable[di])
if ni == EOS_token: #如果ni就是 EOS_token值了,就可以直接退出了
break
# 反向传递损失
loss.backward()
# 更新整个网络模型的参数
encoder_optimizer.step()
decoder_optimizer.step()
# 该方法是训练过程,训练过程仅输出了训练的损失,并不提供翻译得到的句子,会有专门
# 的方法来实施翻译过程。
return loss.item() / target_length #返回训练中的平均loss数值#下面是2个用来计时的辅助函数:
import time
import math
def asMinutes(s): #将输入数值转换为 几分 几秒返回
m = math.floor(s / 60)
s -= m * 60
return '%dm %ds' % (m, s)
def timeSince(since, percent): #
now = time.time() #现在的时间
s = now - since #相对的时间
es = s / (percent) #。。。算了,先不管了,回头来看看
rs = es - s
return '%s (- %s)' % (asMinutes(s), asMinutes(rs))#这里才是正真的 train多次的 情况:
def trainIters(encoder, decoder, n_iters, print_every=1000, plot_every=100, learning_rate=0.01): #每隔1000print一次,每隔100话一次
start = time.time() #启动计时
plot_losses = [] #保存需要绘制的loss
print_loss_total = 0 #Reset every print_every 设置loss采样频率
plot_loss_total = 0 #Reset every plot_every
# 声明两个RNN的优化器
encoder_optimizer = optim.SGD(encoder.parameters(), lr=learning_rate)
decoder_optimizer = optim.SGD(decoder.parameters(), lr=learning_rate)
# 得到训练使用的数据
training_pairs = [variablesFromPair(random.choice(pairs))
for i in range(n_iters)] #获取pairs总共多少对,然后每一对拆分为2个数组-感觉training_pair[2][n_iters][-]
# 损失计算方法
criterion = nn.NLLLoss() #一个少了softmax、log的crossEntropy
# 循环训练,迭代的次数
for iter in range(1, n_iters + 1): #总共n_iters对句子 , 果然之前定义的那个train函数只能用在1个train循环种
training_pair = training_pairs[iter - 1] #获取输入句子的词汇数组 和 输出label的词汇数组
input_variable = training_pair[0]
target_variable = training_pair[1]
loss = train(input_variable, target_variable, encoder,
decoder, encoder_optimizer, decoder_optimizer, criterion) #对这一对句子input 和 label调用train得到loss
print_loss_total += loss #总print_loss+total加上
plot_loss_total += loss
#每隔1000输出一次平均loss
if iter % print_every == 0:
print_loss_avg = print_loss_total / print_every #计算这一轮(1000个句子对)的平均loss
print_loss_total = 0 #置零
print('%s (%d %d%%) %.4f' % (timeSince(start, iter / n_iters),
iter, iter / n_iters * 100, print_loss_avg)) #用来多少时间,计算了多少对,完成了百分之几,平均loss
#每个100输出一次平均loss
if iter % plot_every == 0:
plot_loss_avg = plot_loss_total / plot_every #计算平均loss
plot_losses.append(plot_loss_avg) #加到plot_loss_avg数组种,用于绘制 折线图
plot_loss_total = 0 #置零,等下一轮用
showPlot(plot_losses) #这个画图函数在下面会进行定义的import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
import numpy as np
def showPlot(points):
plt.figure()
fig, ax = plt.subplots()
# this locator puts ticks at regular intervals
loc = ticker.MultipleLocator(base=0.2)
ax.yaxis.set_major_locator(loc)
plt.plot(points) #反正就是绘制折线图,先不管了这里#evaluate 部分的代码:
def evaluate(encoder, decoder, sentence, max_length=MAX_LENGTH):
