python-爬虫-urllib3
导入模块
import urllib3
urllib3:功能强大、条理清晰、用于HTTP客户端的python网络请求库
重要特征
1.线程安全
2.连接池
3.客户端SSL/TLS验证
4.使用分段编码长传文件
5.重试请求和处理HTTP复位的助手
6.支持gzip和deflate编码
7.HTTP和SOCKS的代理支持
8.100%的测试覆盖率
1.发起请求
导入模块
import urllib3
通过PoolManager实例生成请求,由该实例对象处理与线程池的连接及线程安全的所有细节,不需要任何人为操作
http = urllib3.PoolManager()
http # 通过request()创建请求,返回一个HTTP Response对象
r = http.request('GET','https://fanyi.baidu.com/')
r # 通过响应对象的data等方法可以获取响应结果,使用decode对返回的数据进行解码
r.data # 有乱码
r.data.decode('utf8') # 使用decode对返回的数据进行解码
import urllib3
http = urllib3.PoolManager()
r = http.request('GET','https://fanyi.baidu.com/')
r.data
r.data.decode('utf8')

request()可以通过参数控制请求的类型
传递POST参数值,该请求数据部分涵盖发送其他类型的请求的数据,包括JSON、文件和二进制数据
http = urllib3.PoolManager()
r = http.request(
'POST',
'http://httpbin.org/post',
fields={'hello':'world'}
)
r.data

得到的字符串结果前有子母b,b前缀表示一个字节序列(bytes)对象
字节序列是不可变的序列,由0或多个字节组成,每个字节都用0到255之间的整数表示
2.bytes对象常用方法
创建bytes对象
b = b'hello world'
转换为bytes对象
s = 'hello world'
b = s.encode()
b # b'hello world'
将bytes对象转换为字符串
b = b'hello world'
s = b.decode()
s # 'hello world'
访问字节
b[0]取出的是字节’h’的ASCII码,即104
b = b'hello world'
b[0] # 访问第一个字节,输出104
拼接字节
b1 = b'hello'
b2 = b'world'
b1 + b2 # b'helloworld'
字节与字符串的转换
b = b'hello world'
s = str(b, encoding='utf-8') # 'hello world' # 转换为字符串
b = bytes(s, encoding='utf-8') # b'hello world' # 转换为bytes
需要注意的是,在Python3中,字符串是默认以Unicode编码的,因此需要显式指定编码方式进行转换
3.响应内容
发起请求之后,会返回一个响应内容(包含status、data、header等属性)
http = urllib3.PoolManager()
r = http.request('get','http://httpbin.org/ip')
r.status # 200
r.data # b'{\n "origin": "117.136.56.194"\n}\n'
r.headers # HTTPHeaderDict({'Date': 'Tue, 12 Sep 2023 12:38:40 GMT', 'Content-Type': 'application/json', 'Content-Length': '33', 'Connection': 'keep-alive', 'Server': 'gunicorn/19.9.0', 'Access-Control-Allow-Origin': '*', 'Access-Control-Allow-Credentials': 'true'})