# 把sentence转化为网络可以接受的输入,同时初始化编码器的隐藏状态
input_variable = variableFromSentence(input_lang, sentence) #获取输入句子的词汇数组 ,
input_length = input_variable.size()[0]
encoder_hidden = encoder.initHidden()
# 准备编码器输出变量
encoder_outputs = Variable(torch.zeros(max_length, encoder.hidden_size)) #获取一个max_length*hidden_size的数组
encoder_outputs = encoder_outputs.cuda() if use_cuda else encoder_outputs
# 得到编码的输出
for ei in range(input_length): #???为什么,难道有多个是1个个词汇进行的encoder,what
encoder_output, encoder_hidden = encoder(input_variable[ei],
encoder_hidden)
encoder_outputs[ei] = encoder_outputs[ei] + encoder_output[0][0]
# 准备解码器输出的变量
decoder_input = Variable(torch.LongTensor([[SOS_token]])) # SOS
decoder_input = decoder_input.cuda() if use_cuda else decoder_input
# 编码器和解码器之间的桥梁:Context
decoder_hidden = encoder_hidden
# 准备一个列表来保存网络预测的词语
decoded_words = []
# 准备一个变量保存解码过程中产生的注意力数据
decoder_attentions = torch.zeros(max_length, max_length)
# 解码过程,有一个最大长度限制
for di in range(max_length):
decoder_output, decoder_hidden, decoder_attention = decoder(
decoder_input, decoder_hidden, encoder_output, encoder_outputs)
decoder_attentions[di] = decoder_attention.data
topv, topi = decoder_output.data.topk(1)
ni = topi[0][0]
if ni == EOS_token:
decoded_words.append('')
break
else:
decoded_words.append(output_lang.index2word[ni])
# 解码器的输出作为其输入 , 这里就不用 teacher forcing了
decoder_input = Variable(torch.LongTensor([[ni]]))
decoder_input = decoder_input.cuda() if use_cuda else decoder_input
# 返回预测的单词,以及注意力机制(供分析注意力机制)
return decoded_words, decoder_attentions[:di + 1] #观察其中某10个句子的预测情况
def evaluateRandomly(encoder, decoder, n=10):
for i in range(n):
pair = random.choice(pairs) #随机选1对句子
print('>', pair[0])
print('=', pair[1])
output_words, attentions = evaluate(encoder, decoder, pair[0]) #对pair进行evalute预测
output_sentence = ' '.join(output_words) #输出的翻译结果存到output_sentence,并输出
print('<', output_sentence)
print('') #下面的三行代码在之前介绍过
hidden_size = 256
encoder1 = EncoderRNN(input_lang.n_words, hidden_size)
attn_decoder1 = AttnDecoderRNN(hidden_size, output_lang.n_words,1, dropout_p=0.1)
# 支持cuda计算
if use_cuda:
encoder1 = encoder1.cuda()
attn_decoder1 = attn_decoder1.cuda()
# 核心的训练代码仅此一句
trainIters(encoder1, attn_decoder1, 75000, print_every=5000)
#自己笔记本的cpu上面根本跑不动,还是用kaggle试一试
#之前在这里发生错误的原因,就是他们老是使用 老版本的loss.data[0]这个已经不能用了,而应该改用loss.item()#查看随机翻译10个句子的结果
evaluateRandomly(encoder1, attn_decoder1)
#这里有点奇怪,明明应该用test_Data,不过它还是在用同一个train_data三、实验结果:
1.这就是在train上面的loss的变化结果了:(这个代码有值得后期继续改进的地方就是,整个data没有分出一部分来作为 validation,也没有利用validation进行翻译)
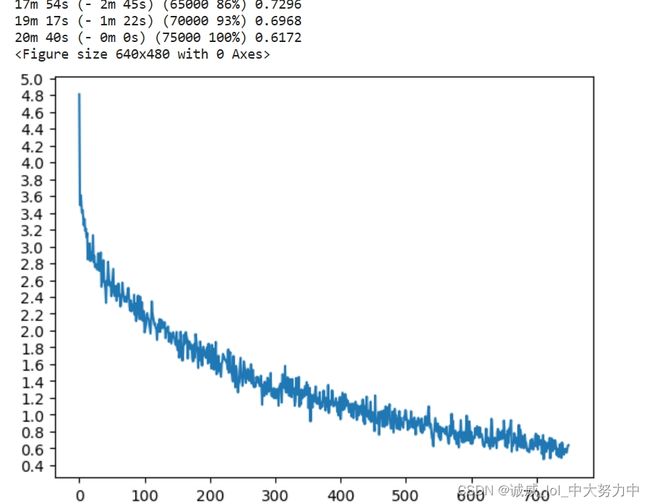
后期继续改进吧,。。。。。。