如果data返回的是json格式的字符串,可通过json库解码和反序列data请求的属性加载json内容
import urllib3
import json
http = urllib3.PoolManager()
r = http.request('get','http://httpbin.org/ip')
json.loads(r.data) # {'origin': '117.136.56.194'}
4.查询参数
对于GET、HEAD和DELETE请求,可以简单的传递参数作为一个字典fields参数
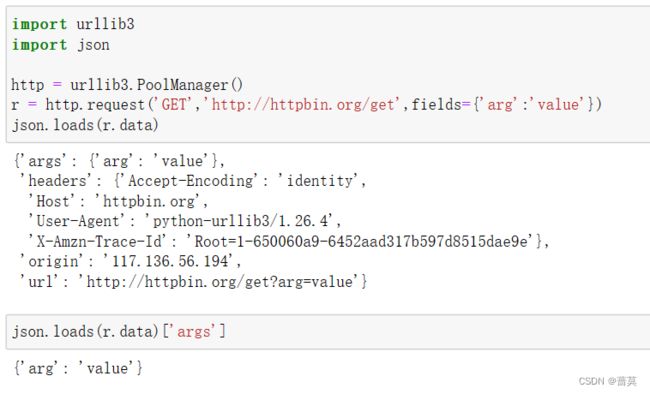
import urllib3
import json
http = urllib3.PoolManager()
r = http.request('GET','http://httpbin.org/get',fields={'arg':'value'})
json.loads(r.data)['args']
对POST和PUT请求,需要在URL中手动编码查询参数
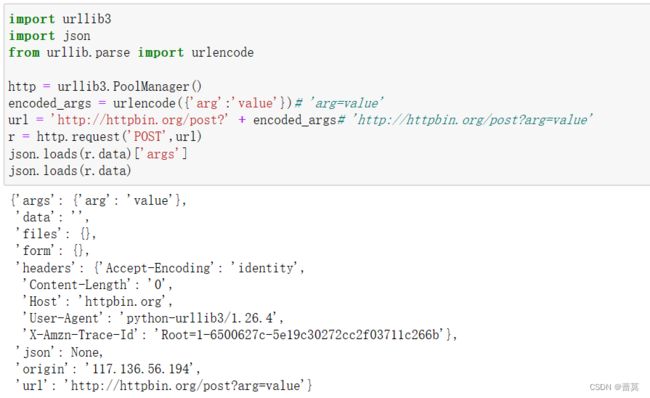
import urllib3
import json
from urllib.parse import urlencode
http = urllib3.PoolManager()
encoded_args = urlencode({'arg':'value'}) # 'arg=value'
url = 'http://httpbin.org/post?' + encoded_args # 'http://httpbin.org/post?arg=value'
r = http.request('POST',url)
json.loads(r.data)['args'] # {'arg': 'value'}
json.loads(r.data)
5.表单数据
对PUT和POST请求,urllib3将自动使用fields提供的参数对字典进行格式编码
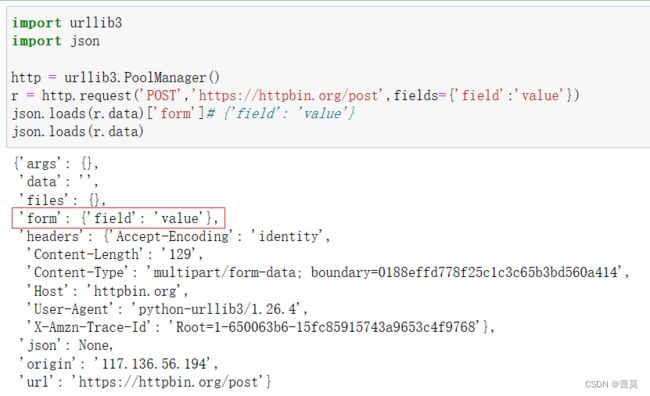
import urllib3
import json
http = urllib3.PoolManager()
r = http.request('POST','https://httpbin.org/post',fields={'field':'value'})
json.loads(r.data)['form']# {'field': 'value'}
json.loads(r.data)
6.提交json数据
通过指定编码数据作为body参数,并且通过Content-Type在调用时设置表头来发送json请求
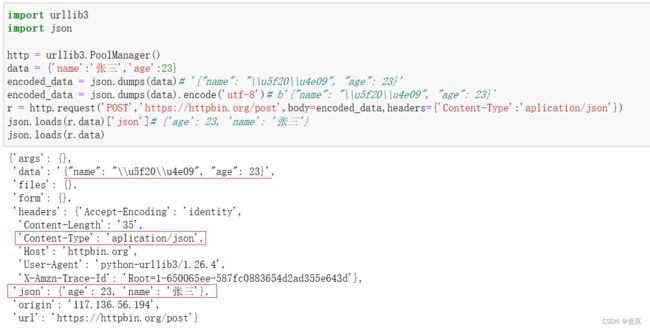
import urllib3
import json
http = urllib3.PoolManager()
data = {'name':'张三','age':23}
encoded_data = json.dumps(data)# '{"name": "\\u5f20\\u4e09", "age": 23}'
encoded_data = json.dumps(data).encode('utf-8')# b'{"name": "\\u5f20\\u4e09", "age": 23}'
r = http.request('POST','https://httpbin.org/post',body=encoded_data,headers={'Content-Type':'aplication/json'})
json.loads(r.data)['json']# {'age': 23, 'name': '张三'}
json.loads(r.data)